1 认识大模型
大模型是人工智能发展的一个里程碑,人工智能包括机器学习,机器学习包括监督学习、无监督学习和强化学习,深度学习神经网络也是机器学习的一个分支,生成式人工智能是深度学习的一个子集,ChatGPT和Stable Diffusion都是其中的一部分,大模型就可以说是生成式人工智能。
大模型即为Foundational Models,基础模型,是一类具有大量参数、能在极为广泛的数据上进行训练、并适用于多种任务的预训练深度学习模型。
大模型的训练分为三个阶段:
- 预训练(Pre-training):大量学习语料,但并未学习领会人类意图;
- 监督微调(SFT,Supervised Fine Tuning):学习领会人类意图,但可能并不符合人类偏好;
- 基于人类反馈的强化学习(RLHF,Reforcement Learning from Human Feedback):学习如何使得回答符合人类偏好。
大模型分为大预言模型(LLM)和多模态模型,多模态模型又可以分为CV模型、音视频模型等。
大模型的工作流程分为两步走,第一步是分词和词表映射,第二步是自回归生成文本。
认识了大模型的基础概念后,就可以开始使用,在使用过程中我们会有更多的需求,这就需要对大模型进行改进:
- 如果大模型可以解决我们的问题,但生成内容的质量有待提升,我们可以尝试改进提问方式(prompt、CoT、ToT等);
- 如果在我们业务场景中,大模型总是在编造一些内容,也就是出现幻觉,我们可以考虑将检索和大模型结合起来减少幻觉(RAG,Retrieve Augmented Generation);
- 如果我们需要大模型在内容生成上稳定地遵循特定风格或者格式,则可以考虑微调大模型。
2 提示词工程
