Elasticsearch是建立在全文搜索引擎库Lucene基础上的搜索引擎,它隐藏了Lucene的复杂性,取而代之的提供了一套简单一致的RESTful API。Elasticsearch的倒排索引,其实就是Lucene的倒排索引。
为什么叫倒排索引
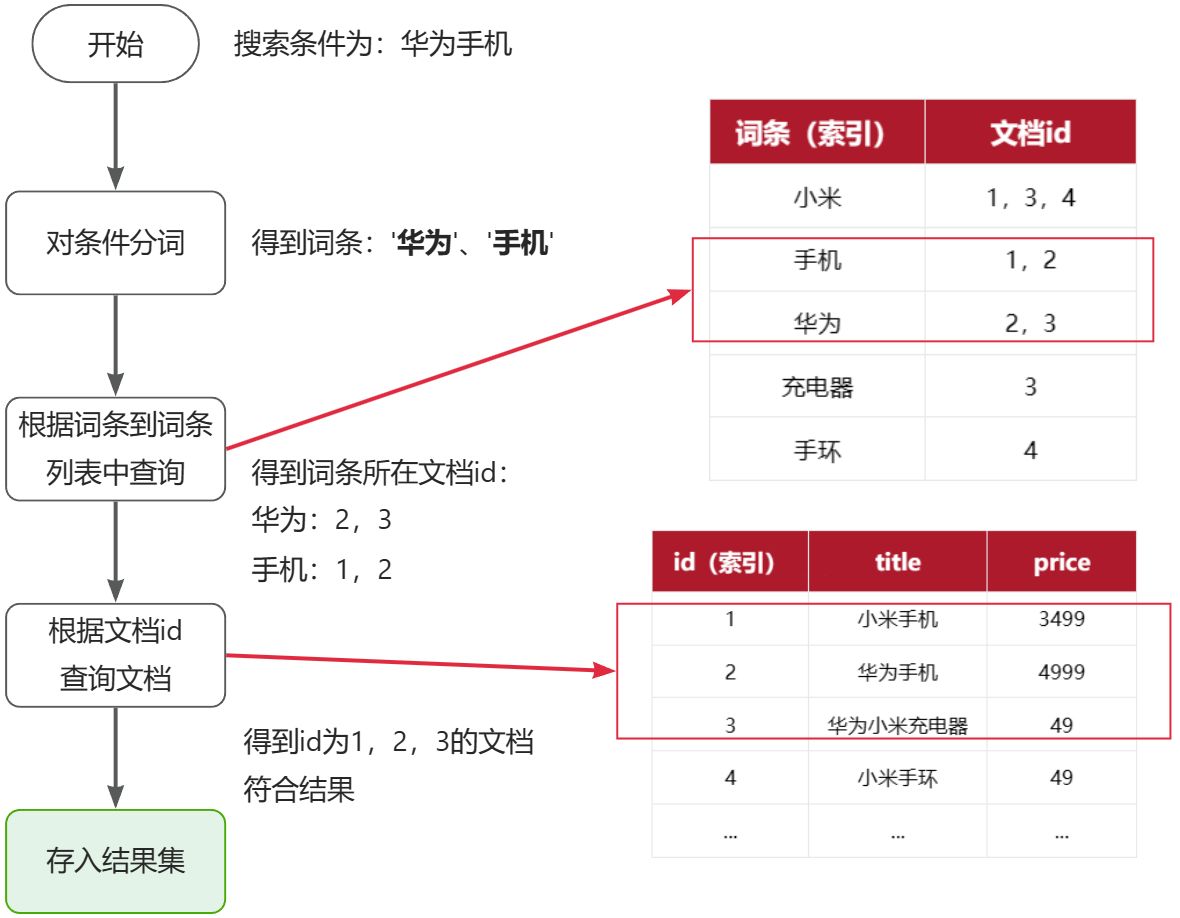
在没有搜索引擎时,我们在搜索框输入文本,这时我们的行为是document->to->words
正向索引
| id(索引) | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| ... | ... | ... |
我们希望能够输入一个单词,找到含有这个单词,或者和这个单词有关系的文章:word->to->documents
| 词条(索引) | 文档id |
