信息采集这件事,技术方案五花八门。商业 API、RPA 工具、八爪鱼这类可视化爬虫、n8n 工作流编排、还有最传统的 Python 脚本。但在实际场景里,很多盆友可能对这些方案的边界并不清晰,就是什么时候该用哪种?各自的成本和局限是什么?这篇文章想通过一个具体的 POC 案例,拆解一下在政府网站定期采集这个特定场景下,怎么选择性价比最高的技术路线。
演示视频链接:https://mp.weixin.qq.com/s/CcY6JU0Hnhk_JTO-EiWB_g
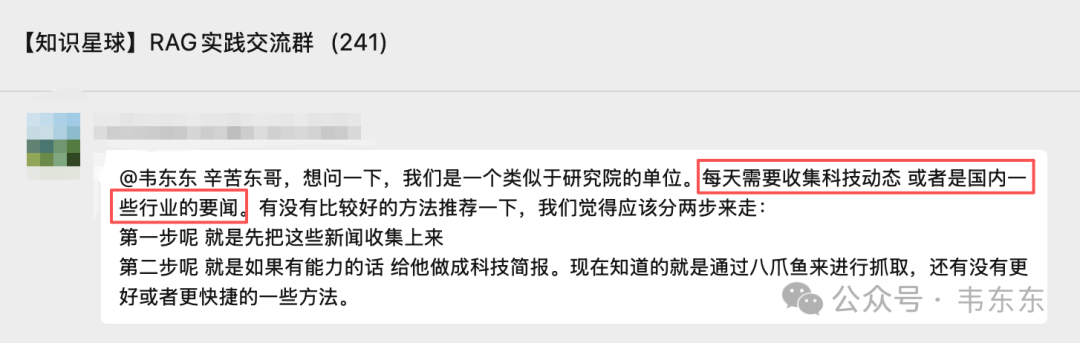
需求来自知识星球的一位成员。对方是类研究院性质的单位,每天需要从行业主管部门官网、垂直门户等几个信息源收集行业动态。短期目标是把新闻抓下来、入库、通过内部工具发布到自己网站的要闻板块;长期规划是做新闻简报、素材撰写。现状是用八爪鱼逐个采集,但"规则经常失效、维护成本高"。我觉得这是个很典型的场景,值得做一个 POC 给有类似需求的盆友打个样。
除了基础的信息采集,这个项目还尝试了一些大模型能解锁的新玩法:用 LLM 对多篇新闻做摘要聚合、用多模态模型生成可视化日报图、把同一份信息源输出成不同形态(网站、钉钉群、领导简报)。从这个角度看,信息采集只是知识库建设的第一步,后续还有很多延伸空间。
这篇试图说清楚:
政府/机构网站的技术架构为什么容易获取、多信息源适配的工程技巧、NocoDB 作为轻量数据库的使用体验、钉钉推送时踩过的坑(图片显示问题、OSS 权限)、LLM 生成日报摘要的 Prompt 设计,以及从本地测试到服务器部署的完整链路。
⚠️ 合规提示
本文仅作为技术方案演示和学习参考。实际应用中请严格遵守以下原则:1. 仅采集公开信息,不涉及登录后数据`2. 控制请求频率,避免对目标服务器造成压力``3. 内容版权归原网站,不做商业分发4. 遵守《网络安全法》及相关法规`爬虫技术本身中性,用途必须合法合规。
以下,enjoy:
1、需求场景分析
从特定信息源定时获取信息,这件事其实一直存在各种工具层面的局限性。它本身是个繁琐但在很多场景下又不得不干的活儿。很多人干起来觉得痛苦,可能不是因为技术难度高,而是没有找到最适合自己场景的方法。
