Jina CLIP v2:多语言多模态的文本图像向量模型
原创 Jina AI Jina AI 2024年11月22日 12:47 北京

多模态向量通过统一的数据表示,实现了不同模态数据的搜索和理解,是神经检索和多模态生成式 AI 应用的基石。今天,我们推出了全新的通用多语言多模态向量模型 ------ jina-clip-v2。该模型基于 jina-clip-v1 和 jina-embeddings-3 构建,并实现了多项关键改进:
-
性能提升 :v2 在文本-图像和文本-文本检索任务中,性能较 v1 提升了 3%。此外,与 v1 类似,v2 的文本编码器也能高效地应用于多语言长文本密集检索索,其性能可与我们目前最先进的模型 ------ 参数量低于 1B 的最佳多语言向量模型 jina-embeddings-v3(基于 MTEB 排行榜)------ 相媲美。
-
多语言支持 :以 jina-embeddings-v3 作为文本塔,jina-clip-v2 支持 89 种语言的多语言图像检索,并在该任务上的性能相比 nllb-clip-large-siglip 提升了 4%。
-
更高图像分辨率 :v2 支持 512x512 像素的输入图像分辨率,相比 v1 的 224x224 有了大幅提升。能够更好地捕捉图像细节,提升特征提取的精度,并更准确地识别细粒度视觉元素。
-
可变维度输出 :
