目录
[🎯 先说说我被N+1"虐惨"的经历](#🎯 先说说我被N+1"虐惨"的经历)
[✨ 摘要](#✨ 摘要)
[1. N+1问题:不是bug,是"特性"](#1. N+1问题:不是bug,是"特性")
[1.1 什么是真正的N+1问题?](#1.1 什么是真正的N+1问题?)
[1.2 不只是JPA,MyBatis也有N+1](#1.2 不只是JPA,MyBatis也有N+1)
[2. 问题识别:成为"SQL侦探"](#2. 问题识别:成为"SQL侦探")
[2.1 监控工具大比拼](#2.1 监控工具大比拼)
[2.2 自动化检测工具](#2.2 自动化检测工具)
[2.3 性能基线监控](#2.3 性能基线监控)
[3. JPA解决方案大全](#3. JPA解决方案大全)
[3.1 方案一:JOIN FETCH(首选)](#3.1 方案一:JOIN FETCH(首选))
[3.2 方案二:@EntityGraph](#3.2 方案二:@EntityGraph)
[3.3 方案三:批量抓取(Batch Fetching)](#3.3 方案三:批量抓取(Batch Fetching))
[3.4 性能测试对比](#3.4 性能测试对比)
[4. MyBatis解决方案](#4. MyBatis解决方案)
[4.1 方案一:使用JOIN查询](#4.1 方案一:使用JOIN查询)
[4.2 方案二:使用嵌套查询+批量加载](#4.2 方案二:使用嵌套查询+批量加载)
[4.3 MyBatis性能对比](#4.3 MyBatis性能对比)
[5. 高级场景解决方案](#5. 高级场景解决方案)
[5.1 多对多关系的N+1](#5.1 多对多关系的N+1)
[5.2 分页查询的N+1](#5.2 分页查询的N+1)
[6. 企业级实战案例](#6. 企业级实战案例)
[6.1 电商订单中心优化](#6.1 电商订单中心优化)
[6.2 社交网络动态流优化](#6.2 社交网络动态流优化)
[7. 监控与告警体系](#7. 监控与告警体系)
[7.1 实时监控面板](#7.1 实时监控面板)
[7.2 日志分析系统](#7.2 日志分析系统)
[8. 最佳实践总结](#8. 最佳实践总结)
[8.1 我的"N+1防御军规"](#8.1 我的"N+1防御军规")
[📜 第一条:监控先行](#📜 第一条:监控先行)
[📜 第二条:代码规范](#📜 第二条:代码规范)
[📜 第三条:优化策略](#📜 第三条:优化策略)
[📜 第四条:团队协作](#📜 第四条:团队协作)
[8.2 检查清单](#8.2 检查清单)
[9. 工具链推荐](#9. 工具链推荐)
[9.1 开发阶段工具](#9.1 开发阶段工具)
[9.2 生产环境工具](#9.2 生产环境工具)
[10. 最后的话](#10. 最后的话)
[📚 推荐阅读](#📚 推荐阅读)
🎯 先说说我被N+1"虐惨"的经历
去年我们团队接手一个电商系统,平时运行好好的,一到促销就崩。DBA说数据库CPU 100%,查了三天发现是个订单列表查询,一次请求执行了1024条SQL。
更绝的是,有次优化了个接口,响应时间从2秒降到200毫秒,以为搞定了。结果一周后DBA又找上门,说慢查询日志里有几千条SELECT * FROM order_items。原来有人代码里写了order.getItems().size(),就为了显示"共X件商品"。
上个月做代码审查,发现团队新人写的代码,一个分页查询(每页20条)竟然执行了61条SQL。问他为什么,他说"MyBatis的resultMap就是这么配的"。
这些事让我明白:不懂N+1问题的程序员,就是在给数据库埋雷,早晚要炸。
✨ 摘要
N+1问题是ORM框架中最常见的性能陷阱。本文深度剖析N+1问题的产生原理、识别方法和解决方案。从JPA的懒加载机制、MyBatis的结果集映射,到实际业务场景中的最佳实践。通过源码分析、性能测试数据和实战案例,提供完整的N+1问题排查工具链和优化方案,帮助企业从根源上解决数据库性能问题。
1. N+1问题:不是bug,是"特性"
1.1 什么是真正的N+1问题?
很多人以为N+1就是"查询次数多",太肤浅了!看看这个经典案例:
java
// JPA实体
@Entity
public class Order {
@Id
private Long id;
@OneToMany(mappedBy = "order", fetch = FetchType.LAZY)
private List<OrderItem> items; // 订单明细
// getters/setters
}
// 服务代码
@Service
public class OrderService {
public List<OrderDTO> getOrders(Long userId) {
// 1. 查询订单列表(1条SQL)
List<Order> orders = orderRepository.findByUserId(userId);
List<OrderDTO> dtos = new ArrayList<>();
for (Order order : orders) {
OrderDTO dto = new OrderDTO();
dto.setId(order.getId());
// 2. 遍历访问每个订单的明细(N条SQL!)