直接提问,也成为零样本提示(Zero-Shot Prompting),提示需要简洁、具体且逻辑清晰,适用于目标明确、问题简单、答案确定且唯一的场景;
增加示例,也成为少样本提示(Few-Shot Prompting),让大模型按照我们的具体格式要求进行输出,或者提供进一步推理的参考;
分配角色,让大模型在特定角色视角下生成回答,从而得到不同风格的答案;
拆解复杂任务,让大语言模型分步来思考问题,成为思维链(Chain-of-Thought Prompting,CoT),不仅寻求答案,还要求模型解释其给出答案的步骤,思维链也分为没有示例的零样本和有示例的少样本;
使用提示词框架,可以得到更加专业、准确的回答。
3 大模型插件
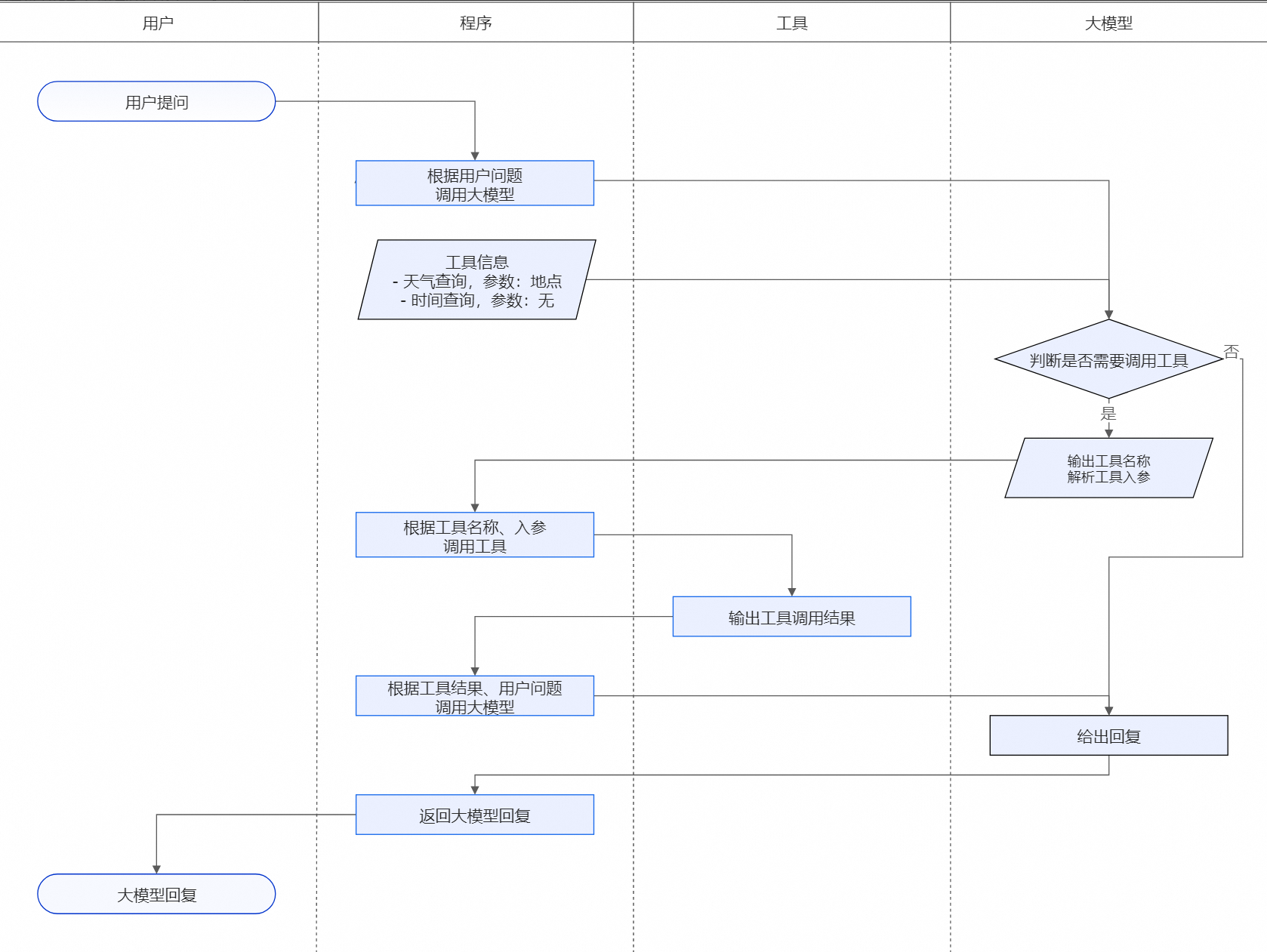