对方给出了明确的信息源:某行业主管部门官网的两个栏目、某发展研究中心、某垂直门户网站。本来想靠八爪鱼来解决,但实际用下来发现规则经常失效、维护成本高。八爪鱼不好用的时候,就只能退回到手动浏览、复制粘贴。更麻烦的是没有增量检测,每次都要人肉判断下某条新闻昨天是否看过。
市面上的工具其实不少,但各有各的问题。八爪鱼这类可视化爬虫,配置学习成本不低,对于"每天抓几个固定网站"这种简单场景来说有点重。RPA 工具擅长模拟复杂交互(登录、验证码),但用来爬静态页面就是大炮打蚊子,启动浏览器慢、还需要 GUI 环境。Scraping API 类的服务主要解决"给一个 URL 返回页面内容"的问题,但不支持"监控列表页增量更新"的逻辑,你还是得自己写去重。至于 RSS 目前大部分目标信息源没有,这也是传统政务网站的通病,信息公开意识有了,但 RSS 支持没跟上。
所以最终的选择是写几个简单的 Python 爬虫脚本,针对每个信息源做适配。

2、政府/机构网站技术架构科普
在动手写脚本之前,有必要先了解一下这类网站的技术特点。政务/机构网站和电商类的互联网站在架构上差别很大:
| 对比维度 | 电商/互联网网站 | 政府/机构网站 |
|---|---|---|
| 前端架构 | SPA(React/Vue),客户端渲染,数据靠 API 动态加载 | 传统 CMS,服务端渲染静态 HTML |
| 反爬策略 | 滑块验证、IP 风控、请求签名、参数加密 | 通常无复杂反爬机制 |
| 爬取难度 | requests 很难搞,经常需要逆向或 Selenium | requests + BeautifulSoup 基本够用 |
简单来说,电商网站会想尽办法不让你爬,而政务网站的信息本来就是公开的,技术上也没做太多限制。国内政务网站常见的 CMS 有 TRS(拓尔思)、方正翔宇等,这些系统的共同特点是:页面是服务端渲染的静态 HTML,列表页和详情页结构相对稳定,URL 规则通常有迹可循。
当然,技术上容易获取不意味着可以滥用。政务网站的服务器资源有限,高频请求可能导致服务器压力、IP 被封,甚至法律风险。合规的做法是控制请求频率(每秒不超过 1 次)、仅采集公开信息、不做商业分发。
3、技术方案选择
