AI时代的爬虫神器到底是什么样?
在大数据和AI日益壮大的今天,有个高效、智能的网络爬虫简直是AI从业者的福音。本文就来聊聊这个神奇的开源项目------Crawl4AI。它不仅免费开源,而且还特别为大语言模型(LLM)友好优化,功能强大不说,速度还贼快。
项目简介
Crawl4AI 是一个专为大语言模型(LLM)和AI应用设计的异步爬虫框架,它不仅能处理复杂的网页爬取,还提供丰富的内容提取和数据处理功能。得益于它的开源特性和强大的功能,大家可以完全根据需求来定制使用。
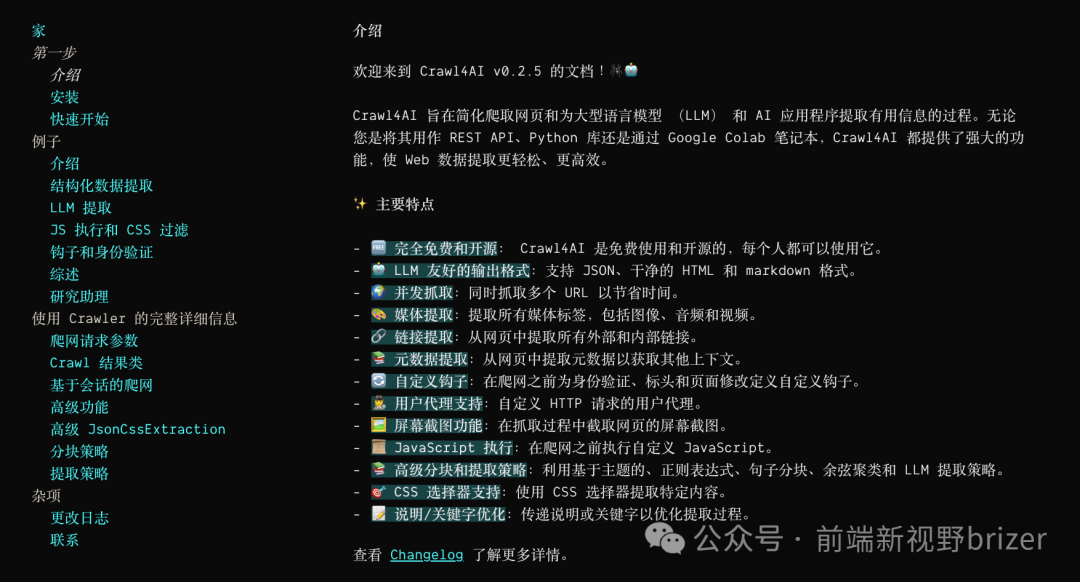
亮点功能
-
• 异步架构:支持 Playwright 多浏览器异步操作,带来更高效的性能和更低的资源占用。
-
• 数据提取能力一流:支持提取所有媒体(图片、音频、视频)和内外部链接,甚至可以根据 JSON、CSS 选择器等策略精准提取结构化数据。
-
• 灵活处理动态内容:比如支持 iframe 内的内容提取、延迟加载处理、自定义页面超时等。
-
• 完全开源:还不收费,这简直要让那些收费的爬虫工具哭晕在厕所了。
-
• 全面支持 LLM 格式:输出格式包括 JSON、清理后的 HTML 和 Markdown,让后续的AI处理变得非常方便。
高级特性
-
- 执行自定义 JavaScript:可以在爬取前执行自定义脚本,处理那些动态加载的页面。
-
- 多会话管理:可以在多个页面之间无缝切换,支持复杂的网页交互场景。
-
- 代理和自定义请求头:增强隐私和防封锁能力,满足更复杂的爬取需求。
-
- 爬取前的自定义钩子:提供页面内容修改、身份验证等能力,让你在爬取前能做更多预处理。
-
- 高级分块策略:支持根据主题、正则、句子等方式分块提取内容,让数据处理更加灵活。
安装与快速上手
Crawl4AI 支持多种安装方式,可以选择使用 pip 安装,也可以直接用 Docker 镜像来跑。下面我们来个快速入门示例,让大家感受一下这个工具的魔力。
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler(verbose=True) as crawler:
result = await crawler.arun(url="https://www.nbcnews.com/business")
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())这段代码展示了如何使用 Crawl4AI 异步爬取并提取网页内容。只需几行代码,Crawl4AI 就能轻松帮你抓取并清理内容。
高级用法示例
-
- 执行 JavaScript:适用于那些需要点击"加载更多"的网页。
-
- 数据结构化提取:使用 JsonCssExtractionStrategy 结合 CSS 选择器精准抓取网页元素。
-
- 代理支持:适用于想保持隐私或绕过某些限制的场景。
想了解更多复杂场景的使用?去(https://github.com/unclecode/crawl4ai)上看看吧,里面有一堆例子等你发掘。
性能对比
Crawl4AI 以速度见长。在与某收费爬虫服务的对比测试中,Crawl4AI 在爬取时的速度比对手快了整整4倍!而且还能加载 JavaScript 提取更多的图片和数据,这性价比直接拉满。
开源地址
https://github.com/unclecode/crawl4ai看到这里,如果觉得这个工具不错,那就赶紧给这个开源项目点个 Star 吧。
结语
Crawl4AI 是一个强大的开源爬虫工具,无论你是想搞大数据、搞AI,还是单纯想用它来爬取大量网页内容,它都能轻松胜任。而且,它对大语言模型特别友好,让你轻松应对各种数据处理需求。
如果你有兴趣,不妨试试看吧,绝对值得一试!
推荐阅读
欢迎关注我的公众号"前端新视野brizer",原创技术文,开源好工具第一时间推送。