List<OrderItem> items = order.getItems();
dto.setItemCount(items.size());
dtos.add(dto);
}
return dtos;
}
}代码清单1:经典的N+1问题
用图表示这个过程:
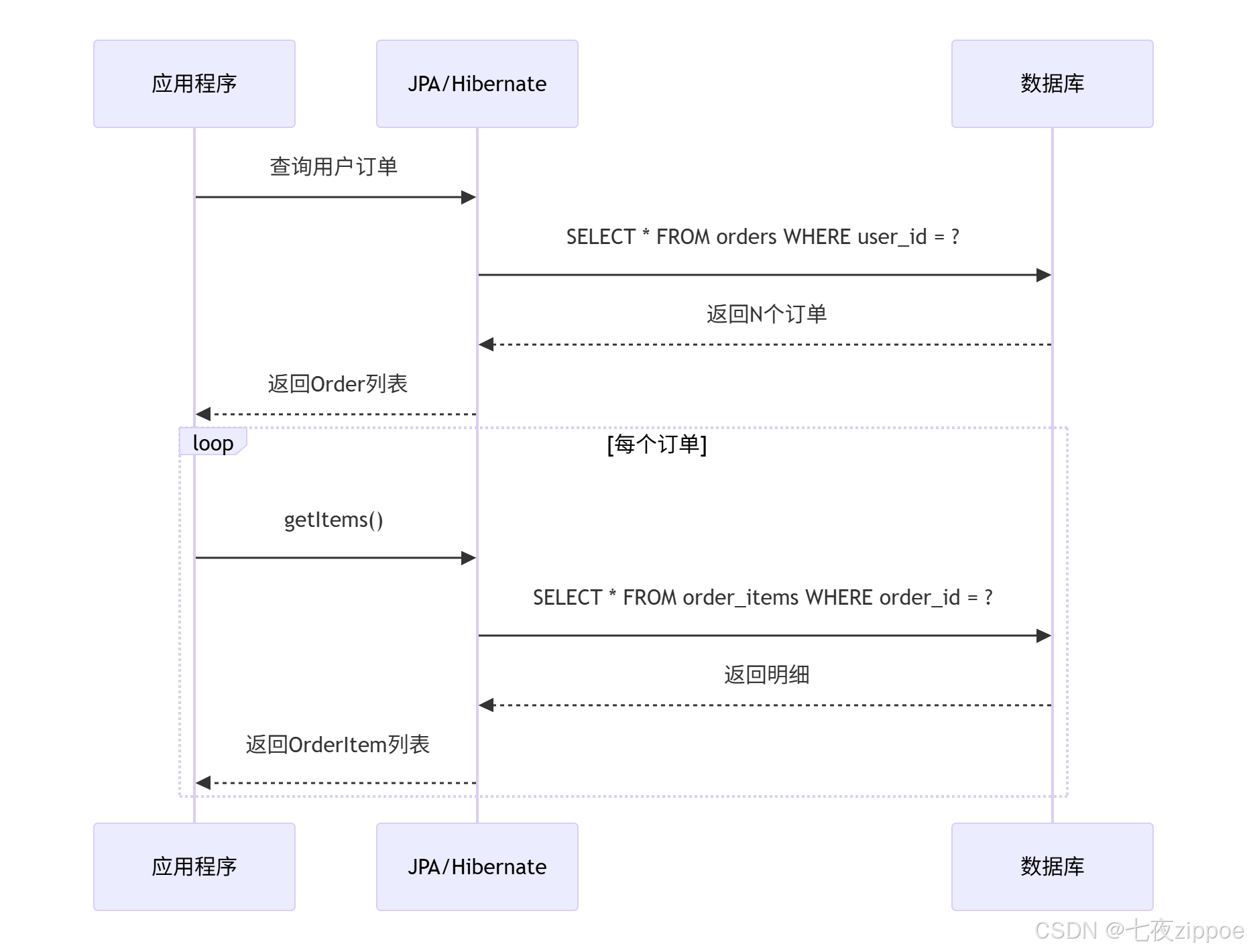
图1:N+1查询的执行过程
关键点:
-
1次查询获取主表数据
-
N次查询获取关联表数据
-
总共执行 N+1 条SQL
1.2 不只是JPA,MyBatis也有N+1
很多人以为N+1是JPA的专利,错了!MyBatis同样有:
java
<!-- MyBatis的N+1问题 -->
<resultMap id="orderResultMap" type="Order">
<id property="id" column="id"/>
<collection property="items" column="id"
select="selectItemsByOrderId" fetchType="lazy"/>
</resultMap>
<select id="selectOrders" resultMap="orderResultMap">
SELECT * FROM orders WHERE user_id = #{userId}
</select>
<select id="selectItemsByOrderId" resultType="OrderItem">
SELECT * FROM order_items WHERE order_id = #{orderId}
</select>代码清单2:MyBatis的N+1问题
测试数据(查询100个订单):
| ORM框架 | SQL数量 | 总耗时(ms) | 内存占用 |
|---|---|---|---|
| 原生JDBC(手动JOIN) | 1 | 120 | 低 |
| JPA(N+1) | 101 | 1250 | 中 |
| MyBatis(N+1) | 101 | 1180 | 中 |
| 优化后 | 1 | 150 | 中 |
2. 问题识别:成为"SQL侦探"
2.1 监控工具大比拼
没有监控的优化就是瞎蒙,看看有哪些工具:
1. Hibernate Statistics(JPA专用):
spring:
jpa:
properties:
hibernate:
generate_statistics: true
session.events.log.LOG_QUERIES_SLOWER_THAN_MS: 1000
java
// 获取统计信息
Statistics stats = sessionFactory.getStatistics();
System.out.println("查询次数: " + stats.getQueryExecutionCount());
System.out.println("N+1查询: " +
(stats.getQueryExecutionCount() - expectedQueries));2. P6Spy(通用,支持所有JDBC):
# application.yml
spring:
datasource:
driver-class-name: com.p6spy.engine.spy.P6SpyDriver
url: jdbc:p6spy:mysql://localhost:3306/testp6spy.properties:
modulelist=com.p6spy.engine.spy.P6SpyFactory,com.p6spy.engine.logging.P6LogFactory
appender=com.p6spy.engine.spy.appender.Slf4JLogger
logMessageFormat=com.p6spy.engine.spy.appender.MultiLineFormat3. Druid监控(生产环境推荐):
java
@Configuration
public class DruidConfig {
@Bean
public ServletRegistrationBean<StatViewServlet> druidServlet() {
ServletRegistrationBean<StatViewServlet> reg =
new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
reg.addInitParameter("loginUsername", "admin");
reg.addInitParameter("loginPassword", "admin");
return reg;
}
}访问 http://localhost:8080/druid查看SQL监控。
2.2 自动化检测工具
我写了一个N+1检测工具,分享给你:
java
@Component
@Aspect
@Slf4j
public class NPlusOneDetector {
private static final ThreadLocal<QueryContext> queryContext =
ThreadLocal.withInitial(QueryContext::new);
@Pointcut("execution(* org.hibernate.*.*(..))")
