在当今数据驱动的世界中,时间序列预测在多个领域扮演着关键角色。从医疗保健分析师预测患者流量,到金融分析师预测股市趋势,再到气候科学家预测环境变化,准确的时间序列预测都至关重要。然而,传统的预测模型面临着三个主要挑战:
- 数据获取难度:对于新兴模式的预测,相关训练数据往往难以获取或收集。例如,LOTSA(最大的公开时间序列数据集)仅包含约270亿个时间点,而相比之下,NLP领域的数据集如RedPajama-Data-v2包含数十万亿个标记。
- 泛化能力受限:传统模型难以在不同领域和应用场景之间迁移,每个新场景都需要重新训练模型。
- 数据效率低下:在训练数据有限的情况下容易出现过拟合现象。

论文创新与改进
1. 架构创新
TSMamba对传统Transformer架构进行了重大改进:
- 线性复杂度实现:- 传统Transformer:输入长度的二次方复杂度- TSMamba:实现线性复杂度,显著提升处理效率- 通过选择性状态空间实现信息的高效过滤与保留
- 双向编码器设计:- 前向编码器:捕捉因果关系依赖- 后向编码器:提取反向时间关系- 时间卷积模块:对齐前向和后向表示
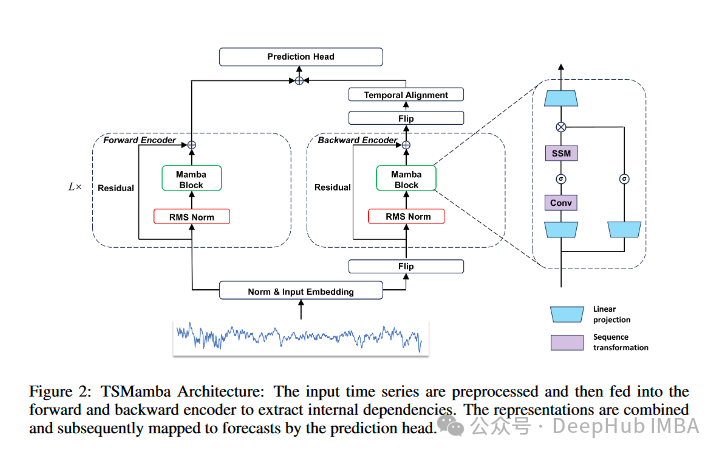
2. 两阶段迁移学习方法
TSMamba采用创新的两阶段迁移学习方法,有效解决了训练数据不足的问题:
第一阶段 - 骨干网络训练:
- 利用预训练的Mamba语言模型初始化
- 通过分片式自回归预测优化骨干网络
- 训练输入嵌入以适应时间序列数据
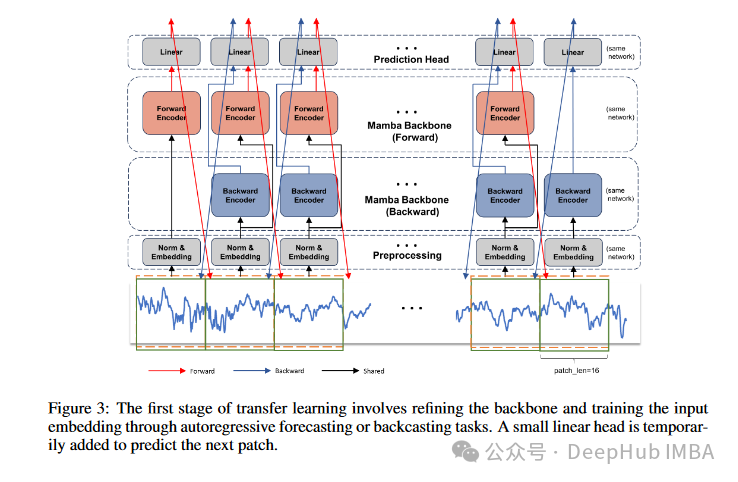
第二阶段 - 长期预测优化:
- 恢复完整TSMamba架构
- 加载第一阶段训练的骨干网络和嵌入层
- 使用差异化学习率策略进行训练
3. 通道压缩注意力机制
为处理多变量时间序列的复杂性,TSMamba引入了创新的通道压缩注意力模块:
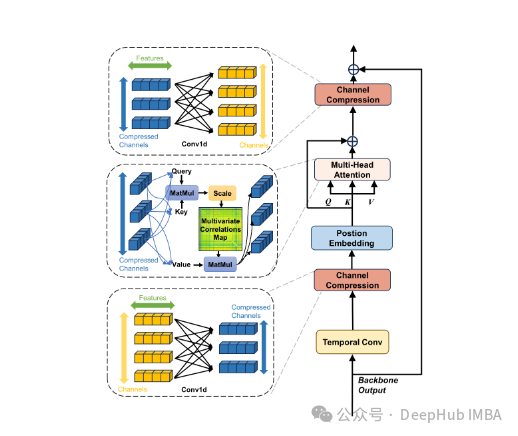
该模块包含四个关键步骤:
- 时间卷积:对齐不同通道的时间维度
- 通道压缩:将通道数从D压缩到⌈log₂(D)⌉
- 注意力计算:在压缩通道维度上提取依赖关系
- 通道恢复:将压缩表示映射回原始通道数
这种设计既保证了对跨通道依赖关系的有效捕捉,又避免了过度拟合的风险。
实验评估与性能分析
实验设置
TSMamba在实验中采用以下配置:
- 3层编码器
- 768维嵌入大小
- 固定512长度的输入序列
实验评估分为两个主要场景:零样本预测和全量数据训练。
零样本预测结果
基准数据集评估
在ETTm2和Weather两个标准数据集上进行了全面测试:
- 预测周期:- 短期:96小时- 中期:192小时- 长期:336小时、720小时
- 评估指标:- 均方误差(MSE)- 平均绝对误差(MAE)

关键发现
- 在长期预测(336和720小时)场景表现突出
- 与使用更大规模预训练数据的模型相比保持竞争力
- 在平均性能上达到领先水平,尤其是在数据效率方面
全量数据训练结果
实验数据集
在三个主要数据集上进行了详细评估:
- ILI (流感数据集)
- ETTm2 (电力负载数据集)
- Weather (气象数据集)
性能对比
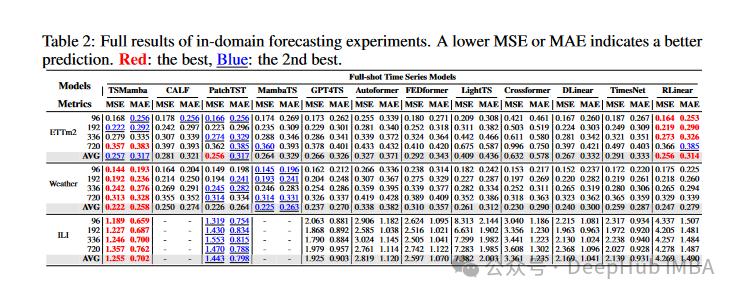
主要结果:
- 整体性能:- 相比GPT4TS提升了15%的性能- 超越了专门的时间序列预测模型PatchTST- 在大多数预测长度上保持最优表现
- 分数据集表现:- ETTm2数据集:平均MSE降低至0.257,MAE降低至0.317- Weather数据集:平均MSE达到0.222,MAE达到0.258- ILI数据集:显著优于所有基准模型
