2024深度学习发论文&模型涨点之------机器学习可解释性
现在以深度学习为主的方法在各个领域都已经next level了,但是如何解释我们的模型仍然是个难题。为什么得到这样的结果往往和结果本身一样重要。因此,个人觉得Explainable AI (XAI)依然会是近些年来一个很热门的方向。
机器学习可解释性(Interpretability in Machine Learning)是确保机器学习模型的预测过程和结果能够被人类理解和解释的能力。随着机器学习模型在各行各业的广泛应用,特别是在医疗、金融、司法等高风险领域,模型的可解释性变得尤为重要。
我整理了一些机器学习可解释性【论文】 合集,需要的同学公人人人号【AI创新工场】自取
论文精选
论文1:
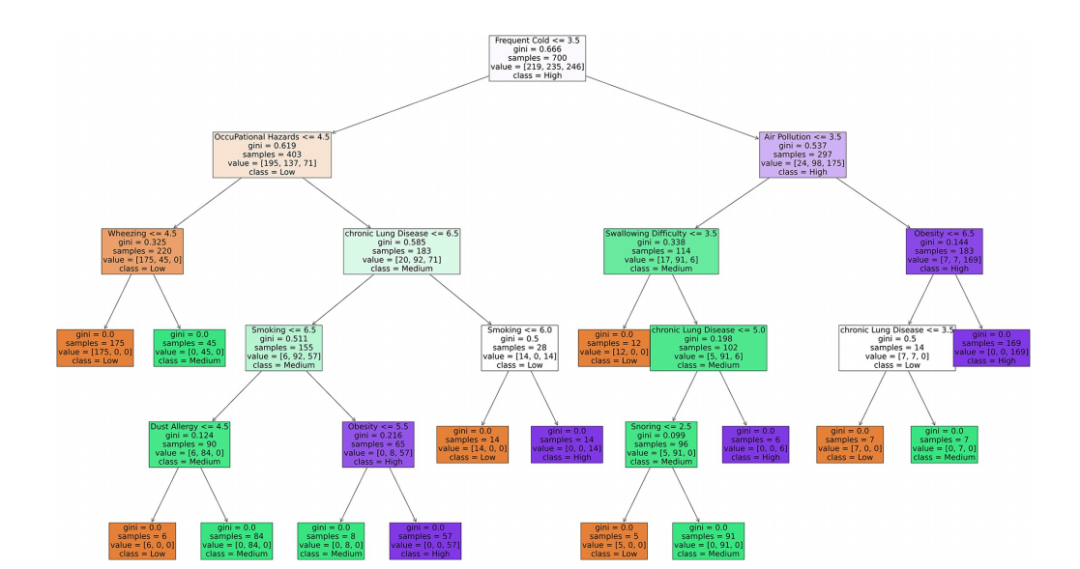
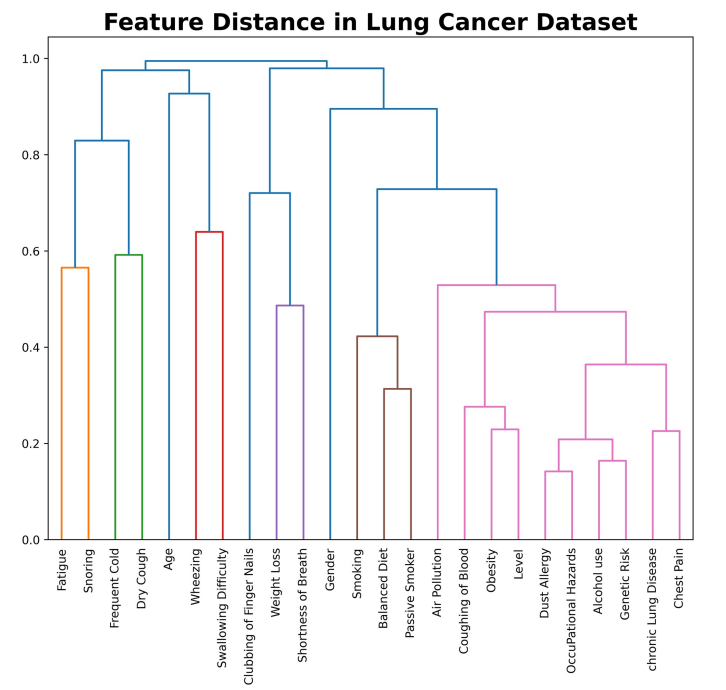
The efficacy of machine learning models in lung cancer risk prediction with explainability
机器学习模型在肺癌风险预测中的效能及可解释性
方法
-
**机器学习模型比较:**使用多种机器学习模型对肺癌相关参数的数值数据集进行训练和测试,比较不同模型的性能和准确性。
-
**超参数调优:**通过网格搜索算法对每个模型进行超参数调优,以选择最佳参数组合。
-
**模型解释性分析:**使用决策边界、局部可解释模型-不可知解释(LIME)和树提取等方法对每个模型的决策过程进行解释。
创新点
-
**模型决策逻辑解释:**提供了模型为何达到特定决策的逻辑解释,增强了患者和医疗工作者对模型的信任。
-
