在众多的 AI 大模型的应用场景中,Text-to-SQL,也就是文本转 SQL,是其中实用性很高的一个。Text-to-SQL 充分利用了大模型的优势,把用户提供的自然语言描述转换成 SQL 语句,还可以执行生成的 SQL 语句,再把查询结果返回给用户。
在实际的业务系统中,绝大部分数据都保存在数据库中,其中以关系数据库为主流。这使得 SQL 成为了很多人的必备技能,除了程序员之外,还包括大量非技术的分析人员。这些人没有技术背景, 学习 SQL 对他们来说有一定的难度。但是他们懂得自己的数据需求,知道如何用自然语言来描述自己的需求,但是 SQL 严格的语法会成为他们的障碍。大模型可以成为他们的助手。只需要把查询需求输入大模型,大模型可以根据描述生成 SQL 语句。通过大模型的方法调用,还可以直接运行生成的 SQL 语句,得到结果之后返回给用户。
文本转 SQL 的实现所涉及的方面比较多,可以很简单,也可以很复杂。实现的复杂度和几个因素有关。
第一个因素是数据库中表的数量。在给大模型的提示中,需要包含数据库中表的元数据,包括表的名称、描述、表中列的名称、类型和描述等。大模型根据这些信息来生成 SQL。如果数据库中的表的数量较少,全部这些表的元数据可以直接内嵌在提示中。如果数据库中的表很多,超过了大模型的上下文窗口的长度限制,那就需要用到检索增强生成(RAG)技术。把全部数据库和表的元数据,保存在向量数据库中。根据用户的查询,从向量数据库中检索到可以满足用户查询需求的表的元数据,仅把这些表的元数据包含在提示中就足够了。
