什么是 Stable Diffusion?简而言之,Stable Diffusion 是一款 AI 绘画工具。所以,在我们进一步介绍它之前,我们先要聊聊:AI 绘画是什么。
1、AI 绘画简介
2022 年 8 月,在美国科罗拉多州举办了一场新兴数字艺术家竞赛,其中『数字艺术/数字修饰照片』类别的一等奖由一幅名为《太空歌剧院》的作品获得,神奇的是这幅作品的作者并没有绘画基础,而是完全用 AI 完成了这幅作品。
这一事件展示了 AI 在艺术创作方面的重大突破和让人惊奇的创造力,让人们见识到 AI 的作品不仅具有较高的逼真度和细节,而且还拥有独特的风格,更重要的是它不需要创作者具备绘画技能,只需要通过自然语言描述清楚创作需求,就能借助 AI 生成出高品质的作品,这让很多普通用户的『画家』和『艺术家』的梦想用极低的成本照进了现实,从而引发了大家的热议,并由此激发了大家对 AI 绘画的兴趣。

更多实操教程和stablediffusion安装包可以扫描下方,免费获取

AI 绘画作品《太空歌剧院》
那什么是 AI 绘画呢?AI 绘画是指使用人工智能算法生成图像或绘画作品,它基于机器学习模型,可以接受不同的提示词、引导图等作为输入参数来生成各种风格和内容的视觉艺术品。
比如,下面这张图片就是给 AI 输入一句提示词 a cute cat 得到的绘图结果:
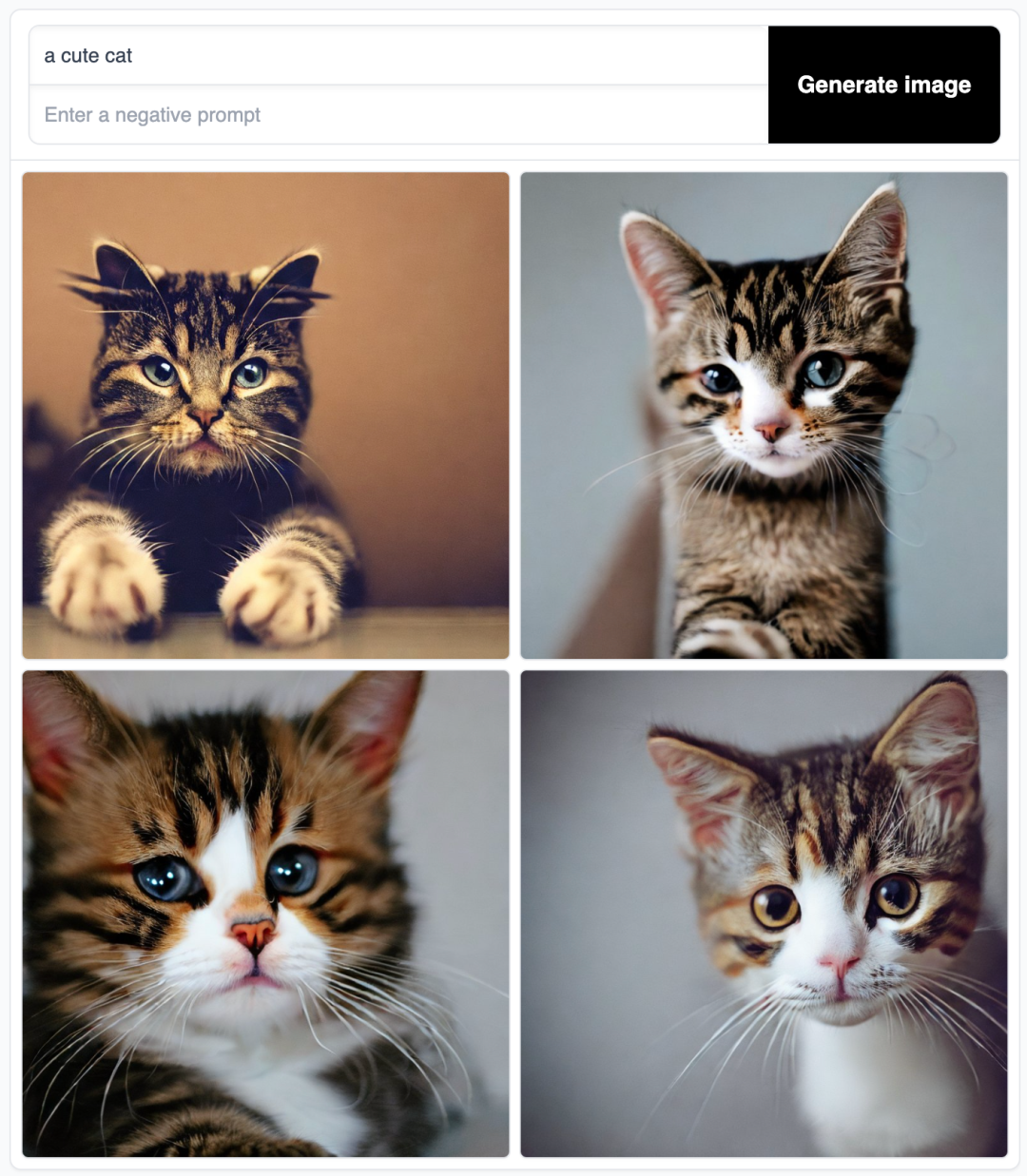
AI 绘画:a cute cat
几个基础单词构成的一行简单的文本就能生成质量相当不错的图片,这无疑是一次重大的技术突破,它大大提升了图像视觉类内容的生产效率。
当然,AI 绘画的技术突破不是一蹴而就的。中国信息通信研究院和京东探索研究院在 2022 年 9 月发布了**《人工智能生成内容(AIGC)白皮书》**1,这里的 AIGC 指的是『人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)』,AI 绘画则是属于 AIGC 范畴的一个分支。结合其中的内容以及一些典型事件,我们可以大致勾勒出 AIGC 及 AI 绘画技术的发展历程:
1)早期萌芽(1950s-1990s):基于规则、模板或统计模型,AIGC 开启零星实验项目
在这个阶段,AIGC 处于零星的实验尝试时期,比如:
1957 年,莱杰伦·希勒(Lejaren Hiller)和伦纳德·艾萨克森(Leonard Isaacson)完成了历史上第一支由计算机创作的音乐作品:弦乐四重奏《伊利亚克组曲(Illiac Suite)》。实现方式是利用计算机随机生成了大量音符序列,然后根据一定的乐理规则,比如限定旋律范围、和声规则、节奏模板等,对这些随机序列进行筛选和编辑,这样反复迭代并人工干预来调整算法和规则,从而生成了最终的乐谱。
1966 年,约瑟夫·魏岑鲍姆(Joseph Weizenbaum)和肯尼斯·科尔比(Kenneth Colby)共同开发了世界第一款可对话的机器人『伊莉莎(Eliza)』。实现方式是扫描用户的输入,以识别输入中的关键词或短语。比如,Eliza 可能会寻找与『我』、『你』、『因为』、『难过』等相关的词汇。一旦识别出关键词,Eliza 会尝试将它们与预定义的规则和转换模式进行匹配,这些规则通常是一些简单的模式匹配规则,通过这种方式,Eliza 可以模拟人类对话的一些基本特征,比如提问、回答、反馈。虽然在现在看来 Eliza 的技术实现非常简单,但它在当时引起了广泛的关注和讨论,甚至被一些人认为是具有人工智能的机器人。
在 1980s 年代,IBM 创造了语音控制打字机『坦戈拉(Tangora)』,能够处理约 20000 个单词。Tangora 基于隐形马尔科夫链模型(Hidden Markov Model,HMM)来建立统计语言模型,用于处理口语表达方式的语音输入。在语音转文字的信号处理过程中,Tangora 使用一个预先定义好的词典,并根据频率信息建立起词与词之间的转移概率。当输入一段语音时,Tangora 提取语音特征将其输入到 HMM 统计语言模型中来寻找发音分类,然后再根据词典和统计模型,搜索出最可能的词序列并进行文本输出。
通过上面的事件案例可以发现,在早期萌芽阶段,AIGC 技术主要是依靠预先设定的规则、模板或者统计模型来进行简单的内容生成,这里有几点局限性:1)与预期的内容质量还有较大的差距;2)所能处理的信息量也有很大的限制;3)能够接触到这些实验性产品的都是具备相关专业知识的科研人员或工程师,很难触达到普通用户。