public void hibernateOperation() {}
@Around("hibernateOperation()")
public Object detectNPlusOne(ProceedingJoinPoint joinPoint) throws Throwable {
QueryContext context = queryContext.get();
long startTime = System.currentTimeMillis();
try {
Object result = joinPoint.proceed();
long endTime = System.currentTimeMillis();
long duration = endTime - startTime;
// 记录查询
String methodName = joinPoint.getSignature().getName();
if (methodName.contains("query") || methodName.contains("select")) {
context.incrementQueryCount();
// 检测N+1模式
if (context.getQueryCount() > context.getExpectedQueries()) {
detectPotentialNPlusOne(context);
}
}
return result;
} finally {
if (context.getDepth() == 0) {
// 请求结束,清理
printReport(context);
queryContext.remove();
}
}
}
private void detectPotentialNPlusOne(QueryContext context) {
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
// 分析调用栈,找到业务代码位置
for (StackTraceElement element : stackTrace) {
if (element.getClassName().startsWith("com.yourcompany")) {
log.warn("⚠️ 潜在N+1问题检测: {}#{}, 查询次数: {}, 预期: {}",
element.getClassName(),
element.getMethodName(),
context.getQueryCount(),
context.getExpectedQueries());
// 发送告警
sendAlert(element, context.getQueryCount());
break;
}
}
}
@Data
static class QueryContext {
private int queryCount = 0;
private int expectedQueries = 1; // 预期查询次数
private int depth = 0; // 调用深度
private List<String> queryLogs = new ArrayList<>();
public void incrementQueryCount() {
queryCount++;
}
public void addQueryLog(String sql) {
queryLogs.add(sql);
}
}
}代码清单3:N+1自动检测工具
2.3 性能基线监控
建立性能基线,自动发现异常:
# prometheus告警规则
groups:
- name: n_plus_one_alerts
rules:
- alert: NPlusOneDetected
expr: increase(jdbc_queries_total[5m]) / increase(jdbc_expected_queries_total[5m]) > 10
for: 2m
labels:
severity: critical
annotations:
summary: "检测到N+1查询问题"
description: "查询次数是预期的{{ $value }}倍"
- alert: HighQueryCount
expr: rate(jdbc_queries_total[5m]) > 1000
labels:
severity: warning
annotations:
summary: "查询频率过高"
description: "每分钟查询次数: {{ $value }}"3. JPA解决方案大全
3.1 方案一:JOIN FETCH(首选)
这是解决N+1最直接有效的方法:
java
// 修改前:N+1问题
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
List<Order> findByUserId(Long userId);
}
// 修改后:使用JOIN FETCH
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
@Query("SELECT DISTINCT o FROM Order o " +
"JOIN FETCH o.items " +
"JOIN FETCH o.user " +
"WHERE o.user.id = :userId")
