混合模型并不遵循高斯马尔可夫随机场的范式,因为由混合模型生成的数据通常是多模态的。不过,Gómez-Rubio 和 HRue(2018)提供了一种通过结合 INLA 和 MCMC 来用 INLA 拟合混合模型的方法,Gómez-Rubio(2017)也探索了使用其他算法用 INLA 拟合混合模型。总体而言,混合模型的分析较为复杂,本文旨在建立 INLA 与这些模型之间的简短联系,并展示如何用 INLA 拟合这些模型。
(一)混合模型的表示形式
混合模型通常可表示如下:
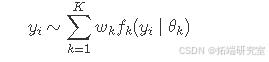
这里,{fk(⋅∣θk}Kk=1(这里注意不要翻译代码中的变量等符号)是一组(参数化)分布,w=(w1,...,wK)是相关权重,它们的定义使得其总和为一,即∑Kk=1wk=1,可将其视为数据中来自每个组的观测值的比例。
一种常见的拟合混合模型的方法是考虑 "扩充" 数据(Dempster、Laird 和 Rubin,1977),即引入一个辅助变量z=(z1,...,zn)来将每个观测值分配到一个组。因此,变量zi,i=1,...,n在集合{1,...,K}中取值。于是,混合模型也可如下表示:
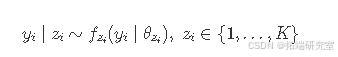
辅助变量z的分布可表述为:
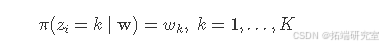
考虑完整数据(y,z),模型似然变为:
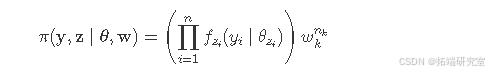
这里,nk,k=1,...,K是组k中的观测值数量。
需要注意的是,如果使用可交换先验,给定z,不同的组是相互独立的。这意味着,在给定z的条件下,可以使用具有多个似然的模型用 INLA 拟合混合模型。如下文所述,可通过多种方式利用这一点来用 INLA 拟合混合模型。
混合模型是不可识别的,因为不同组的标记方式有些随意,不同的标记可能会导致完全相同的模型。例如,在一个有两组的混合模型中,给定z的值,如果标签互换(即 1 设为 2,反之亦然),就会得到完全相同的模型。这就是众所周知的 "标签切换" 问题(Celeux、Merrilee 和 Robert,2000;Stephens,2000)。因此,通常会对θ的先验施加额外约束,且不应使用不恰当的先验。处理此问题的一种简单方法是分配有信息的先验(Carlin 和 Chib,1995)或对不同组的均值施加排序约束(Diebolt 和 Robert,1994;Richardson 和 Green,1997)。
(二)数据集的喷发时间分析
"geyser" 数据集(Azzalini 和 Bowman,1990)描述了黄石国家公园老忠实间歇泉的喷发持续时间以及两次喷发之间的间隔时间,具体变量描述见表。

以下代码展示了如何加载数据并对数据集中的变量进行汇总:
其输出结果如下:
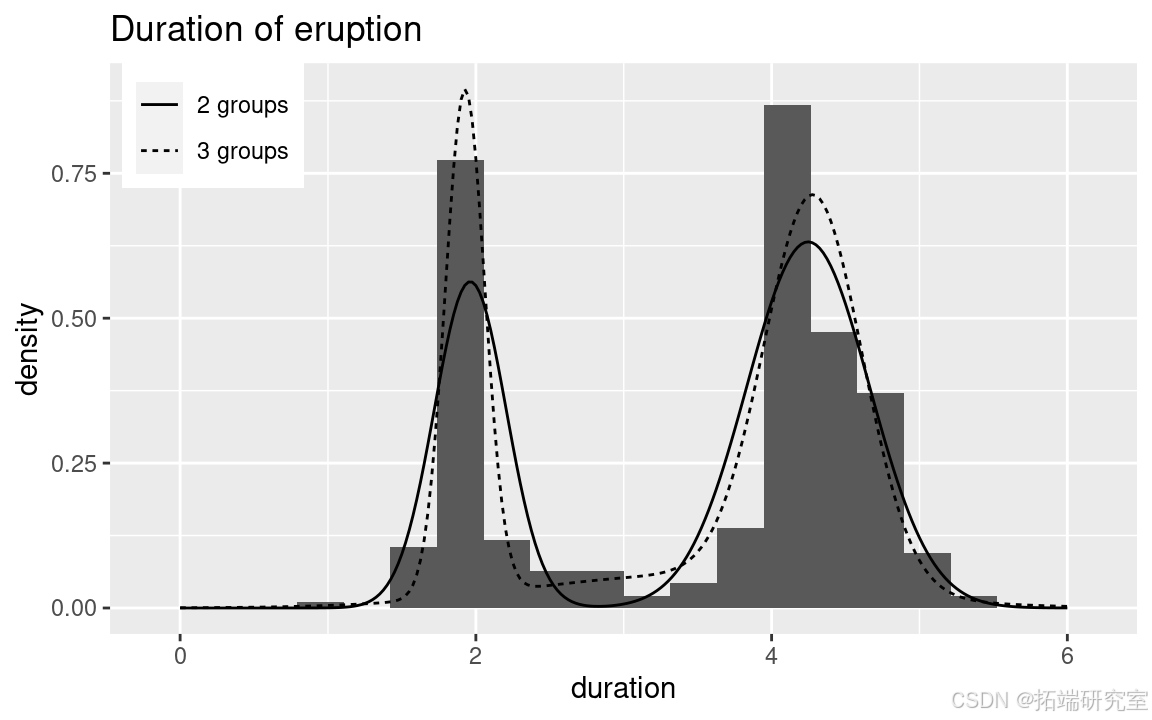