大模型应用使用插件的决策流程和人类使用工具的流程是一样的。首先接收输入,判断是否需要使用工具及选择合适的工具,然后使用工具并获得返回结果进行后续推理生成。
4 RAG
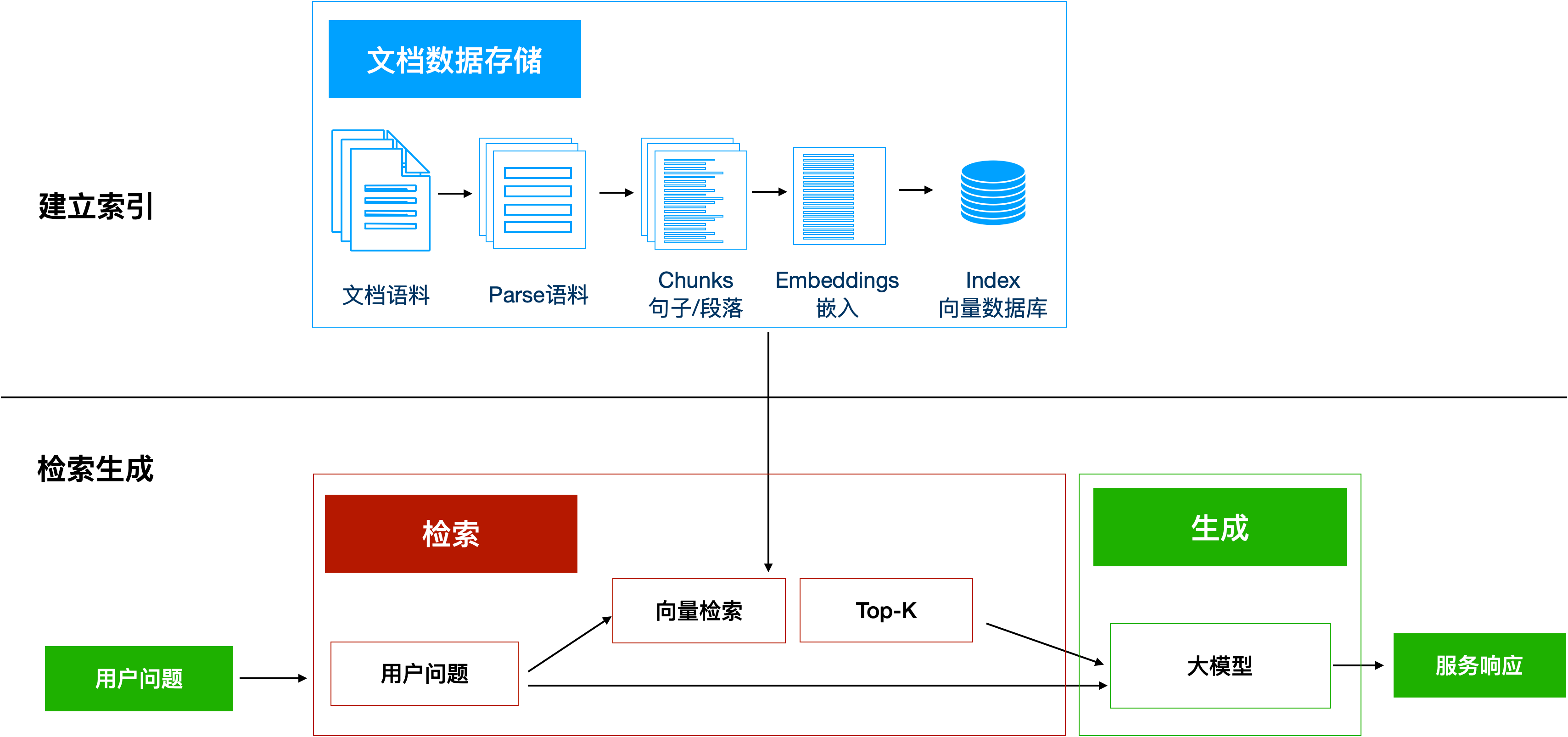
RAG(Retrieval Augmented Generation),即为检索增强生成方法,包括三个步骤,建立索引、检索、生成,首先建立知识库索引,大模型检索知识库,根据提示词和检索到的资料生成答案。
建立索引:首先要清洗和提取原始数据,将 PDF、Docx等不同格式的文件解析为纯文本数据;然后将文本数据分割成更小的片段(chunk);最后将这些片段经过嵌入模型转换成向量数据(此过程叫做embedding),并将原始语料块和嵌入向量以键值对形式存储到向量数据库中,以便进行后续快速且频繁的搜索。这就是建立索引的过程。