在 20 世纪 80 年代末至 90 年代中,由于高昂的系统成本无法带来客观的商业变现,研究机构和商业公司纷纷减少了在人工智能领域的投入,AIGC 没有取得重大的突破。
2)沉淀积累(1990s-2010s):深度学习算法突破,AIGC 从实验性向实用性逐渐转变
这个阶段是 AI 技术在各个层面开始加速发展的阶段。在硬件层面,图形处理器(Graphics Processing Unit,GPU)、张量处理器(Tensor Processing Unit,TPU) 等算力设备性能不断提升;在数据层面,互联网使用的数据规模快速膨胀并为各类人工智能算法提供了海量训练数据;在 AI 算法层面,模仿人脑神经网络工作模式并结合计算机科学和统计学来解决人工智能领域的常见问题的人工神经网络(Artificial Neural Network)技术不断迭代发展,基于多层神经网络的**深度学习(Deep Learning)**算法在图像识别、语音识别、自然语言处理等领域取得了重大突破。
2012 年,杰弗里·欣顿(Geoffrey Hinton)教授的课题组构建的卷积神经网络(Convolutional Neural Network,CNN)模型 AlexNet 在参加业界知名的 ImageNet 图像识别大赛中以碾压第二名的态势一举夺得冠军,从而使深度学习(Deep Learning)算法引发了工业界的关注,迅速开始在工业界应用开来。
受益于相关技术的发展,AIGC 相关的应用也开始从实验性逐渐向实用性转变,比如:
2007 年,纽约大学人工智能研究员罗斯·古德温(Ross Goodwin)装配的人工智能系统通过对公路旅行中的一切所见所闻进行记录和感知,撰写出世界第一部完全由人工智能创作的小说《1 The Road》。实现方式是通过训练一个可以生成任意长度文本的神经网络模型,将公路旅行中采集的图像、声音、地理位置等信息作为种子输入给模型来生成出文本内容。作为世界第一部完全由人工智能创作的小说,其象征意义远大于实际意义,整体可读性不强,拼写错误、辞藻空洞、缺乏逻辑等缺点明显。
2012 年,微软公开展示了一个基于深层神经网络(Deep Neural Network,DNN)的全自动同声传译系统,该系统在发布会现场自动将演讲者的英文演讲内容实时转换成了与他音色相近的字正腔圆的中文语音,效果流畅,赢得了参会人员的一片掌声。
可以看到随着技术的突破,AI 在图像识别、语音识别、自然语言处理等领域已经开始出现效果不错的应用,更多的普通用户开始接触到集成了这些 AI 能力的产品,比如:跨国语言翻译工具、人脸识别系统等等。但是,由于算法瓶颈的限制,AI 还无法较好地完成内容创作类型的任务,相关的应用非常有限,效果也有待提升。
3)快速发展(2010s-2020s):生成对抗网络提出和发展,AIGC 效果显著提升
2014 年,伊恩·古德费洛(Ian J. Goodfellow)等人提出了一种非监督机器学习的方法:生成对抗网络(Generative Adversarial Network,GAN),该方法由两个神经网络用相互博弈的方式进行学习,这种方法在图像生成方面效果显著。
随后,在生成对抗网络这个方向上产生了许多流行的框架:
2018 年,Andrew Brock 和 DeepMind 发布了 BigGAN,首次用生成对抗网络生成了具有高保真度和低品种差距的图像,生产的图像效果足以以假乱真。
2018 年,英伟达发布的 StyleGAN 模型可以自动生成图片。StyleGAN 算法的核心是风格转移技术或风格混合。它在面部生成任务中创造了新记录,除了生成面部外,它还可以生成高质量的汽车,卧室等图像。目前 StyleGAN 已经升级到第四代模型 StyleGAN-XL,其生成的高分辨率图片人眼难以分辨真假。
2019 年,DeepMind 发布了 DVD-GAN,它能够生成高分辨率和具备时间一致性的视频。DVD-GAN 将大型图像生成模型 BigGAN 扩展到视频领域,同时使用多项技术加速训练,它生成的视频效果在草地、广场等明确的场景下表现突出。
随着以生成对抗网络(Generative Adversarial Network,GAN)为代表的 AI 算法不断迭代更新,生成的图像效果提升显著,甚至逼真到人们难以分辨真假的地步。这让 AIGC 这个方向迎来了新时代,内容生成类应用也开始走到了普通用户面前,比如曾经风靡一时的视频换脸、真人变漫画特效等等。不过,这些被大多数普通用户感知到的应用场景还比较狭窄,用户还无法获得较大创作自由度。
4)破圈起飞(2020s-今):扩散模型突破,AIGC 出圈推向平民化并显现商业化前景