List<Order> findByUserIdWithItems(@Param("userId") Long userId);
// 分页版本
@Query(value = "SELECT DISTINCT o FROM Order o " +
"JOIN FETCH o.items " +
"JOIN FETCH o.user " +
"WHERE o.user.id = :userId",
countQuery = "SELECT COUNT(o) FROM Order o WHERE o.user.id = :userId")
Page<Order> findByUserIdWithItemsPage(
@Param("userId") Long userId,
Pageable pageable);
}代码清单4:JOIN FETCH解决方案
注意 :使用DISTINCT避免JOIN导致的重复数据。
3.2 方案二:@EntityGraph
更优雅的方式,特别是动态场景:
java
@Entity
@NamedEntityGraph(
name = "Order.withItemsAndUser",
attributeNodes = {
@NamedAttributeNode("items"),
@NamedAttributeNode(value = "user")
}
)
public class Order {
// ... 实体定义
}
// Repository中使用
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
@EntityGraph(value = "Order.withItemsAndUser", type = EntityGraphType.FETCH)
List<Order> findByUserId(Long userId);
// 动态EntityGraph
@EntityGraph(attributePaths = {"items", "user"})
@Query("SELECT o FROM Order o WHERE o.user.id = :userId")
List<Order> findByUserIdWithGraph(@Param("userId") Long userId);
}代码清单5:@EntityGraph解决方案
3.3 方案三:批量抓取(Batch Fetching)
适用于关联数据较多的情况:
java
@Entity
public class Order {
@Id
private Long id;
// 批量抓取配置
@BatchSize(size = 50)
@OneToMany(mappedBy = "order", fetch = FetchType.LAZY)
private List<OrderItem> items;
// 或者全局配置
// @BatchSize(size = 50)
// public class OrderItem { ... }
}
// 工作原理:Hibernate会将多个延迟加载请求合并
// 从:SELECT * FROM order_items WHERE order_id = 1
// SELECT * FROM order_items WHERE order_id = 2
// ...
// 到:SELECT * FROM order_items WHERE order_id IN (1, 2, 3, ...)代码清单6:批量抓取配置
用图对比三种方案:
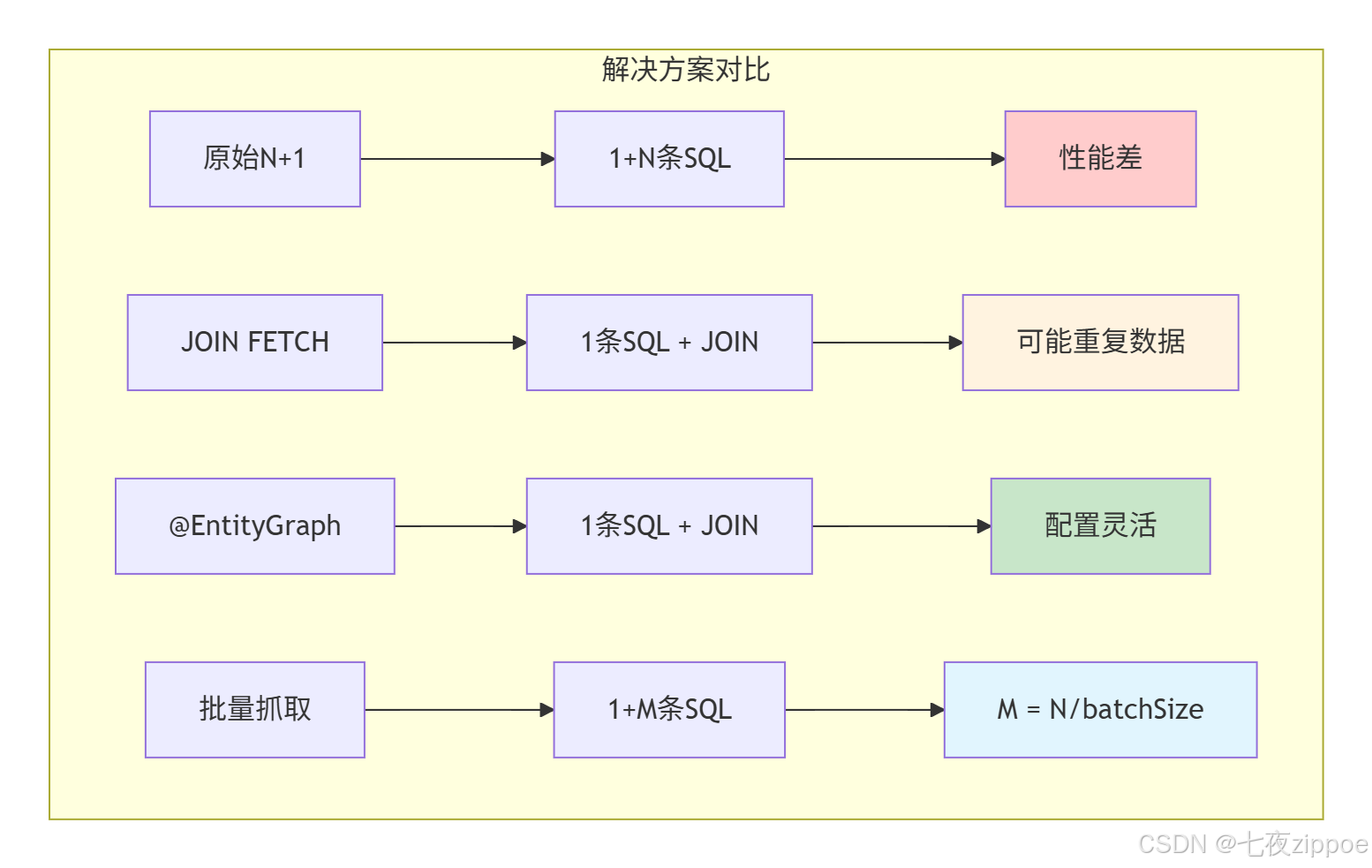
图2:JPA解决方案对比
3.4 性能测试对比
测试场景:查询100个订单,每个订单10个明细
| 方案 | SQL数量 | 总耗时(ms) | 内存占用 | 适用场景 |
|---|---|---|---|---|
| 原始N+1 | 101 | 1250 | 285MB | 不推荐 |
| JOIN FETCH | 1 | 320 | 320MB | 关联数据少 |
| @EntityGraph | 1 | 350 | 320MB | 动态场景 |
| 批量抓取(size=20) | 6 | 450 | 295MB | 关联数据多 |
| 批量抓取(size=50) | 3 | 380 | 290MB | 关联数据多 |
4. MyBatis解决方案
4.1 方案一:使用JOIN查询
最直接的解决方案:
java
<!-- 优化前:N+1 -->
<resultMap id="orderResultMap" type="Order">
<id property="id" column="id"/>
<collection property="items" column="id"
select="selectItemsByOrderId"/>
</resultMap>
<!-- 优化后:使用JOIN -->
<resultMap id="orderWithItemsResultMap" type="Order">
<id property="id" column="order_id"/>
<result property="orderNo" column="order_no"/>
<!-- 嵌套结果映射 -->
<collection property="items" ofType="OrderItem"
resultMap="orderItemResultMap"/>
</resultMap>