检索生成:系统会获取到用户输入,随后计算出用户的问题与向量数据库中的文档块之间的相似度,选择相似度最高的K个文档块(K值可以自己设置)作为回答当前问题的知识。知识与问题会合并到提示词模板中提交给大模型,大模型给出回复。这就是检索生成的过程。
改进RAG,可以从下面这些思路进行:
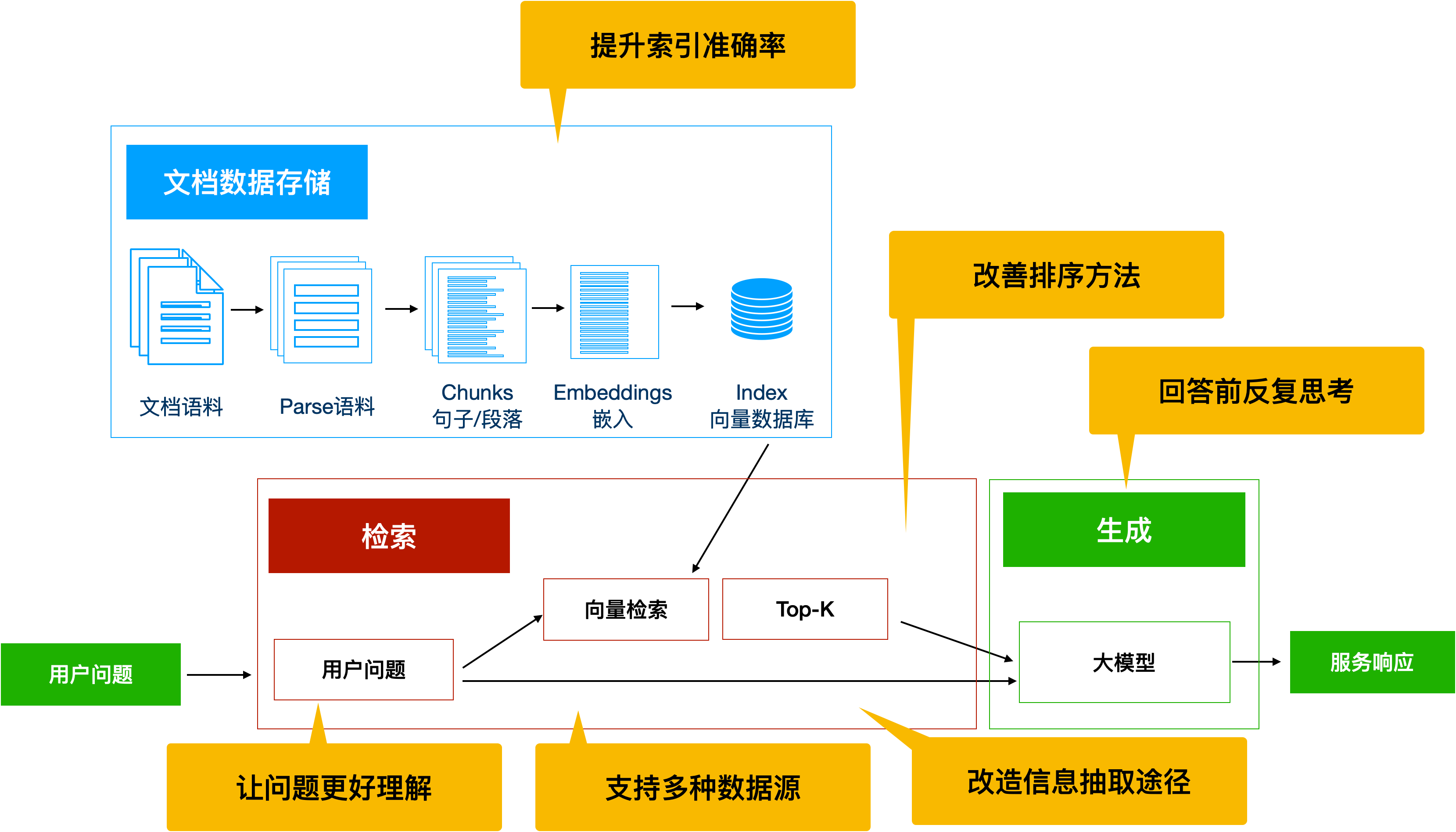
- 提升索引准确率:优化原始信息的提取、优化chunk切分模式、滑动窗口检索、选择合适的词向量模型和排序模型;
- 让问题更好理解:通过多轮对话完善用户问题、让大模型转述用户问题再进行RAG问答、多路召回(大模型从不同角度进行问题改写并整合答案)、问题分解、假设答案;
- 改造检索渠道:优化向量相似度匹配算法、让大模型直接判断;
- 回答前反复思考:Self-RAG,让大模型对自己的回答进行相关性、是否有幻觉以及是否已解答的判决,通过反思优化答案;