先简单对比一下市面上常见的几种方案:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 八爪鱼/后羿采集器 | 可视化配置,无需编程 | 学习成本高,稳定性一般,付费 | 一次性采集任务 |
| RPA(UiPath/影刀) | 能模拟复杂交互 | 需要 GUI 环境,执行慢,维护成本高 | 需要登录、验证码的场景 |
| Scraping API | 无需部署,按量付费 | 不支持增量监控逻辑,需要自己写去重 | 一次性爬取特定页面 |
| n8n+HTTP Request | 可视化工作流,定时触发 | Python 脚本进 n8n 有环境隔离问题,调试困难 | 多系统集成场景 |
| Python + requests | 灵活、可控、轻量 | 需要编程能力 | ✅ 增量监控、定制化逻辑 |
可以看到,不同方案各有各的适用场景。八爪鱼适合一次性采集任务,RPA 适合需要登录验证码的复杂交互,Scraping API 适合按需爬取特定页面。但对于"每天定时采集几个固定网站、做增量检测"这种场景,Python 脚本反而是最直接的选择。
最终选择了最朴素的 Python + requests + BeautifulSoup 方案。增量监控需要自定义逻辑------列表页解析、日期过滤、URL 去重、详情页爬取,这套流程用代码写最灵活。部署也简单,一个 Python 脚本放服务器上,crontab 定时跑就行。后续网站结构变了,改几行代码就能适配,维护成本可控。
最初其实考虑过用 n8n 做工作流编排(定时触发 → 执行脚本 → 通知),后来放弃了。主要原因是如果 n8n 只是当定时器用,Linux 自带的 crontab 更稳定;Python 脚本放进 n8n 的 Code Node 会遇到环境隔离问题(依赖、路径);而且这个场景有人工审核断点,两个工作流的衔接很别扭。总之,对于这个场景,n8n 反而是大炮打蚊子。
4、多源适配的工程细节
实际写脚本的时候踩了不少坑。这里整理一下遇到的典型问题和解决思路:
| 问题类型 | 具体表现 | 解决方案 |
|---|---|---|