jina-clip-v2引入了俄罗斯套娃表示学习(Matryoshka Representation Learning,MRL)技术,只需设置dimensions参数,即可获取指定维度的向量输出,且在减少存储成本的同时,保持强大的性能。
模型开源链接 **:**https://huggingface.co/jinaai/jina-clip-v2
API 快速上手 : https://jina.ai/?sui=\&model=jina-clip-v2
模型架构
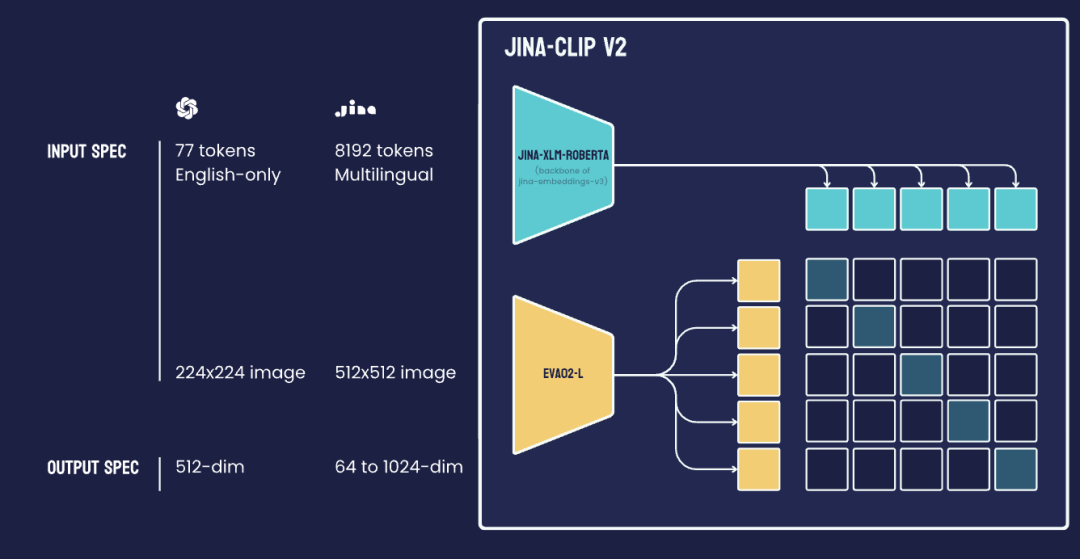
jina-clip-v2 是一个 9 亿参数的类 CLIP 模型,它结合了两个强大的编码器:文本编码器 Jina XLM-RoBERTa(jina-embeddings-v3 的骨干网络)和视觉编码器 EVA02-L14(由 BAAI 开发的高效视觉 Transformer)。这些编码器经过联合训练,生成图像和文本的对齐表示。
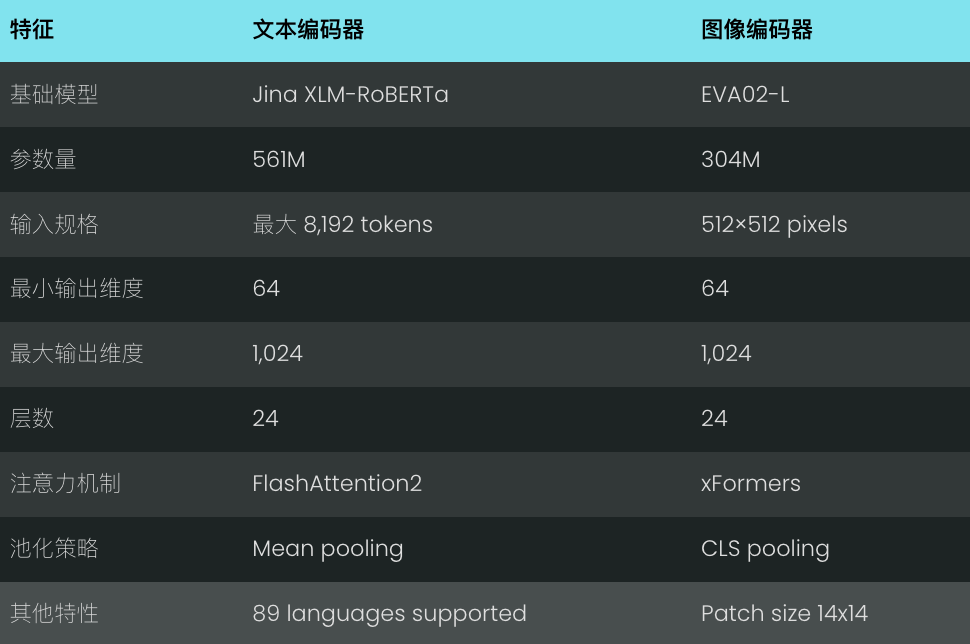
跨模态检索性能
Jina CLIP v2 支持 89 种语言,在包括中文、英语、法语、德语、日语、俄语、阿拉伯语和西班牙语在内的主要语种中都表现优异。
在多语言图像检索基准测试中,8.65 亿参数的jina-clip-v2 的性能比目前最先进的 CLIP 模型 NLLB-CLIP-SigLIP 相当甚至更好。