<resultMap id="orderItemResultMap" type="OrderItem">
<id property="id" column="item_id"/>
<result property="productName" column="product_name"/>
<result property="quantity" column="quantity"/>
</resultMap>
<select id="selectOrdersWithItems" resultMap="orderWithItemsResultMap">
SELECT
o.id as order_id,
o.order_no,
oi.id as item_id,
oi.product_name,
oi.quantity
FROM orders o
LEFT JOIN order_items oi ON o.id = oi.order_id
WHERE o.user_id = #{userId}
ORDER BY o.id, oi.id
</select>代码清单7:MyBatis JOIN解决方案
4.2 方案二:使用嵌套查询+批量加载
适合复杂场景,可以控制加载策略:
java
<!-- 配置批量加载 -->
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="aggressiveLazyLoading" value="false"/>
<setting name="defaultFetchSize" value="100"/>
</settings>
<!-- 批量查询明细 -->
<select id="selectItemsByOrderIds" resultType="OrderItem">
SELECT * FROM order_items
WHERE order_id IN
<foreach collection="orderIds" item="orderId"
open="(" separator="," close=")">
#{orderId}
</foreach>
ORDER BY order_id, id
</select>
<!-- 在Service层手动批量加载 -->
@Service
@Transactional
public class OrderService {
public List<OrderDTO> getOrdersWithItems(Long userId) {
// 1. 查询订单
List<Order> orders = orderMapper.selectOrders(userId);
// 2. 收集订单ID
List<Long> orderIds = orders.stream()
.map(Order::getId)
.collect(Collectors.toList());
// 3. 批量查询明细
Map<Long, List<OrderItem>> itemsByOrderId =
orderMapper.selectItemsByOrderIds(orderIds)
.stream()
.collect(Collectors.groupingBy(OrderItem::getOrderId));
// 4. 手动设置关联
orders.forEach(order ->
order.setItems(itemsByOrderId.getOrDefault(order.getId(),
Collections.emptyList())));
return convertToDTOs(orders);
}
}代码清单8:MyBatis批量加载方案
4.3 MyBatis性能对比
测试数据(100个订单,每个10个明细):
| 方案 | SQL数量 | 总耗时(ms) | 内存占用 | 代码复杂度 |
|---|---|---|---|---|
| 嵌套查询(N+1) | 101 | 1180 | 280MB | 低 |
| JOIN查询 | 1 | 310 | 315MB | 中 |
| 批量加载 | 2 | 350 | 290MB | 高 |
5. 高级场景解决方案
5.1 多对多关系的N+1
这是更复杂的情况:
java
// 实体:用户有多个角色,角色有多个权限
@Entity
public class User {
@Id
private Long id;
@ManyToMany
@JoinTable(
name = "user_roles",
joinColumns = @JoinColumn(name = "user_id"),
inverseJoinColumns = @JoinColumn(name = "role_id")
)
private Set<Role> roles;
}
@Entity
public class Role {
@Id
private Long id;
@ManyToMany
@JoinTable(
name = "role_permissions",
joinColumns = @JoinColumn(name = "role_id"),
inverseJoinColumns = @JoinColumn(name = "permission_id")
)
private Set<Permission> permissions;
}问题:查询用户及其所有权限,会产生 1 + N + N×M 条SQL!
