基于Dubbo 3.1,详细介绍了Dubbo服务的发布与引用的源码。
此前我们学习了Dubbo3.1版本的MigrationRuleHandler这个处理器,它用于通过动态更改规则来控制迁移行为。MigrationRuleListener的onrefer方法是Dubbo2.x 接口级服务发现与Dubbo3.x应用级服务发现之间迁移的关键。在未来的版本MigrationRuleListener将会被删除。
我们最后讲到了MigrationRuleHandler的refreshInvoker方法,该方法除了刷新invoker迁移新规则之外,还负责远程服务发现订阅的逻辑,即消费者能发现远程服务提供方的地址列表。而接口级的服务引入订阅则是通过refreshInterfaceInvoker方法实现的,refreshServiceDiscoveryInvoker方法则实现应用级服务发现。
本次我们来学习接口级服务发现订阅refreshInterfaceInvoker。
Dubbo 3.x服务引用源码:
- Dubbo 3.x源码(11)---Dubbo服务的发布与引用的入口
- Dubbo 3.x源码(18)---Dubbo服务引用源码(1)
- Dubbo 3.x源码(19)---Dubbo服务引用源码(2)
- Dubbo 3.x源码(20)---Dubbo服务引用源码(3)
- Dubbo 3.x源码(21)---Dubbo服务引用源码(4)
- Dubbo 3.x源码(22)---Dubbo服务引用源码(5)服务引用bean的获取以及懒加载原理
- Dubbo 3.x源码(23)---Dubbo服务引用源码(6)MigrationRuleListener迁移规则监听器
- Dubbo 3.x源码(24)---Dubbo服务引用源码(7)接口级服务发现订阅refreshInterfaceInvoker
- Dubbo 3.x源码(25)---Dubbo服务引用源码(8)notify订阅服务通知更新
Dubbo 3.x服务发布源码:
- Dubbo 3.x源码(11)---Dubbo服务的发布与引用的入口
- Dubbo 3.x源码(12)---Dubbo服务发布导出源码(1)
- Dubbo 3.x源码(13)---Dubbo服务发布导出源码(2)
- Dubbo 3.x源码(14)---Dubbo服务发布导出源码(3)
- Dubbo 3.x源码(15)---Dubbo服务发布导出源码(4)
- Dubbo 3.x源码(16)---Dubbo服务发布导出源码(5)
- Dubbo 3.x源码(17)---Dubbo服务发布导出源码(6)
1 refreshInterfaceInvoker刷新接口级invoker
该方法具有接口级别的远程服务发现、引入、订阅能力,大概逻辑为:
- 首先判断是否需要刷新invoker,即重新创建真实invoker:如果真实invoker不存在,或者已被销毁,或者内部没有Directory,则需要刷新。
- 一般情况下,当启动消费者并首次执行refer的时候,真实invoker为null,需要创建真实invoker。
- 通过注册中心操作类registryProtocol#getInvoker方法来引入服务提供者invoker,这是消费者进行接口级服务发现订阅的核心逻辑。
java
/**
* MigrationInvoker的方法
* <p>
* 刷新接口invoker
*
* @param latch 倒计数器
*/
protected void refreshInterfaceInvoker(CountDownLatch latch) {
/*
* 1 如果MigrationInvoker内部的真实invoker存在,那么清空真实invoker的directory的
*/
clearListener(invoker);
/*
* 2 判断是否需要刷新invoker,即重新创建真实invoker
* 如果真实invoker不存在,或者已被销毁,或者内部没有Directory
* 一般情况下,当启动消费者并首次执行refer的时候,真实invoker为null,需要创建
*/
if (needRefresh(invoker)) {
if (logger.isDebugEnabled()) {
logger.debug("Re-subscribing interface addresses for interface " + type.getName());
}
//如果不为null,则销毁
if (invoker != null) {
invoker.destroy();
}
/*
* 3 通过注册中心操作类registryProtocol获取真实invoker
*
* 这是消费者进行接口级服务发现订阅的核心逻辑,这里的registryProtocol类型为InterfaceCompatibleRegistryProtocol
*/
invoker = registryProtocol.getInvoker(cluster, registry, type, url);
}
/*
* 设置监听器
*/
setListener(invoker, () -> {
latch.countDown();
if (reportService.hasReporter()) {
reportService.reportConsumptionStatus(
reportService.createConsumptionReport(consumerUrl.getServiceInterface(), consumerUrl.getVersion(), consumerUrl.getGroup(), "interface"));
}
//如果迁移状态为APPLICATION_FIRST,那么设置首选invoker
if (step == APPLICATION_FIRST) {
calcPreferredInvoker(rule);
}
});
}2 getInvoker获取invoker
这是默认消费者进行接口级服务发现订阅的核心逻辑,这里的registryProtocol类型为InterfaceCompatibleRegistryProtocol。
- 首先创建接口级动态注册心中目录RegistryDirectory
- 随后调用doCreateInvoker 方法创建服务引入invoker。
java
/**
* InterfaceCompatibleRegistryProtocol的方法
