导读
提取多种多样字符的信息有利于在日常生活和工业生产中落实标准化和规范化的要求。友思特 Neuro-T的OCR模型 基于无代码深度学习算法,轻松实现了精准高效的字符检测。
在现代生活和工业领域,字符检测技术应用正变得越来越重要。无论是在日常生活中对扫描文档的自动识别,还是在工业生产线上的自动化检测,准确提取和解析字符信息都是关键。
然而,这一任务面临着诸多挑战。首先,字符的多样性和变异性,如字体、排版和手写体的不同,使得识别过程复杂且易出错。其次,实际应用中常见的数据噪声和格式不规范问题,会影响检测的准确性。再者,大规模数据处理需要高效的实时性能,这对系统的处理能力提出了严格要求。
针对这些难点,友思特技术人员基于Neuro-T的OCR模型,使用深度学习的方式,通过训练强大的模型和优化算法,结合前置传统图像处理算法,能够在各种复杂环境下实现高效的字符检测,为生活和工业应用提供了可靠的技术支持。

友思特Neuro-T支持的深度学习模型类型
友思特 Neuro-T 支持九种 不同的深度学习模型:
|-----------------------|-------------------------------------------------------------------------------------|-------------------------------------|
| 监督学习 |||
| 分类 |  | 将图像分类为多个缺陷类别(一副图像只能包含一类缺陷) |
| 将图像分类为多个缺陷类别(一副图像只能包含一类缺陷) |
| 分块 分类 |  | 通过将高分辨率图像分割成小块来进行分类(一幅图像可能包含多类缺陷) |
| 通过将高分辨率图像分割成小块来进行分类(一幅图像可能包含多类缺陷) |
| 实例 分割 |  | 在像素级检测缺陷的精确形状和位置(能在一张图像中检测出多个缺陷) |
| 在像素级检测缺陷的精确形状和位置(能在一张图像中检测出多个缺陷) |
| 目标 检测 |  | 识别物体数量并确定其位置 |
| 识别物体数量并确定其位置 |
| OCR 字符 识别 |  | 识别图像中的文字(英文、数字、特殊符号) |
| 识别图像中的文字(英文、数字、特殊符号) |
| 旋转 |  | 自动将原始图像旋转到正确方向 |
| 自动将原始图像旋转到正确方向 |
| GAN 对抗生成网络 |  | 生成与真实缺陷相似的人工缺陷图像 |
| 生成与真实缺陷相似的人工缺陷图像 |
| 无监督学习 |||