Jina CLIP v2 的参数量介于 NLLB-CLIP-SigLIP 的两个版本之间:其 base 版本参数量为 5.07 亿,比 Jina CLIP v2 小 41%,large 版本参数量则高达 12 亿,比 Jina CLIP v2 大 39%。
英语文本和图像检索性能
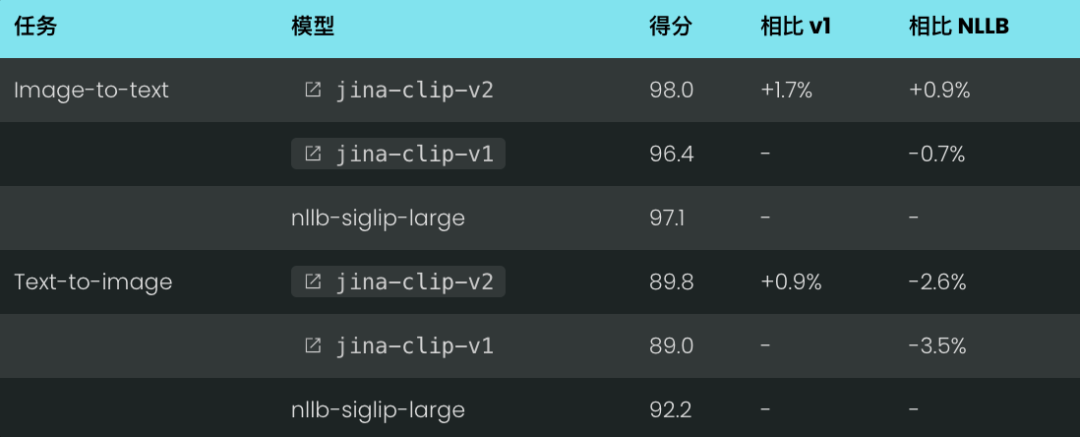
jina-clip-v2 在标准跨模态检索基准(Flickr30k 和 COCO)取得了全面的性能提升。
尤其在 Flickr30k 图像到文本检索任务中,jina-clip-v2 达到 98% 的 SOTA 精度,超越了前代版本 jina-clip-v1 和 NLLB-CLIP-SigLIP。
即使在 COCO 数据集上,jina-clip-v2 相比 v1 提升了 3.3% 的性能,并在其他基准和模态组合上保持了与 NLLB-CLIP-SigLIP 的强劲竞争力。
Flickr30k Recall@5 性能:
COCO Recall@5 性能:
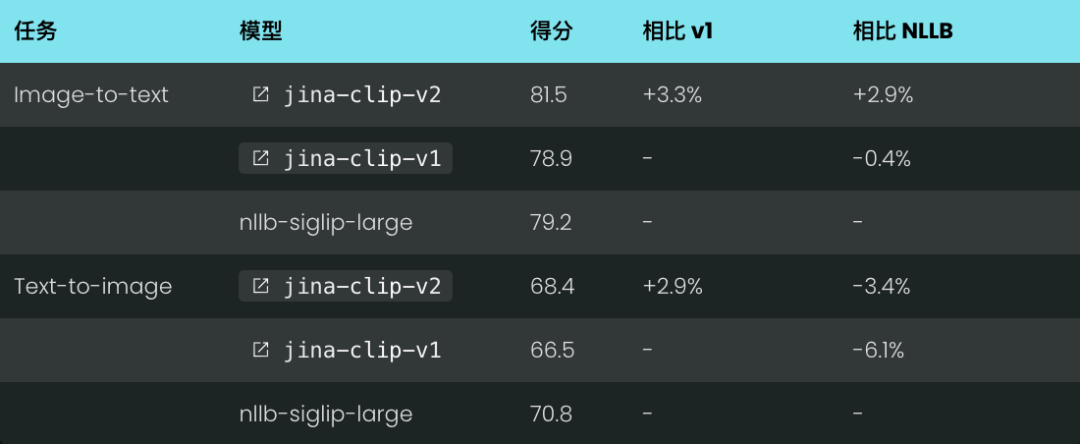
多语言文本和图像检索性能
jina-clip-v2 在多语言跨模态基准测试中同样表现出色,特别在图像到文本检索。
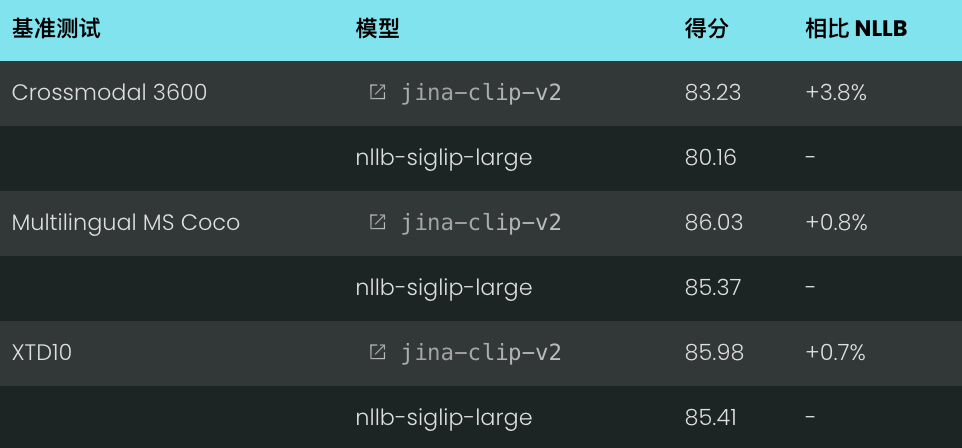
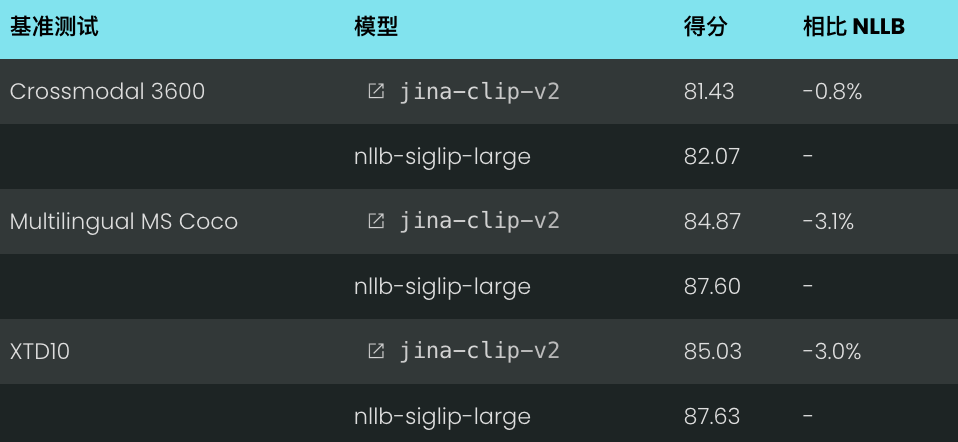