| SSL 证书错误 | SSLCertVerificationError ,部分机构网站证书链不完整 | 请求时设置 verify=False,同时禁用警告 |
| 子栏目结构差异 | 同一网站下不同栏目的列表页结构不一致 | 用简单的模式匹配识别分类标题 |
| 视频/音频内容 | 部分新闻是视频,没有文字正文 | 通过标题关键词识别自动跳过 |
| 外部链接 | 部分新闻实际跳转到外部网站 | 检测 URL 域名,非目标域名的直接跳过 |
其中有个值得单独说的点:部分网站的新闻会跳转到微信公众号文章。这类链接我选择直接跳过,原因是微信公众号有反爬机制,直接 requests 请求拿不到正文;另外微信生态相对封闭,爬取公众号内容存在一定法律风险;而且公众号文章通常在官网也有对应版本,跳过不影响信息覆盖。

代码结构上,从最初的单文件脚本重构成了模块化架构。每个网站一个独立的爬虫类,继承统一的基类,实现 fetch_news_list() 和 fetch_news_content() 两个方法就行。后续新增网站只需要写一个新的适配文件,不用改动主流程。
5、数据存储与去重
存储方案对比了几种选择:
| 方案 | 优点 | 缺点 |
|---|---|---|
| Excel | 简单直接 | 并发写入有问题,无法通过 API 查询 |
| SQLite | 轻量级数据库 | 需要写 SQL,非技术人员不好用 |
| 飞书多维表格 | 云端协作,界面友好 | API 有调用频率限制,数据存在第三方 |
| NocoDB | 类 Airtable 体验,支持 REST API,本地部署 | 需要 Docker 环境 |
最开始其实考虑过用飞书多维表格,毕竟界面友好、支持协作。但后来还是选择了本地部署的方案,主要是考虑到数据安全和长期稳定性。云端服务的 API 限制、数据归属权、后续迁移成本都是隐患。
NocoDB 是一个开源的 Airtable 替代品,GitHub 上有 61k+ 的星标,社区很活跃。它可以把 MySQL、PostgreSQL 甚至 SQLite 包装成类似 Airtable 的 Web 界面,支持 REST API 读写。对于这个场景来说刚好够用:对方可以直接在网页上查看、筛选、导出,不需要懂数据库;脚本通过 API 写入数据,接口设计和 Airtable 类似,上手很快。如果觉得 Docker 部署麻烦,SQLite + 一个简单的 Web 界面(比如 sqlite-web 或者 Datasette)也是类似的思路。