此外,图 展示了这两个变量的散点图以及喷发持续时间的直方图和核密度估计。喷发时间的分布明显是多模态的,拟合典型的线性回归可能不太合适。
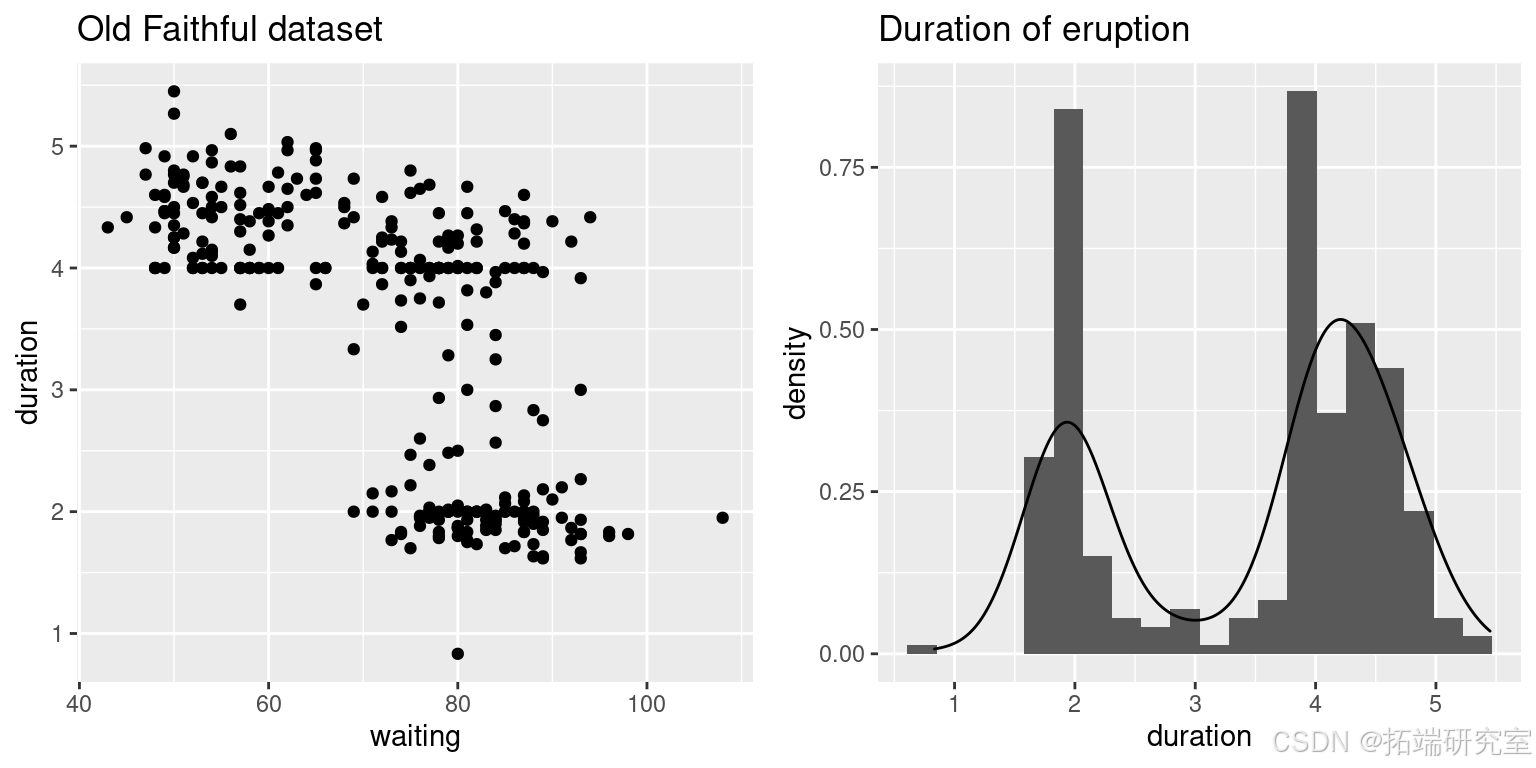
双变量图还显示了喷发前时间与其持续时间之间的高度相关性。实际上,国家公园管理员能够根据前一次喷发的持续时间预测下一次喷发的时间。
现在感兴趣的问题是量化数据集中有多少个组,同时能够刻画每个喷发持续时间组的特征。对图 右侧图的直观检查表明,数据中(至少)有两个不同的组,其均值大致在 2 和 4 左右,且两组之间的标准差相似。注意,有几位作者曾建议该数据集中可能有更多的成分(Zucchini、MacDonald 和 Langrock,2016),但为了简单起见,我们这里只考虑两组的分析。
一种简单的方法是将数据简单地分成两组,并拟合一个具有两个似然的模型。例如,我们可以将所有喷发持续时间小于或等于 3 的喷发时间分配到组 1,其他观测值分配到组 2。或者,也可以使用 K-means 算法对数据进行初步的粗略分类。在这种特定情况下,这两种方法将创建相同的初始数据分类。注意,由于将使用两个不同的似然,响应需要放入一个 2 列矩阵中。
此索引稍后将用于创建数据集,现在也可用于显示分配到每个组的观测值数量:
登录后复制 代码解读
plain
table(idx1)其输出结果如下:

注意到大多数观测值在第二组中,如图 所示。
因为我们希望每个组有不同的均值,所以必须使用与观测数据类似的结构将截距分成两部分。在这种情况下,将使用一个 2 列矩阵,其元素为 1 和NA。
登录后复制 代码解读
bash
#Create two different intercepts
II <- yy
II\[II > 0\] <- 1接下来,可以通过在数据中使用值yy和I(在调用inla()时分别命名为duration和Intercept)以及两个似然来拟合模型:

模型的汇总结果显示,两组的均值估计值分别为 1.9994 和 4.2753。此外,第一组的估计精度为 10.712,而第二组的估计精度为 7.2257,这使得第二组的喷发时间略具更大的可变性。
虽然这种方法能对两组之间的喷发时间得出合理的估计,但存在两个问题。第一个问题是我们已经使用了一次数据来确定有两组以及这两组是如何定义的。其次,这种方法忽略了每个观测值来自哪个组的内在不确定性。在将观测值分类到组中时,这是一个重要问题,简单的截断点很少是个好主意。
从建模的角度来看,我们刚才所做的是在给定辅助变量z的条件下拟合模型,即我们已经将z设置为给定的分类。虽然这在实践中可能有用(有关使用 INLA 拟合条件模型的一些示例,请参见 Gómez-Rubio 和 Palmí-Perales,2019),但在完整的贝叶斯分析中,我们也应该对z的后验分布感兴趣。
用 INLA 拟合混合模型