|---|---|
| 小米 | 1,3,4 |
| 手机 | 1,2 |
| 华为 | 2,3 |
| 充电器 | 3 |
| 手环 | 4 |
倒排索引就好比书签:
倒排索引的内部结构
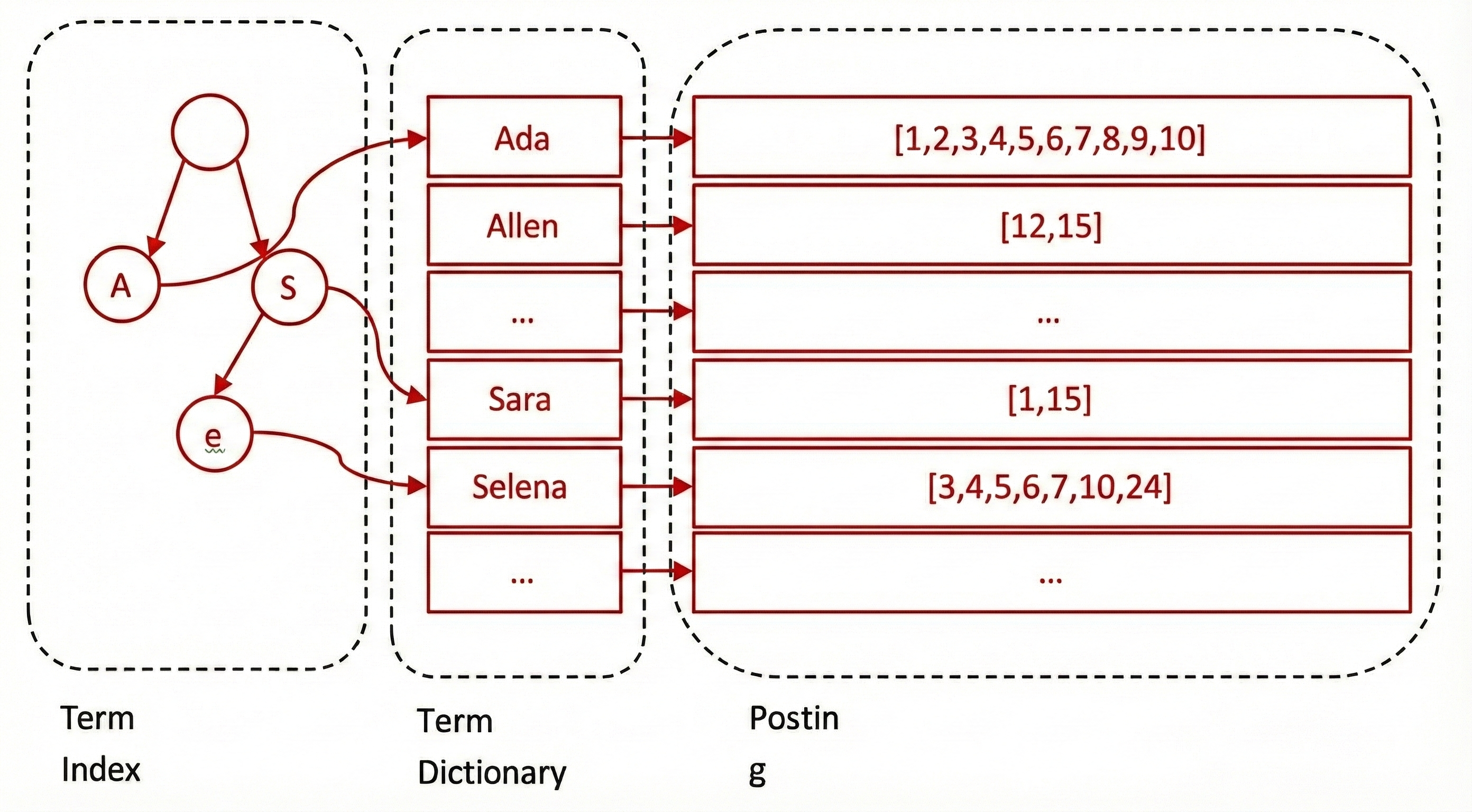
Lucene的倒排索引增加了最左边的一层字典树,它不存储所有的单词,只存储单词前缀,通过字典树找到单词所在的块,也就是单词的大概位置,再再块里二分查找,找到对应的单词,再找到单词对应的文档列表。
Lucene的操作都在内存中,内存寸土寸金,能省则省,所以Lucene还用了FST(Finite State Transducers)对它进一步压缩。最右边的Postig List只是存一个文档ID数组,但是再设计时,遇到的问题可不少。
FST
原生的Posting List有两个痛点:
- 如何压缩以节省磁盘空间
- 如何快速求交并集
压缩
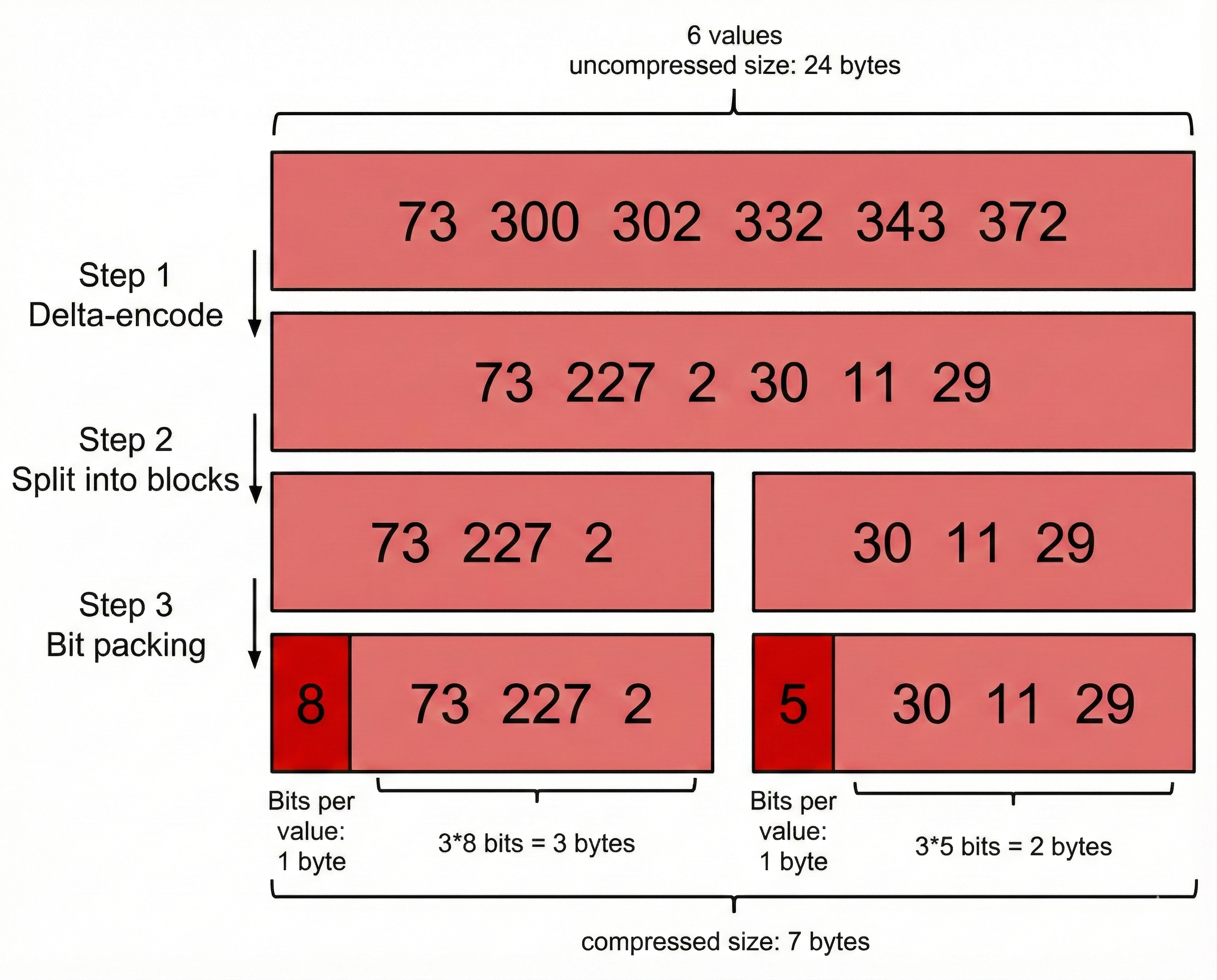
假设我们有这样一个数组:
73, 300, 302, 332, 343 372
Lucene里,数据是按Segment存储的,每个Segment最多存65536个文档ID,所以文档ID的范围,从0到2^16-1,所以每个元素都会占用2bytes,对应上面的数组,就是6*2 = 12bytes。
第一步:Delta-encode--增量编码
我们只记录元素与元素之间的增量,于是数组变成了:
73,227,2,30,11,29
第二步:Split into blocks--分割成快
Lucene里每个块是256个文档ID,这样可以保证每个块,增量编码后,每个元素都不会超过256(1byte).