在所有测试数据集上,jina-clip-v2 的性能都优于 NLLB-SigLIP-Large,在 Crossmodal 3600 数据集上提升了 3.8%。虽然 NLLB-SigLIP-Large 在文本到图像检索方面略强,但性能差距仍然很小,在 3% 以内。
图像到文本召回率@5 性能:
文本到图像召回率@5 性能:
纯文本密集检索性能
与其前代模型类似,jina-clip-v2 的文本编码器也可以作为一个高效的多语言密集检索器。
在综合性的多语言 MTEB 基准测试中,jina-clip-v2 表现出色,在检索任务和语义相似度任务中分别取得了 69.86% 和 67.77% 的高分,展现了其多功能性,和专门的文本向量模型 jina-embeddings-v3 相比也有竞争力。
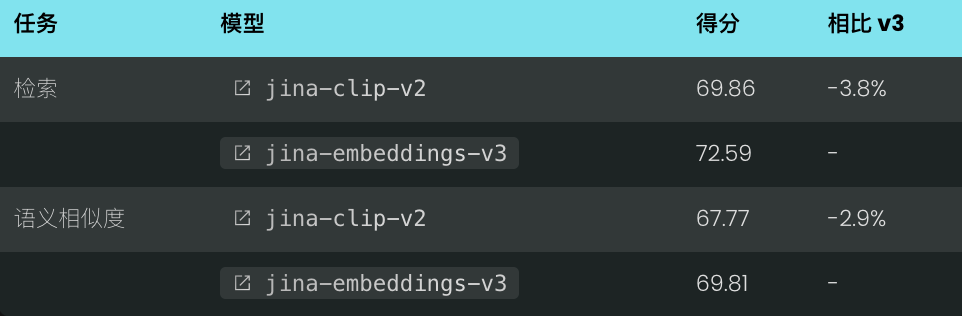
此外,在英语文本检索任务中,jina-clip-v2 的性能持续优于前代版本和 NLLB-SigLIP,尤其在检索性能方面,其得分几乎是 NLLB-SigLIP 的两倍。

可变维度输出的性能评估
jina-clip-v2 的文本和图像编码器均引入了俄罗斯套娃表征学习(Matryoshka Representation Learning, MRL)技术,来实现灵活的灵活的输出维度长度。输出维度可以从 1024 截断至 64 维,并在很大程度上能保持原有性能。