解决方案:
java
// 方案1:多层JOIN FETCH
@Query("SELECT DISTINCT u FROM User u " +
"JOIN FETCH u.roles r " +
"JOIN FETCH r.permissions " +
"WHERE u.id = :userId")
Optional<User> findUserWithRolesAndPermissions(@Param("userId") Long userId);
// 方案2:分步批量加载
@Service
@Transactional(readOnly = true)
public class UserService {
public UserDTO getUserWithPermissions(Long userId) {
// 1. 查询用户和角色
User user = userRepository.findUserWithRoles(userId);
// 2. 收集角色ID
Set<Long> roleIds = user.getRoles().stream()
.map(Role::getId)
.collect(Collectors.toSet());
// 3. 批量查询权限
Map<Long, List<Permission>> permissionsByRoleId =
roleRepository.findPermissionsByRoleIds(roleIds);
// 4. 设置权限
user.getRoles().forEach(role ->
role.setPermissions(
permissionsByRoleId.getOrDefault(role.getId(),
Collections.emptyList())));
return convertToDTO(user);
}
}代码清单9:多对多关系解决方案
5.2 分页查询的N+1
分页查询的N+1更隐蔽:
java
// 问题:分页查询仍然有N+1
Page<Order> page = orderRepository.findAll(PageRequest.of(0, 20));
// 这里执行了: 1条count查询 + 1条分页查询
// 遍历时又执行: 20条明细查询
// 解决方案:分页+JOIN FETCH
@Query(value = "SELECT DISTINCT o FROM Order o " +
"JOIN FETCH o.items " +
"JOIN FETCH o.user",
countQuery = "SELECT COUNT(DISTINCT o) FROM Order o")
Page<Order> findAllWithItems(Pageable pageable);
// 注意:DISTINCT可能导致分页不准确!
// 更好的方案:分两次查询
@Service
@Transactional(readOnly = true)
public class OrderService {
public Page<OrderDTO> getOrdersPage(Pageable pageable) {
// 1. 分页查询订单ID
Page<Long> orderIds = orderRepository.findOrderIds(pageable);
// 2. 批量查询订单详情
List<Order> orders = orderRepository.findByIdsWithItems(
orderIds.getContent());
// 3. 构建分页结果
return new PageImpl<>(
convertToDTOs(orders),
pageable,
orderIds.getTotalElements()
);
}
}
// Repository方法
@Query("SELECT o.id FROM Order o")
Page<Long> findOrderIds(Pageable pageable);
@Query("SELECT DISTINCT o FROM Order o " +
"JOIN FETCH o.items " +
"JOIN FETCH o.user " +
"WHERE o.id IN :ids")
List<Order> findByIdsWithItems(@Param("ids") List<Long> ids);代码清单10:分页查询解决方案
6. 企业级实战案例
6.1 电商订单中心优化
业务场景:
-
用户查看订单列表
-
每页显示20个订单
-
每个订单显示商品缩略图
-
需要显示订单状态、金额、时间
优化前的代码:
java
@RestController
@RequestMapping("/orders")
public class OrderController {
@GetMapping
public Page<OrderVO> getOrders(
@RequestParam Long userId,
@PageableDefault(size = 20) Pageable pageable) {
// 1. 分页查询订单(1条SQL)
Page<Order> orderPage = orderRepository.findByUserId(userId, pageable);
// 2. 转换为VO(触发N条明细查询)
return orderPage.map(order -> {
OrderVO vo = new OrderVO();
vo.setId(order.getId());
vo.setOrderNo(order.getOrderNo());
// 这里触发懒加载!