- 稳定性分析:- 在不同预测长度下保持稳定表现- 预测结果的方差较小,显示出较高的可靠性
消融研究
为验证各个模块的有效性,进行了详细的消融实验:
- 通道压缩注意力模块的影响:- 完整模型vs去除压缩机制- 不同压缩比率的效果对比
- 两阶段训练策略的贡献:- 单阶段vs两阶段训练的效果对比- 不同预训练策略的影响
- 双向编码器的作用:- 仅使用前向编码器的效果- 双向编码器带来的性能提升
这些实验结果证实了TSMamba各个创新组件的必要性和有效性。
技术细节
论文没给源代码,我们按照论文的思路进行一个简单的复现
关键技术实现
1. 模型核心组件
预处理模块
classPreprocessModule(nn.Module):
def__init__(self):
super().__init__()
# 实例归一化
self.norm=ReverseInstanceNorm()
# 1D卷积实现输入嵌入
self.embedding=nn.Conv1d(
in_channels=1,
out_channels=model_dim,
kernel_size=patch_length,
stride=patch_length
)通道压缩注意力模块
classChannelCompressedAttention(nn.Module):
def__init__(self, dim, num_channels):
super().__init__()
# 时间卷积层
self.temporal_conv=nn.Conv1d(dim, dim, kernel_size=3, padding=1)
# 通道压缩
compressed_channels=ceil(log2(num_channels))
self.channel_compress=nn.Conv1d(num_channels, compressed_channels, 1)
# 注意力层
self.attention=nn.MultiheadAttention(dim, num_heads=8)
# 通道恢复
self.channel_expand=nn.Conv1d(compressed_channels, num_channels, 1)2. 优化策略
-
两阶段训练流程:- 第一阶段:优化骨干网络- 第二阶段:微调预测头- 使用差异化学习率
-
损失函数设计:
defhuber_loss(y_pred, y_true, delta=1.0):
residual=torch.abs(y_pred-y_true)
quadratic_loss=0.5residual.pow(2)
linear_loss=deltaresidual-0.5*delta.pow(2)
returntorch.mean(torch.where(residual<=delta,
quadratic_loss,
linear_loss))
总结
TSMamba通过其创新的架构设计和训练策略,成功解决了传统时间序列预测模型面临的多个关键问题。其主要贡献包括:
- 实现了线性复杂度的计算效率
- 提出了有效的两阶段迁移学习方法
- 设计了创新的通道压缩注意力机制
这些创新为时间序列预测领域提供了新的研究方向和实践指导。随着技术的不断发展,我们期待看到更多基于TSMamba的改进和应用,推动时间序列预测技术继续向前发展。
论文:
https://avoid.overfit.cn/post/7813f935a8584f4199d146bce348f787