**超参数调优改进:**通过超参数调优,所有四个模型的准确性得到了显著提高,几乎达到了100%。
-
**模型解释性方法的应用:**结合不同的模型解释性方法,使非技术用户或患者能够更好地理解模型结果。
-
**与以往研究的比较:**与之前使用类似数据集的研究相比,本研究在模型准确性和解释性方面取得了更好的结果。
论文2:
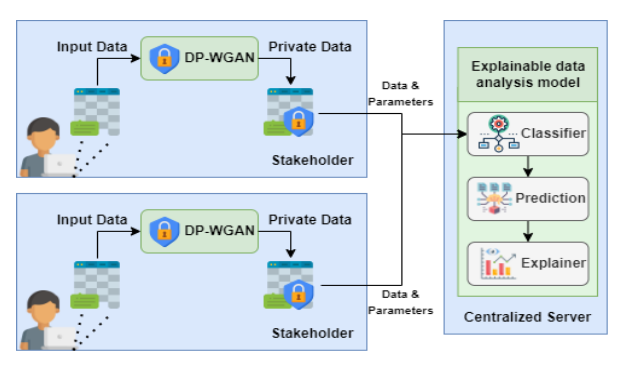
Further Insights: Balancing Privacy, Explainability, and Utility in Machine Learning-based Tabular Data Analysis
进一步洞察:在基于机器学习的表格数据分析中平衡隐私、可解释性和效用
方法
-
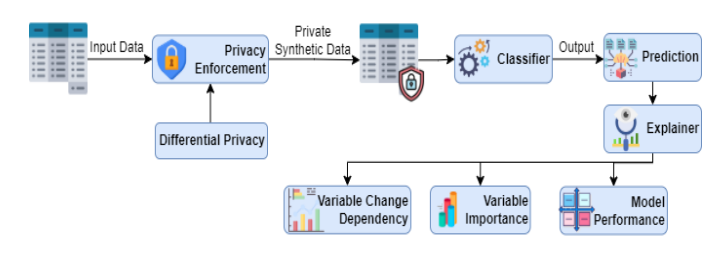
**隐私保护和可解释数据分析:**提出了一个综合优化标准,平衡数据隐私、模型可解释性和数据效用的关键方面。
-
**(𝜋?,𝛿)-差分隐私与生成对抗网络(GANs):**使用(𝜋?,𝛿)-差分隐私和生成对抗网络作为隐私机制,生成与原始数据分布相似的合成数据。
-
**模型解释方法:**结合了多种模型解释方法,以提供对模型决策的洞察。
创新点
-
**隐私与可解释性的平衡:**提出了一种新的方法,通过调节隐私参数和探索不同配置,找到最大化隐私增益和可解释性相似度,同时最小化对数据效用不利影响的最佳权衡点。
-
**综合优化标准:**定义了一个全面优化标准,系统地探索隐私参数值的不同配置,以识别最佳配置。
-
