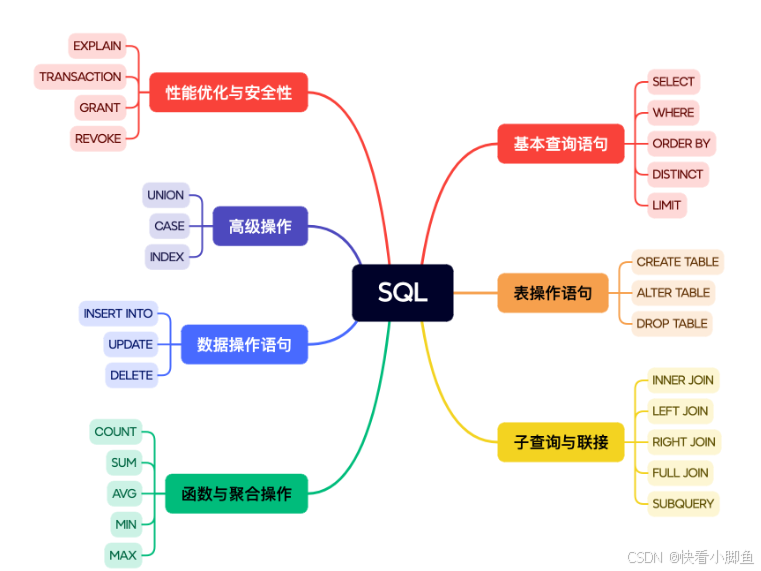
SQL语法
①常用的数据库本身的操作
sql
# 显示数据库列表
show databases;
# 使用某个数据库
use twbpm_dev;
# 创建一个数据库
create database db_test;
# 删除一个数据库
drop database if exists db_test;
# 显示数据库中所有的表
show tables;
# 查看MySQL的版本
select version();
show variables like 'version';②创建操作
sql
# 创建表
create table testTable(
id int(19) not null primary key ,
name varchar(50) not null ,
address varchar(100),
phone char(11)
);
create table 新表 as select * from 旧表
# 创建索引
create index i_testIndex on testTable(name);
# 创建视图
create view v_testView as select * from testTable;③新增操作
sql
# 插入数据
insert into testTable value (10000001,"张三","湖南省长沙市xxxxxxxx",12345678643);
insert into testTable values (10000001,"张三","湖南省长沙市xxxxxxxx",12345678643),(10000002,"李四","广东省深圳市xxxxxxxx",12345456789);
# 查询结果当新增
insert into testTable select * from testTable01;
# 批量插入大量数据
LOAD DATA INFILE '/path/to/data.txt' //读取文件
INTO TABLE testTable //选择目标表
FIELDS TERMINATED BY ',' //指定文件中字段分隔符
ENCLOSED BY '"' //在""中的字符都会被当做一个列数据
LINES TERMINATED BY '\n' //指定行分隔符
IGNORE 1 LINES //忽略第1行的数据
(column_list); //要插入的列,可以不写默认为全部列为什么LOAD DATA比逐行INSERT效率要高?