一般而言,混合模型很难拟合(Celeux、Merrilee 和 Robert,2000),并且由于它们不能表示为潜在的高斯马尔可夫随机场(GMRF),所以不属于 INLA 能够拟合的模型类别。然而,正如 Gómez - Rubio 和 HRue(2018)以及 Gómez - Rubio(2017)所指出的,在给定变量(z)的条件下,混合模型就变成了可以用 INLA 拟合的模型。
Gómez - Rubio(2017)指出,混合模型的模型参数的后验边缘可以写成(此处未明确给出内容)。需要注意的是,这需要(z)的后验分布,而通常这是未知的。不过,如 Gómez - Rubio 和 HRue(2018)所示,可以在马尔可夫链蒙特卡罗(MCMC)方法中使用 INLA 轻松估计它。
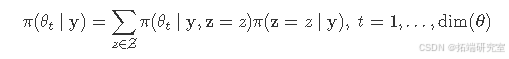
在这个例子中,将使用 Metropolis - Hastings 算法来估计(z)的后验分布。因此,需要一个建议分布来提出(z)的新值,并且所有的赋值将作为一个整体被接受或拒绝(即,对于每个(z_{i},i = 1,\cdots,n)不是单独接受或拒绝)。
建议分布(q(z^{\prime}\mid z))定义了在给定当前值(z)的情况下新值(z^{\prime})的概率。对于每个单独的(z_{i})为(1)的概率为(Marin、Mengersen 和 Robert,2005)(此处未明确给出内容)。这里,(f_{1}(\cdot\mid\mu_{1},\tau_{1}))是均值为(\mu_{1})、精度为(\tau_{2})的正态分布(这是在给定(z)条件下拟合模型得到的第一组的参数),(f_{2}(\cdot\mid\mu_{2},\tau_{2}))的定义与之类似。注意这里均值和精度的值取决于(z)。
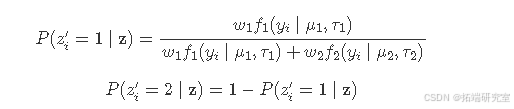
这里的示例取自 Gómez - Rubio 和 HRue(2018),它依赖于 INLABMA 包中的 INLAMH()函数。
下面将描述在 MCMC 中使用 INLA 拟合混合模型所需的不同函数。为了对整体情况有一个概述,实现此算法所需的不同函数如下:
get.probs():给定潜在变量(z)的观测值,计算不同组件的权重。
dq.z():建议分布的密度概率函数。
rq.z():建议分布的随机数生成器函数。
fit.inla.internal():给定(z)的值拟合所需的 INLA 模型。这用于计算接受概率所需的条件边缘似然(\pi(y\mid z))。
prior.z():计算(z)的先验。
此外,需要注意的是,在以下函数中存储观测值分类的变量不是一个简单的表示观测值所属组的向量,而是一个更复杂的数据结构。特别是,它是一个包含以下元素的列表:
z:指示观测值所属的向量。
m:在(z)值条件下用 INLA 拟合的模型。它是一个包含两个组件的列表:拟合的 INLA 模型和模型拟合的边缘似然。