* <p>
* 获取接口级别invoker
*
* @param cluster 集群操作对象
* @param registry 注册中心对象,例如ListenerRegistryWrapper(ZookeeperRegistry)
* @param type 接口类型
* @param url 注册中心协议url,协议是真实注册中心协议,例如zookeeper
* @return 真实invoker
*/
@Override
public <T> ClusterInvoker<T> getInvoker(Cluster cluster, Registry registry, Class<T> type, URL url) {
/*
* 1 创建动态注册心中目录DynamicDirectory
*/
DynamicDirectory<T> directory = new RegistryDirectory<>(type, url);
/*
* 2 创建invoker
*/
return doCreateInvoker(directory, cluster, registry, type);
}3 RegistryDirectory注册中心目录
RegistryDirectory是基于注册中心的服务发现使用的服务目录,其内部存储着从远程注册中心获取的服务提供者的信息。消费者进行远程rpc调用的时候能够通过RegistryDirectory找到一个远程服务提供者。
RegistryDirectory会自动从注册中心更新 Invoker列表、配置信息、路由列表。
下面是RegistryDirectory的构造器的逻辑,仅仅是进行了一系列的初始化操作。
java
/**
* 创建动态注册心中目录
*
* @param serviceType 服务接口类型
* @param url 注册中心协议url,协议是真实注册中心协议,例如zookeeper
*/
public RegistryDirectory(Class<T> serviceType, URL url) {
//调用父类构造器
super(serviceType, url);
//设置模块模型
moduleModel = getModuleModel(url.getScopeModel());
//设置消费者配置监听器ConsumerConfigurationListener
consumerConfigurationListener = getConsumerConfigurationListener(moduleModel);
}3.1 DynamicDirectory动态目录
java
/**
* 动态目录
*
* @param serviceType 服务接口类型
* @param url 注册中心协议url
*/
public DynamicDirectory(Class<T> serviceType, URL url) {
//调用父类构造器
super(url, true);
//模块模型
ModuleModel moduleModel = url.getOrDefaultModuleModel();
//基于Dubbo SPI获取Cluster的自适应实现,Cluster$Adaptive
this.cluster = moduleModel.getExtensionLoader(Cluster.class).getAdaptiveExtension();
//基于Dubbo SPI获取RouterFactory的自适应实现,RouterFactory$Adaptive
this.routerFactory = moduleModel.getExtensionLoader(RouterFactory.class).getAdaptiveExtension();
if (serviceType == null) {
throw new IllegalArgumentException("service type is null.");
}
if (StringUtils.isEmpty(url.getServiceKey())) {
throw new IllegalArgumentException("registry serviceKey is null.");
}
//是否需要注册,默认true
this.shouldRegister = !ANY_VALUE.equals(url.getServiceInterface()) && url.getParameter(REGISTER_KEY, true);
//是否简化,默认false
this.shouldSimplified = url.getParameter(SIMPLIFIED_KEY, false);
//服务接口类型
this.serviceType = serviceType;
//服务key
this.serviceKey = super.getConsumerUrl().getServiceKey();
//消费者url
this.directoryUrl = consumerUrl;
//消费者消费的服务分组信息
String group = directoryUrl.getGroup("");
//多个组
this.multiGroup = group != null && (ANY_VALUE.equals(group) || group.contains(","));
//当是服务目录信息为空时否快速失败,默认true
this.shouldFailFast = Boolean.parseBoolean(ConfigurationUtils.getProperty(moduleModel, Constants.SHOULD_FAIL_FAST_KEY, "true"));
}3.2 AbstractDirectory抽象目录
java
/**
* 抽象目录
* @param url 注册中心协议url
* @param isUrlFromRegistry 是否是注册中心协议
*/
public AbstractDirectory(URL url, boolean isUrlFromRegistry) {
this(url, null, isUrlFromRegistry);
}