2015 年,Jascha Sohl-Dickstein 等人基于非平衡热力学提出了一个纯数学的生成模型:扩散模型(Diffusion Model,DM) 。参考:《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》2。此后,经过技术发展和实现,扩散模型可以应用于各种任务,如:图像去噪、图像修复、超分辨率成像、图像生成等等。例如,一个图像生成模型,经过对自然图像的扩散过程的反转训练之后,可从一张完全随机的噪声图像开始逐步生成新的自然图像。此外,扩散模型的算法还允许在图像生成过程中添加引导机制来控制生成结果,从而不需要重新训练整个模型就能满足模型的调优。但是,由于扩散模型通常直接在像素空间中运行,因此对模型进行调优往往要耗费上百 GPU 天,成本仍然是非常高的。
2021 年,Robin Rombach 等人所在的 CompVis 研究团队在扩散模型的基础上提出了一种潜在扩散模型(Latent Diffusion Model,LDM) 。参考:《High-Resolution Image Synthesis with Latent Diffusion Models》3。潜在扩散模型(LDM)是扩散模型(DM)的一个变体,它通过技术改进显著降低了模型训练和生成图像的计算成本,使得在有限的计算资源上运行模型成为了可能。
从 2022 年开始,基于潜在扩散模型的 AI 绘画产品纷纷推出。比如:
2022 年,OpenAI 推出了 DALL-E 的升级版本 DALL-E-2,主要应用于文本与图像的交互生成内容,用户只需要输入简短的描述性文字,DALL-E-2 即可创作出相应极高质量的卡通、写实、抽象等风格的绘画作品。
2022 年,美国初创公司 Midjourney Lab 推出的 AI 绘画工具 Midjourney,该工具架设在 Discord 频道上,使用方法很简单,进入 Midjourney 的 Discord 频道,在频道对话框输入自然语言提示词,系统就会在对话框里发送生成的图。该工具迅速流行起来,在一年的时间内就积累了上千万用户。
2022 年,Stability.ai 推出 Stable Diffusion 并将其开源,Stable Diffusion 在搭载了一定性能显卡的个人电脑即可驱动,且出图效果经过反复迭代有着显著改进,从而把 AIGC 创作最终推向平民化。
可以发现基于潜在扩散模型推出的 AI 绘画工具可准确把握文本信息进行创作,只需通过简单的提示词就能在数秒内生成高质量的图片,这种简易的交互方式和生产速度将 AIGC 的使用成本大大降低,而创作自由度却得到了极大提升。对普通用户来讲,简单的一句话,就能生成与之对应的高质量图像,这种『言出法随』的效果被大家称为『魔法』。伴随着大量用户的广泛认可,AIGC 随着 AI 绘画的火爆而出圈,开始显现出令人期待的商业化前景,国内外互联网巨头和独角兽纷纷下场。于是,很多人也开始把 2022 年称为 AI 绘画的元年。
2、Stable Diffusion 简介
如上文介绍,Stable Diffusion 也是一款在 2022 年发布的支持由文本生成图像的 AI 绘画工具。它主要用于根据文本的描述生成对应的图像,也可以应用于其他任务,如:对原图像内的部分遮罩区域进行重绘的内补绘制功能(Inpainting)、在原图像外部范围进行延伸画图的外补绘制功能(Outpainting)、在提示词(Prompt)引导下基于输入图像生成新图像的图生图功能等。
2.1、Stable Diffusion 模型
Stable Diffusion 最核心的部分是它的模型,如上文介绍 Stable Diffusion 模型是一种文本到图像的潜在扩散模型。
要理解 Stable Diffusion 所使用的潜在扩散模型背后的技术细节需要一定的算法技术基础,而探索这些细节并不属于本文的目的,我们在这里就不做过多的探讨了。
这里系列文章的内容主要是向大家介绍如何使用 Stable Diffusion 来进行 AI 绘画,大家了解一些相关的技术梗概会有助于大家后续使用 Stable Diffusion,所以我们在这里只用尽量简要的语言介绍一下扩散模型的大概过程,以帮助大家对它建立一个大概的印象:
1)扩散模型训练需要先找到一堆高质量的图像,训练时对每张图像按照高斯噪声公式一步一步来加噪点,直到整张图像变成一张全是噪点的图像(如下图从左到右的过程所示),这个训练的过程会记录所有步骤。接下来,就用神经网络的方式来反向学习如何从一个全是噪点的图像变成一张高清图像(如下图从右到左的过程所示)。