注意,例如,函数(rq.z())返回这种类型的对象。这是用于表示变量(z)的数据结构,并传递给几个函数用于计算。包含模型拟合的原因是为了避免在 Metropolis - Hastings 算法的实现中多次拟合模型。
在描述所需函数之前,要使用的组数为(2),在变量(n.grp)中设置,供下面定义的一些函数使用。此外,变量(grp)定义为一个向量,用于存储观测值最初所属的组:
登录后复制 代码解读
bash
# 组数
n.grp <- 2
# 初始分类
grp <- rep(1, length(geyser$duration))
grp[!idx1] <- 2函数fit.inla.internal()用于在给定(z)的情况下实际拟合所需的模型,在下面的rq.z()函数中使用。需要注意的是,下面还定义了另一个类似的函数inla.fit()用于类似目的。这两个函数的主要区别在于fit.inla.internal()调用inla()在(z)条件下拟合条件模型,而fit.inla()只是从表示(z)值和模型拟合的复杂数据结构中获取拟合模型。
登录后复制 代码解读
bash
# y:响应值向量
# grp:分配变量的整数向量
fit.inla.internal <- function(y, grp) {
# 两列格式的数据
yy <- matrix(NA, ncol = n.grp, nrow = length(y))
for(i in 1:n.grp) {
idx <- which(grp == i)
yy[idx, i] <- y[idx]
}
# X存储模型中的截距
x <- yy
x[!is.na(x)] <- 1
d <- list(y = yy, x = x)
# 模型拟合(在z条件下)
m1 <- inla(y ~ -1 + x, data = d,
family = rep("gaussian", n.grp),
# control.fixed = list(mean = list(x1 = 2, x2 = 4.5), prec = 1)
control.fixed = list(mean = prior.means, prec = 1)
)
res<- list(model = m1, mlik = m1$mlik[1, 1])
return(res)
}
表示分组分配和相关模型拟合的初始数据结构(如上所述)接下来在变量grp.init中定义。需要注意的是,由于这包括模型拟合,所以通过变量prior.means定义了组均值上高斯先验分布的先验均值。此外,设置变量scale.sigma用于建议分布。
下面展示了实现 Metropolis - Hastings 算法所需的函数。作为 R 语言的注释,给出了它们各自参数的一些信息。
函数get.probs()将根据(z)的当前值(作为从(1)到(K)的整数向量传递)计算每个组件的权重。
登录后复制 代码解读
bash
# 属于每个组的概率
# z:值从1到组数的整数向量
get.probs <- function(z) {