public AbstractDirectory(URL url, RouterChain<T> routerChain, boolean isUrlFromRegistry) {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
//移除属性
this.url = url.removeAttribute(REFER_KEY).removeAttribute(MONITOR_KEY);
Map<String, String> queryMap;
//获取refer属性,即服务引用参数map
Object referParams = url.getAttribute(REFER_KEY);
if (referParams instanceof Map) {
queryMap = (Map<String, String>) referParams;
//消费者url,协议默认为consumer
this.consumerUrl = (URL) url.getAttribute(CONSUMER_URL_KEY);
} else {
queryMap = StringUtils.parseQueryString(url.getParameterAndDecoded(REFER_KEY));
}
// remove some local only parameters 删除一些仅本地参数
ApplicationModel applicationModel = url.getOrDefaultApplicationModel();
this.queryMap = applicationModel.getBeanFactory().getBean(ClusterUtils.class).mergeLocalParams(queryMap);
if (consumerUrl == null) {
String host = isNotEmpty(queryMap.get(REGISTER_IP_KEY)) ? queryMap.get(REGISTER_IP_KEY) : this.url.getHost();
String path = isNotEmpty(queryMap.get(PATH_KEY)) ? queryMap.get(PATH_KEY) : queryMap.get(INTERFACE_KEY);
String consumedProtocol = isNotEmpty(queryMap.get(PROTOCOL_KEY)) ? queryMap.get(PROTOCOL_KEY) : CONSUMER;
URL consumerUrlFrom = this.url
.setHost(host)
.setPort(0)
.setProtocol(consumedProtocol)
.setPath(path);
if (isUrlFromRegistry) {
// reserve parameters if url is already a consumer url
consumerUrlFrom = consumerUrlFrom.clearParameters();
}
this.consumerUrl = consumerUrlFrom.addParameters(queryMap);
}
//连接检查任务调度执行器,Dubbo-framework-connectivity-scheduler,线程数为可用cup核心数
this.connectivityExecutor = applicationModel.getFrameworkModel().getBeanFactory()
.getBean(FrameworkExecutorRepository.class).getConnectivityScheduledExecutor();
//获取配置对象
Configuration configuration = ConfigurationUtils.getGlobalConfiguration(url.getOrDefaultModuleModel());
//获取dubbo.reconnect.reconnectTaskTryCount配置,默认10,重新连接任务的最大数量
this.reconnectTaskTryCount = configuration.getInt(RECONNECT_TASK_TRY_COUNT, DEFAULT_RECONNECT_TASK_TRY_COUNT);
//获取dubbo.reconnect.reconnectTaskPeriod配置,默认1000ms,重新连接任务的间隔时间
this.reconnectTaskPeriod = configuration.getInt(RECONNECT_TASK_PERIOD, DEFAULT_RECONNECT_TASK_PERIOD);
//路由器链
setRouterChain(routerChain);
}4 doCreateInvoker创建invoker
该方法由InterfaceCompatibleRegistryProtocol的父类RegistryProtocol实现。大概步骤为:
- 首先根据消费者信息转换为消费者注册信息url,内部包括消费者ip、指定引用的protocol(默认consumer协议)、指定引用的服务接口、指定引用的方法以及其他消费者信息。
- 调用registry.register方法将消费者注册信息url注册到注册中心。
- 调用directory.buildRouterChain方法构建服务调用路由链。
- 调用directory.subscribe方法进行服务发现、引入并订阅服务。
- 调用cluster.join方法进行集群容错能力包装。
java
/**
* RegistryProtocol的方法
* 创建ClusterInvoker
*
* @param directory 动态目录
* @param cluster 集群
* @param registry 注册中心
* @param type 服务接口类型
* @return ClusterInvoker
*/
protected <T> ClusterInvoker<T> doCreateInvoker(DynamicDirectory<T> directory, Cluster cluster, Registry registry, Class<T> type) {
//注册中心操作类
directory.setRegistry(registry);