NocoDB开源地址:https://github.com/nocodb/nocodb
去重逻辑比较简单:用新闻 URL 作为唯一标识,每次运行前先查询数据库里已有的 URL 列表,只处理不在列表里的新增内容。另外为了区分不同来源,设计了层级化的 Source 字段,比如"网站 A-要闻栏目"、"网站 B-媒体之声"这种格式,方便后续在数据库里按来源筛选和统计。
6、完整工作流设计
整体工作流分成三个阶段:采集阶段、人工审核和日报生成阶段。用一张图来展示会更清晰:
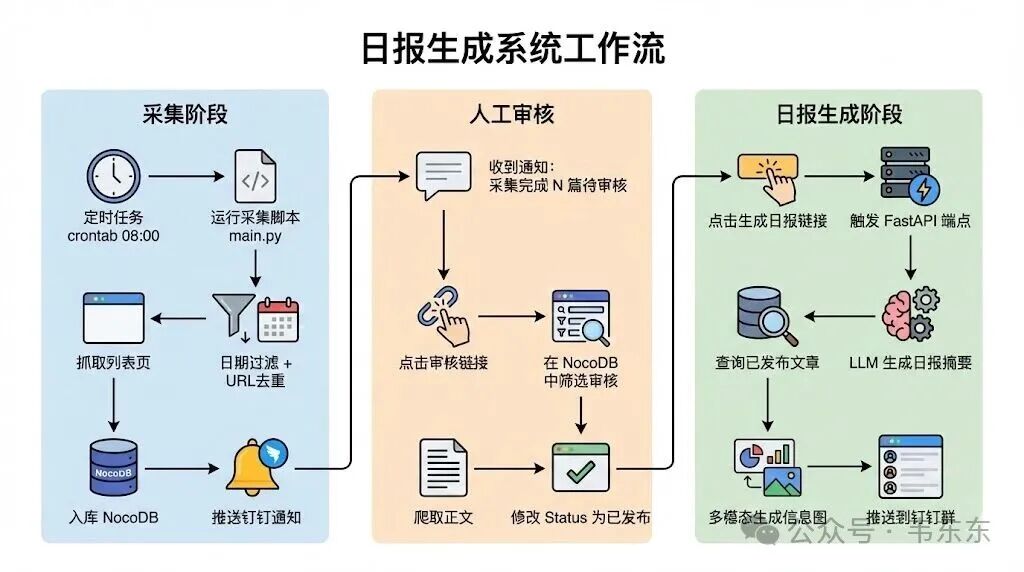
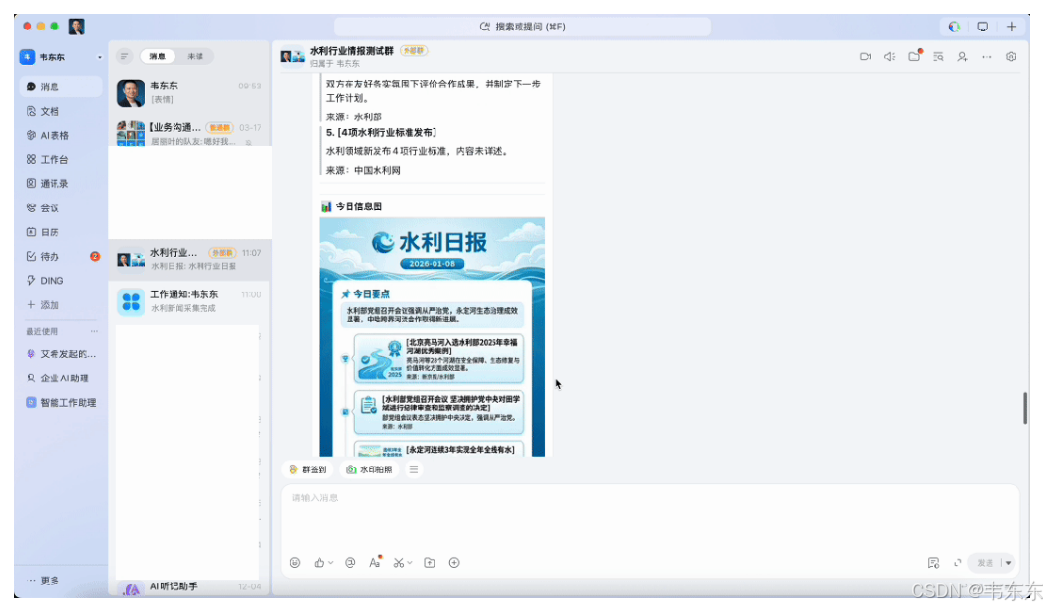
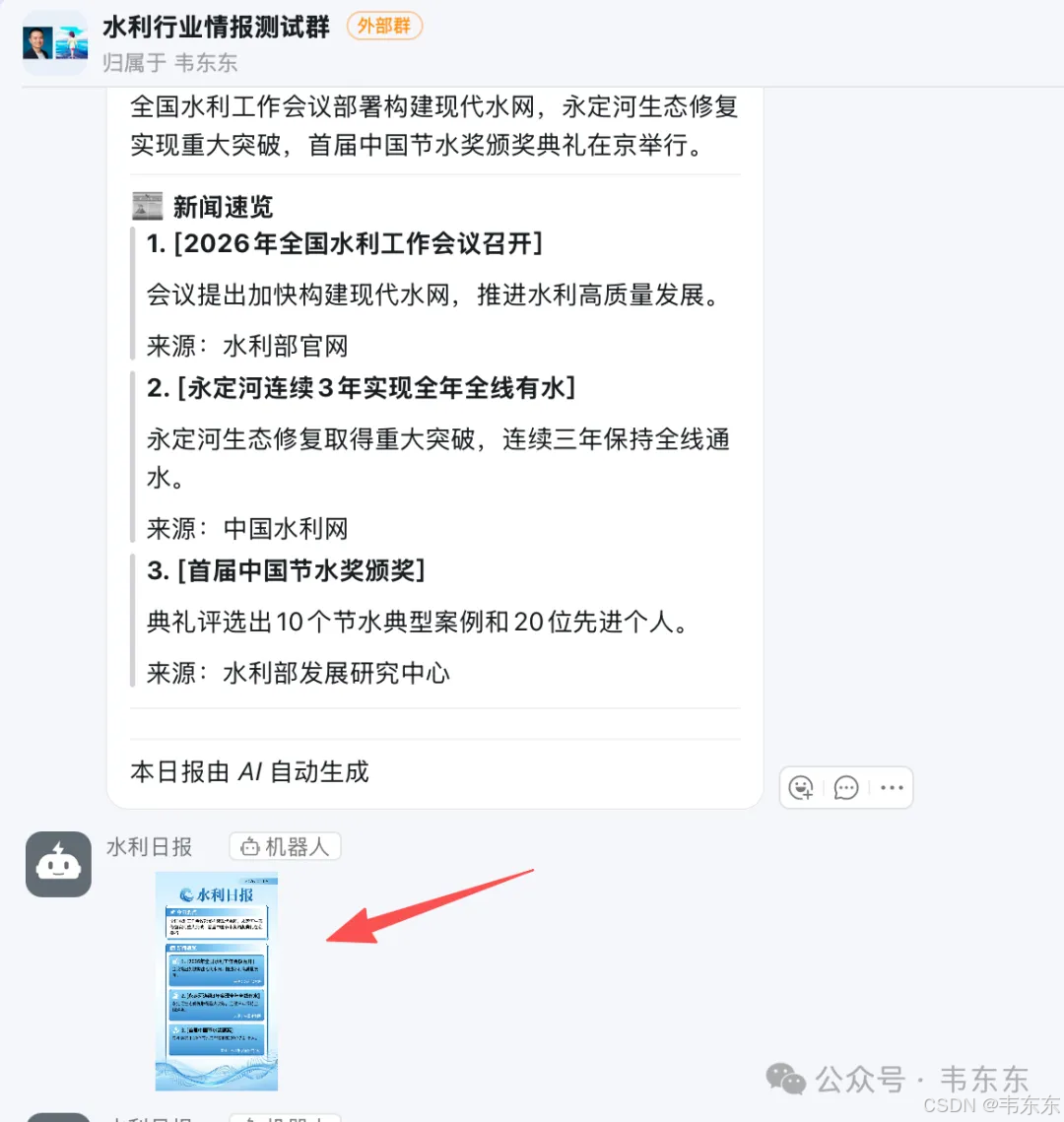
采集阶段由定时任务触发(比如设置crontab 每天早上 8 点),运行采集脚本,依次抓取列表页、日期过滤、URL 去重、爬取正文、入库。采集完成后会推送一条钉钉消息,告诉对方"采集完成,共 N 条待审核",消息里附带审核地址(NocoDB 的 Web 界面)和生成日报的链接。
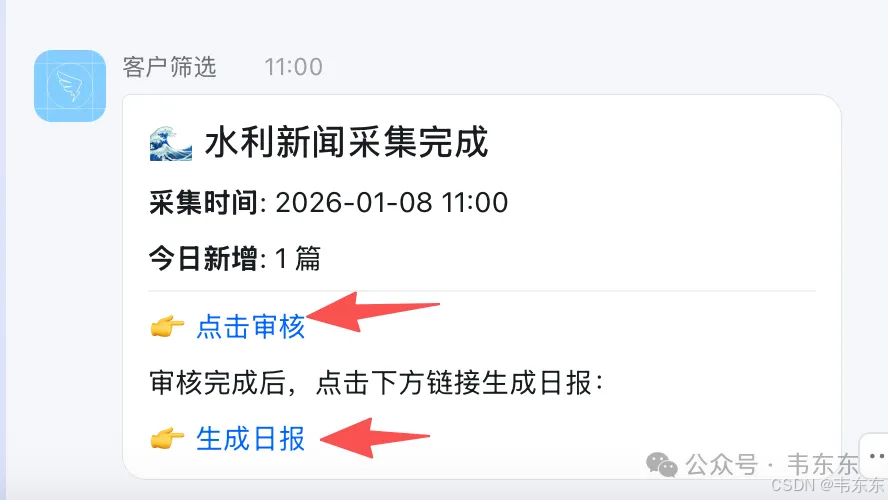
日报生成阶段是人工触发的。对方在数据库里审核完新闻(把 Status 改成"已发布"),然后点击钉钉消息里的"生成日报"链接。这个链接会调用一个 FastAPI 端点,查询所有已发布的文章,调用 LLM 生成日报摘要,最后推送到钉钉群。
关于日报触发机制,考虑过几种方案:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 双定时任务 | 最简单 | 必须在固定时间前完成审核 |
| API 手动触发 | 灵活,审核完随时点 | 需要额外开发 API 服务 |
| 数据库 Webhook | 自动化程度高 | 配置复杂,每条更新都触发 |