我们的评估结果表明,即使是激进的 75% 维度削减,模型在文本、图像和跨模态任务中仍能保持 99% 以上的性能,展现出了 jina-clip-v2 极高的压缩效率。
图像分类(截断维度)
为了全面评估图像分类性能,我们使用了涵盖多个领域的基准数据集,包括 VTAB(19 个基准测试)、VOC 2007、SUN397、STL10、Rendered SST2、ObjectNet、MNIST、GTSRB、FGVC-Aircraft、FER 2013、Country211、Cars196 以及 ImageNet 系列(A、O、1k、Sketch、v2)。
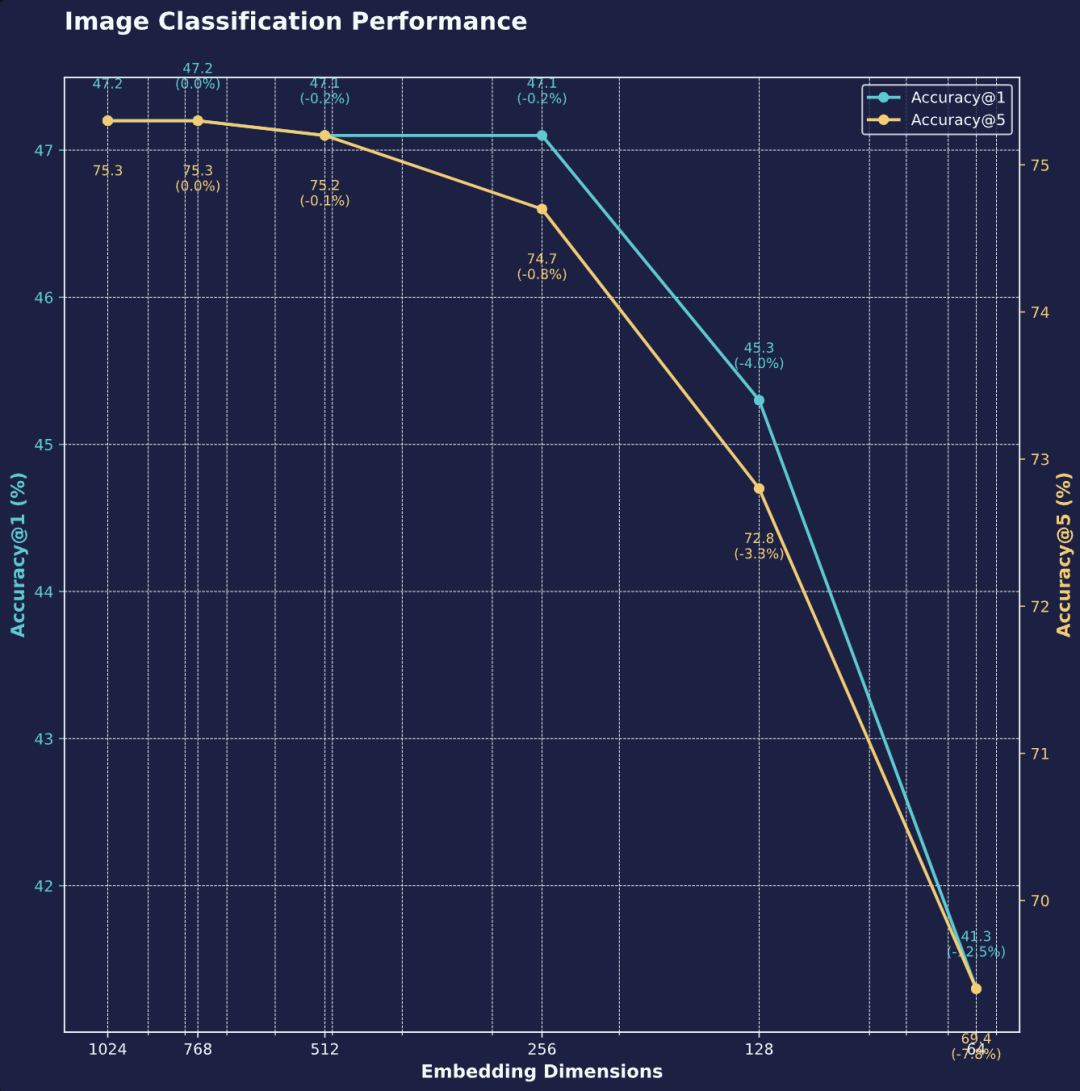
在 37 个不同的图像分类基准测试中,jina-clip-v2 的图像编码器对维度截断表现出良好的鲁棒性。从 1024 维压缩到 64 维,94% 的压缩率,仅仅导致 top-5 准确率下降 8%,top-1 准确率下降 12.5%,体现了 jina-clip-v2 在低资源环境下高效部署的潜力。
跨模态检索 (截断维度)
我们基于六个基准测试对 Jina CLIP v2 的跨模态检索性能进行了评估,其中三个为多语言基准测试:Crossmodal-3600(36 种语言)、flickr30k(仅英语)、flickr8k(仅英语)、MS COCO Captions(仅英语)、Multilingual MS COCO Captions(10 种语言)和 XTD 200(27 种语言)。