//设置协议,Protocol$Adaptive
directory.setProtocol(protocol);
// all attributes of REFER_KEY 消费者服务引用参数
Map<String, String> parameters = new HashMap<>(directory.getConsumerUrl().getParameters());
//消费者信息转消费者注册信息url
URL urlToRegistry = new ServiceConfigURL(
//获取protocol属性,只调用指定协议的服务提供方,其它协议忽略,默认值consumer
parameters.get(PROTOCOL_KEY) == null ? CONSUMER : parameters.get(PROTOCOL_KEY),
//消费者ip
parameters.remove(REGISTER_IP_KEY),
//端口
0,
//服务接口路径
getPath(parameters, type),
//服务引用参数
parameters
);
urlToRegistry = urlToRegistry.setScopeModel(directory.getConsumerUrl().getScopeModel());
urlToRegistry = urlToRegistry.setServiceModel(directory.getConsumerUrl().getServiceModel());
//是否应该注册,默认true
if (directory.isShouldRegister()) {
//设置注册的消费者url
directory.setRegisteredConsumerUrl(urlToRegistry);
/*
* 1 消费者注册信息url注册到注册中心
*/
registry.register(directory.getRegisteredConsumerUrl());
}
/*
* 2 构建服务路由器链
*/
directory.buildRouterChain(urlToRegistry);
/*
* 3 服务发现并订阅服务
*/
directory.subscribe(toSubscribeUrl(urlToRegistry));
/*
* 4 集群容错包装
*/
return (ClusterInvoker<T>) cluster.join(directory, true);
}4.1 register注册接口级消费者信息
该方法的源码我们在此前学习provider导出服务并且接口级服务注册到注册中心的时候就讲过了,即注册接口级别服务消费者和提供者信息是同一个方法。
该方法将会通过注册中心操作类Registry将服务消费者url的信息注册到注册中心。以ZookeeperRegistry为例,根据url构建节点路径,/dubbo/{servicePath}/ consumers /{urlString},例如:/dubbo/org.apache.dubbo.demo.DemoService/consumers/consumer%3A%2F%2F10.253.45.126%2Forg.apache.dubbo.demo.DemoService%3Fapplication%3Ddemo-consumer%26background%3Dfalse%26category%3Dconsumers%26check%3Dfalse%26dubbo%3D2.0.2%26interface%3Dorg.apache.dubbo.demo.DemoService%26methods%3DsayHello%2CsayHelloAsync%26pid%3D62247%26release%3D%26side%3Dconsumer%26sticky%3Dfalse%26timestamp%3D1667211594775%26unloadClusterRelated%3Dfalse,节点的值是服务提供者的节点ip。
注意此节点是一个临时节点,当服务关闭时节点删除。对于接口级的消费者服务注册,在zookeeper中的节点样式如下,可以发现和服务提供者注册的服务信息在同一个大的目录下面,即在同一个服务接口目录下:
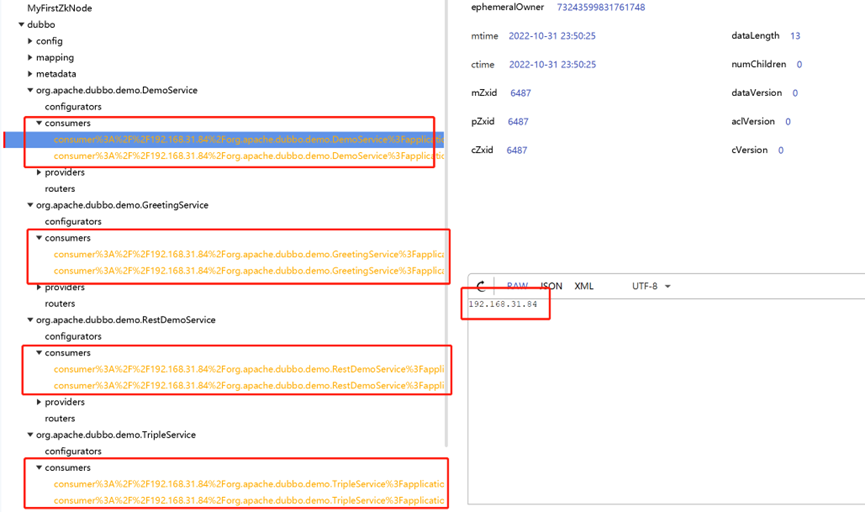
4.2 buildRouterChain构建路由链
buildRouterChain方法用于构建路由链RouterChain,每个Directory都有一条RouterChain。服务消费者会向注册中心获取服务提供者的地址列表,当消费端发起调用服务时,会先根据路由策略选出需要调用的目标服务提供者地址列表,随后根据负载算法直接调用提供者。
流量路由,顾名思义就是把具有某些属性特征的流量,路由到指定的目标。dubbo流量路由是流量治理中重要的一环,多个路由如同流水线一样,形成一条路由链,从所有的地址表中筛选出最终目的地址集合,再通过负载均衡策略选择访问的地址。开发者可以基于流量路由标准来实现各种场景,如灰度发布、金丝雀发布、容灾路由、标签路由等。
该方法入口为DynamicDirectory的buildRouterChain方法,基于RouterChain.buildChain构建路由链并设置给AbstractDirectory 的routerChain属性。
java
/**
* DynamicDirectory的方法
* 构建服务路由链
*
* @param url 消费者注册信息url
*/
public void buildRouterChain(URL url) {
//构建一个RouterChain
this.setRouterChain(RouterChain.buildChain(getInterface(), url));
}RouterChain.buildChain方法源码如下。
java
/**
* RouterChain的方法
*
* 构建路由链
*
* @param interfaceClass 服务接口class
* @param url 消费者注册信息url
* @return 消费者服务路由链
*/
public static <T> RouterChain<T> buildChain(Class<T> interfaceClass, URL url) {
ModuleModel moduleModel = url.getOrDefaultModuleModel();