第二个因素是生成 SQL 语句的验证。大模型生成的 SQL 语句,不一定总是正确的,可能有语法错误,也可能有逻辑错误。具体的问题,只有真正执行了 SQL 语句之后才能知道。可以把执行时的错误信息,和 SQL 语句一起,再次发送给大模型,由大模型对错误的 SQL 语句进行修改。这样重复迭代多次,从而得到最终正确的结果。
这里给出了一个简单的代码示例,不考虑使用检索增强生成,以及 SQL 的验证。对于较小规模的数据库,以及相对简单的查询需求,一次生成的 SQL 语句的准确性已经比较高了。
这个例子使用 Spring AI 开发,使用 JDBC 提取出数据库的元数据,以 JSON 格式嵌入在发送给大模型的提示中,另外创建了一个大模型使用的工具,可以执行 SQL 语句。完整的代码在 GitHub (https://github.com/JavaAIDev/simple-text-to-sql) 上。
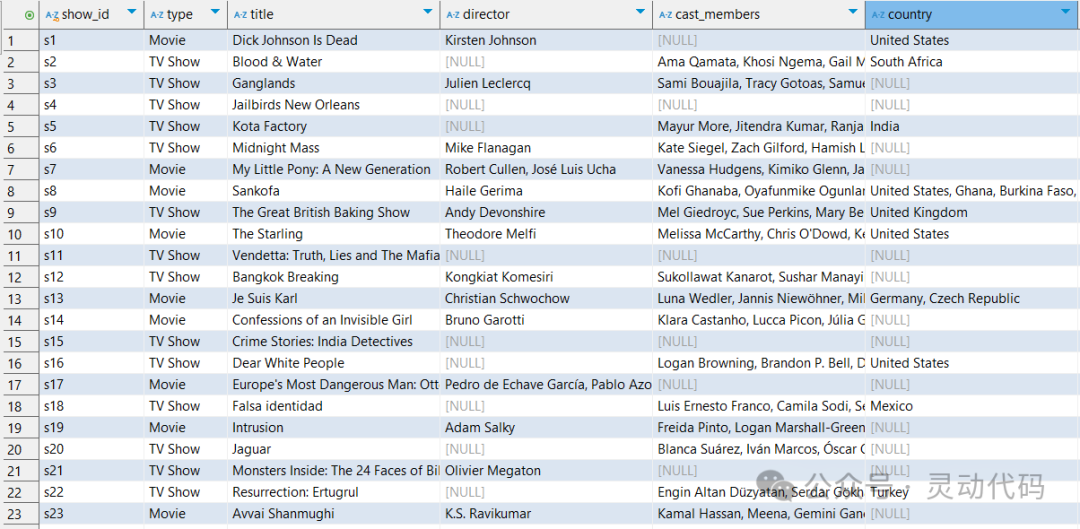
这里通过一个 Netflix 上的节目的数据库来作为演示,这个数据库里面只有一张表。表的结构和包含的数据如下所示。
使用 JDBC 提取出来数据库的元数据,所生成的 JSON 格式的内容如下所示。

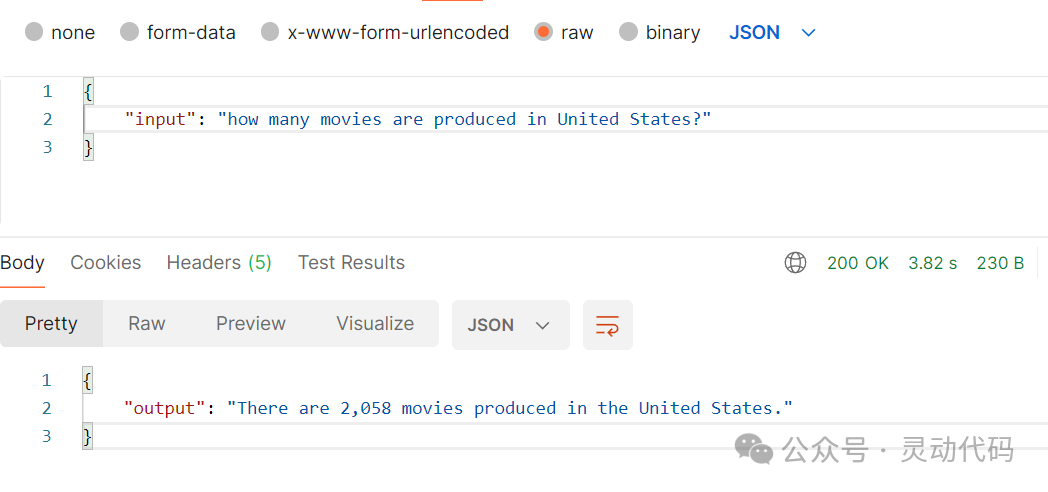
输入的查询是, how many movies are produced in United States?,意思是"在美国制作的电影的数量"。大模型的输出如下所示,数量是 2058。
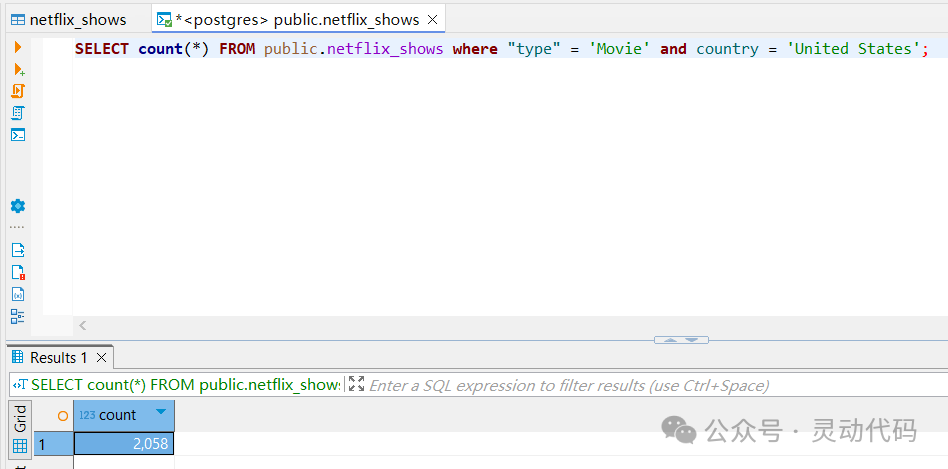
所生成的 SQL 语句如下所示。在生成的 SQL 语句中,根据 type 和 country 进行了过滤。在 SQL 客户端中执行所生成的语句,可以得到同样的结果。
以上就是使用大模型进行文本转 SQL 的基本实现方式。