- 从多种数据源中获取资料:传统RAG只是分析文本文档,还可以推广到结构化的数据;
Agent
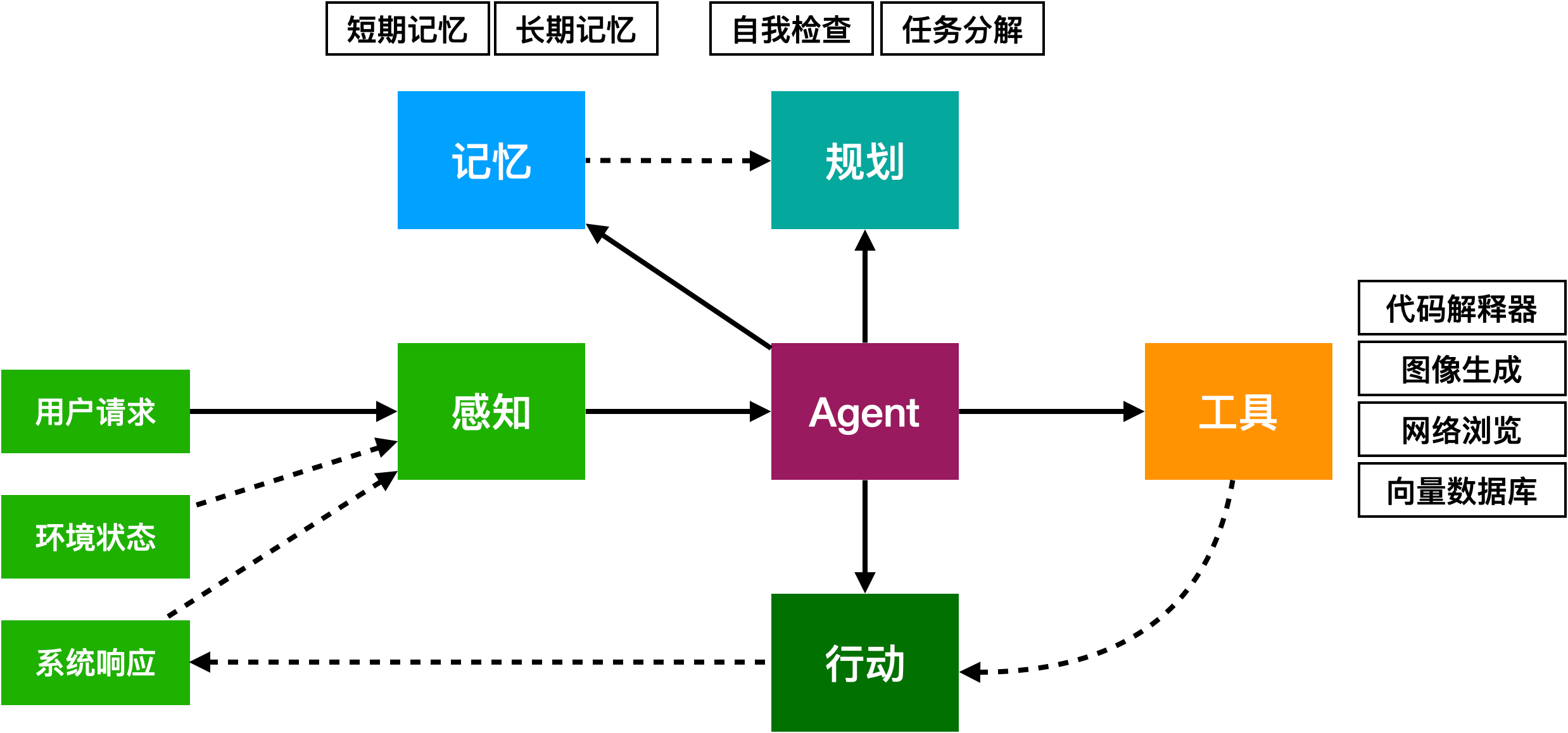
大模型Agent是指基于大语言模型的,能使用工具与外部世界进行交互的计算机程序。
Agent可以进行合作,成为Multi-Agent,进行十分复杂的任务。
大模型微调
微调就是再预训练的基础上,使用特定领域的数据对模型进行进一步的训练,从而让模型更擅长处理你想要解决的问题,微调可以使得大模型适应特定领域风格,或者掌握特定系统接口,做到格式化输出。
微调相较于从头训练,能够提高效率和降低成本;
微调要求使用特定领域的高质量数据,同时需要配置合适的参数。
从调整参数量的大小这个角度,可以把微调分为全参微调与高效微调:
- 全参微调(Full Fine Tuning):是指再预训练模型的基础上进行全量参数微调的模型优化方法,会对所有参数进行调整;
- 高效微调(PEFT,Parameter-Efficient Fine-Tuning):只微调部分参数,却能达到与全量微调相似的效果;
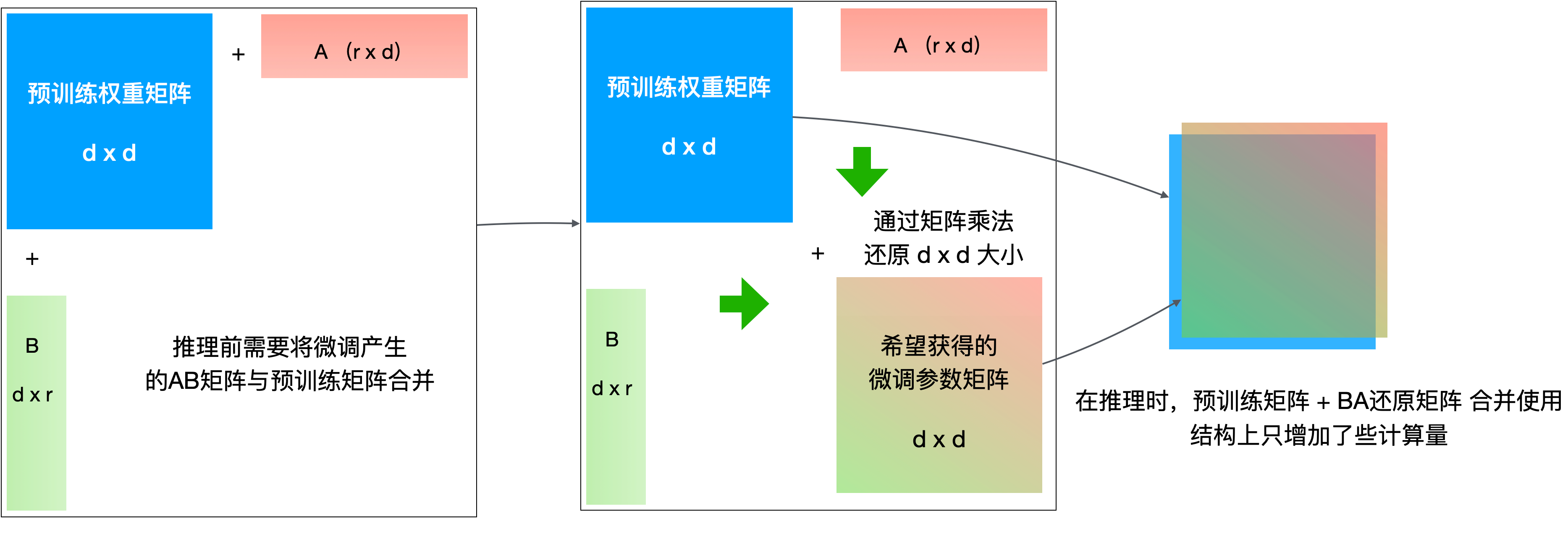
LoRA(Low-Rank Adaptation)低秩适应,不对原模型做微调,而是通过学习原模型降维后得到的低秩矩阵来近似模型权重矩阵的参数更新,训练时只优化低秩矩阵参数,通过降维再升维的操作来大量压缩需要训练的参数。
LoRA在所有微调方式里面效果最好。
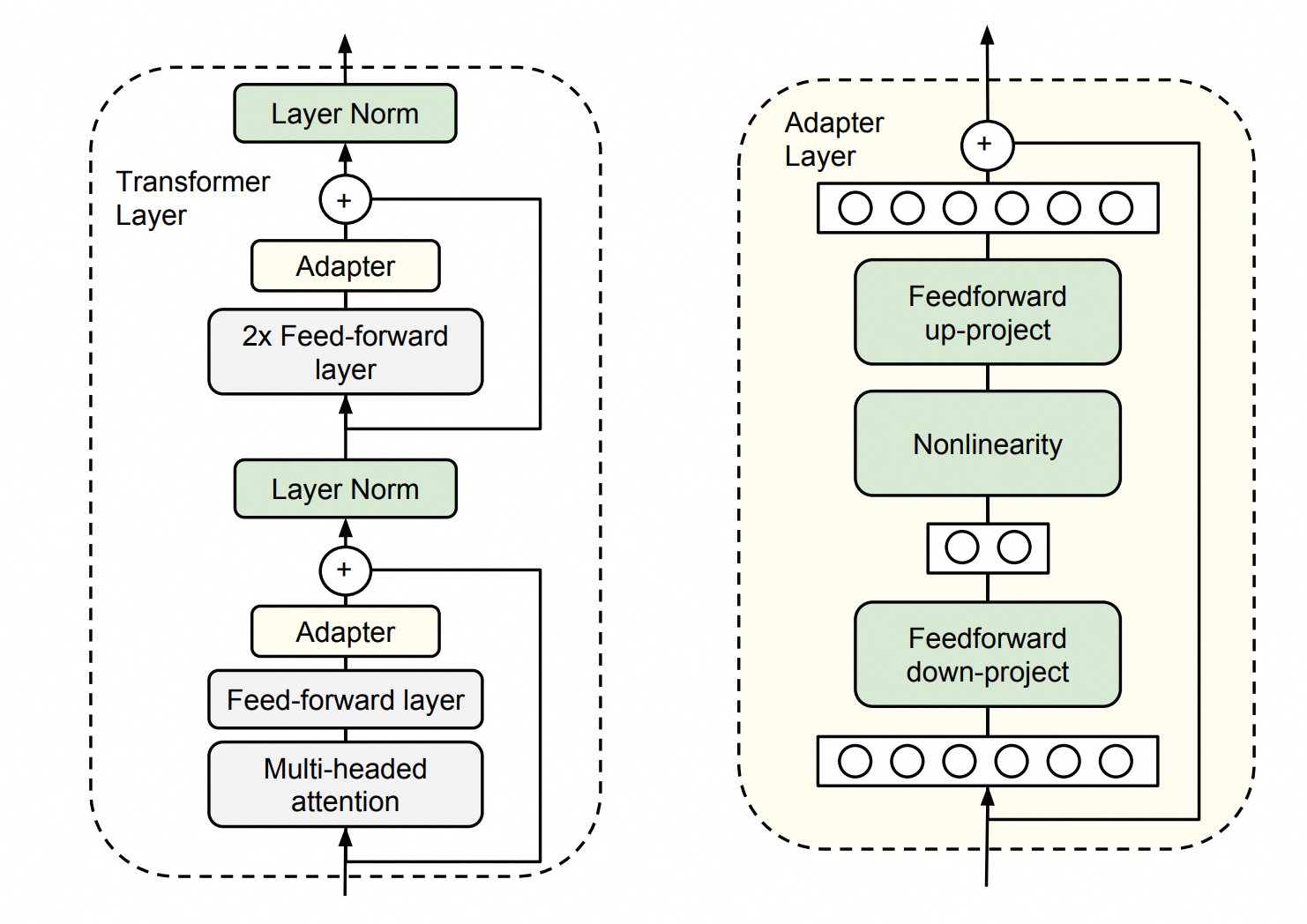