//从消费者注册信息url中获取获取router属性的值,并且拆分后作为扩展名获取全部扩展名的RouterFactory实现,默认返回空列表
List<RouterFactory> extensionFactories = moduleModel.getExtensionLoader(RouterFactory.class)
.getActivateExtension(url, ROUTER_KEY);
//从 RouterFactory 获取 Router,默认返回空列表
List<Router> routers = extensionFactories.stream()
.map(factory -> factory.getRouter(url))
.sorted(Router::compareTo)
.collect(Collectors.toList());
//获取状态路由列表,默认有5个状态路由
List<StateRouter<T>> stateRouters = moduleModel
.getExtensionLoader(StateRouterFactory.class)
.getActivateExtension(url, ROUTER_KEY)
.stream()
.map(factory -> factory.getRouter(interfaceClass, url))
.collect(Collectors.toList());
//是否快速失败
boolean shouldFailFast = Boolean.parseBoolean(ConfigurationUtils.getProperty(moduleModel, Constants.SHOULD_FAIL_FAST_KEY, "true"));
//获取RouterSnapshotSwitcher
RouterSnapshotSwitcher routerSnapshotSwitcher = ScopeModelUtil.getFrameworkModel(moduleModel).getBeanFactory().getBean(RouterSnapshotSwitcher.class);
//创建一个RouterChain对象并返回
return new RouterChain<>(routers, stateRouters, shouldFailFast, routerSnapshotSwitcher);
}该方法会尝试获取消费者引用配置中指定的Router和StateRouter,默认情况下没有Router,但有5个StateRouter。随后将路由链表构建为一个RouterChain返回。

- MockInvokersSelector:一种特殊Router,如果一个请求被配置为使用mock,那么这个路由器保证只有带有mock协议的invoker出现在最终的invoker列表中,所有其他invoker将被排除。
- StandardMeshRuleRouter:dubbo3新增的Router,用于服务治理。可以动态配置到/dubbo/config/dubbo/{applicationName}.MESHAPPRULE节点。
- TagStateRouter:标签路由,根据规则获取指定tag的invoker地址列表,进行过滤排除那些没有的invoker。tag可以动态配置到/dubbo/config/dubbo/{providerApplicationName}.tag-router节点。
- ServiceStateRouter:服务级别路由器,可以动态配置到/dubbo/config/dubbo/{interface}:{version}:{group}.condition-router节点。
- AppStateRouter:应用级别路由器,可以动态配置到/dubbo/config/dubbo/{applicationName}.condition-router节点。
4.3 subscribe接口级服务发现和订阅
该方法用于消费者端订阅zookeeper服务节点下的providers,configurators,routers节点目录变更,当这些节点目录发生变化时会触发回调通知RegistryDirectory执行notify方法,进而完成本地服务列表的动态更新功能。实际上服务提供者也会订阅,只不过只会订阅configurators节点。
该方法首先调用父类DynamicDirectory的subscribe方法,随后将当前RegistryDirectory实例加入到节点目录变化的回调通知监听器集合中,用以接收通知。
java
/**
* RegistryDirectory的方法
* <p>
* 订阅服务
*
* @param url 服务消费者url
*/
@Override
public void subscribe(URL url) {
//调用父类DynamicDirectory的subscribe方法
super.subscribe(url);
//获取enable-configuration-listen配置,默认true
if (moduleModel.getModelEnvironment().getConfiguration().convert(Boolean.class, org.apache.dubbo.registry.Constants.ENABLE_CONFIGURATION_LISTEN, true)) {
//将当前RegistryDirectory加入到节点目录变化的回调通知监听器集合中
consumerConfigurationListener.addNotifyListener(this);
//引用配置监听器
referenceConfigurationListener = new ReferenceConfigurationListener(moduleModel, this, url);
}
}DynamicDirectory的subscribe方法源码如下,主要是调用registry注册中心的subscribe方法实现服务订阅,并将自身作为监听器。
java
/**
* DynamicDirectory的方法
* 订阅服务
*
* @param url 服务消费者url
*/
public void subscribe(URL url) {
//设置subscribeUrl属性