最终选择了 API 手动触发。原因很简单:审核完成后点击链接即可,不受时间限制;FastAPI 几十行代码就能搞定,开发成本很低。
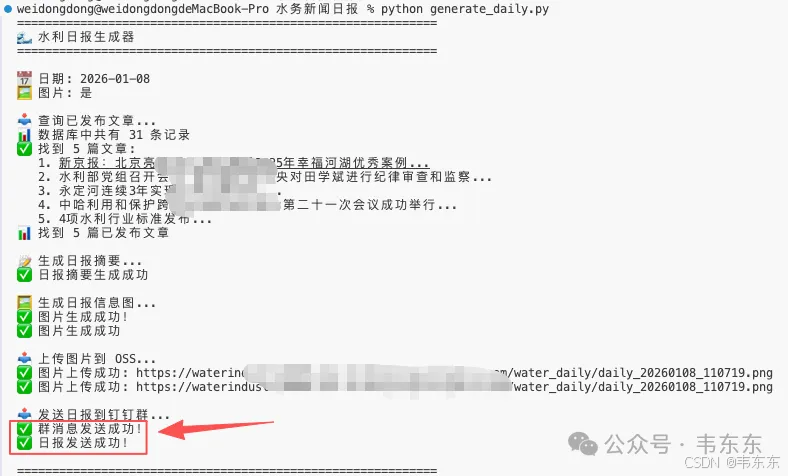
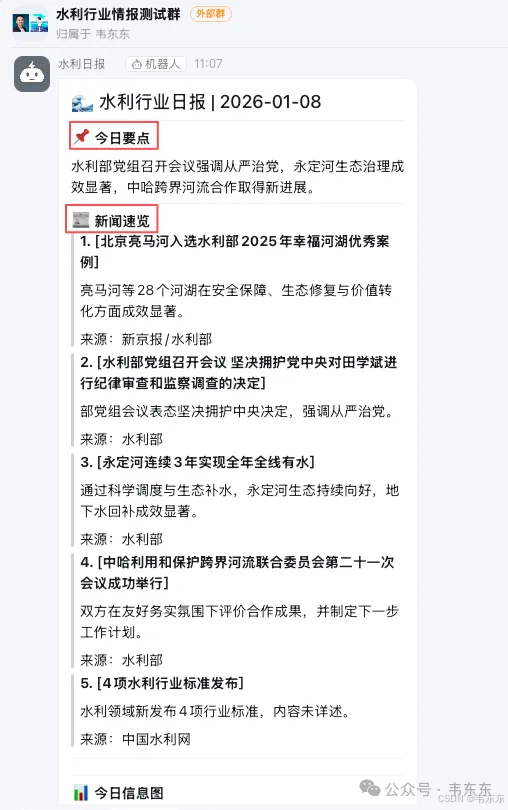
日报输出目前规划了两种形式。一种是正式的 Markdown 版:LLM 输出结构化的 JSON(标题、分类、一句话摘要),用模板渲染成 Markdown,通过钉钉 Markdown 消息推送。另一种是美观的图片版:调用多模态 API 生成信息图,内容压缩、视觉效果好,适合朋友圈或群分享。

7、本地测试与服务器部署
本地测试和服务器部署的流程略有不同,主要区别在于触发方式。
本地测试时需要手动运行两个脚本。先运行 python main.py 完成采集入库,然后打开 NocoDB 网页界面进行人工审核(把 Status 改成"已发布"),最后运行 python generate_daily.py 生成日报。两个脚本之间有一个人工审核的断点,毕竟不是所有采集到的新闻都需要发布。
服务器部署之后,采集脚本由 crontab 定时触发,每天早上自动运行。采集完成后钉钉会推送一条消息,里面带着审核链接和生成日报的链接。对方在手机上收到通知,点击链接可以直接打开 NocoDB 进行审核,审核完再点击"生成日报"链接触发 FastAPI 端点。整个过程不需要登录服务器。
简单对比一下两种模式的差异:
| 环节 | 本地测试 | 服务器部署 |
|---|---|---|
| 采集触发 | 手动python main.py | crontab 定时自动 |
| 审核界面 | http://localhost:8080 | http://服务器 IP:8080 |
| 日报触发 | 手动python generate_daily.py | 点击钉钉消息链接 |
| API 服务 | 可选 | 必须运行 |
部署架构也很简单:一台云服务器上跑两个 Docker 容器(NocoDB 和 FastAPI),加一个 crontab 定时任务。NocoDB 暴露 8080 端口用于审核,FastAPI 暴露 8000 端口用于触发日报生成。两个服务都通过钉钉 Webhook 推送消息。