④更新、删除操作
sql
# 更新
update testTable set name = 'mike' where id = '11110011';
update testTable set name = 'amy'; //如果不加条件会把所有的数据的name行更新为amy
# 删除表数据
delete from testTable; //如果不加条件会把所有的数据都删除(索引、表结构不会变)
# 删除索引
drop index if exists i_testIndex on testTable;
# 删除表本身
drop table if exists testTable;
# 删除视图
drop view if exists vivw_name;⑤排序操作
sql
# 排序
select * from testTable
order by id , phone desc; //先按照id升序排序,如果id相同的则按照phone降序排序⑥修改操作
sql
# 添加一个新的列
alter table testTable
add new_column varchar(255);
# 删除一个列
alter table testTable
drop column column_name;
# 修改列数据类型
alter table testTable
alter column new_column char(11);⑦Limit、In、Union
sql
# limit
select * from testTable limit 3; //一个参数的时候是返回数据的前3行
select * from testTable limit 2(pageNum),3(pageSize);//两个参数的时候是分页,pageNum页码,pageSize页大小
# in
select * from testTable where id in (value1,value2.....、也可以接子查询、列表、集合)
# union //union的两边必须要是相同的列
SELECT column1, column2, ...FROM table1
UNION //union会去重
SELECT column1, column2, ...FROM table2;
# union all
SELECT column1, column2, ...FROM table1
UNION ALL //union all会保留所有的数据
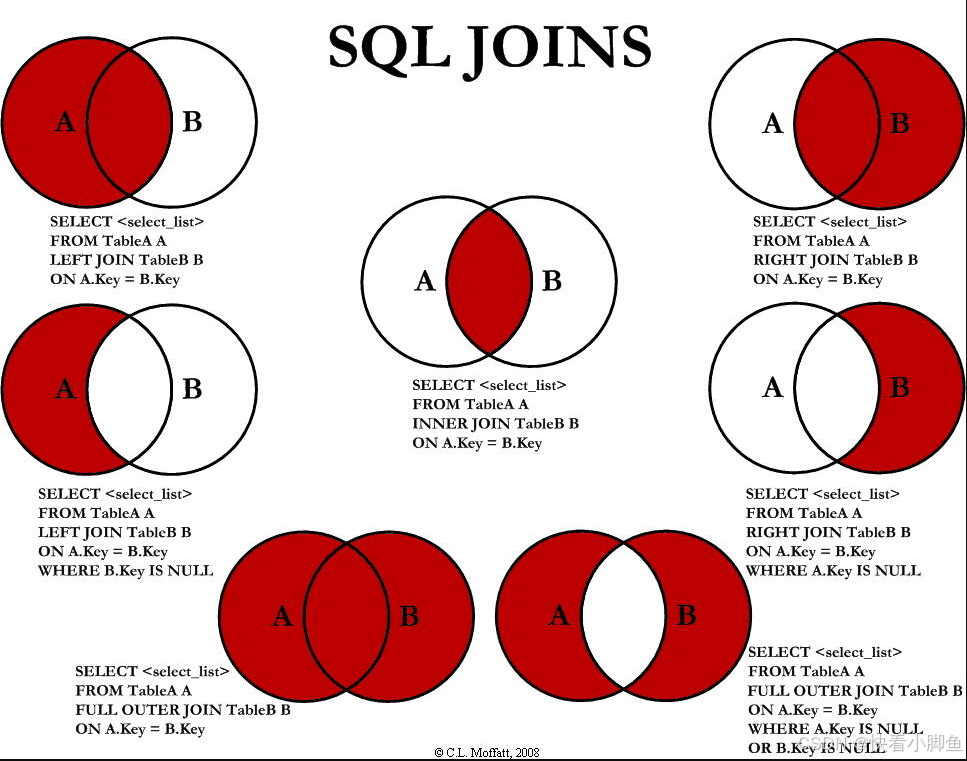
SELECT column1, column2, ...FROM table2;⑧连接操作
⑨XML文件中的标签
XML
<!--select标签--> 作用:与mapper接口对应,并且指定返回数据类型
<select id="selectByPrimaryKey" resultType="com.exzample.bean.User">
select ....
</select>
<!--if标签--> 作用:test进行判断,如果条件满足,则会把标签内的sql语句拼到最终查询语句中
<select id="selectByPrimaryKey" resultType="com.exzample.bean.User">
select * from product
<if test="name!=null">
where name like concat('%',#{name},'%')
</if>
</select>
<!--where标签--> 作用:当where标签中没有一个if标签成立时,where会被去掉
<select id="listProduct" resultType="com.exzample.bean.User">
select * from product
<where>
<if test="name!=null">
and name like concat('%',#{name},'%')
</if>
<if test="price!=null and price!=0">
and price > #{price}
</if>
</where>
</select>
<!--foreach标签--> 作用:循环遍历集合(item:单个元素 collection:集合名字 separator:分隔符 index:元素的索引)
<select id="listProduct" resultType="com.exzample.bean.User">
select * from product
where id in
<foreach item="code" collection="itemCodes" separator="," open="(" close=")" index="index">
#{item}
</foreach>
</select>
<!--sql标签 、include标签--> 作用:定义sql片段,并且引用拼接sql片段
<sql id="sqlTerm">
order_id,cid,address,create_date
</sql>
<select id="listProduct" resultType="com.exzample.bean.User">
select <include refid="sqlTerm" />
from ordertable where order_id = #{orderId}
</select>⑩写SQL时应该注意到的点
sql
# null不能直接与数值型进行比较
select name from Customer where referee_id != 2 or referee_id is null;