setSubscribeUrl(url);
//调用registry注册中心的subscribe方法实现服务订阅
registry.subscribe(url, this);
}4.3.1 Registry#subscribe订阅服务
对于接口级别的服务发现协议来说,内部注册中心是各个协议对应的真正的注册中心实现,例如ListenerRegistryWrapper(ZookeeperRegistry),而对于应用级别服务发现协议来说,则是ListenerRegistryWrapper(ServiceDiscoveryRegistry)。
ListenerRegistryWrapper的subscribe方法通过内部的registry#subscribe方法实现订阅。
java
/**
* ListenerRegistryWrapper的方法
* <p>
* 订阅服务
*
* @param url 服务消费者url
* @param listener 事件监听器
*/
@Override
public void subscribe(URL url, NotifyListener listener) {
try {
//通过内部的registry#subscribe方法实现订阅
if (registry != null) {
registry.subscribe(url, listener);
}
} finally {
//注册监听器,监听事件
listenerEvent(serviceListener -> serviceListener.onSubscribe(url, registry));
}
}4.3.2 FailbackRegistry#subscribe订阅服务
该方法是subscribe方法入口。
- 调用父类AbstractRegistry的subscribe方法,将url和listener添加到中subscribed缓存中。
- 随后调用removeFailedSubscribed从failedSubscribed缓存中移除该url失败的订阅。
- 最后调用doSubscribe方法向服务器端发送订阅请求,该方法由各个注册中心子类实现。
java
/**
* FailbackRegistry的方法
* <p>
* 订阅服务
*
* @param url 订阅者url
* @param listener 通知监听器
*/
@Override
public void subscribe(URL url, NotifyListener listener) {
//调用父类AbstractRegistry的subscribe方法,将url和listener添加到中subscribed缓存中
super.subscribe(url, listener);
//从failedSubscribed缓存中移除该url失败的订阅
removeFailedSubscribed(url, listener);
try {
// Sending a subscription request to the server side
/*
* 向服务器端发送订阅请求
*/
doSubscribe(url, listener);
} catch (Exception e) {
//失败处理
Throwable t = e;
List<URL> urls = getCacheUrls(url);
if (CollectionUtils.isNotEmpty(urls)) {
notify(url, listener, urls);
logger.error("Failed to subscribe " + url + ", Using cached list: " + urls + " from cache file: " + getCacheFile().getName() + ", cause: " + t.getMessage(), t);
} else {
// If the startup detection is opened, the Exception is thrown directly.
boolean check = getUrl().getParameter(Constants.CHECK_KEY, true)
&& url.getParameter(Constants.CHECK_KEY, true);
boolean skipFailback = t instanceof SkipFailbackWrapperException;
if (check || skipFailback) {
if (skipFailback) {
t = t.getCause();
}
throw new IllegalStateException("Failed to subscribe " + url + ", cause: " + t.getMessage(), t);
} else {
logger.error("Failed to subscribe " + url + ", waiting for retry, cause: " + t.getMessage(), t);
}
}
// Record a failed registration request to a failed list, retry regularly
//添加到失败订阅列表,定时默认5000ms重试
addFailedSubscribed(url, listener);
}
}ZookeeperRegistry#doSubscribe订阅服务
该方法的大概逻辑为:
- 该方法获取url的category参数,该参数表示要监听的子目录,在默认设置下,当url是消费者url时,path变量可以为:
- dubbo/service name/providers,即服务提供者目录。
- dubbo/service name/configurators,即配置目录。
- dubbo/service name/routers,即服务路由目录。
- 遍历path,为path设置监听器,并且获取当前path下的子节点。并且加入urls集合中。
- 主动调用notify方法通知数据变更,这里实际上会动态更新本地内存和文件中的服务提供者缓存,并将url转换为invoker,还会创建NettyClient与服务端建立连接。这一步也是核心流程。
java
/**
* ZookeeperRegistry的方法
* <p>