| 异常 分类 | 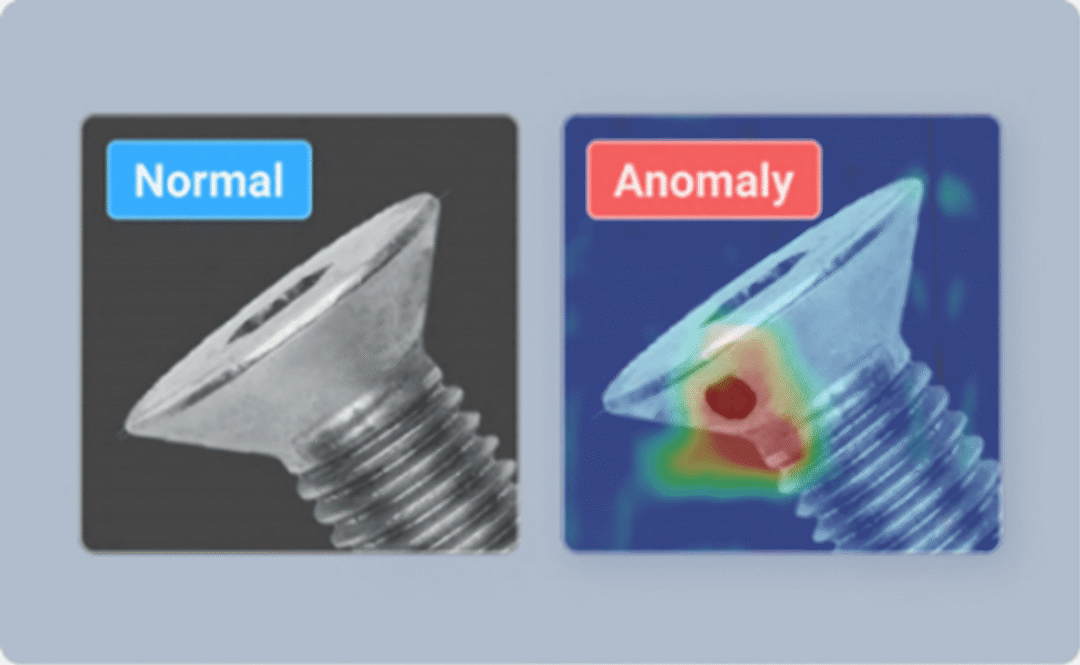 | 以热力图的形式为二元分类提供基础,仅对正常图像进行训练 *正常/缺陷 |
| 以热力图的形式为二元分类提供基础,仅对正常图像进行训练 *正常/缺陷 |
| 异常 分割 | 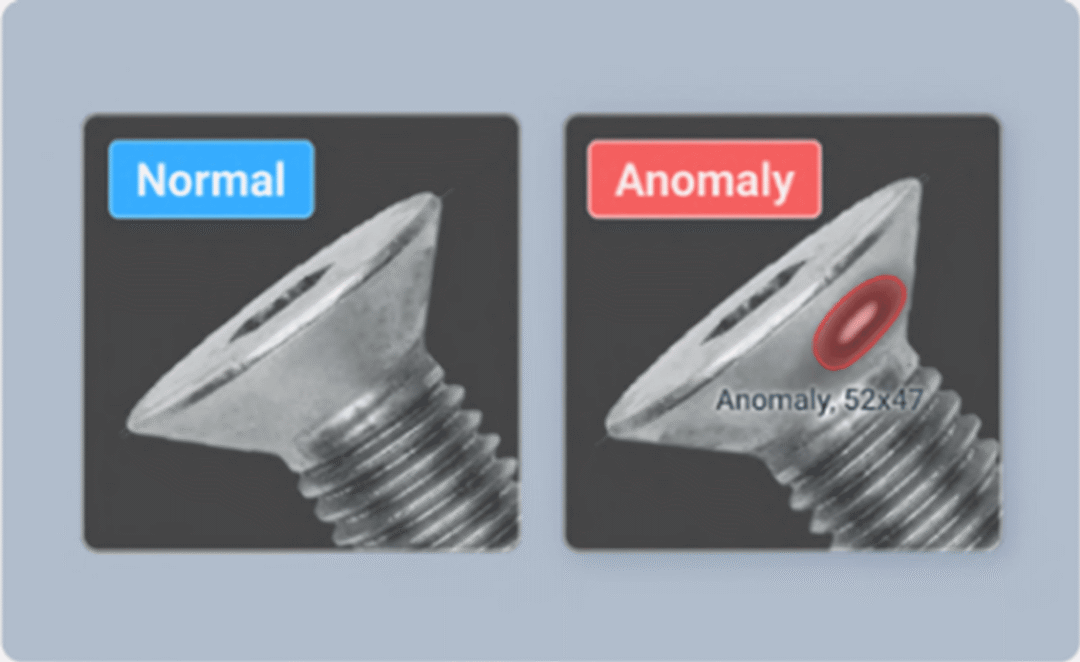 | 像素级别检测缺陷区域,仅对正常图像进行训练 |
| 像素级别检测缺陷区域,仅对正常图像进行训练 |
Neuro-T的OCR模型训练字符检测模型的具体操作步骤
1. 新建项目→新建数据集→导入图像数据
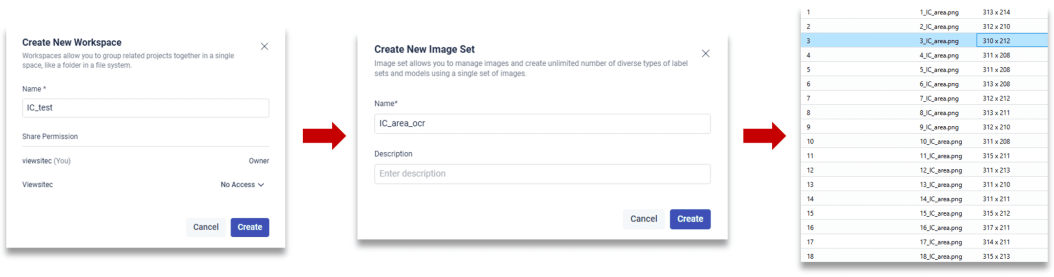
2. 创建标签集→选择模型类型(OCR)
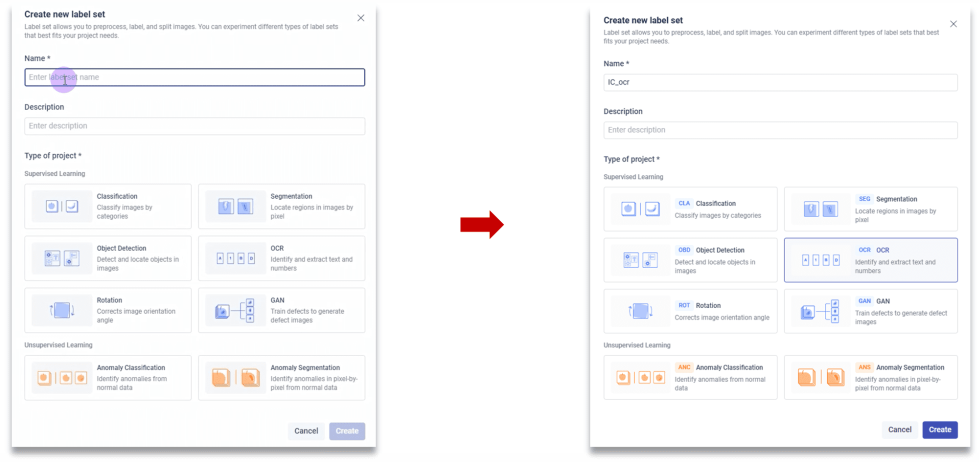
3. 标注数据
可以使用手动标注或自动标注的方式对图像进行字符内容的标注。
(1)手动标注
- 将图像中的文字旋转到合适的朝向;
- 选择绘制矩形框、设置大小写类型以及字符排布方向;
- 在图像中需要标注的字符位置绘制矩形框并填写字符内容。

(2)自动标注
Neuro-T自动学习平台的OCR深度学习模型提供了两种自动标注方式:
①预训练模型自动标注:
使用Neuro-T平台自带的预训练OCR模型对数据集进行自动批量快速标注,再微调标注结果。
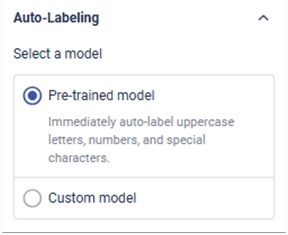
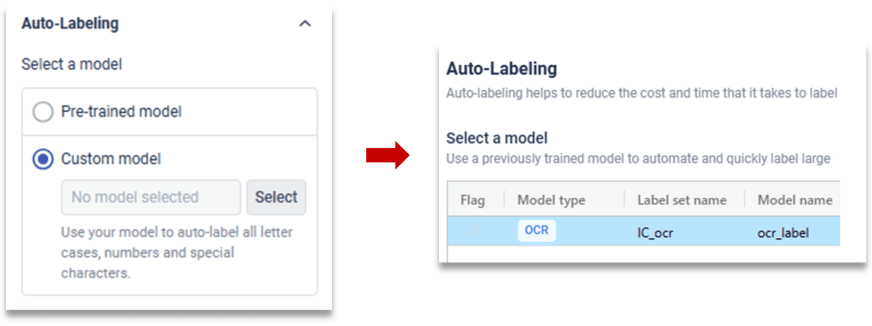
②自定义模型自动标注:
手动标注部分图像来训练OCR模型,选择用于标注的OCR模型,再应用到想要标注的图像上即可。
4. 划分训练集和测试集
自动或手动按预设比例将图像集分配为训练集和测试集。

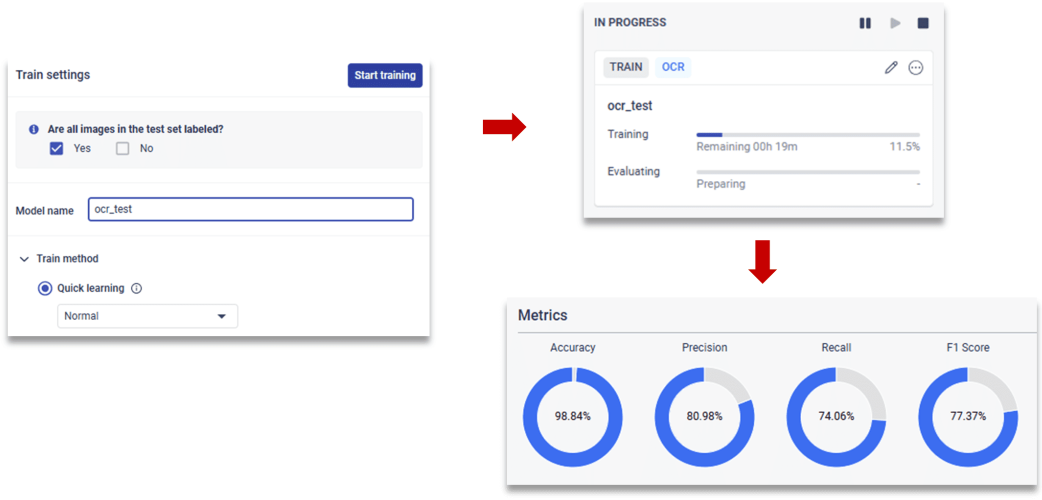
5. 训练生成OCR模型并查看模型结果
在模型训练页面输入训练的模型名字即可进行OCR模型训练,无需参数设置,最后可以查看OCR模型的评估指标结果。
正则匹配技术
通过OCR模型识别客户检测对象中的字符内容,往往还没能解决客户的需求。客户需要的是自动化从中提取分析 出所需要的信息,并且排除冗余信息 ,或者替换 部分检测信息为其他字符内容。这个时候,我们通常会选用正则匹配的方式来为客户实现。
正则匹配(正则表达式匹配)是一种用于在文本中查找特定模式的技术。正则表达式(regex)是一种强大的文本处理工具,可以用于匹配、搜索、替换文本。它广泛应用于数据验证、文本处理、数据清理等场景。
