基于Redis的实现方式
1、选用Redis实现分布式锁原因:
(1)Redis有很高的性能;
(2)Redis命令对此支持较好,实现起来比较方便
2、使用命令介绍:
(1)SETNX
SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
(2)expire
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
(3)delete
delete key:删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。
3、实现思想:
(1)获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此在释放锁的时候进行判断。
(2)获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
(3)释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
4、 分布式锁的简单实现代码:
/**
* 分布式锁的简单实现代码
* Created by liuyang on 2017/4/20.
*/
public class DistributedLock {
private final JedisPool jedisPool;
public DistributedLock(JedisPool jedisPool) {
this.jedisPool = jedisPool;
}
/**
* 加锁
* @param lockName 锁的key
* @param acquireTimeout 获取超时时间
* @param timeout 锁的超时时间
* @return 锁标识
*/
public String lockWithTimeout(String lockName, long acquireTimeout, long timeout) {
Jedis conn = null;
String retIdentifier = null;
try {
// 获取连接
conn = jedisPool.getResource();
// 随机生成一个value
String identifier = UUID.randomUUID().toString();
// 锁名,即key值
String lockKey = "lock:" + lockName;
// 超时时间,上锁后超过此时间则自动释放锁
int lockExpire = (int) (timeout / 1000);
// 获取锁的超时时间,超过这个时间则放弃获取锁
long end = System.currentTimeMillis() + acquireTimeout;
while (System.currentTimeMillis() < end) {
if (conn.setnx(lockKey, identifier) == 1) {
conn.expire(lockKey, lockExpire);
// 返回value值,用于释放锁时间确认
retIdentifier = identifier;
return retIdentifier;
}
// 返回-1代表key没有设置超时时间,为key设置一个超时时间
if (conn.ttl(lockKey) == -1) {
conn.expire(lockKey, lockExpire);
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retIdentifier;
}
/**
* 释放锁
* @param lockName 锁的key
* @param identifier 释放锁的标识
* @return
*/
public boolean releaseLock(String lockName, String identifier) {
Jedis conn = null;
String lockKey = "lock:" + lockName;
boolean retFlag = false;
try {
conn = jedisPool.getResource();
while (true) {
// 监视lock,准备开始事务
conn.watch(lockKey);
// 通过前面返回的value值判断是不是该锁,若是该锁,则删除,释放锁
if (identifier.equals(conn.get(lockKey))) {
Transaction transaction = conn.multi();
transaction.del(lockKey);
List<Object> results = transaction.exec();
if (results == null) {
continue;
}
retFlag = true;
}
conn.unwatch();
break;
}
} catch (JedisException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.close();
}
}
return retFlag;
}
}5、测试刚才实现的分布式锁
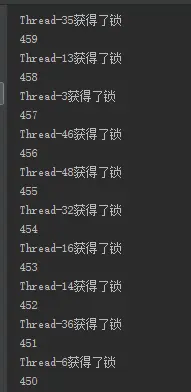
例子中使用50个线程模拟秒杀一个商品,使用--运算符来实现商品减少,从结果有序性就可以看出是否为加锁状态。
模拟秒杀服务,在其中配置了jedis线程池,在初始化的时候传给分布式锁,供其使用。
/**
* Created by liuyang on 2017/4/20.
*/
public class Service {
private static JedisPool pool = null;
private DistributedLock lock = new DistributedLock(pool);
int n = 500;
static {
JedisPoolConfig config = new JedisPoolConfig();
// 设置最大连接数
config.setMaxTotal(200);
// 设置最大空闲数
config.setMaxIdle(8);
// 设置最大等待时间
config.setMaxWaitMillis(1000 * 100);
// 在borrow一个jedis实例时,是否需要验证,若为true,则所有jedis实例均是可用的
config.setTestOnBorrow(true);
pool = new JedisPool(config, "127.0.0.1", 6379, 3000);
}
public void seckill() {
// 返回锁的value值,供释放锁时候进行判断
String identifier = lock.lockWithTimeout("resource", 5000, 1000);
System.out.println(Thread.currentThread().getName() + "获得了锁");
System.out.println(--n);
lock.releaseLock("resource", identifier);
}
}模拟线程进行秒杀服务:
public class ThreadA extends Thread {
private Service service;
public ThreadA(Service service) {
this.service = service;
}
@Override
public void run() {
service.seckill();
}
}
public class Test {
public static void main(String[] args) {
Service service = new Service();
for (int i = 0; i < 50; i++) {
ThreadA threadA = new ThreadA(service);
threadA.start();
}
}
}结果如下,结果为有序的:
若注释掉使用锁的部分:
public void seckill() {
// 返回锁的value值,供释放锁时候进行判断
//String indentifier = lock.lockWithTimeout("resource", 5000, 1000);
System.out.println(Thread.currentThread().getName() + "获得了锁");
System.out.println(--n);
//lock.releaseLock("resource", indentifier);
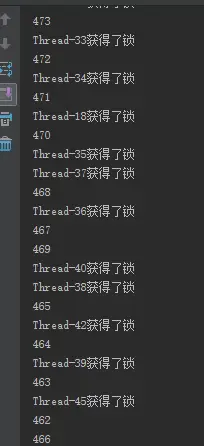
}从结果可以看出,有一些是异步进行的:
上述实现存在的问题
-
非原子性操作
加锁setnx和锁超时expire两个命令未非原子性操作,当执行加锁setnx后,若因网络或客户端问题锁超时expire命令未成功执行时,锁将无法被释放。
解决方案:使用set命令取代setnx和expire命令。setnx本身不支持设置超时时间。在Redis 2.6.12以上版本为set指令增加了可选参数,伪代码:set(key, value, expire)。

