爬取研究中心的书目
现在,想要把如下网站中的书目信息爬取出来。
案例一 耶鲁
Publications | Yale Law School
分析网页,如下图所示,需要爬取的页面,标签信息是"<p>",所以用 items=soup.find_all("p")

代码如下:
python
import requests
from bs4 import BeautifulSoup as bs
from openpyxl import Workbook
url="https://law.yale.edu/china-center/publications/recent-staff-publications"
webfile=requests.get(url)
webfile.encoding="utf-8"
data=webfile.text
soup=bs(data,"html.parser")
soup.prettify()
items=soup.find_all("p")
for i in items:
print(i.get_text())完善代码如下:
python
import requests
from bs4 import BeautifulSoup as bs
from openpyxl import Workbook
import re
wb=Workbook()
ws=wb.active
wfile=open("bool.txt","w",encoding="utf-8")
url="https://law.yale.edu/china-center/publications/recent-staff-publications"
webfile=requests.get(url)
webfile.encoding="utf-8"
data=webfile.text
soup=bs(data,"html.parser")
soup.prettify()
items=soup.find_all("p")
# 正则表达式匹配模式
pattern1 = r'([^,\n"]+), "([^"]+),"\s*([^,\n]+)'
pattern2 = r'([^,]+(?: and [^,]+)*), "([^"]+),"'
'''
正则表达式匹配模式:
([^,]+(?: and [^,]+)*):匹配作者名。这个模式匹配一个或多个名字,由"and"连接。[^,]+匹配一个或多个非逗号字符,(?: and [^,]+)*是一个非捕获组,匹配零个或多个"and"后跟一个或多个非逗号字符的模式。
"([^"]+),":匹配文章名。这个模式匹配引号内的任何字符,直到遇到闭合的引号和逗号。
([^,\n"]+):匹配作者名。这个模式匹配一个或多个非逗号、换行符和左引号的字符序列。[^,\n"]是一个字符集,表示匹配除了逗号、换行符和左引号之外的任何字符。+表示匹配一个或多个这样的字符。
"([^"]+),":匹配文章名。这个模式匹配以左引号开始,以右引号结束的任何字符序列,并且确保文章名后面跟着一个逗号。
([^,\n]+):匹配期刊名。这个模式匹配一个或多个非逗号和换行符的字符序列。
'''
for i in items:
info=i.get_text()
# 查找所有匹配项
matches = re.findall(pattern1, info)
if len(matches)>0:
print(matches)
for m in matches:
print(m,sep=",",file=wfile)
wfile.close()将txt文本导入excel即可。原因在于正则表达式中得到的列表中的信息,有的似乎是tuptle类型,导致openpyxl无法输入xlsx表格中。所以采用了txt文本方式。
即可完成。
案例二 哈佛
爬取哈佛大学费正清中心出版书籍的信息时候,标签信息是class="article-container entry-content clear",所以用:item1=soup.find_all(attrs={"class":"article-container entry-content clear"})

所以,爬取代码如下:
python
'''
下面这段代码,爬取哈佛大学费正清中心出版书籍的信息
'''
import requests
from bs4 import BeautifulSoup as bs
from openpyxl import Workbook
wb=Workbook()
ws=wb.active
for page in range(1,9):
url=f'https://fairbank.fas.harvard.edu/research/publications/page/{page}/'
webFile=requests.get(url)
webFile.eocoding="utf-8"
data=webFile.text
soup=bs(data,'html.parser')
soup.prettify()