这个方案能跑通的前提条件其实很简单:目标网站是传统 CMS、静态 HTML、无复杂反爬;请求量很小,每天一次、每次几十条;人工审核是必要的,不追求全自动;部署足够简单,两个 Docker 容器加一个 crontab 就搞定。
8、IM 推送与日报生成的工程细节
这部分踩了些坑,值得单独拿出来说一下。本文以钉钉为例演示推送和审核的细节,实际上也可以换成企业微信、飞书或者内部的 IM 工具,实现逻辑是类似的。钉钉有两种推送方式,适用于不同场景:
| 方式 | 推送目标 | 获取方式 | 适用场景 |
|---|---|---|---|
| 工作通知 | 个人(App 内推送) | 创建企业内部应用,获取 Client ID/Secret/Agent ID | 采集完成提醒 |
| 群机器人 | 群聊 | 在群设置中添加自定义机器人,获取 Webhook URL | 日报发布 |
这个项目里组合使用了两种方式:采集完成后通过工作通知推给运营负责人(私信更容易引起注意),日报生成后通过群机器人发送到群里(方便大家一起看)。
关于图片消息显示问题。一开始用 image 消息类型发送图片,结果在群里显示为一个小缩略图(类似表情),无法点击放大。查了文档才发现,钉钉群机器人的 image 消息类型本身就有这个限制。解决方案是把图片嵌入到 Markdown 消息中:
python
# ❌ 错误方式:单独发送图片消息
payload = {"msgtype": "image", "image": {"picURL": url}}
# ✅ 正确方式:在 Markdown 中嵌入图片
content = f"## 日报标题
内容...
"
payload = {"msgtype": "markdown", "markdown": {"title": "日报", "text": content}}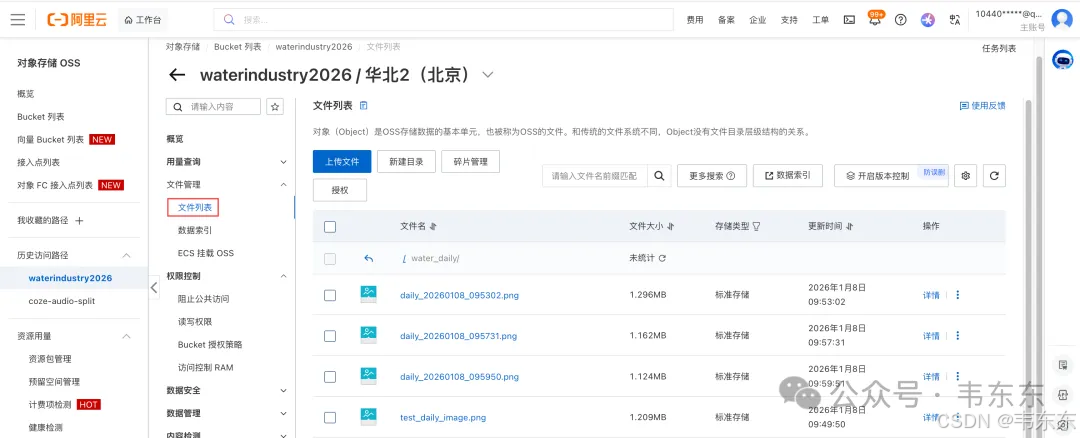
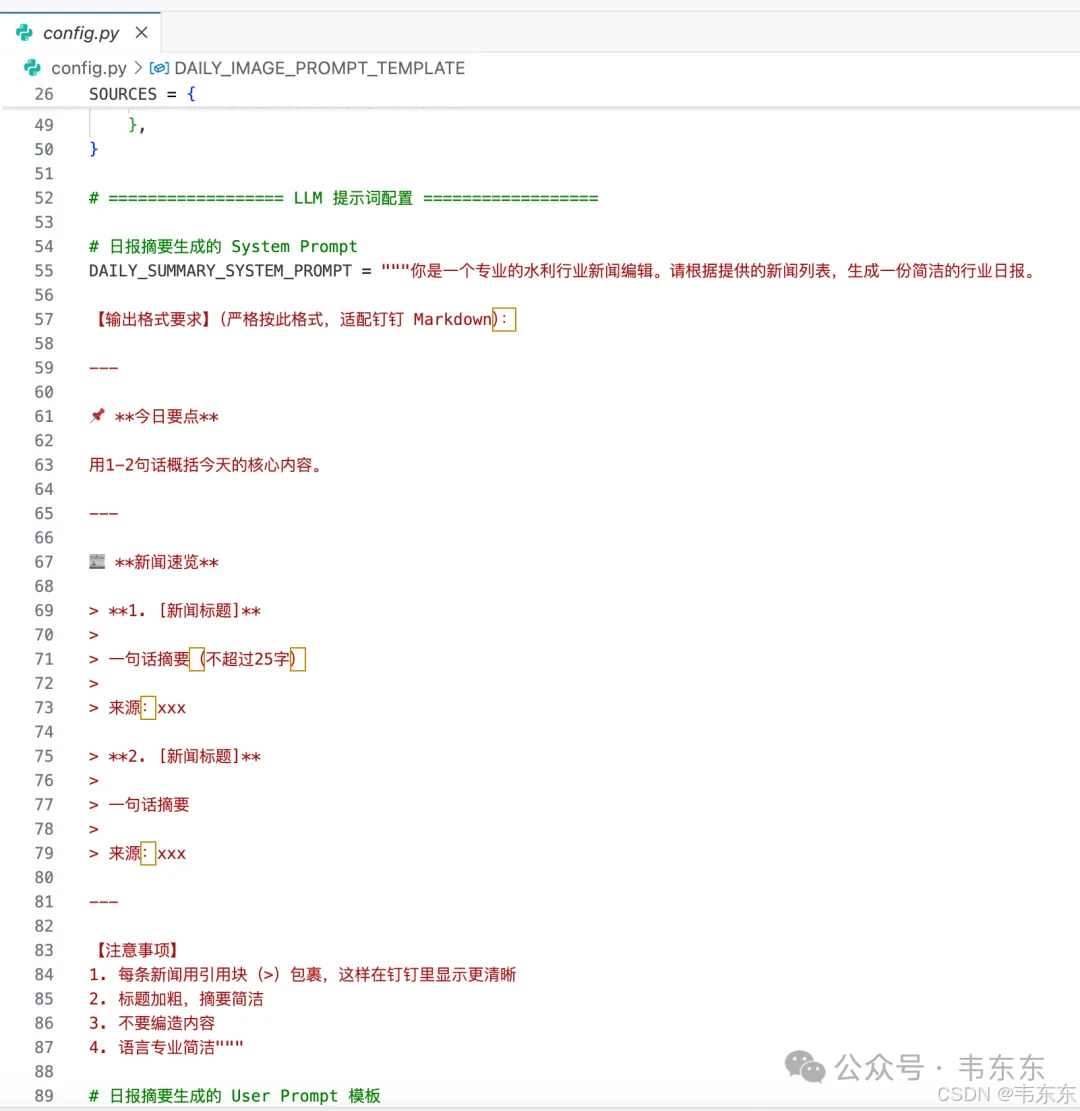