Adapter Tuning是在原有的模型架构上,在某些位置之间插入Adapter层,微调时只训练这些层,而原先参数不会参与训练,虽然效果不错,但是会增加推理成本。
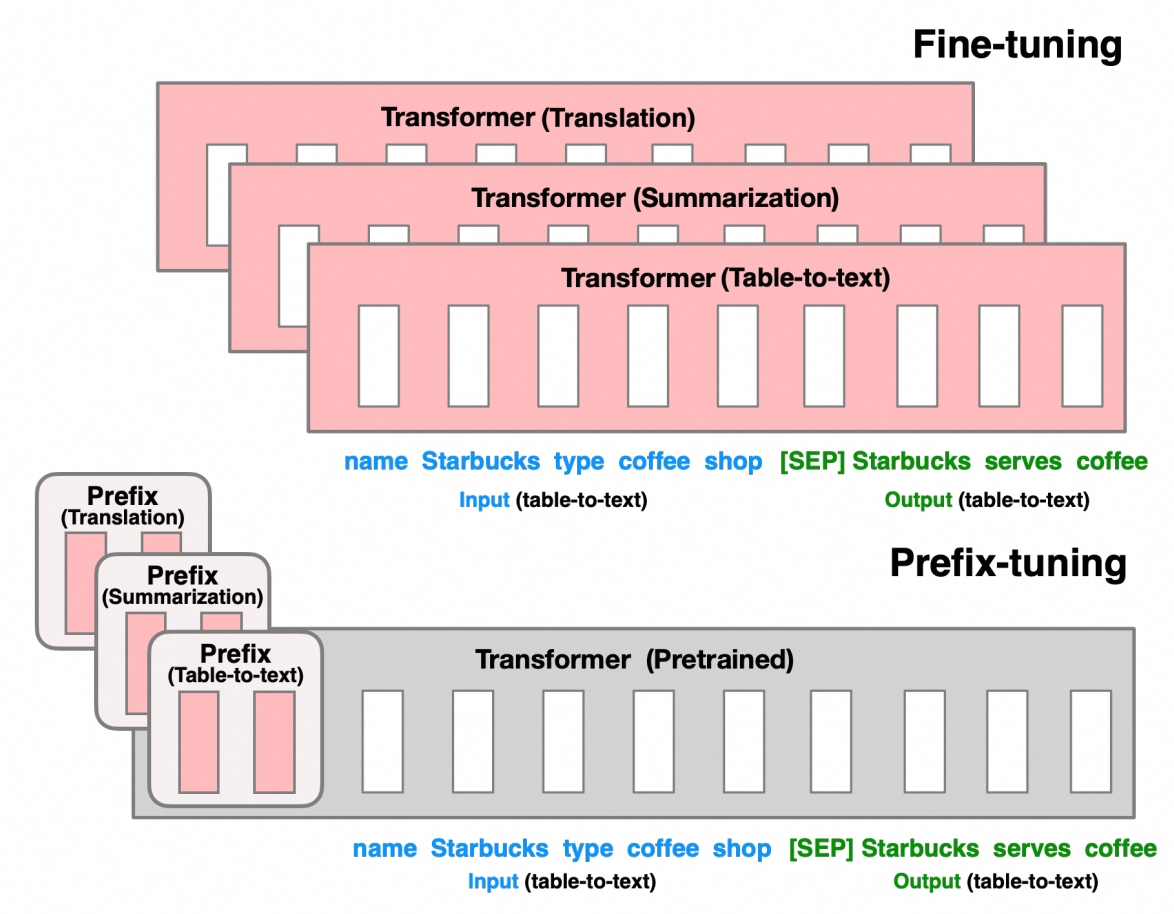
Prefix Tuning是在给定文本数据的token前构造一段固定长度任务相关的虚拟token作为为前缀Prefix,训练时只更新这个虚拟token部分的参数,这些前缀向量可以视为对模型进行引导的指令,帮助模型理解即将处理的任务。
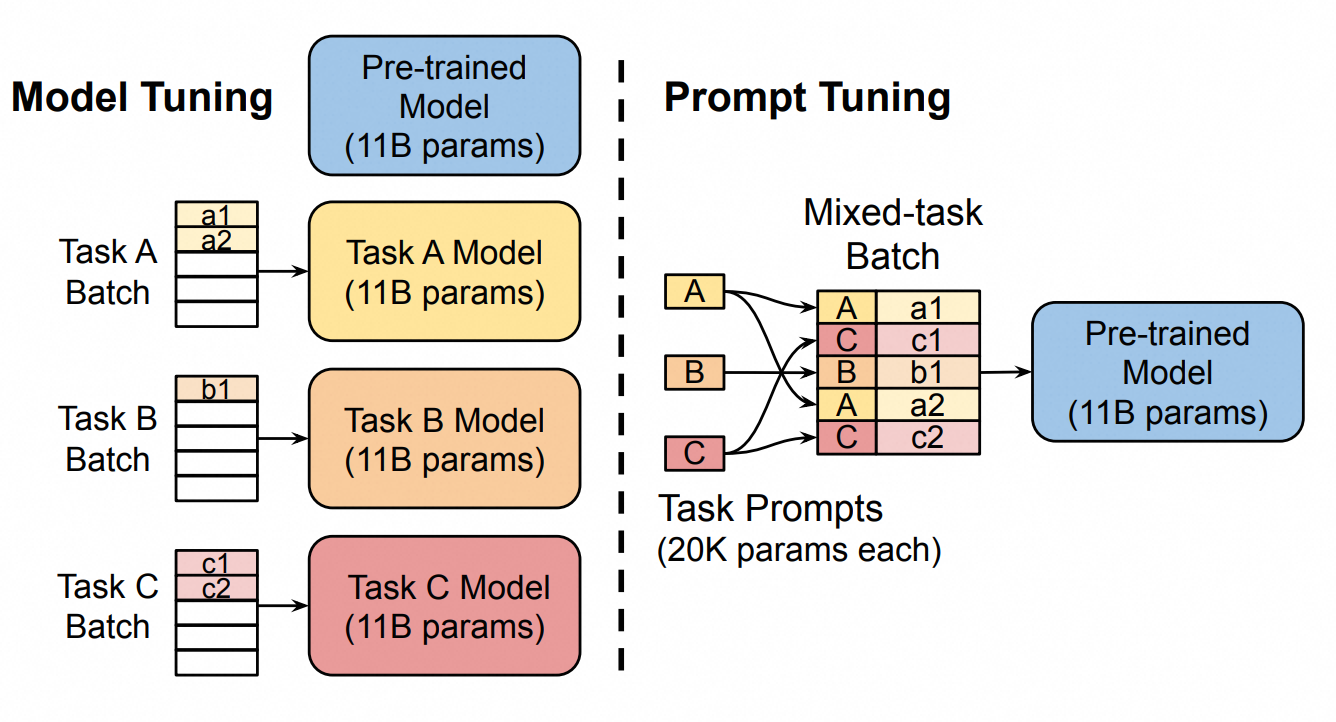
Prompt Tuning和上面的方法相似,是在输入浅入向量中加入prompt tokens向量,针对每种任务设定不同的提示词向量,使得模型可以很好地区分并适配不同任务,但是这两种方法由于引入了前缀序列,会占用处理下游任务的序列长度,消耗的token会更多。