-
例如"\d{3}-\d{4}-\d{4}"用于匹配类似"020-1234-5678"的电话号码信息。
-
例如"^a-zA-Z0-9._%+-+@a-zA-Z0-9.-+\.a-zA-Z{2,}$"用于匹配邮箱地址。
客户案例
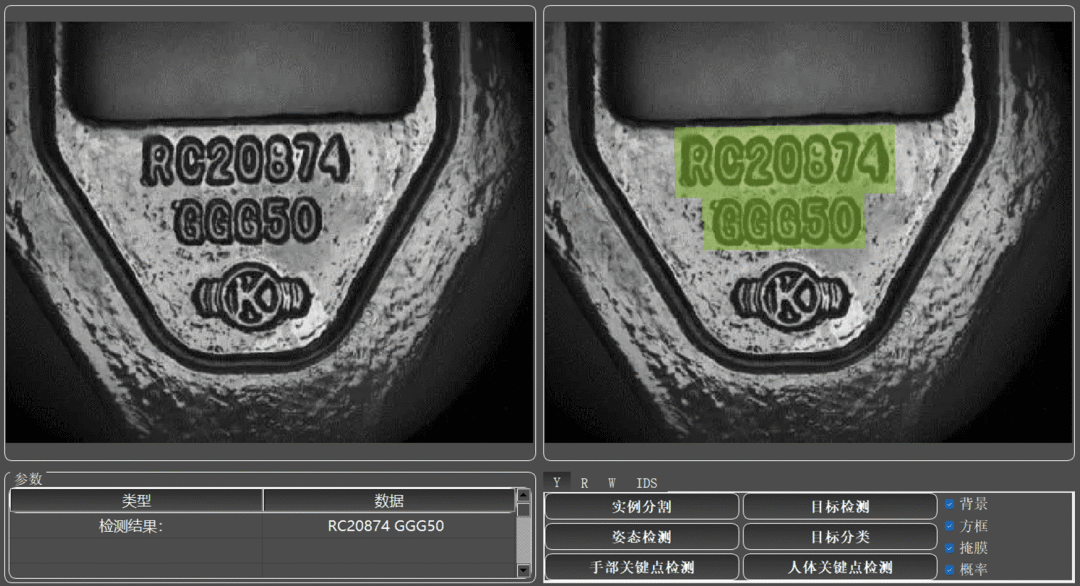
场景1:工件的蚀刻/凹刻字符检测
金属工件表面通过物理或化学反应形成的凹陷字样的字符检测需求。由于字符内容与背景无明显颜色差异,需要搭配一定的光源进行打光来凸显字符内容的轮廓,再行调用OCR模型进行字符检测。

场景2:医药溶媒字符检测
检测医疗袋装溶媒上面的字符,并使用正则匹配的方式,从中提取出溶媒种类、容量、浓度等信息传输至上位机。


场景3:物流纸箱打标字符检测
物流纸箱位于传送带上实时传送,架设 IDS 相机进行实时动态拍摄并返回上位机字符识别结果。由于纸箱粗糙表面存在噪点对字符识别造成干扰,且字符印刷颜色较浅,直接识别存在一定的难度,因此采用包括灰度化、Gamma校正、提高全局对比度、二值化、高通滤波和开运算等一系列图像处理操作,得到的图像再调用OCR模型进行检测,返回检测结果。