扩散模型训练过程
2)一旦完成训练得到了扩散模型,机器就可以通过噪点来对图像进行预测。这样一来,整个绘画的过程就是 AI 用一组随机噪点(随机数)来预测基于它们能画出一个什么样的图像。AI 就是从一堆凌乱的随机数中画出图像的,这个过程是一个大力出奇迹的过程,但厉害的是最终能产出清晰度和细节度非常高的图像。
Stable Diffusion 模型的发布经历了这样几个节点:
1)2021 年,在潜在扩散模型论文**《High-Resolution Image Synthesis with Latent Diffusion Models》**4相关的工作基础上,CompVis 团队与商业公司 Stability AI 5、Runway 6 合作,在 Stability AI 的资助和人工智能领域的非营利组织 LAION 7 的帮助下,基于大规模图文数据集 LAION-5B8 的一个子集的 512x512 的图像上训练出了 Stable Diffusion 模型的 v1 版本。并在后续,迭代发布了多个 v1.x 版本的 Checkpoint。
Stable Diffusion v1 项目开源发布在:https://github.com/CompVis/stable-diffusion。
2)2022 年,Stability AI 公司在上述的 Stable Diffusion 模型的基础上继续迭代和增强,并推出了 Stable Diffusion 模型的 v2 系列版本。Stability AI 同时也将该项目开源并推向了市场。
Stable Diffusion v2 项目开源发布在:https://github.com/Stability-AI/stablediffusion。
Stable Diffusion 模型是从无到有训练的大模型,其训练成本是相当高昂的。Stability AI 创始人兼 CEO Emad Mostaque 曾表示,训练该模型使用了 256 块英伟达 A100 显卡,耗费了 15 万机时,花费了 60 万美元的成本。
3)2023 年,Stability AI 公司又推出了 Stable Diffusion XL 版本。在这个版本中,可以使用更简短的提示词实现 AI 绘画,并且支持在图像中生成单词。此外,XL 版本还支持更强的图像组合和人脸生成,有着更优秀的视觉效果、真实感和美学提升。
2.2、Stable Diffusion 的产品策略
在当下流行的 AI 绘画工具中,Midjourney 和 Stable Diffusion 应该是风头最盛的,它们在产品策略上各有长处。
Midjourney 的厉害之处在于它通过 Discord 来构建自己 AI 绘画社区的巧思,这个策略一方面使得用户能够在社区互相学习提示词的使用技巧、快速生成高质量美图,从而激发用户的兴趣、刺激了产品的传播;另一方面通过庞大的用户积累了独有的数据集,从而可以根据用户需求针对性地训练模型并快速进行产品迭代,形成了正反馈循环。
Stable Diffusion 的厉害之处则在于它可以在大多数配备有适度 GPU 的电脑硬件上运行,并且开源了项目代码和模型权重。这样一来,开源社区的开发者就可以在它的基础上进行二次开发、做插件、做工具,这就有了如今结合 Stable Diffusion 流行起来的 Stable Diffusion WebUI、LoRA、ControlNet 等等开源项目。这就相当于给 Stable Diffusion 的发展增加了大量的盟友,极大的丰富了它的功能和特性。
对于想要使用 Stable Diffusion 来 AI 绘画的用户来说,开源也意味着更大的灵活性和自由度,我们可以借助 Stable Diffusion 丰富的相关模型和扩展插件来满足我们自己独特的 AI 绘画创作需求,这也是为什么我们选择写 Stable Diffusion 系列文章的重要原因之一。
2.3、Stable Diffusion 的绘图效果
夸了这么多,我们来看看 Stable Diffusion 的绘图效果:

港口

底下洞穴的水晶沉积物

甜美风小姐姐

韩风小姐姐

什么是 Stable Diffusion?简而言之,Stable Diffusion 是一款 AI 绘画工具。所以,在我们进一步介绍它之前,我们先要聊聊:AI 绘画是什么。
1、AI 绘画简介
2022 年 8 月,在美国科罗拉多州举办了一场新兴数字艺术家竞赛,其中『数字艺术/数字修饰照片』类别的一等奖由一幅名为《太空歌剧院》的作品获得,神奇的是这幅作品的作者并没有绘画基础,而是完全用 AI 完成了这幅作品。
这一事件展示了 AI 在艺术创作方面的重大突破和让人惊奇的创造力,让人们见识到 AI 的作品不仅具有较高的逼真度和细节,而且还拥有独特的风格,更重要的是它不需要创作者具备绘画技能,只需要通过自然语言描述清楚创作需求,就能借助 AI 生成出高品质的作品,这让很多普通用户的『画家』和『艺术家』的梦想用极低的成本照进了现实,从而引发了大家的热议,并由此激发了大家对 AI 绘画的兴趣。

AI 绘画作品《太空歌剧院》
那什么是 AI 绘画呢?AI 绘画是指使用人工智能算法生成图像或绘画作品,它基于机器学习模型,可以接受不同的提示词、引导图等作为输入参数来生成各种风格和内容的视觉艺术品。
比如,下面这张图片就是给 AI 输入一句提示词 a cute cat 得到的绘图结果:
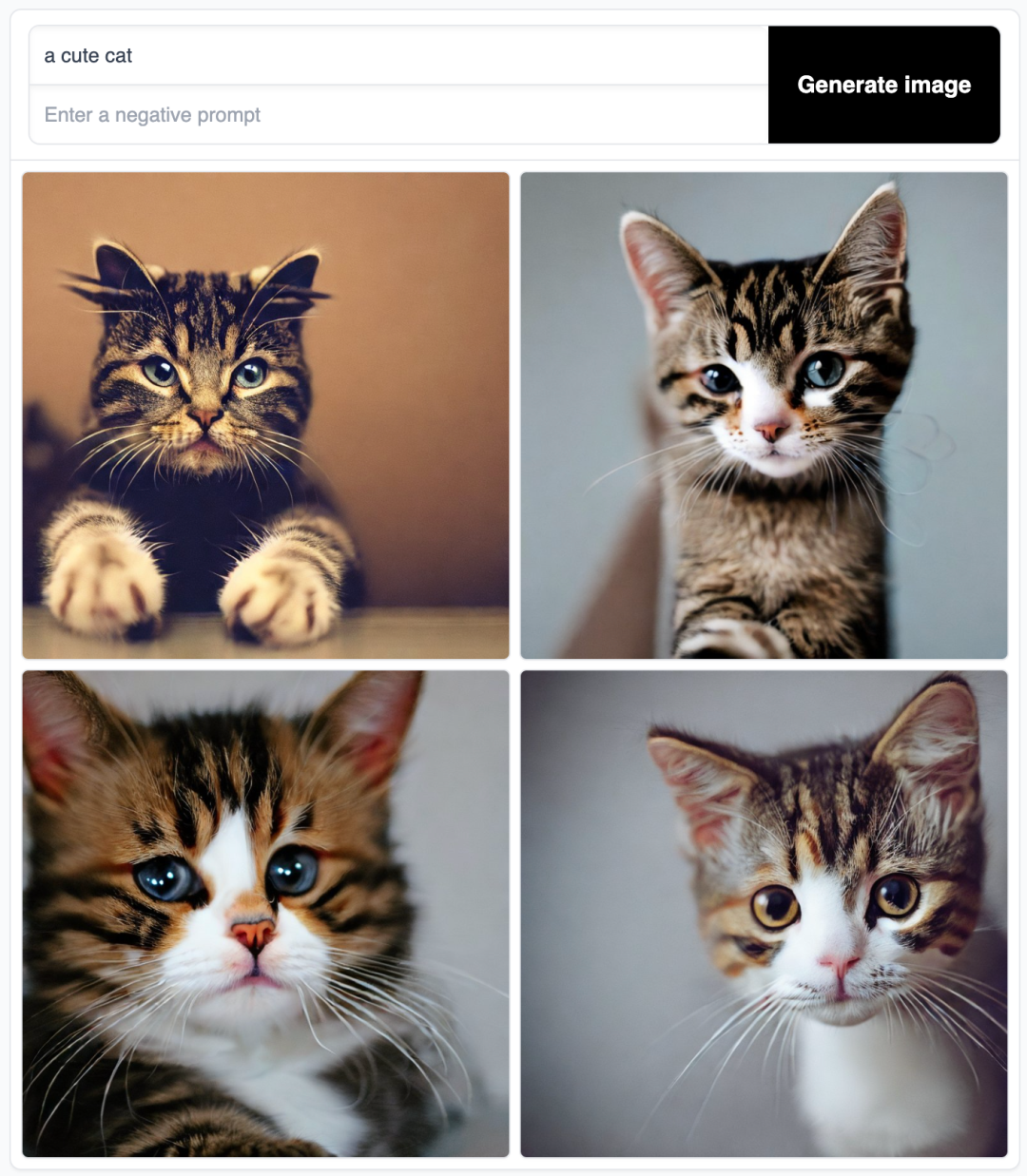
AI 绘画:a cute cat
几个基础单词构成的一行简单的文本就能生成质量相当不错的图片,这无疑是一次重大的技术突破,它大大提升了图像视觉类内容的生产效率。
当然,AI 绘画的技术突破不是一蹴而就的。中国信息通信研究院和京东探索研究院在 2022 年 9 月发布了**《人工智能生成内容(AIGC)白皮书》**1,这里的 AIGC 指的是『人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)』,AI 绘画则是属于 AIGC 范畴的一个分支。结合其中的内容以及一些典型事件,我们可以大致勾勒出 AIGC 及 AI 绘画技术的发展历程:
1)早期萌芽(1950s-1990s):基于规则、模板或统计模型,AIGC 开启零星实验项目
在这个阶段,AIGC 处于零星的实验尝试时期,比如:
1957 年,莱杰伦·希勒(Lejaren Hiller)和伦纳德·艾萨克森(Leonard Isaacson)完成了历史上第一支由计算机创作的音乐作品:弦乐四重奏《伊利亚克组曲(Illiac Suite)》。实现方式是利用计算机随机生成了大量音符序列,然后根据一定的乐理规则,比如限定旋律范围、和声规则、节奏模板等,对这些随机序列进行筛选和编辑,这样反复迭代并人工干预来调整算法和规则,从而生成了最终的乐谱。
1966 年,约瑟夫·魏岑鲍姆(Joseph Weizenbaum)和肯尼斯·科尔比(Kenneth Colby)共同开发了世界第一款可对话的机器人『伊莉莎(Eliza)』。实现方式是扫描用户的输入,以识别输入中的关键词或短语。比如,Eliza 可能会寻找与『我』、『你』、『因为』、『难过』等相关的词汇。一旦识别出关键词,Eliza 会尝试将它们与预定义的规则和转换模式进行匹配,这些规则通常是一些简单的模式匹配规则,通过这种方式,Eliza 可以模拟人类对话的一些基本特征,比如提问、回答、反馈。虽然在现在看来 Eliza 的技术实现非常简单,但它在当时引起了广泛的关注和讨论,甚至被一些人认为是具有人工智能的机器人。
在 1980s 年代,IBM 创造了语音控制打字机『坦戈拉(Tangora)』,能够处理约 20000 个单词。Tangora 基于隐形马尔科夫链模型(Hidden Markov Model,HMM)来建立统计语言模型,用于处理口语表达方式的语音输入。在语音转文字的信号处理过程中,Tangora 使用一个预先定义好的词典,并根据频率信息建立起词与词之间的转移概率。当输入一段语音时,Tangora 提取语音特征将其输入到 HMM 统计语言模型中来寻找发音分类,然后再根据词典和统计模型,搜索出最可能的词序列并进行文本输出。
通过上面的事件案例可以发现,在早期萌芽阶段,AIGC 技术主要是依靠预先设定的规则、模板或者统计模型来进行简单的内容生成,这里有几点局限性:1)与预期的内容质量还有较大的差距;2)所能处理的信息量也有很大的限制;3)能够接触到这些实验性产品的都是具备相关专业知识的科研人员或工程师,很难触达到普通用户。