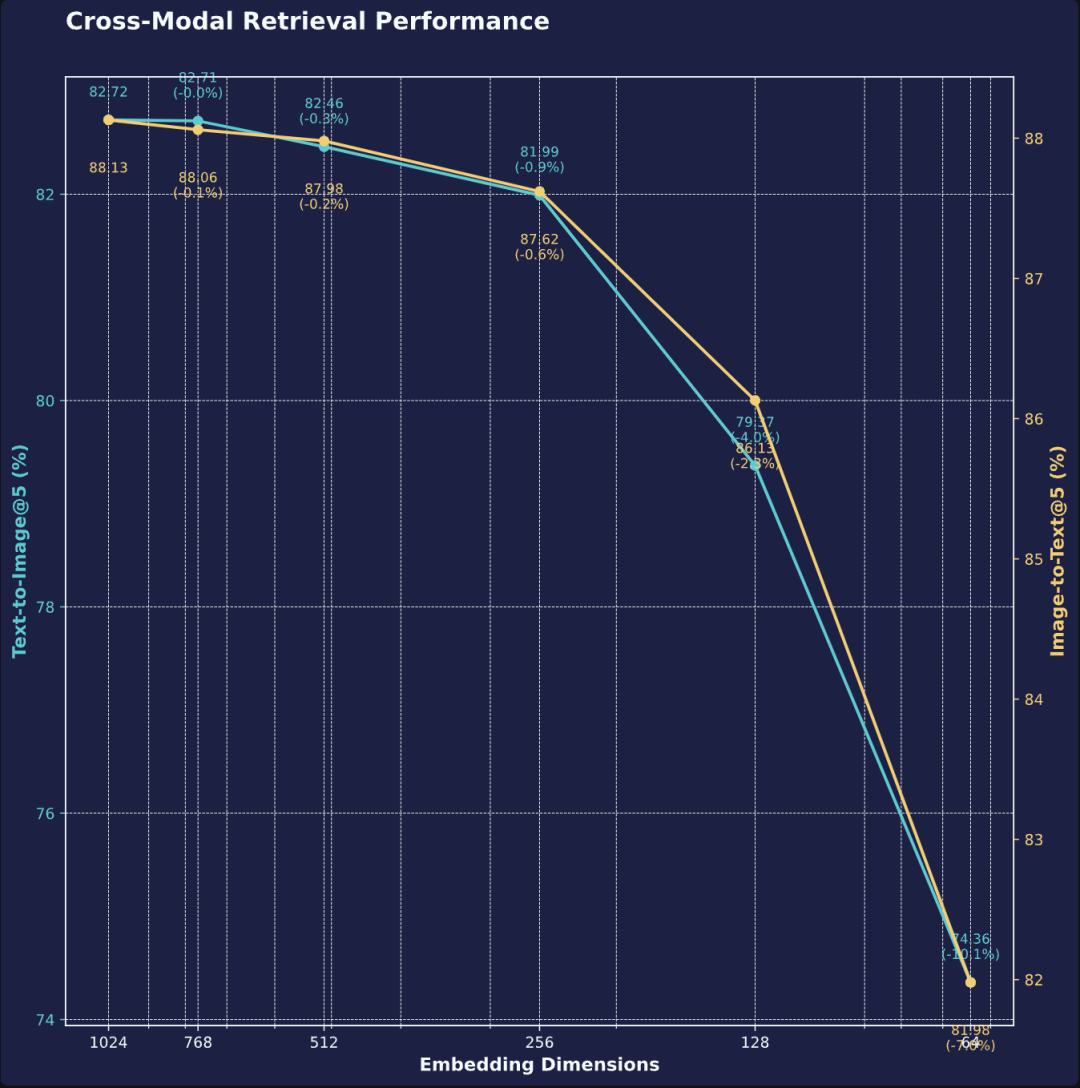
即使在维度大幅减少 94%(降至 64 维)的情况下,使用截断后的图像和文本向量进行跨模态检索仍能保持出色的性能,图像到文本和文本到图像检索性能分别保持在 93% 和 90%。
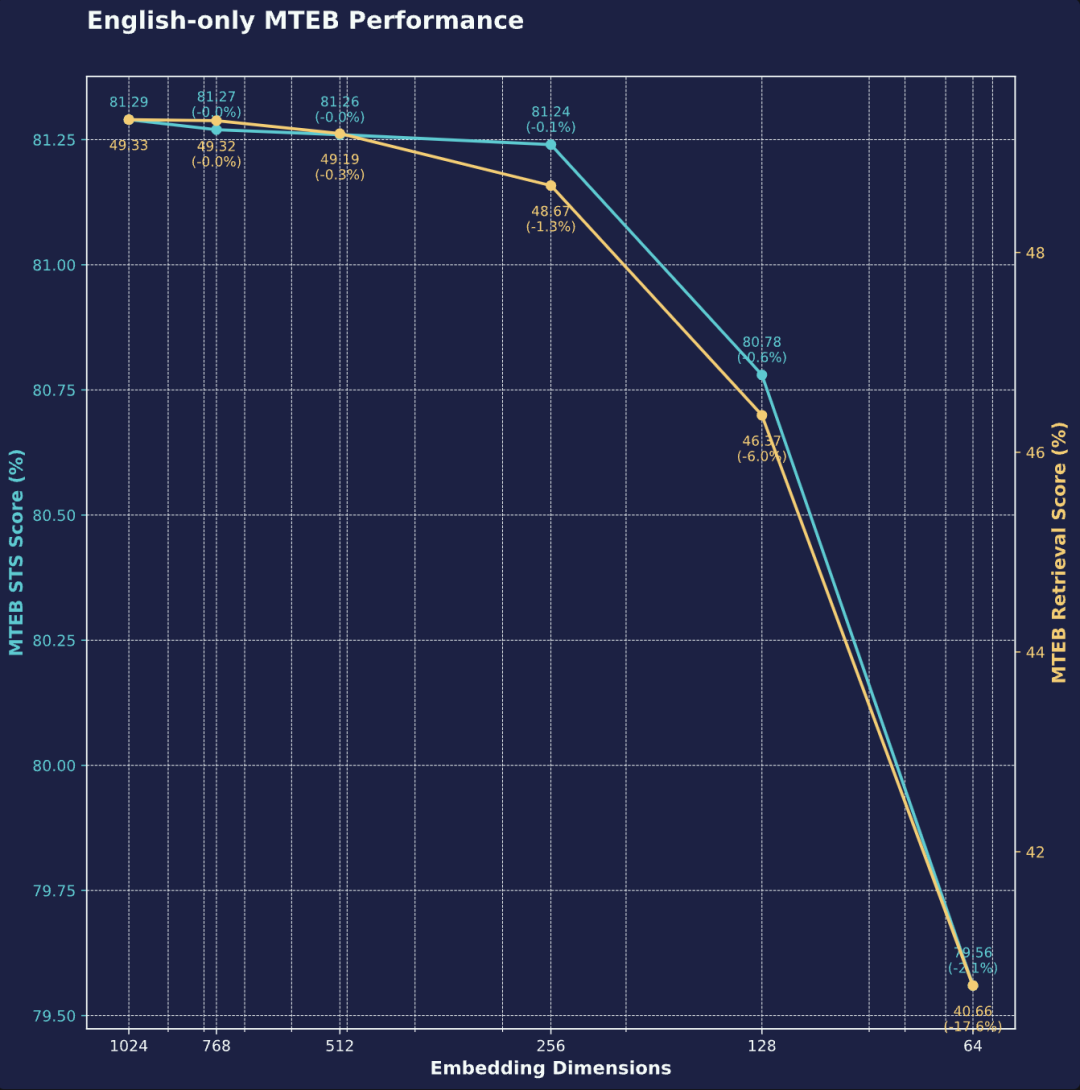
纯文本检索 (截断维度)
在仅英语的 MTEB 基准测试中,将向量维度从 1024 压缩至 64 维后,语义相似度得分仅下降 2.1%,而检索性能下降 17.5%。
快速开始
通过 API 调用
调用我们的 API 最快最简单的上手方式,你只需发送一段文本、一张图片(Base64 编码或图片链接),并指定向量维度即可(默认为 1024 维,下面示例中使用了 768 维)。
import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v2',
'encoding_type': 'float',
'dimensions': '768'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")请将代码中的 <YOUR_JINA_AI_API_KEY> 替换成你自己的 Jina API Key。还没有 API Key?没关系,点击官网即可获取,内含一百万免费 Toekn。