* 订阅服务节点
*
* @param url 订阅者url
* @param listener 通知监听器
*/
@Override
public void doSubscribe(final URL url, final NotifyListener listener) {
try {
checkDestroyed();
//如果url的interface为*,即指定的服务接口为则监听所有,那么直接监听zk的dubbo root 节点
//一般都不会这么指定
if (ANY_VALUE.equals(url.getServiceInterface())) {
//root节点路径,默认dubbo节点
String root = toRootPath();
boolean check = url.getParameter(CHECK_KEY, false);
//初始化监听器
ConcurrentMap<NotifyListener, ChildListener> listeners = zkListeners.computeIfAbsent(url, k -> new ConcurrentHashMap<>());
//添加监听器
ChildListener zkListener = listeners.computeIfAbsent(listener, k -> (parentPath, currentChildren) -> {
for (String child : currentChildren) {
child = URL.decode(child);
if (!anyServices.contains(child)) {
anyServices.add(child);
subscribe(url.setPath(child).addParameters(INTERFACE_KEY, child,
Constants.CHECK_KEY, String.valueOf(check)), k);
}
}
});
//创建dubbo节点
zkClient.create(root, false);
//添加节点监听器
List<String> services = zkClient.addChildListener(root, zkListener);
if (CollectionUtils.isNotEmpty(services)) {
for (String service : services) {
service = URL.decode(service);
anyServices.add(service);
subscribe(url.setPath(service).addParameters(INTERFACE_KEY, service,
Constants.CHECK_KEY, String.valueOf(check)), listener);
}
}
}
//普通逻辑
else {
CountDownLatch latch = new CountDownLatch(1);
try {
List<URL> urls = new ArrayList<>();
/*
Iterate over the category value in URL.
With default settings, the path variable can be when url is a consumer URL:
/dubbo/[service name]/providers,
/dubbo/[service name]/configurators
/dubbo/[service name]/routers
*/
//获取url的category参数,该参数表示要监听的子目录
//在默认设置下,当url是消费者url时,path变量可以为:
//dubbo/[service name]/providers ,即服务提供者目录
//dubbo/[service name]/configurators ,即配置目录
//dubbo/[service name]/routers ,即路由目录
for (String path : toCategoriesPath(url)) {
//初始化监听器
ConcurrentMap<NotifyListener, ChildListener> listeners = zkListeners.computeIfAbsent(url, k -> new ConcurrentHashMap<>());
//获取RegistryChildListenerImpl这个ChildListener
ChildListener zkListener = listeners.computeIfAbsent(listener, k -> new RegistryChildListenerImpl(url, k, latch));
if (zkListener instanceof RegistryChildListenerImpl) {
((RegistryChildListenerImpl) zkListener).setLatch(latch);
}
// create "directories".
//尝试创建监听的节点目录,永久节点
zkClient.create(path, false);
// Add children (i.e. service items).
//为该节点添加一个子节点监听器,返回该节点目前的所有子节点
List<String> children = zkClient.addChildListener(path, zkListener);
if (children != null) {
// The invocation point that may cause 1-1.
//如果是providers下的子节点,则将consumer以及对应的子节点存入存入ZookeeperRegistry的缓存stringUrls中
urls.addAll(toUrlsWithEmpty(url, path, children));
}
}
/*
* 主动调用notify方法通知数据变更
*/
notify(url, listener, urls);
} finally {
// tells the listener to run only after the sync notification of main thread finishes.
