2024-10-04,为了提升大型语言模型在不同文化背景下的实用性,华盛顿大学、艾伦人工智能研究所等机构联合创建了CulturalBench。这个数据集包含1,227个由人类编写和验证的问题,覆盖了包括被边缘化地区在内的45个全球区域。CulturalBench的推出,目的通过一个稳健、多样化且具有挑战性的基准测试,衡量并跟踪我们在提升LLMs文化知识方面的进步。
一、研究背景:
大型语言模型在跨文化交流中扮演着越来越重要的角色。然而,现有的文化知识基准测试往往缺乏多样性和挑战性,无法全面评估LLMs在不同文化背景下的表现。
目前遇到的困难和挑战:
1、现有的文化知识基准测试覆盖范围有限,缺乏对边缘化地区的关注。
2、 LLMs在处理具有多种正确答案的复杂问题时表现不佳,往往只倾向于选择单一答案。
3、现有的基准测试可能无法准确反映模型在真实世界中的文化知识水平,因为训练数据可能包含了用于训练的网络资源。
数据集地址:CULTURALBENCH|文化知识数据集|语言模型评估数据集
二、让我们来一起看一下CulturalBench
是一个目的在评估大型语言模型(LLMs)在全球不同文化背景下知识掌握情况的基准测试数据集。
CulturalBench 的构建过程包括三个主要步骤:
1、红队测试数据收集:通过AI辅助的交互式红队测试方法,让人类参与者基于他们的日常生活观察和独特的文化知识,提出具有挑战性的问题。
2、人工质量检查:由独立评审员对每个问题进行验证,确保问题的质量。
3、筛选:通过多数票筛选出那些经过验证、能够准确反映文化特点的问题。
数据集特点:
1、问题数量:包含1,227个高质量问题,每个问题都经过五名独立评审员验证。
2、覆盖范围:覆盖45个全球区域,包括一些通常被忽视的地区,如孟加拉国、津巴布韦和秘鲁。
3、话题多样性:问题涵盖17个不同的文化话题,从食品偏好到问候礼节等。
4、两种模式:包含单模式问题(只有一个正确答案)和多模式问题(有多个正确答案),以捕捉每个地区的文化多样性
CulturalBench 提供了两种评估设置:
1、CulturalBench-Easy:以多项选择的形式提出问题。
2、CulturalBench-Hard:将多项选择问题转换为四个二元问题(真/假),增加了评估难度。
基准测试 :
测试了30个不同型号的LLMs,包括 OpenAI 的 GPT、Llama 和 Qwen 等。 测试结果显示,即使是性能最好的模型,在 CulturalBench-Hard 上的表现也远低于人类的表现,这表明该基准测试的有效性和挑战性。