在 20 世纪 80 年代末至 90 年代中,由于高昂的系统成本无法带来客观的商业变现,研究机构和商业公司纷纷减少了在人工智能领域的投入,AIGC 没有取得重大的突破。
2)沉淀积累(1990s-2010s):深度学习算法突破,AIGC 从实验性向实用性逐渐转变
这个阶段是 AI 技术在各个层面开始加速发展的阶段。在硬件层面,图形处理器(Graphics Processing Unit,GPU)、张量处理器(Tensor Processing Unit,TPU) 等算力设备性能不断提升;在数据层面,互联网使用的数据规模快速膨胀并为各类人工智能算法提供了海量训练数据;在 AI 算法层面,模仿人脑神经网络工作模式并结合计算机科学和统计学来解决人工智能领域的常见问题的人工神经网络(Artificial Neural Network)技术不断迭代发展,基于多层神经网络的**深度学习(Deep Learning)**算法在图像识别、语音识别、自然语言处理等领域取得了重大突破。
2012 年,杰弗里·欣顿(Geoffrey Hinton)教授的课题组构建的卷积神经网络(Convolutional Neural Network,CNN)模型 AlexNet 在参加业界知名的 ImageNet 图像识别大赛中以碾压第二名的态势一举夺得冠军,从而使深度学习(Deep Learning)算法引发了工业界的关注,迅速开始在工业界应用开来。
受益于相关技术的发展,AIGC 相关的应用也开始从实验性逐渐向实用性转变,比如:
2007 年,纽约大学人工智能研究员罗斯·古德温(Ross Goodwin)装配的人工智能系统通过对公路旅行中的一切所见所闻进行记录和感知,撰写出世界第一部完全由人工智能创作的小说《1 The Road》。实现方式是通过训练一个可以生成任意长度文本的神经网络模型,将公路旅行中采集的图像、声音、地理位置等信息作为种子输入给模型来生成出文本内容。作为世界第一部完全由人工智能创作的小说,其象征意义远大于实际意义,整体可读性不强,拼写错误、辞藻空洞、缺乏逻辑等缺点明显。
2012 年,微软公开展示了一个基于深层神经网络(Deep Neural Network,DNN)的全自动同声传译系统,该系统在发布会现场自动将演讲者的英文演讲内容实时转换成了与他音色相近的字正腔圆的中文语音,效果流畅,赢得了参会人员的一片掌声。
可以看到随着技术的突破,AI 在图像识别、语音识别、自然语言处理等领域已经开始出现效果不错的应用,更多的普通用户开始接触到集成了这些 AI 能力的产品,比如:跨国语言翻译工具、人脸识别系统等等。但是,由于算法瓶颈的限制,AI 还无法较好地完成内容创作类型的任务,相关的应用非常有限,效果也有待提升。
3)快速发展(2010s-2020s):生成对抗网络提出和发展,AIGC 效果显著提升
2014 年,伊恩·古德费洛(Ian J. Goodfellow)等人提出了一种非监督机器学习的方法:生成对抗网络(Generative Adversarial Network,GAN),该方法由两个神经网络用相互博弈的方式进行学习,这种方法在图像生成方面效果显著。
随后,在生成对抗网络这个方向上产生了许多流行的框架:
2018 年,Andrew Brock 和 DeepMind 发布了 BigGAN,首次用生成对抗网络生成了具有高保真度和低品种差距的图像,生产的图像效果足以以假乱真。
2018 年,英伟达发布的 StyleGAN 模型可以自动生成图片。StyleGAN 算法的核心是风格转移技术或风格混合。它在面部生成任务中创造了新记录,除了生成面部外,它还可以生成高质量的汽车,卧室等图像。目前 StyleGAN 已经升级到第四代模型 StyleGAN-XL,其生成的高分辨率图片人眼难以分辨真假。
2019 年,DeepMind 发布了 DVD-GAN,它能够生成高分辨率和具备时间一致性的视频。DVD-GAN 将大型图像生成模型 BigGAN 扩展到视频领域,同时使用多项技术加速训练,它生成的视频效果在草地、广场等明确的场景下表现突出。
随着以生成对抗网络(Generative Adversarial Network,GAN)为代表的 AI 算法不断迭代更新,生成的图像效果提升显著,甚至逼真到人们难以分辨真假的地步。这让 AIGC 这个方向迎来了新时代,内容生成类应用也开始走到了普通用户面前,比如曾经风靡一时的视频换脸、真人变漫画特效等等。不过,这些被大多数普通用户感知到的应用场景还比较狭窄,用户还无法获得较大创作自由度。
4)破圈起飞(2020s-今):扩散模型突破,AIGC 出圈推向平民化并显现商业化前景