latch.countDown();
}
}
} catch (Throwable e) {
throw new RpcException("Failed to subscribe " + url + " to zookeeper " + getUrl() + ", cause: " + e.getMessage(), e);
}
}实际返回的urls中的数据案例如下,可以返回多个子节点集群信息,如果没有配置和路由信息,那么返回的url协议为empty。

4.4 cluster.join集群容错
集群对象Cluster,实际上Cluster不仅仅有容错功能,因为其还代表着Dubbo十层架构中的集群层,因此,集群路由、负载均衡、发起RPC调用、失败重试、服务降级都是在该层实现的。但是这些功能不都是由Cluster接口实现的,而是由集群层的其他核心接口实现,例如Directory 、 Router 、 LoadBalance,他们的关系如下:
- 这里的 Invoker 是 Provider 的一个可调用 Service 的抽象,Invoker 封装了 Provider 地址及 Service 接口信息
- Directory 代表多个 Invoker,可以把它看成 List ,但与 List 不同的是,它的值可能是动态变化的,比如注册中心推送变更。
- Cluster 将 Directory 中的多个 Invoker 伪装成一个 Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个。
- Router 负责从多个 Invoker 中按路由规则选出子集,比如读写分离,应用隔离等。
- LoadBalance 负责从多个 Invoker 中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选。
更多集群容错介绍参见官方文档:https://dubbo.apache.org/zh/docs3-v2/java-sdk/advanced-features-and-usage/service/fault-tolerent-strategy/
Cluster通过基于Dubbo SPI机制获取,同时还会被wrapper包装,例如MockClusterWrapper。MockClusterWrapper#join方法将会被最先调用,它的join方法如下,通过MockClusterInvoker包装下层join方法返回的invoker,用于实现本地mock功能。
java
/**
* MockClusterWrapper的方法
*
* @param directory 服务目录
* @param buildFilterChain 是否构建过滤器链
* @return MockClusterInvoker
* @throws RpcException
*/
@Override
public <T> Invoker<T> join(Directory<T> directory, boolean buildFilterChain) throws RpcException {
//通过MockClusterInvoker包装下层join方法返回的invoker,用于实现本地mock功能
return new MockClusterInvoker<T>(directory,
this.cluster.join(directory, buildFilterChain));
}我们可以通过属性cluster设置集群方式,如不设置默认failover,即FailoverCluster。常见策略如下:
- Failover Cluster:失败自动切换。
- 失败自动切换,Dubbo默认的容错策略。服务消费方调用失败后自动切换到其他服务提供者的服务器进行重试。客户端等待服务端的处理时间超过了设定的超时时间时,也算做失败,将会重试。可通过 retries属性来设置重试次数(不含第一次),默认重试两次。
- 通常用于读操作或者具有幂等的写操作,需要注意的是重试会带来更长延迟。
- Failfast Cluster:快速失败。
- 只发起一次调用,失败后立即抛出异常。
- 通常用于非幂等性的写操作,比如新增记录。
- Failsafe Cluster:安全失败。
- 当调用失败出现异常时,直接忽略此异常,并记录一条日志,返回一个null结果,即使失败了也不会影响整个调用流程。
- 通常用于操作日志记录等无需要严格保证成功的操作。
- Failback Cluster:失败自动恢复。
- 当调用失败出现异常后,不会抛出异常,这类似于Failsafe,但Failback还会将这次调用加入内存中的失败列表中,对于这个列表中的失败调用,会在另一个线程中进行异步重试,重试如果再发生失败,则会忽略,并且即使重试调用成功,原来的调用方也感知不到结果了。
- 通常用于对于实时性要求不高,且不需要返回值的一些异步操作,比如消息通知。
- Forking Cluster:并行调用。
- 并行调用多个服务提供者,只要一个成功即返回。可通过forks="2"来设置最大并行数。
- 通常用于实时性要求较高的读操作,不适用于非幂等操作,并且需要消耗更多的服务资源。
- Broadcast Cluster:广播调用。
- 广播调用所有提供者,逐个调用,任意一台报错则调用报错。
- 通常用于通知所有提供者更新缓存或日志等本地资源信息。
- Available Cluster:可用实例调用。
- 调用目前可用的实例(只调用一个),如果当前没有可用的实例,则抛出异常。
- 通常用于不需要负载均衡的场景。
- Mergeable Cluster:合并调用。
- 将集群中的调用结果聚合起来返回结果。
- 通常和group一起配合使用。通过分组对结果进行聚合并返回聚合后的结果,比如菜单服务,用group区分同一接口的多种实现,现在消费方需从每种group中调用一次并返回结果,对结果进行合并之后返回,这样就可以实现聚合菜单项。
- ZoneAware Cluster:多注册中心调用。
- 多注册中心订阅的场景,注册中心集群间的负载均衡。
当在对directory执行了buildRouterChain方法构建路由链,以及subscribe方法服务发现并订阅服务的处理之后,directory内部实际上已经包含了configurators配置信息集合,routerChain路由链以及urlInvokerMap这三个缓存。在最后,将会通过cluster.join为服务调用添加集群容错机制。
不同的cluster#join方法会返回具有对应的容错功能的invoker。例如FailoverCluster#join方法将会返回FailoverClusterInvoker。
集群容错的能力只有在服务调用的时候才会得到体现,当我们学习Dubbo服务调用的时候在学习他们的源码。
5 总结
本次我们学习了接口级的服务引入订阅的refreshInterfaceInvoker方法,当时还有最为关键的notify服务通知更新的部分源码没有学习,所以下一篇文章将会介绍,notify通知本地服务更新的源码,然后在进行总结。