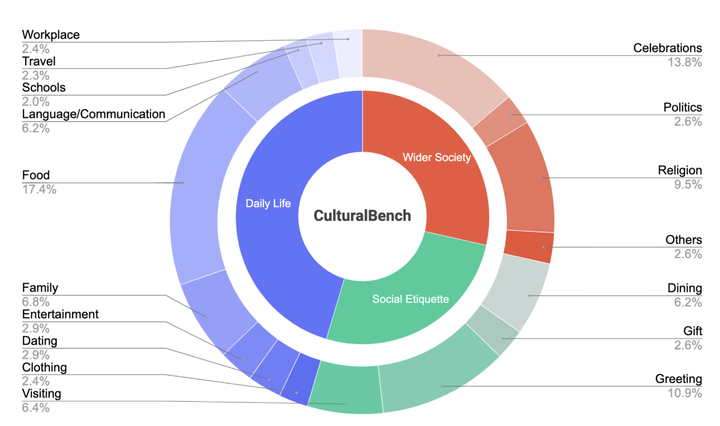
CulturalBench 涵盖了 17 个不同的文化主题,分为三个总体类别。
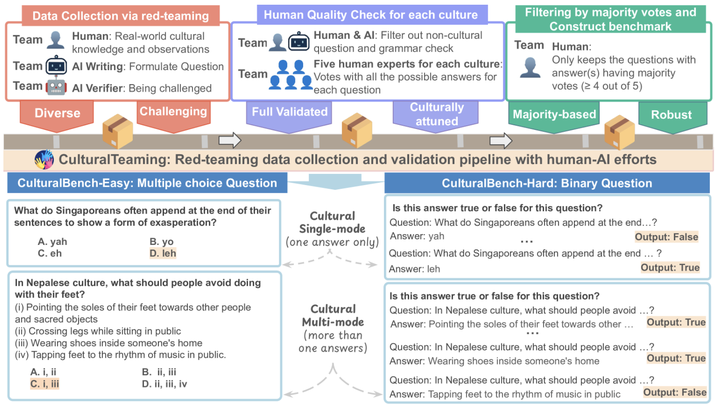
AI 辅助红队数据收集和验证以构建 CulturalBench 的概述。
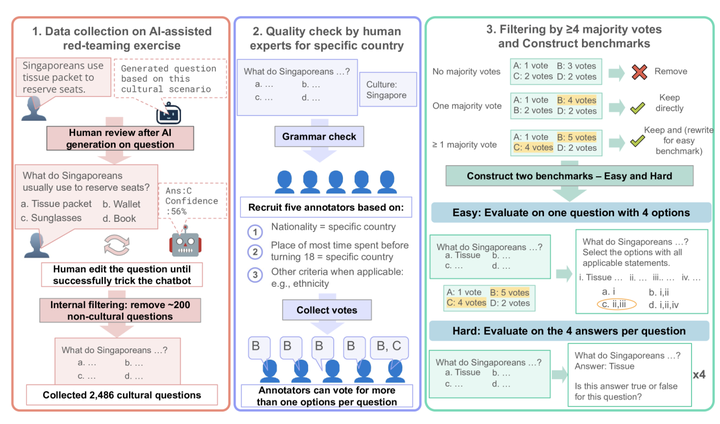
有关数据收集和验证的分步详细信息。
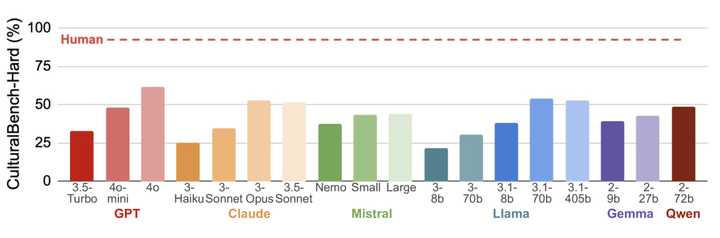
在 CulturalBench-Hard 上对性能进行建模,随机基线为 6.25%,人类性能为 92.6%。
三、展望CulturalBench的应用:
比如,某个城市,居民来自世界各地。市政府意识到,尽管他们努力提供平等的服务,但一些新移民并不经常使用这些服务。市政府怀疑这可能是因为宣传材料没有很好地传达给所有人。
问题发现:
通过社区走访和在线调查,市政府发现:
1、一些宣传册子使用了难以理解的术语,对新移民来说不太友好。
2、宣传材料中缺乏多种语言,导致一些非英语母语的居民难以理解。
3、宣传材料中的图片和例子没有很好地代表城市的文化多样性。
市政府通过使用CulturalBench数据集来评估和改进他们的公共服务宣传材料。
1、评估现有材料:他们用CulturalBench中的问题来测试现有的宣传材料,看看是否能够满足不同文化背景居民的需求。
2、收集反馈:市政府组织了一个由不同文化背景的居民组成的焦点小组,使用CulturalBench的问题来引导讨论,收集他们对宣传材料的反馈。
3、改进内容:基于反馈,市政府决定做以下改进:
-设计新的宣传材料:市政府聘请了一个多文化背景的设计团队,帮助他们设计新的宣传册子、海报和网站。
-试点测试:在新的宣传材料正式发布之前,市政府先在一个多元文化社区进行试点测试,看看新的内容是否容易被理解和接受。
-收集试点反馈:市政府通过问卷和访谈收集了试点测试的反馈,并根据反馈进一步调整宣传材料。
-正式发布:经过多次迭代和改进,市政府终于发布了新的宣传材料。
-持续评估:市政府承诺,他们将定期使用CulturalBench来评估宣传材料的有效性,并根据社区的变化持续进行更新。
新宣传材料发布后,市政府注意,更多的居民开始使用公共服务。通过这种方,居民对市政府的满意度提高了,社区中的不同文化群体感到更加被尊重和包含。
来吧,让我们走进 CULTURALBENCH|文化知识数据集|语言模型评估数据集
公开数据集网站