2015 年,Jascha Sohl-Dickstein 等人基于非平衡热力学提出了一个纯数学的生成模型:扩散模型(Diffusion Model,DM) 。参考:《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》2。此后,经过技术发展和实现,扩散模型可以应用于各种任务,如:图像去噪、图像修复、超分辨率成像、图像生成等等。例如,一个图像生成模型,经过对自然图像的扩散过程的反转训练之后,可从一张完全随机的噪声图像开始逐步生成新的自然图像。此外,扩散模型的算法还允许在图像生成过程中添加引导机制来控制生成结果,从而不需要重新训练整个模型就能满足模型的调优。但是,由于扩散模型通常直接在像素空间中运行,因此对模型进行调优往往要耗费上百 GPU 天,成本仍然是非常高的。
2021 年,Robin Rombach 等人所在的 CompVis 研究团队在扩散模型的基础上提出了一种潜在扩散模型(Latent Diffusion Model,LDM) 。参考:《High-Resolution Image Synthesis with Latent Diffusion Models》3。潜在扩散模型(LDM)是扩散模型(DM)的一个变体,它通过技术改进显著降低了模型训练和生成图像的计算成本,使得在有限的计算资源上运行模型成为了可能。
从 2022 年开始,基于潜在扩散模型的 AI 绘画产品纷纷推出。比如:
2022 年,OpenAI 推出了 DALL-E 的升级版本 DALL-E-2,主要应用于文本与图像的交互生成内容,用户只需要输入简短的描述性文字,DALL-E-2 即可创作出相应极高质量的卡通、写实、抽象等风格的绘画作品。
2022 年,美国初创公司 Midjourney Lab 推出的 AI 绘画工具 Midjourney,该工具架设在 Discord 频道上,使用方法很简单,进入 Midjourney 的 Discord 频道,在频道对话框输入自然语言提示词,系统就会在对话框里发送生成的图。该工具迅速流行起来,在一年的时间内就积累了上千万用户。
2022 年,Stability.ai 推出 Stable Diffusion 并将其开源,Stable Diffusion 在搭载了一定性能显卡的个人电脑即可驱动,且出图效果经过反复迭代有着显著改进,从而把 AIGC 创作最终推向平民化。
可以发现基于潜在扩散模型推出的 AI 绘画工具可准确把握文本信息进行创作,只需通过简单的提示词就能在数秒内生成高质量的图片,这种简易的交互方式和生产速度将 AIGC 的使用成本大大降低,而创作自由度却得到了极大提升。对普通用户来讲,简单的一句话,就能生成与之对应的高质量图像,这种『言出法随』的效果被大家称为『魔法』。伴随着大量用户的广泛认可,AIGC 随着 AI 绘画的火爆而出圈,开始显现出令人期待的商业化前景,国内外互联网巨头和独角兽纷纷下场。于是,很多人也开始把 2022 年称为 AI 绘画的元年。
2、Stable Diffusion 简介
如上文介绍,Stable Diffusion 也是一款在 2022 年发布的支持由文本生成图像的 AI 绘画工具。它主要用于根据文本的描述生成对应的图像,也可以应用于其他任务,如:对原图像内的部分遮罩区域进行重绘的内补绘制功能(Inpainting)、在原图像外部范围进行延伸画图的外补绘制功能(Outpainting)、在提示词(Prompt)引导下基于输入图像生成新图像的图生图功能等。
2.1、Stable Diffusion 模型
Stable Diffusion 最核心的部分是它的模型,如上文介绍 Stable Diffusion 模型是一种文本到图像的潜在扩散模型。
要理解 Stable Diffusion 所使用的潜在扩散模型背后的技术细节需要一定的算法技术基础,而探索这些细节并不属于本文的目的,我们在这里就不做过多的探讨了。
这里系列文章的内容主要是向大家介绍如何使用 Stable Diffusion 来进行 AI 绘画,大家了解一些相关的技术梗概会有助于大家后续使用 Stable Diffusion,所以我们在这里只用尽量简要的语言介绍一下扩散模型的大概过程,以帮助大家对它建立一个大概的印象:
1)扩散模型训练需要先找到一堆高质量的图像,训练时对每张图像按照高斯噪声公式一步一步来加噪点,直到整张图像变成一张全是噪点的图像(如下图从左到右的过程所示),这个训练的过程会记录所有步骤。接下来,就用神经网络的方式来反向学习如何从一个全是噪点的图像变成一张高清图像(如下图从右到左的过程所示)。