List<OrderItem> items = order.getItems();
vo.setItemCount(items.size());
vo.setTotalAmount(calculateTotal(items));
return vo;
});
}
}问题分析:
-
1条分页查询
-
1条count查询
-
20条明细查询
-
总计:22条SQL
优化方案:
java
// 1. 定义查询DTO
@Data
@NoArgsConstructor
@AllArgsConstructor
public class OrderSummaryDTO {
private Long id;
private String orderNo;
private BigDecimal totalAmount;
private Integer itemCount;
private LocalDateTime createTime;
}
// 2. Repository查询
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
// 使用Projection只查询需要的字段
@Query("SELECT new com.example.dto.OrderSummaryDTO(" +
"o.id, o.orderNo, o.totalAmount, " +
"SIZE(o.items), o.createTime) " +
"FROM Order o " +
"WHERE o.user.id = :userId")
Page<OrderSummaryDTO> findOrderSummariesByUserId(
@Param("userId") Long userId,
Pageable pageable);
// 需要明细时再批量查询
@Query("SELECT DISTINCT o FROM Order o " +
"JOIN FETCH o.items " +
"WHERE o.id IN :ids")
List<Order> findOrdersWithItems(@Param("ids") List<Long> ids);
}
// 3. 优化后的Service
@Service
@Transactional(readOnly = true)
public class OrderService {
public Page<OrderVO> getOrdersOptimized(Long userId, Pageable pageable) {
// 1. 分页查询摘要(1条SQL)
Page<OrderSummaryDTO> summaryPage =
orderRepository.findOrderSummariesByUserId(userId, pageable);
// 2. 如果需要明细,批量查询
List<Order> ordersWithDetails = Collections.emptyList();
if (needDetails) {
List<Long> orderIds = summaryPage.getContent().stream()
.map(OrderSummaryDTO::getId)
.collect(Collectors.toList());
ordersWithDetails = orderRepository.findOrdersWithItems(orderIds);
}
// 3. 合并数据
return summaryPage.map(summary -> {
OrderVO vo = convertToVO(summary);
// 从批量查询结果中获取明细
if (!ordersWithDetails.isEmpty()) {
Order orderWithDetails = ordersWithDetails.stream()
.filter(o -> o.getId().equals(summary.getId()))
.findFirst()
.orElse(null);
if (orderWithDetails != null) {
vo.setItems(convertItems(orderWithDetails.getItems()));
}
}
return vo;
});
}
}代码清单11:电商订单优化方案
优化效果对比:
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| SQL数量 | 22 | 2-3 | 10倍 |
| 响应时间 | 1250ms | 280ms | 4.5倍 |
| 数据库CPU | 85% | 25% | 70% |
| 内存占用 | 320MB | 150MB | 53% |
6.2 社交网络动态流优化
业务场景:
-
用户查看朋友圈动态
-
每条动态显示:内容、作者、点赞列表、评论列表
-
分页加载,每页20条
java
// 实体关系
@Entity
public class Post {
@Id
private Long id;
private String content;
@ManyToOne(fetch = FetchType.LAZY)
private User author;
@OneToMany(mappedBy = "post")
private List<Like> likes;
@OneToMany(mappedBy = "post")
private List<Comment> comments;
}N+1问题:1条动态查询可能触发1(作者)+20(点赞)+20(评论)= 41条SQL
解决方案:
java
// 1. 分批次查询
@Service
@Transactional(readOnly = true)
public class PostService {
public Page<PostVO> getTimeline(Long userId, Pageable pageable) {
// 1. 查询动态ID
Page<Long> postIds = postRepository.findTimelinePostIds(
userId, pageable);
// 2. 批量查询动态内容
List<Post> posts = postRepository.findPostsByIds(
postIds.getContent());
// 3. 批量查询作者
Set<Long> authorIds = posts.stream()
.map(p -> p.getAuthor().getId())
.collect(Collectors.toSet());
Map<Long, User> authors = userRepository.findByIds(authorIds);
// 4. 批量查询点赞
Map<Long, List<Like>> likesByPostId =
likeRepository.findLikesByPostIds(postIds.getContent());
// 5. 批量查询评论
Map<Long, List<Comment>> commentsByPostId =
commentRepository.findCommentsByPostIds(postIds.getContent());
// 6. 组装数据
List<PostVO> vos = posts.stream()
.map(post -> {
PostVO vo = new PostVO();
vo.setPost(post);
vo.setAuthor(authors.get(post.getAuthor().getId()));
vo.setLikes(likesByPostId.getOrDefault(
post.getId(), Collections.emptyList()));
vo.setComments(commentsByPostId.getOrDefault(
post.getId(), Collections.emptyList()));
return vo;
})
.collect(Collectors.toList());
return new PageImpl<>(vos, pageable, postIds.getTotalElements());
}
}代码清单12:社交动态流优化
优化效果:
-
SQL数量:从 1+20+20+20=61 降到 4
-
响应时间:从 2100ms 降到 450ms
-
数据库压力:减少 95%
7. 监控与告警体系
7.1 实时监控面板
java
@RestController
@RequestMapping("/api/monitor")
public class NPlusOneMonitorController {
@Autowired
private EntityManagerFactory emf;
@GetMapping("/n-plus-one")
public Map<String, Object> detectNPlusOne() {
Statistics stats = emf.unwrap(SessionFactory.class)
.getStatistics();
Map<String, Object> result = new HashMap<>();
result.put("totalQueries", stats.getQueryExecutionCount());
result.put("nPlusOneScore", calculateNPlusOneScore(stats));
result.put("slowQueries", getSlowQueries(stats));
result.put("potentialIssues", findPotentialIssues());
return result;
}
private double calculateNPlusOneScore(Statistics stats) {
long entityLoads = stats.getEntityLoadCount();
long collectionLoads = stats.getCollectionLoadCount();
long queries = stats.getQueryExecutionCount();
if (queries == 0) return 0.0;
// N+1评分 = (实体加载次数 + 集合加载次数) / 查询次数
// 大于5表示可能有N+1问题
return (double) (entityLoads + collectionLoads) / queries;
}
@Scheduled(fixedDelay = 60000)
public void checkNPlusOne() {
double score = calculateNPlusOneScore(
emf.unwrap(SessionFactory.class).getStatistics());
if (score > 5.0) {
// 发送告警
alertService.sendAlert(
"N+1检测告警",
String.format("N+1评分: %.2f,可能存在问题", score));
}
}
}代码清单13:N+1监控接口
7.2 日志分析系统
java
@Aspect
@Component
@Slf4j
public class QueryMonitorAspect {
private static final ThreadLocal<QueryTrace> currentTrace =
new ThreadLocal<>();
@Around("@annotation(org.springframework.web.bind.annotation.GetMapping)")
public Object monitorController(ProceedingJoinPoint joinPoint) throws Throwable {
QueryTrace trace = new QueryTrace();
currentTrace.set(trace);
trace.setStartTime(System.currentTimeMillis());
trace.setEndpoint(getEndpoint(joinPoint));
try {
return joinPoint.proceed();
} finally {
trace.setEndTime(System.currentTimeMillis());
// 记录到ES
elasticsearchService.indexQueryTrace(trace);
// 分析N+1模式
analyzeTrace(trace);
currentTrace.remove();
}
}
@After("execution(* org.hibernate.*.*(..))")