Token 消耗计算
API 调用会根据处理的文本和图片大小计算 Token 消耗量。图片的计费方式是:将图片切分成多个 512x512 像素的小块,每个小块计费 4,000 Token。为了控制成本,我们建议在调用 API 前,将图片调整到 512x512 像素。

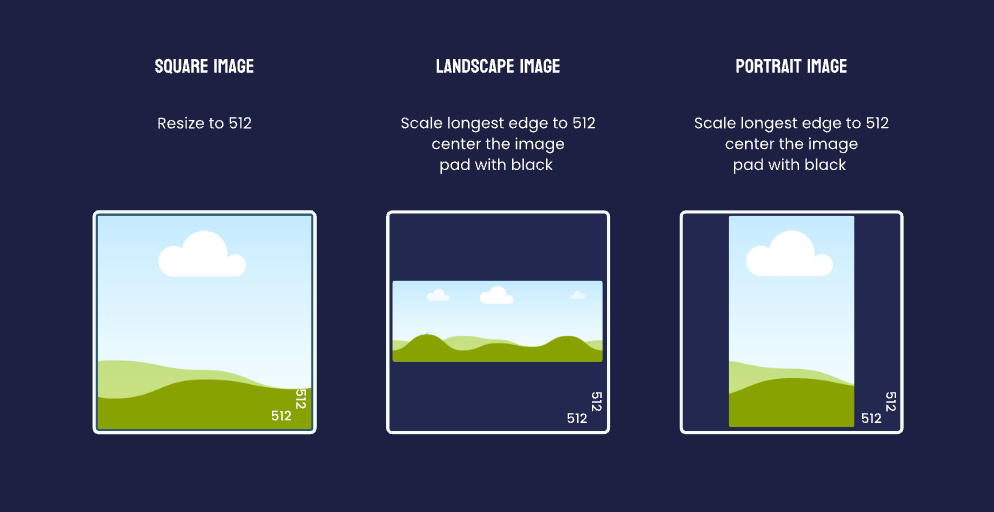
如果是正方形图片,调整到 512x512 像素是最经济的选择。如果需要保持图片原比例,把图片最长边缩放到 512 像素,图片居中,用黑色填充。一般来说,直接将图片调整到 512x512 像素就能满足需求。
云平台部署
Jina CLIP v2 还可以直接部署在 AWS、Azure 和 GCP 等主流云平台上,方便大家根据需求灵活选择。更多定价信息请参考对应平台官方页面:
-
**AWS Marketplace:**https://aws.amazon.com/marketplace/pp/prodview-bfbctuqmky676
-
Microsoft Azure Marketplace **:**https://azuremarketplace.microsoft.com/en-gb/marketplace/apps?search=Jina
-
Google Cloud Marketplace:****https://console.cloud.google.com/marketplace/browse?q=jina
向量数据库集成
-
Pinecone:****https://docs.pinecone.io/models/jina-clip-v2
-
Weav iate:****https://weaviate.io/developers/weaviate/model-providers/jinaai/embeddings-multimodal
-
Qdrant:****https://qdrant.tech/documentation/embeddings/jina-embeddings/
结论
Jina AI 继今年 6 月推出 Jina CLIP v1,9 月推出前沿的多语言模型 Jina Embeddings v3 之后,再次凭借 Jina CLIP v2 取得了重大进展。
Jina CLIP v1 扩展了 OpenAI CLIP 模型的文本输入能力,最高可达 8192 个 token。如今,Jina CLIP v2 在此基础上实现了三大突破:支持 89 种语言 ,图像分辨率提升至 512x512 ,并实现了灵活的输出维度长度,进一步提升了模型表征性能和鲁棒性。
类 CLIP 模型已成为通用多模态应用的基石。Jina CLIP v2 进一步提升了 CLIP 模型的性能,打破语言障碍,实现了更精准的跨模态理解和检索。我们相信这次发布兑现了承诺,Jina CLIP v2 让全球开发者能够应用更强大、更易用的多模态搜索能力。