扩散模型训练过程
2)一旦完成训练得到了扩散模型,机器就可以通过噪点来对图像进行预测。这样一来,整个绘画的过程就是 AI 用一组随机噪点(随机数)来预测基于它们能画出一个什么样的图像。AI 就是从一堆凌乱的随机数中画出图像的,这个过程是一个大力出奇迹的过程,但厉害的是最终能产出清晰度和细节度非常高的图像。
Stable Diffusion 模型的发布经历了这样几个节点:
1)2021 年,在潜在扩散模型论文**《High-Resolution Image Synthesis with Latent Diffusion Models》**4相关的工作基础上,CompVis 团队与商业公司 Stability AI 5、Runway 6 合作,在 Stability AI 的资助和人工智能领域的非营利组织 LAION 7 的帮助下,基于大规模图文数据集 LAION-5B8 的一个子集的 512x512 的图像上训练出了 Stable Diffusion 模型的 v1 版本。并在后续,迭代发布了多个 v1.x 版本的 Checkpoint。
Stable Diffusion v1 项目开源发布在:https://github.com/CompVis/stable-diffusion。
2)2022 年,Stability AI 公司在上述的 Stable Diffusion 模型的基础上继续迭代和增强,并推出了 Stable Diffusion 模型的 v2 系列版本。Stability AI 同时也将该项目开源并推向了市场。
Stable Diffusion v2 项目开源发布在:https://github.com/Stability-AI/stablediffusion。
Stable Diffusion 模型是从无到有训练的大模型,其训练成本是相当高昂的。Stability AI 创始人兼 CEO Emad Mostaque 曾表示,训练该模型使用了 256 块英伟达 A100 显卡,耗费了 15 万机时,花费了 60 万美元的成本。
3)2023 年,Stability AI 公司又推出了 Stable Diffusion XL 版本。在这个版本中,可以使用更简短的提示词实现 AI 绘画,并且支持在图像中生成单词。此外,XL 版本还支持更强的图像组合和人脸生成,有着更优秀的视觉效果、真实感和美学提升。
2.2、Stable Diffusion 的产品策略
在当下流行的 AI 绘画工具中,Midjourney 和 Stable Diffusion 应该是风头最盛的,它们在产品策略上各有长处。
Midjourney 的厉害之处在于它通过 Discord 来构建自己 AI 绘画社区的巧思,这个策略一方面使得用户能够在社区互相学习提示词的使用技巧、快速生成高质量美图,从而激发用户的兴趣、刺激了产品的传播;另一方面通过庞大的用户积累了独有的数据集,从而可以根据用户需求针对性地训练模型并快速进行产品迭代,形成了正反馈循环。
Stable Diffusion 的厉害之处则在于它可以在大多数配备有适度 GPU 的电脑硬件上运行,并且开源了项目代码和模型权重。这样一来,开源社区的开发者就可以在它的基础上进行二次开发、做插件、做工具,这就有了如今结合 Stable Diffusion 流行起来的 Stable Diffusion WebUI、LoRA、ControlNet 等等开源项目。这就相当于给 Stable Diffusion 的发展增加了大量的盟友,极大的丰富了它的功能和特性。
对于想要使用 Stable Diffusion 来 AI 绘画的用户来说,开源也意味着更大的灵活性和自由度,我们可以借助 Stable Diffusion 丰富的相关模型和扩展插件来满足我们自己独特的 AI 绘画创作需求,这也是为什么我们选择写 Stable Diffusion 系列文章的重要原因之一。
2.3、Stable Diffusion 的绘图效果
夸了这么多,我们来看看 Stable Diffusion 的绘图效果:

港口

底下洞穴的水晶沉积物

甜美风小姐姐

韩风小姐姐

关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈
(全套教程文末领取哈)

👉AI绘画必备工具👈
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