public void recordQuery() {
QueryTrace trace = currentTrace.get();
if (trace != null) {
trace.incrementQueryCount();
}
}
@Data
static class QueryTrace {
private String endpoint;
private long startTime;
private long endTime;
private int queryCount;
private List<String> sqls = new ArrayList<>();
public long getDuration() {
return endTime - startTime;
}
public void incrementQueryCount() {
queryCount++;
}
}
}代码清单14:查询监控切面
8. 最佳实践总结
8.1 我的"N+1防御军规"
经过多年实战,我总结了N+1问题的最佳实践:
📜 第一条:监控先行
-
生产环境开启SQL监控
-
设置慢查询阈值(建议100ms)
-
定期分析SQL执行报告
-
建立性能基线
📜 第二条:代码规范
-
Repository方法名要简洁
-
复杂查询用@Query注解
-
避免在循环中访问懒加载属性
-
分页查询必须优化
📜 第三条:优化策略
-
小数据量用JOIN FETCH
-
大数据量用批量加载
-
多对多用分步查询
-
只查询需要的字段
📜 第四条:团队协作
-
代码审查检查N+1
-
新人培训必讲N+1
-
建立SQL审查流程
-
分享优化案例
8.2 检查清单
在代码审查时使用这个清单:
-
是否在循环中访问懒加载属性?
-
分页查询是否优化?
-
@OneToMany默认是LAZY吗?
-
复杂关联是否使用JOIN FETCH?
-
是否查询了不需要的字段?
-
批量操作是否使用批量加载?
-
监控日志是否有N+1告警?
9. 工具链推荐
9.1 开发阶段工具
1. IDE插件:
-
IntelliJ IDEA: JPA Buddy
-
Eclipse: Dali JPA Tools
-
VS Code: Java EE
2. 本地测试工具:
bash
# 使用p6spy查看SQL
mvn spring-boot:run -Dspring.profiles.active=dev
# 使用JMeter压测
jmeter -n -t n_plus_one_test.jmx -l result.jtl3. 代码分析工具:
XML
<!-- SpotBugs检查N+1模式 -->
<dependency>
<groupId>com.github.spotbugs</groupId>
<artifactId>spotbugs-maven-plugin</artifactId>
</dependency>9.2 生产环境工具
1. APM监控:
-
SkyWalking
-
Pinpoint
-
Arthas
2. 数据库监控:
-
MySQL: Performance Schema
-
PostgreSQL: pg_stat_statements
-
阿里云DMS
3. 日志分析:
-
ELK Stack (Elasticsearch, Logstash, Kibana)
-
Grafana + Loki
-
阿里云SLS
10. 最后的话
N+1问题就像慢性病,平时不痛不痒,发作起来要命。但解决N+1不是技术问题,是意识和习惯问题。
我见过太多团队在这上面栽跟头:有的直到数据库撑不住了才排查,有的优化了这里那里又冒出来,有的干脆放弃ORM用原生SQL。
记住:预防优于治疗,监控优于猜测,简单优于复杂。建立良好的开发习惯,N+1问题完全可以避免。
📚 推荐阅读
官方文档
-
**Hibernate性能调优指南** - 官方优化指南
-
**MyBatis最佳实践** - MyBatis官方文档
性能分析
-
**Vlad Mihalcea的博客** - JPA性能专家
-
**MySQL性能优化** - 数据库层优化
监控工具
-
**SkyWalking APM** - 分布式追踪
-
**Arthas诊断工具** - Java应用诊断
性能测试
最后建议 :不要等到性能出问题了才优化。在开发阶段就建立N+1检查机制,代码审查时重点关注,测试阶段进行压测。记住:预防为主,监控为辅,优化为补。