-
误删锁
设想如下情形:
(1)JVM1使用set(001, 002, 30)成功获取锁,并设置超时时间为30s;
(2)JVM1开始数据处理,处理时间已经超过了30s...
(3)服务器检测到(001, 002, 30)数据超时,将自动执行del进行数据删除,此时JVM1还在数据处理...
(4)此时,JVM2使用set(001, 002, 30)成功获取锁,并设置超时时间为30s;
(5)JVM2开始数据处理。与此同时,JVM1处理完成,操作提交后,根据商品id001,执行了del;
到此,JVM1成功误删了JVM2的锁。
解决方案:del数据之前,增加锁判断机制:判断要删除的锁是否属于本线程。操作流程:
(1)加锁:set(id, threadId,expire),其中value为当前线程ID;
(2)解锁:执行del命令时,根据id和threadId数据判断该锁是否仍属于本线程。是,则删除。
-
并发问题
基于误删锁的前提下,由于我们无法确定程序成功处理完成数据的具体时间,这就为超时时间的设置提出了难题。设置时间过长、过短都将影响程序并发的效率。
解决方案: JVM1需要自己判断在超时时间内是否完成数据处理,如未完成,应请求延长超时时间。具体操作:为获取锁的锁的线程开启一个守护线程。当29秒时(或更早),线程A还没执行完,守护线程会执行expire指令,为这把锁"续命"20秒。守护线程从第29秒开始执行,每20秒执行一次。当线程A执行完任务,会显式关掉守护线程。

image另一种情况:如果节点1 忽然断电,由于线程A和守护线程在同一个进程,守护线程也会停下。当过了超时时间后,没有守护进程的"续命",锁将自动释放。
Redisson实现Redis分布式锁的底层原理
好的,接下来就通过一张手绘图,给大家说说Redisson这个开源框架对Redis分布式锁的实现原理。

(1)加锁机制
咱们来看上面那张图,现在某个客户端要加锁。如果该客户端面对的是一个redis cluster集群,他首先会根据hash节点选择一台机器。
这里注意,仅仅只是选择一台机器!这点很关键!
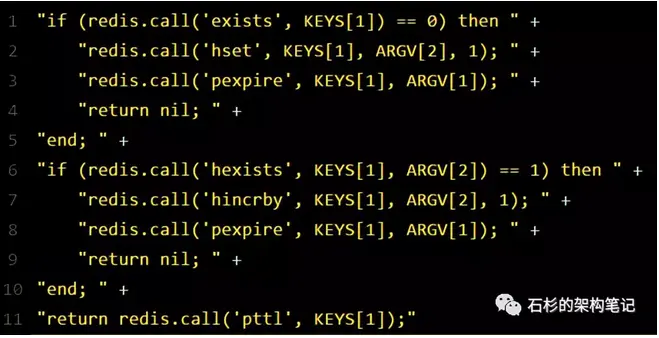
紧接着,就会发送一段lua脚本到redis上,那段lua脚本如下所示:
https://img2.sycdn.imooc.com/5cad94d10001b02806590338.jpg
为啥要用lua脚本呢?
因为一大坨复杂的业务逻辑,可以通过封装在lua脚本中发送给redis,保证这段复杂业务逻辑执行的原子性。
那么,这段lua脚本是什么意思呢?
**KEYS1**代表的是你加锁的那个key,比如说:
RLock lock = redisson.getLock("myLock");
这里你自己设置了加锁的那个锁key就是"myLock"。
**ARGV1**代表的就是锁key的默认生存时间,默认30秒。
**ARGV2**代表的是加锁的客户端的ID,类似于下面这样:
8743c9c0-0795-4907-87fd-6c719a6b4586:1
给大家解释一下,第一段if判断语句,就是用"exists myLock"命令判断一下,如果你要加锁的那个锁key不存在的话,你就进行加锁。
如何加锁呢?很简单,用下面的命令:
hset myLock
8743c9c0-0795-4907-87fd-6c719a6b4586:1 1通过这个命令设置一个hash数据结构,这行命令执行后,会出现一个类似下面的数据结构:

https://img4.sycdn.imooc.com/5cad94e50001d8a106640162.jpg
上述就代表"8743c9c0-0795-4907-87fd-6c719a6b4586:1"这个客户端对"myLock"这个锁key完成了加锁。
接着会执行"pexpire myLock 30000"命令,设置myLock这个锁key的生存时间是30秒。
好了,到此为止,ok,加锁完成了。
(2)锁互斥机制
那么在这个时候,如果客户端2来尝试加锁,执行了同样的一段lua脚本,会咋样呢?
很简单,第一个if判断会执行"exists myLock",发现myLock这个锁key已经存在了。
接着第二个if判断,判断一下,myLock锁key的hash数据结构中,是否包含客户端2的ID,但是明显不是的,因为那里包含的是客户端1的ID。
所以,客户端2会获取到pttl myLock返回的一个数字,这个数字代表了myLock这个锁key的**剩余生存时间。**比如还剩15000毫秒的生存时间。
此时客户端2会进入一个while循环,不停的尝试加锁。
(3)watch dog自动延期机制
客户端1加锁的锁key默认生存时间才30秒,如果超过了30秒,客户端1还想一直持有这把锁,怎么办呢?
简单!只要客户端1一旦加锁成功,就会启动一个watch dog看门狗,他是一个后台线程,会每隔10秒检查一下,如果客户端1还持有锁key,那么就会不断的延长锁key的生存时间。
(4)可重入加锁机制
那如果客户端1都已经持有了这把锁了,结果可重入的加锁会怎么样呢?
比如下面这种代码:

https://img1.sycdn.imooc.com/5cad94f60001654e06620453.jpg
这时我们来分析一下上面那段lua脚本。
第一个if判断肯定不成立,"exists myLock"会显示锁key已经存在了。
第二个if判断会成立,因为myLock的hash数据结构中包含的那个ID,就是客户端1的那个ID,也就是"8743c9c0-0795-4907-87fd-6c719a6b4586:1"
此时就会执行可重入加锁的逻辑,他会用:
incrby myLock
8743c9c0-0795-4907-87fd-6c71a6b4586:1 1
通过这个命令,对客户端1的加锁次数,累加1。
此时myLock数据结构变为下面这样:

大家看到了吧,那个myLock的hash数据结构中的那个客户端ID,就对应着加锁的次数
(5)释放锁机制
如果执行lock.unlock(),就可以释放分布式锁,此时的业务逻辑也是非常简单的。
其实说白了,就是每次都对myLock数据结构中的那个加锁次数减1。
如果发现加锁次数是0了,说明这个客户端已经不再持有锁了,此时就会用:
"del myLock"命令,从redis里删除这个key。
然后呢,另外的客户端2就可以尝试完成加锁了。
这就是所谓的分布式锁的开源Redisson框架的实现机制。
一般我们在生产系统中,可以用Redisson框架提供的这个类库来基于redis进行分布式锁的加锁与释放锁。
(6)上述Redis分布式锁的缺点
其实上面那种方案最大的问题,就是如果你对某个redis master实例,写入了myLock这种锁key的value,此时会异步复制给对应的master slave实例。
但是这个过程中一旦发生redis master宕机,主备切换,redis slave变为了redis master。
接着就会导致,客户端2来尝试加锁的时候,在新的redis master上完成了加锁,而客户端1也以为自己成功加了锁。
此时就会导致多个客户端对一个分布式锁完成了加锁。
这时系统在业务语义上一定会出现问题,导致各种脏数据的产生。
所以这个就是redis cluster,或者是redis master-slave架构的主从异步复制导致的redis分布式锁的最大缺陷:在redis master实例宕机的时候,可能导致多个客户端同时完成加锁。
引用(本文章只供本人学习以及学习的记录,如有侵权,请联系我删除)
拜托,面试请不要再问我Redis分布式锁的实现原理
分布式锁简单入门以及三种实现方式介绍
Redis实现分布式锁
最后编辑于:2024-11-11 21:08:36
© 著作权归作者所有,转载或内容合作请联系作者

喜欢的朋友记得点赞、收藏、关注哦!!!