probs <- rep(0, n.grp)
tab <- table(z)
probs[as.integer(names(tab))] <- tab / sum(tab)
return(probs)
}接下来,定义函数dq.z()来计算给定当前值(z.old)时(z)的新值(z.new)的密度。需要注意的是,这些值是如上所述的数据结构,而不仅仅是整数向量。
使用给定(z)当前值的建议分布对(z)进行随机观测采样的函数是rq.z()。需要注意的是,(z)是一个复杂的数据结构,包括指示向量和模型拟合,如上所述。
登录后复制 代码解读
bash
# FIXME:这里我们不考虑可能的标签切换
# z:z的当前值
rq.z <- function(z) {
m.aux <- z$m$model
means <- m.aux$summary.fixed[, "mean"]
precs <- m.aux$summary.hyperpar[, "mean"]
ws <- get.probs(z$z)
z.sim <- sapply(1:length(z$z), function (X) {
aux <- ws * dnorm(y[X], means, scale.sigma * sqrt(1 / precs))
sample(1:n.grp, 1, prob = aux / sum(aux))
})
# 拟合模型
z.model <- fit.inla.internal(y, z.sim)
# 新值
z.new <- list(z = z.sim, m = z.model)
return(z.new)
}
(z)上的先验分布简单地是概率为(0.5)的伯努利分布的乘积,以提供一个模糊先验:
函数fit.inla()是 INLAMH()函数用于在给定(z)值的情况下拟合模型的函数。在这个特定的实现中,实际的模型拟合是在函数rq.z()中使用fit.inla.internal()函数完成的,因此fit.inla()只是从数据结构中检索元素(m)。
登录后复制 代码解读
bash
fit.inla<- function(y, grp) {
return(grp$m)
}接下来,需要调用INLAMH()函数来拟合模型。由于起始点接近数据的最优划分(但需要注意这并不常见),所以不需要大量的预烧迭代。此外,迭代次数保持在较低的(100)次(每隔(5)次取一次),因为在这个特定的例子中,只有少数观测值的后验概率可能不接近(0)或(1)。在更复杂的例子中,可能需要更高的模拟次数。
一旦模型拟合完成,它将返回一个包含拟合模型和(z)值(其中包括许多实际上不需要的辅助变量)的列表。(z)的采样值可以通过以下方式获得:
登录后复制 代码解读
plain
zz <- do.call(rbind, lapply(inlamh.res$b.sim, function(X){X$z}))从后验分布(\pi(z\mid y))的这个样本中,我们可以计算属于每个组的后验概率:
登录后复制 代码解读
plain
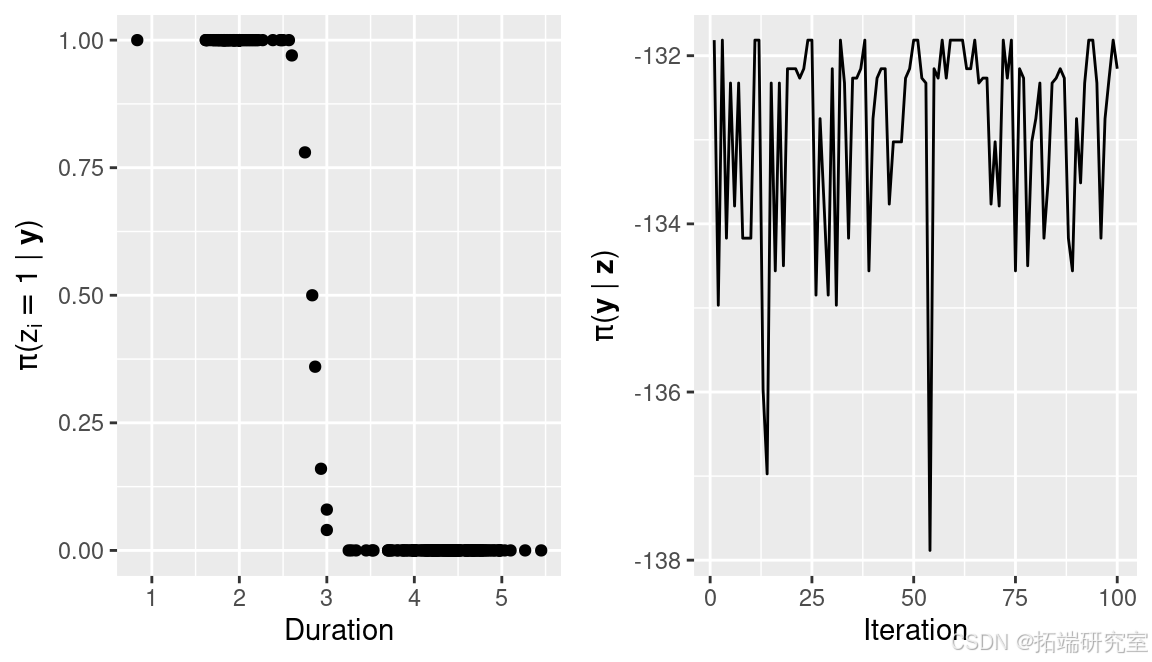
zz.probs <- apply(zz, 2, get.probs)需要注意的是,大多数观测值的概率为(0)和(1),即分类非常清晰,只有少数观测值在分类中会显示出一些不确定性。图展示了观测值与属于喷发持续时间较短组(即(z_{i}=1))的后验概率的关系。
还可以获得与(z)采样值相关的所有模型的条件边缘似然,以深入了解模拟过程:
这些也显示在图(右图)中,它们展示了初始模型拟合(其边缘似然为 - 140.16)相比,采样算法如何使条件边缘似然增加。这也意味着较短的预烧期就足够了。
此外,链显示只探索了少数几种分类。可以通过增加用于抽样的迭代次数或选择不同的建议分布(例如,选择标准差更大的值,如两倍的值)来轻松改变这种行为。然而,在这个特定的情况下,大多数观测值属于两个组之一的后验概率很高,这意味着它们总是被分到同一组。因此,后验概率集中在少数几种分类中,只有喷发持续时间约为(3)分钟的观测值会被分到两组中的任何一组。
混合模型的模型选择
混合模型组件数量确定的挑战与方法
在混合模型中,确定模型的组件数量往往颇具难度,迄今为止已有诸多相关提议。在此,我们将通过已知组数来探讨混合模型边际似然的估计方法。需注意,可按如下方式(Gómez - Rubio,2017)计算边际似然:
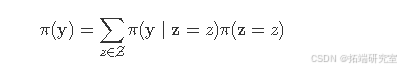
要注意的是,在给定(z)的情况下,通过用INLA拟合模型所返回的边际似然能够较为准确地近似(\pi(y\mid z = z))。此外,(\pi(z))是先验分布,其始终是已知的。
另外,还可通过如下方式(Chib,1995)计算混合模型的边际似然:
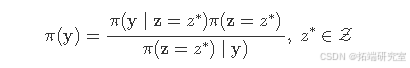
需注意,为使上述计算稳定,(z^{*})的后验概率必须远离零。一个不错的选择是(z)的后验众数。
例如,我们可以选取具有最高边际似然值的(z)值(注意所有(z)值的先验值相同),这里选取在第60次迭代时得到的值:
登录后复制 代码解读
plain
z.idx <- 60然后,由INLA提供的条件边际似然(\pi(y\mid z = z^{*}))的估计值为:
登录后复制 代码解读
bash
# 边际似然(对数尺度)
mliks[z.idx]输出结果如下:
登录后复制 代码解读
plain
## [1] -131.8接下来,计算(z^{})处的先验(\pi(z = z^{}))(对数尺度):
登录后复制 代码解读
bash
# 先验(对数尺度)
prior.z(inlamh.res$b.sim[[z.idx]])输出结果如下:
登录后复制 代码解读
plain