##item1=soup.find_all(attrs={"class":"uagb-post__title"})#提取书本标题信息
##for i in item1:
## print(i.get_text())
##
##
##item2=soup.find_all(attrs={"class":"ast-excerpt-container ast-blog-single-element"})#提取书目介绍信息
##for k in item2:
## print(k.get_text())
item3=soup.find_all(attrs={"class":"article-container entry-content clear"})#在网络页面中,找到的整个的文本
for m in item3:
info=m.get_text()
row1=info.split("\n")
row2=list(filter(lambda x:len(x)>1,row1))#过滤掉空字符串。
ws.append(row2)#worksheet中添加的是列表,然后把列表中的元素挨个放到了xlsx表格中。
wb.save("bool.xlsx")
即可完成。
一日一图
代码如下:
python
"""
使用Python中的turtle模块绘制一个壮观的太阳系图是一个有趣且具有挑战性的任务
"""
import turtle
import math
# 设置屏幕
screen = turtle.Screen()
screen.bgcolor("black")
screen.title("Solar System")
# 创建太阳
sun = turtle.Turtle()
sun.hideturtle()
sun.penup()
sun.goto(0, -200)
sun.pendown()
sun.color("yellow")
sun.begin_fill()
sun.circle(50)
sun.end_fill()
# 行星数据(名称,距离太阳的距离(单位:像素),大小(单位:像素))
planets = [
("Mercury", 35, 5),
("Venus", 72, 10),
("Earth", 98, 10),
("Mars", 152, 7),
("Jupiter", 279, 30), # 简化大小,实际应更大
("Saturn", 449, 25), # 简化大小,实际应更大
# "Uranus" 和 "Neptune" 由于距离太远,在这个比例下可能无法很好地显示
]
# 绘制行星和轨道
orbit_color = "gray"
planet_color = ["gray", "yellow", "blue", "red", "orange", "gold", "lightblue"] # 对应行星的颜色,实际应根据行星选择
for i, (name, distance, size) in enumerate(planets):
# 绘制轨道
orbit_turtle = turtle.Turtle()
orbit_turtle.hideturtle()
orbit_turtle.speed(0)
orbit_turtle.penup()
orbit_turtle.goto(0, 0)
orbit_turtle.pendown()
orbit_turtle.color(orbit_color)
orbit_turtle.width(2)
orbit_turtle.circle(distance)
orbit_turtle.hideturtle()
# 绘制行星
planet_turtle = turtle.Turtle()
planet_turtle.hideturtle()
planet_turtle.speed(0)
planet_turtle.penup()
# 计算行星在轨道上的位置
angle = 360 * i / len(planets) # 均匀分布行星
x = distance * math.cos(math.radians(angle))
y = distance * math.sin(math.radians(angle)) - 200 # 减去太阳的高度
planet_turtle.goto(x, y)
planet_turtle.pendown()
planet_turtle.color(planet_color[i % len(planet_color)]) # 循环使用颜色
planet_turtle.begin_fill()
planet_turtle.circle(size)
planet_turtle.end_fill()
planet_turtle.write(name, align="center", font=("Arial", 8, "normal"))
planet_turtle.hideturtle()
# 隐藏turtle光标
turtle.done()
turtle.tracer(False)图片如下:
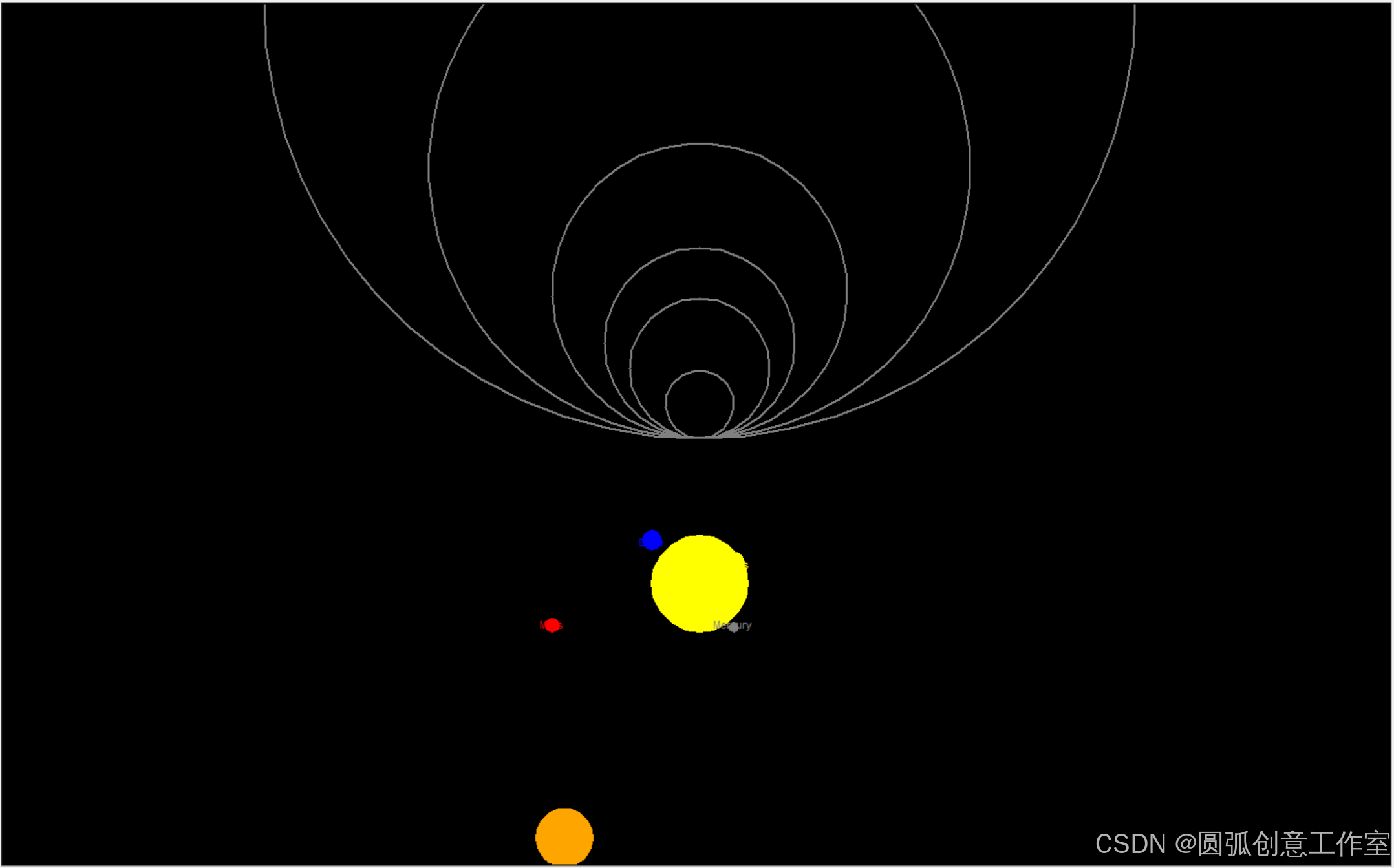
即可完成。