1、安装步骤
1、上传

cd /opt/modules2、解压
tar -zxf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/installs3、重命名
cd /opt/installs
mv spark-3.1.2-bin-hadoop3.2 spark-local4、创建软链接
ln -s spark-local spark5、配置环境变量:
vi /etc/profile
export SPARK_HOME=/opt/installs/spark
export PATH=$SPARK_HOME/bin:$PATH
5、安装python
通过Anaconda 安装 ,因为这个软件不仅有python还有其他的功能,比单纯安装python功能要强大。
实现Linux机器上使用Anaconda部署Python
conda list:列举所有的包
conda install 包名:安装库包
conda remove 包名:移除库包安装这个软件的另一个好处:具有资源环境隔离功能,方便基于不同版本不同环境进行测试开发

进入某个环境,退出某个环境的命令:
base:Anaconda自带的基础环境
# 切换
conda activate base
# 关闭
conda deactivate下载链接:下载:https://repo.anaconda.com/archive/
1)上传
cd /opt/modules-
安装
添加执行权限
chmod u+x Anaconda3-2021.05-Linux-x86_64.sh
执行
sh ./Anaconda3-2021.05-Linux-x86_64.sh
过程
#第一次:【直接回车,然后按q】
Please, press ENTER to continue
>>>
#第二次:【输入yes】
Do you accept the license terms? [yes|no]
[no] >>> yes
#第三次:【输入解压路径:/opt/installs/anaconda3】
[/root/anaconda3] >>> /opt/installs/anaconda3
#第四次:【输入yes,是否在用户的.bashrc文件中初始化
Anaconda3的相关内容】
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>> yes
安装完成之后,进行环境变量的刷新
# 刷新环境变量
source /root/.bashrc
# 激活虚拟环境,如果需要关闭就使用:conda deactivate
conda activate输入python3 查看命令是否可用
配置环境变量:
# 编辑环境变量
vi /etc/profile
# 添加以下内容
# Anaconda Home
export ANACONDA_HOME=/opt/installs/anaconda3
export PATH=$PATH:$ANACONDA_HOME/bin刷新环境变量,并且做一个软链接
# 刷新环境变量
source /etc/profile
小结:实现Linux机器上使用Anaconda部署Python
3:单机部署:Spark Python Shell
目标:掌握Spark Shell的基本使用
实施
功能:提供一个交互式的命令行,用于测试开发Spark的程序代码
Spark的客户端bin目录下:提供了多个测试工具客户端
启动
核心
# 创建软连接
ln -s /opt/installs/anaconda3/bin/python3 /usr/bin/python3
# 验证
echo $ANACONDA_HOME2、测试使用
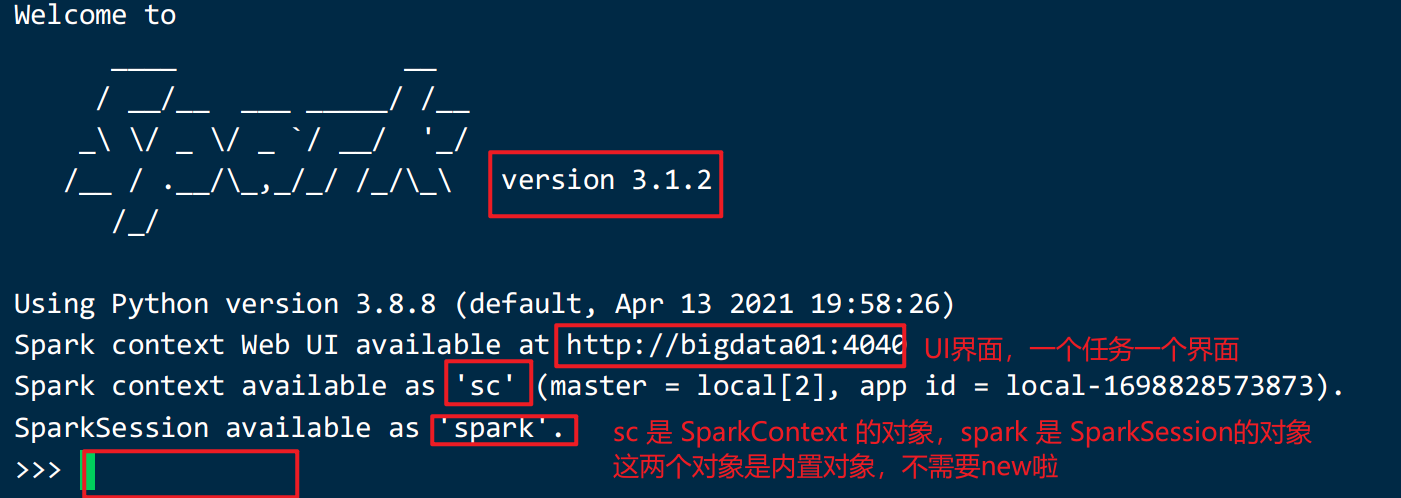
Spark Python Shell 是一个交互工具,可以启动spark中的交互工具,里面可以写代码
# 启动Python开发Spark的交互命令行
# --master:用于指定运行的模式,--master yarn
# local[2]:使用本地模式,并且只给2CoreCPU来运行程序
/opt/installs/spark/bin/pyspark --master local[2]