为了方便演示,我们假设每个块是3个文档ID:
73,227,2\],\[30,11,29
第三步:Bit packing--按序分配空间
对于第一个块,73,227,2,最大元素是227,需要8bits,那么我就给这个块的每个元素,都分配8bits的空间。
但是对于第二个块,30,11,29,最大元素才30,只需要5bits,那我就给你每个元素只分配5bits的空间,足矣。
以上三个步骤,共同组成一项编码技术,Frame Of Reference(FOR):
Roaring bitmaps
Posting List的第二个痛点:如何快速求交并集。
在Lucene中查询,通常不只有一个查询条件,比如我们想搜索:
- 含有"生存"相关词语的文档
- 文档发布事件在最近一个月
- 文档发布者是平台的特约作者
这样就需要根据三个字段,去三颗倒排索引里去查,我们首先要把数据进行反向处理,即解压,才能还原成原始的文档ID,然后把这三个文档ID数组在内存中做一个交集。
把这个问题简化成一道算法题:
假设有下面三个数组:
64, 300, 303, 343
73, 300, 302, 303, 343, 372
303, 311, 333, 343
求它们的交集。
方式一:Integer数组
直接使用原始的文档ID,将数组逐个遍历一遍,遍历完就知道交集是什么了。
其实对于有序的数组,用跳表可以更加高效。假设有100M个文档ID,每个文档ID占2bytes,那已经是200MB,而这些数据是要放到内存中进行处理的,把这么大量的数据,从磁盘解压后丢到内存,内存肯定撑不住。
方式二:Bitmap
假设有这样一个数组:
3,6,7,10
那么我们可以这样来表示:
0,0,1,0,0,1,1,0,0,1
我们用0表示角标对应的数字不存在,用1表示存在。
两个好处:
- 节省空间:既然我们只需要0和1,那每个文档ID就只需要1bit,还是假设有100M个文档,那只需要100M bits = 100M * 1/8bits = 12.5MB,比之前用Integer数组的200MB,优秀太多了。
- 运算更快:0 和 1,天然就适合进行位运算,求交集,「与」一下,求并集,「或」一下,一切都回归到计算机的起点
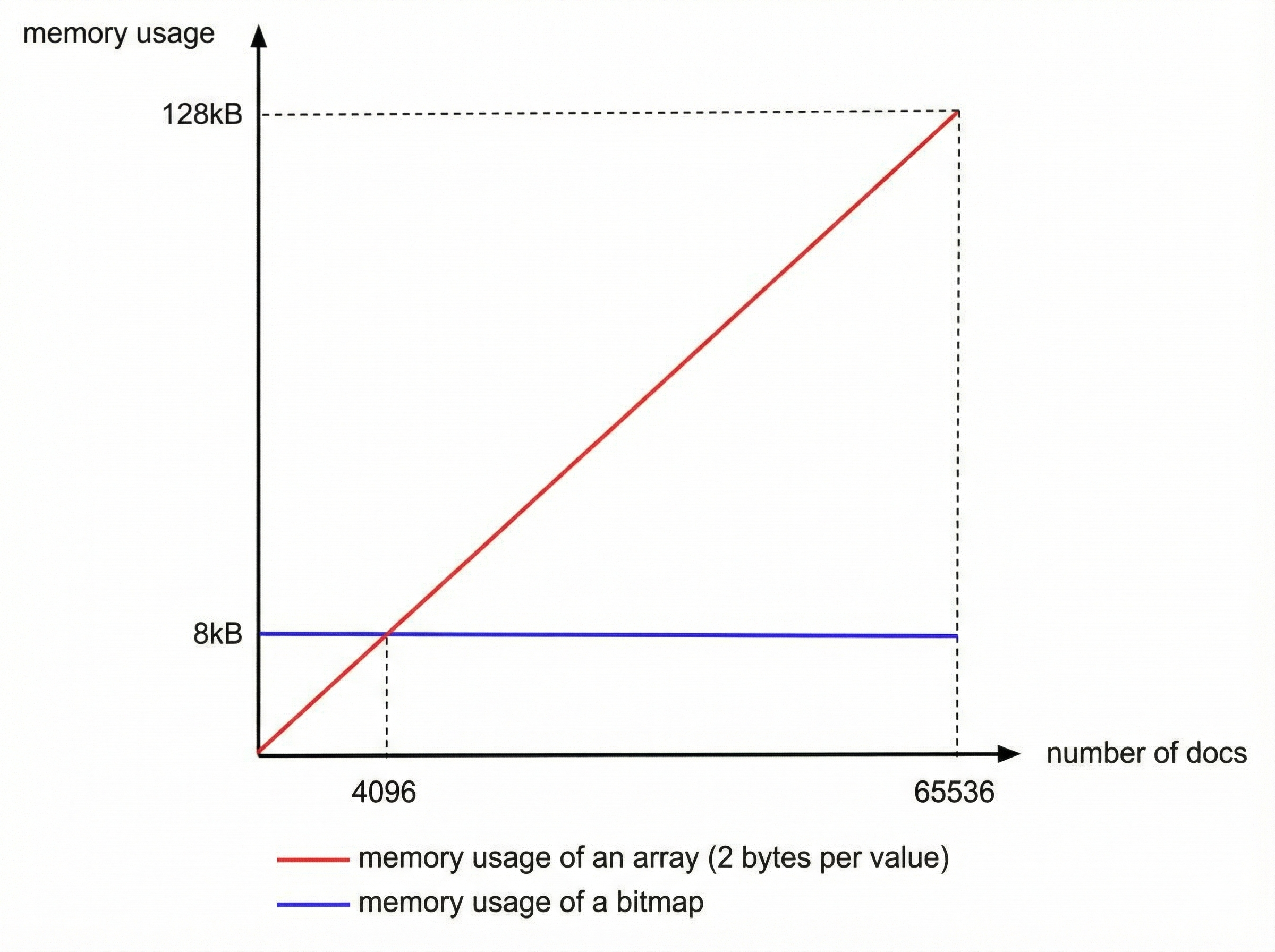
方式三:Roaring Bitmaps
bitmap有个 硬伤,就是不管你有多少个文档,你占用的空间都是一样的,之前说过,Lucene Posting List的每个Segement最多放65536个文档ID,举一个极端的例子,有一个数组,里面只有两个文档ID:
0, 65535
用Bitmap,要怎么表示?
1,0, 0, 0,......(超级多个0),......,0,0,1
你需要65536个bit,也就是65536/8=8192bytes,而用Integer数组,你只需要2*2bytes=4bytes。
可见在文档数量不多的时候,使用Integer数组更加节省内存。
我们来算一下临界值,很简单,无论文档数量多少,bitmap都需要8192bytes,而Integer数组和文档数量成线性关系,每个文档ID占2bytes,所以:
8192 / 2 = 4096
当文档数量少于4096时,用Integer数组,否则用bitmap
总结
很多业务上、技术上要解决的问题,最后都可以抽象为一道算法题,复杂问题简单化。