1、定位一组元素
python
h获取所有按钮
buttons = page.locator('button').all()
# 获取所有按钮的数量
button_count = page.locator('button').count()
# 点击第二个按钮
second_button = page.locator('button').nth(1)
second_button.click()
使用 locator().evaluate_all(fn) 方法对所有元素执行函数
# 获取所有按钮的文本内容
button_texts = page.locator('button').evaluate_all('nodes => nodes.map(node => node.textContent)')
evaluate_all允许你对所有匹配的元素执行一个 JavaScript 函数,并返回结果。这个函数 fn 在浏览器上下文中运行,因此它可以访问 DOM 元素。2、设置cookies
context.add_cookies(cookies_data)cookie数据是一个数组,数组中每个元素是一个字典,字典的键是固定的
有name,value,domain,path等,如果不设置domain、path会报错
python
page.set_cookie({'name': 'test', 'value': '123', 'domain': 'example.com'})
cookies = page.context.cookies()
print(cookies)
# 登录后保存storage state 到指定的文件
storage = context.storage_state(path="auth/state.json")
其他页面使用storage,就不需要登录了
context = browser.new_context(storage_state="state.json")eg:
python
from playwright.sync_api import sync_playwright
def main():
cookies_data = [
{
'name': '5',
'value': 'CocIXmZhewK0/h11GYndAg==',
'domain': '.5dns.org',
'path': '/'
}
]
with sync_playwright() as p:
browser = p.chromium.launch(headless=False, slow_mo=1000)
context = browser.new_context()
context.add_cookies(cookies_data)
page = context.new_page()
page.goto("http://example.app.com")
page.wait_for_timeout(5000)
for i in range(4):
page.get_by_placeholder('请选择').nth(i).click()
page.get_by_role("list").get_by_text("通过").click()
if __name__ == '__main__':
main()3、录制脚本
python
playwright codegen 所要打开的网站
eg:
playwright codegen https://www.baidu.com
以iphone11模式打开百度
playwright codegen --device="iPhone 11" https://www.baidu.com
执行身份验证并关闭浏览器后,auth.json将包含存储状态
playwright codegen --save-storage=auth.json
在进行录制时,携带存储的cookie等上边操作后保存的信息
playwright open --load-storage=auth.json my.web.app
playwright codegen --load-storage=auth.json my.web.app终端执行上述命令后,打开两个窗口,一个浏览器,一个代码录制窗口,自己操作浏览器,右边就会生成对应的代码,还可切换成不同语言的,操作完成后,可以复制到代码编辑器,运行回放
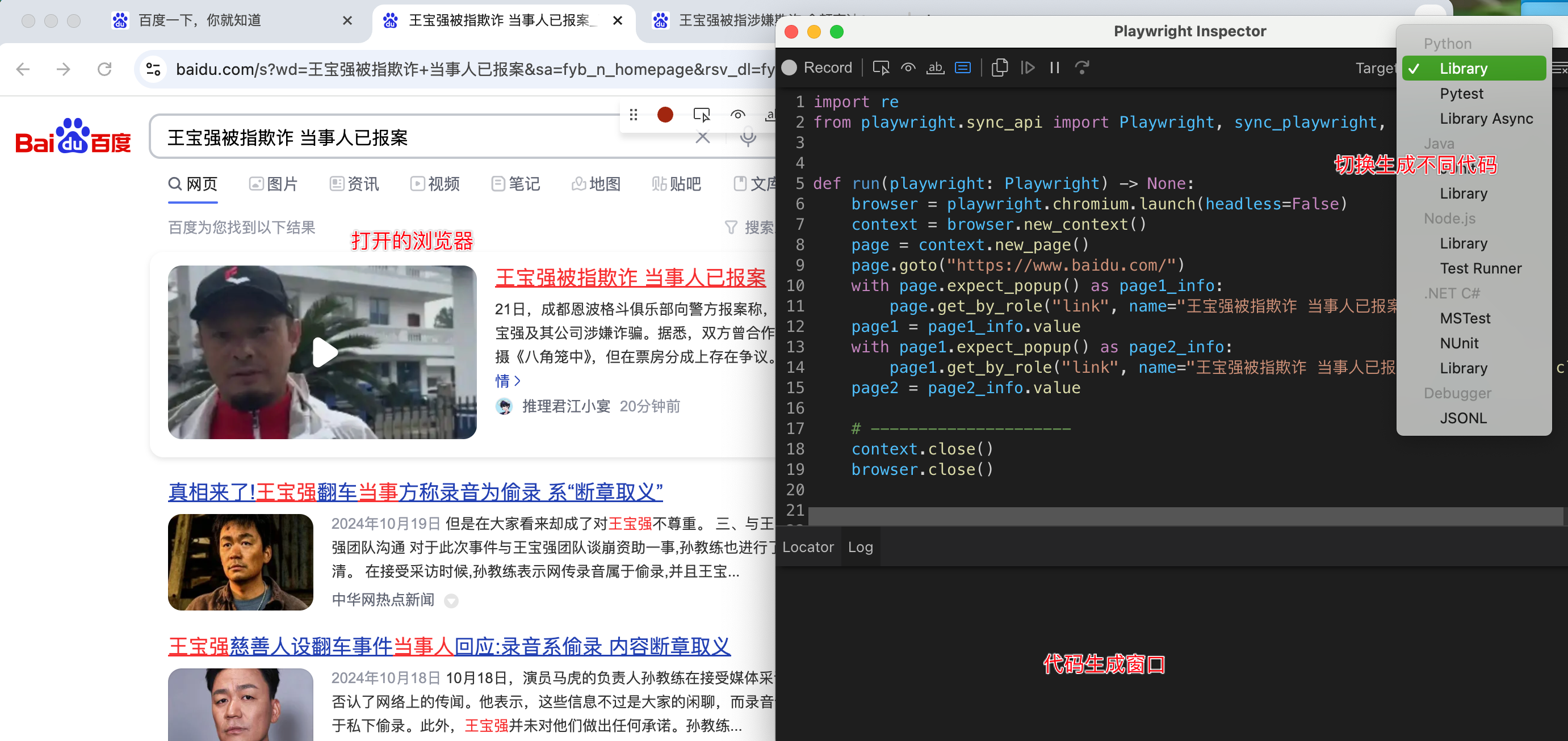
python
import re
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/")
page.locator("#kw").click()
page.locator("#kw").fill("theshy")
page.get_by_role("button", name="百度一下").click()
with page.expect_popup() as page1_info:
page.get_by_label("标题:已确认TheShy与Rookie重回IG").click()
page1 = page1_info.value
# ---------------------
context.close()
browser.close()
if __name__ == '__main__':
with sync_playwright() as playwright:
run(playwright)如果自己定位不到的元素,可以使用录制方式,定位试试
打开手机百度

4、截图
python
page.screenshot(path="screenshot.png")
截全屏
page.screenshot(path="screenshot.png", full_page=True)
图片数据流获取
screenshot_bytes = page.screenshot()
print(base64.b64encode(screenshot_bytes).decode())
截取单个元素图片
page.locator(".header").screenshot(path="screenshot.png")5、执行过程录屏
python
context = browser.new_context(record_video_dir="videos/")
# 确保调用 close, videos视频才会保存
context.close()
context = browser.new_context(
record_video_dir="videos/",
record_video_size={"width": 640, "height": 480}
)
打印视频路径
path = page.video.path()视频格式.webm,可使用浏览器打开