**实验验证:**通过在包含敏感属性的著名Adult数据集上使用五个分类器进行实验,验证了所提方法在保护数据隐私和生成模型解释方面的能力。
-
**兼容性矩阵和权衡分数优化:**使用兼容性矩阵和权衡分数优化来确定满足所有要求和约束的最佳权衡分数,为模型开发中的数据效用、隐私和可解释性提供了一个系统和客观的调和手段。
论文3:
Regulating Explainability in Machine Learning Applications -- Observations from a Policy Design Experiment
机器学习应用中的可解释性规范------政策设计实验的观察
方法
-
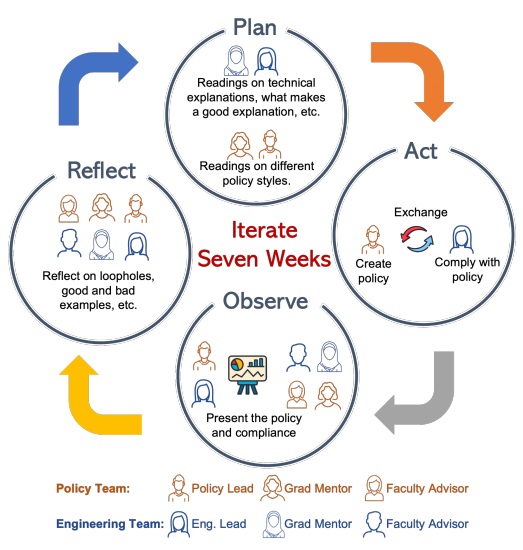
跨学科合 **作:**通过将具有人工智能和政策背景的研究人员组成团队,进行为期十周的持续合作实验。
-
**实验性研究:**通过迭代的政策设计过程,包括起草政策、尝试遵守(或规避)政策,并每周集体评估其有效性。
-
**政策草案迭代:**在实验过程中,政策草案经过多次迭代,以平衡人工智能开发者的需求和保护个人及社会的需求。
-
**证据讨论:**在政策设计过程中讨论合规证据,包括人类主题研究作为证据的重要性。
创新点
-
**跨学科政策设计:**提出了一种跨学科的方法来设计人工智能应用的可解释性政策,这种方法在政策设计中较为新颖。
-
**实证研究方法:**通过实验性研究方法,将政策设计过程置于实际案例中,以观察和学习政策设计的挑战和策略。
-
**迭代和持续反馈:**强调了迭代和持续反馈在改进政策草案中的重要性,这种方法有助于在政策设计中实现动态学习和适应。
-
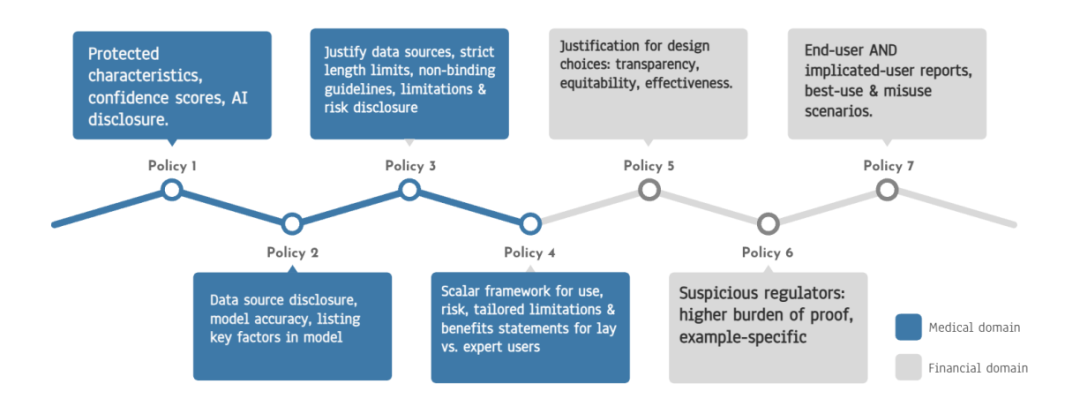