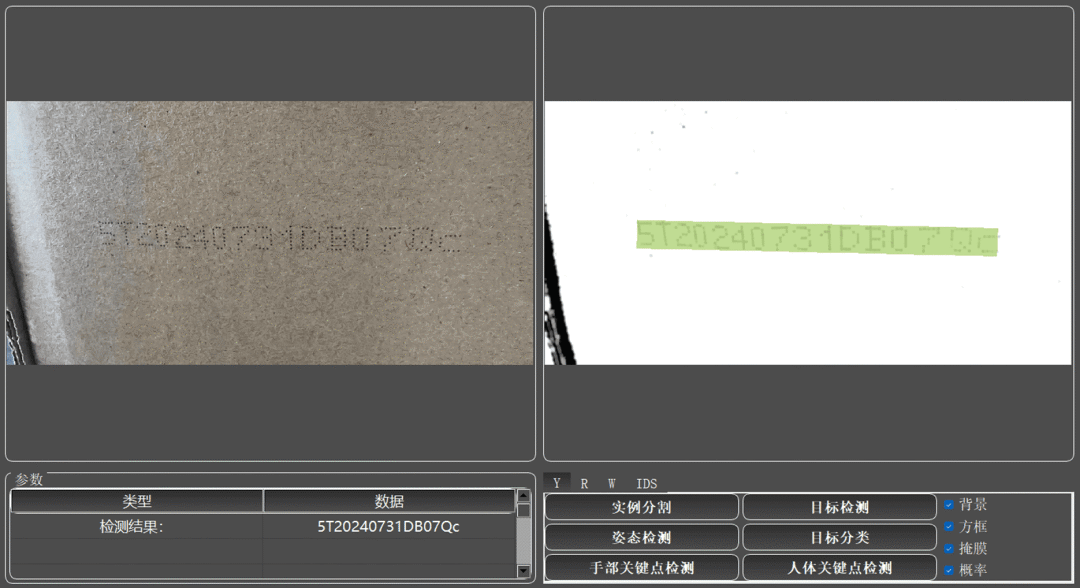
场景4:饮料包装生产日期检测
检测易拉罐底部或盒装饮料顶部的印刷字符,并从中提取出产品的生产日期。


其余常见场景
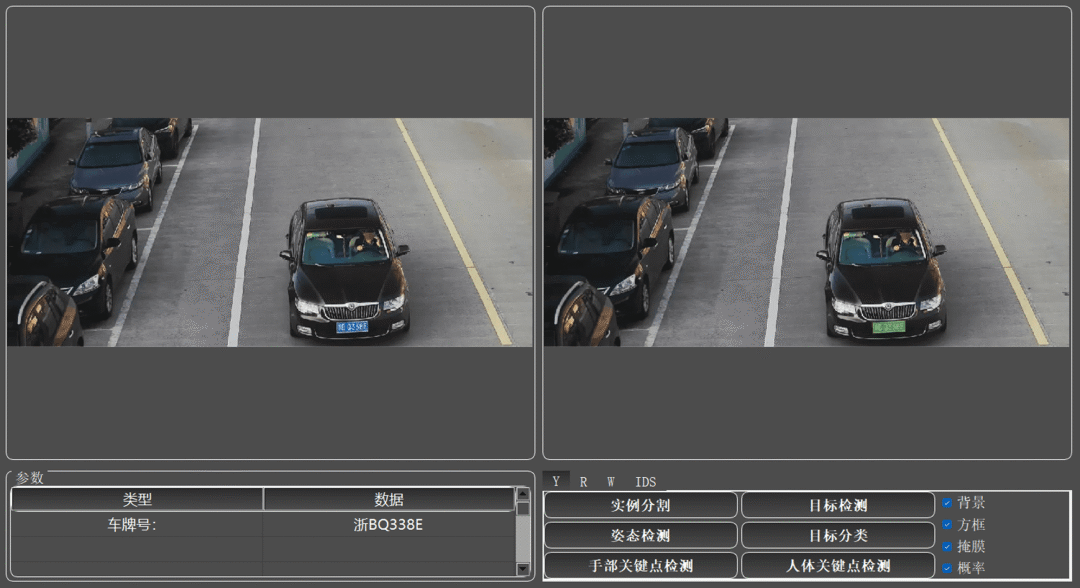
①车牌识别:

②高铁票识别:
通过正则匹配的方式从检测到的字符数组中匹配提取出包括站点、时间、座位等信息。

* 客户现场真实数据保密,替代图片来源网络,侵删。
友思特字符检测系统套装
Neuro-T

Neuro-T 使用简单的图形用户界面,通过自动优化深度学习模型结构和训练参数来创建出性能最佳的模型,无需任何深度学习经验,即可运行自己的深度学习项目。在系统中,Neuro-T 是用于训练模型的核心工具。
2D 工业相机

友思特 2D 工业相机结合了支持USB3视觉标准的高质量全局快门传感器技术 和具有成本效益的uEye XCP相机平台,是流行的USB2接口的uEye LE相机系列的最佳、高性能和长期替代品。借助友思特自研视觉软件 VST-2D,对接IDS相机的实时图像流,即可获取PCB的实时图像数据。
了解更多? 欢迎探索丰富案例:https://viewsitec.com/neurocle/