关于 LLM 日报生成,也有一些 Prompt 优化的经验。钉钉的 Markdown 渲染能力比较有限,如果不针对性优化,LLM 输出的内容会标题和正文挤在一起、列表项没有视觉分隔、整体看起来像一大段文字。优化后的 Prompt 要点是每条新闻用引用块包裹、标题加粗、用分隔线区分不同部分、适当添加 emoji 增加可读性。
图片生成方面,最终选择了 gemini-3-pro-image-preview(也就是 Nano Banana Pro,通过 OpenRouter 调用)。这个模型是目前端到端多模态生图能力较强的选择之一,中文提示词支持好、输出质量稳定。这种原生的多模态能力,给日报输出解锁了一些新的可能,不只是文字摘要,还能自动生成美观的信息图,适合在群里分享。
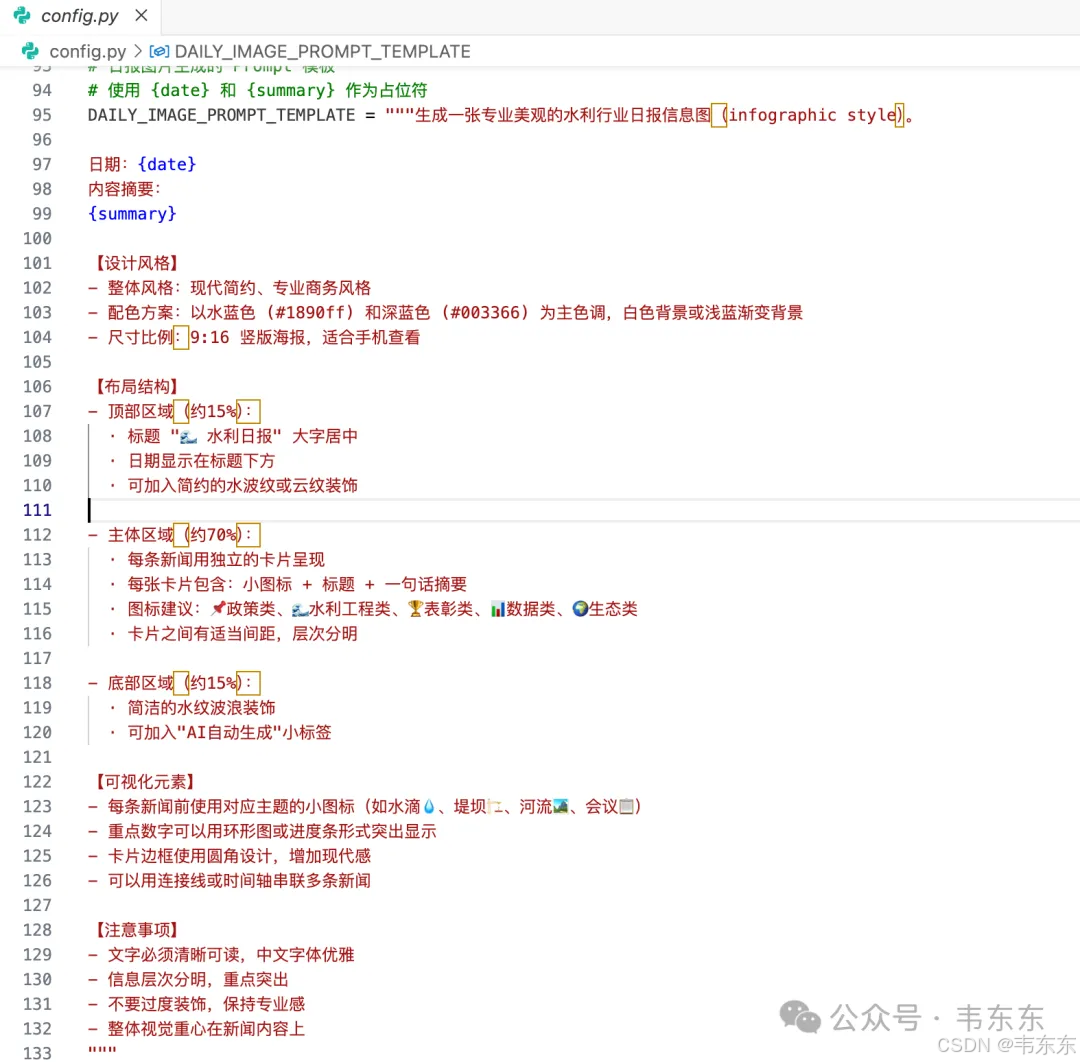
完整的日报生成流程是:LLM 生成日报摘要(DeepSeek V3.2)→ 多模态模型生成信息图(Gemini)→ 上传图片到 OSS 获取公网 URL → 构造 Markdown 消息嵌入图片 → 发送到钉钉群。
9、写在最后
跳出这个项目来看,这类需求其实非常普适。政策研究机构追踪部委公告、行业协会收集会员单位新闻、企业市场部监控行业资讯、投资机构追踪标的公司公告,本质上都是"从若干固定信息源定期采集增量内容"。这类需求的共同特点是目标网站技术上不复杂、需要增量监控而非一次性采集、对实时性要求不高、体量也不大。
大模型的成熟给这类需求解锁了一些新的可能。以前信息采集就只是采集,输出的是原始素材,后续的摘要、加工、分发还得人工来。现在可以做到多篇新闻自动聚合摘要、生成结构化的日报输出、甚至用多模态模型生成可视化的信息图。同样一份信息源,可以输出给网站、给 IM 群、给领导简报,形态各异但流程自动化。这就不只是信息采集了,而是知识库素材生成的第一步。
最后还是要强调一下合规问题,爬虫技术本身中性,但用途必须合法合规;控制请求频率,不对目标服务器造成压力;仅采集公开信息,不涉及登录后数据;内容版权归原网站,不做商业分发。
如果你有类似的需求或在做类似的事,欢迎交流。
项目源码已发布至星球《企业大模型应用从入门到落地》
视频课程目前已更新11个案例,剩余四个预计1月下旬完更,
可点击下方"原文链接"试看部分案例
(星球成员享1元兑换福利)