**政策和技术创新的平衡:**实验结果表明,通过跨学科努力,可以达成比当前指南更清晰、更可操作和可执行的政策共识。
论文4:
Investigating Adversarial Attacks in Software Analytics via Machine Learning Explainability
通过机器学习可解释性调查软件分析中的对抗性攻击
方法
-
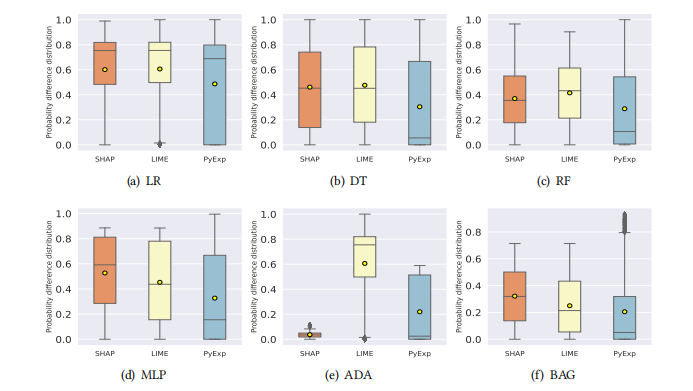
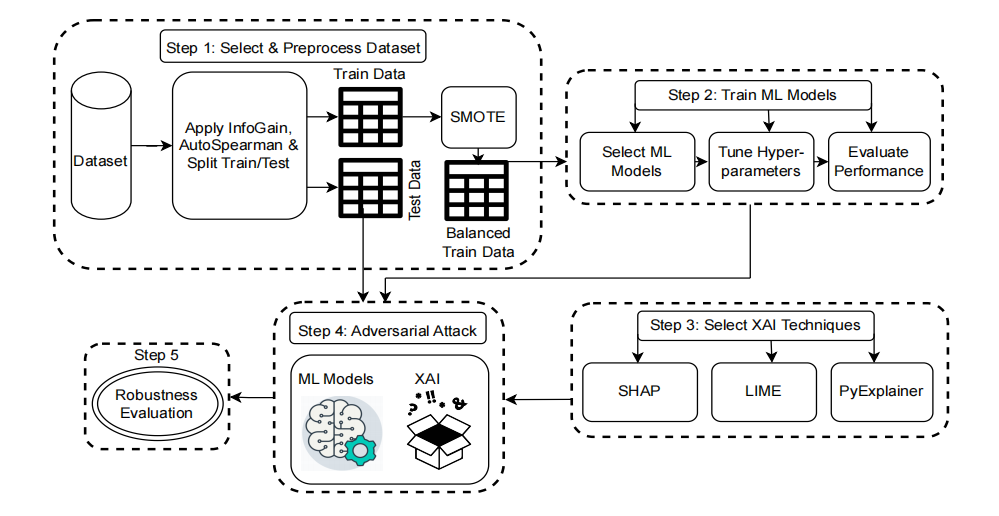
**机器学习可解释性技术应用:**使用SHAP、LIME和PyExplainer等机器学习可解释性技术来识别影响机器学习模型决策的重要特征。
-
**对抗性示例生成:**基于识别出的重要特征,通过修改这些特征来生成对抗性示例。
-
**多目标优化函数:**使用多目标优化函数来平衡最小化修改特征数量和最大化攻击成功率之间的关系。
-
**攻击成功率评估:**采用攻击成功率(ASR)指标来评估机器学习模型在对抗性攻击下的鲁棒性。
创新点
-
**特征空间的对抗性攻击:**提出了一种新的对抗性攻击方法,专注于在特征空间而非输入空间进行攻击。
-
**解释引导的对抗性攻击:**利用机器学习可解释性技术来指导对抗性攻击,这是一种新颖的方法来评估机器学习模型的鲁棒性。
-
**跨数据集和模型的评估:**通过在多个数据集和多种机器学习模型上的实验,展示了所提出技术的有效性和普适性。
-
**实际应用中的鲁棒性评估:**研究结果强调了在软件分析任务中开发更鲁棒的机器学习模型和对抗解释引导的对抗性攻击的重要性。