## [1] -207.3最后,从通过MCMC算法获得的(z)的后验分布样本中获取(z{*})的后验概率。具体做法是简单检查(z{*})在(z)的后验分布样本中出现的比例:
登录后复制 代码解读
bash
# 后验概率
z.post <- table(apply(zz, 1, function(x) {paste(x, collapse = "")})) / 100
# 获取z^*的对数尺度后验概率
log.pprob <- unname(
log(z.post[names(z.post) ==
paste(inlamh.res$b.sim[[z.idx]]$z, collapse = "")])
)
log.pprob输出结果如下:
登录后复制 代码解读
plain
## [1] -1.561需要注意的是,上述使用了paste()函数,目的是通过将(z)的所有值拼接在一起为每个(z)值创建一个唯一的标签。生成的标签长度与观测值数量相同,可能会很长。无论如何,这是一种用标签标识潜在变量每个值的简单方法,不过在实际应用中应优先选择更简短的方式(如哈希表)。为(z)的每个值提供一个唯一标签,能让我们直接对样本值使用table()函数,以计算潜在变量每个值在MCMC样本中出现的次数。
因此,边际似然(对数尺度)的估计值为:
登录后复制 代码解读
bash
mlik.mix<- mliks[z.idx] + prior.z(inlamh.res$b.sim[[z.idx]]) - log.pprob
mlik.mix输出结果如下:
登录后复制 代码解读
plain
## [1] -337.5需要注意的是,这种边际似然的估计依赖于对(\pi(y\mid z = z^{}))(由INLA提供)和(\pi(z = z^{}\mid y))(从MCMC样本中获得)的近似。因此,为获得可靠估计,可能需要运行MCMC算法更多的迭代次数。
可将获得的这个边际似然值与对整个数据集拟合单一似然的高斯模型时INLA所报告的值进行比较:
登录后复制 代码解读
plain
inla(duration ~ 1, data = geyser)$mlik[1,1]输出结果如下:
登录后复制 代码解读
bash
## log marginal-likelihood (integration)
## -478.6不同组件数量混合模型的应用与分析
最后,可使用相同方法对数据拟合一个具有三个组件的模型。这需要将组数设置为三,并生成一个合适的起始点(在此例中,是将数据等分为三组):
登录后复制 代码解读
bash
# 组数
n.grp <- 3
# 初始分类
grp3 <- as.numeric(cut(geyser$duration, 3))
grp.init3 <- list(z = grp3, m = fit.inla.internal(y, grp3))接下来,设置先验均值以及建议分布的标准差尺度:
登录后复制 代码解读
bash
# 均值的先验
prior.means <- list(x1 = 2, x2 = 3.5, x3 = 5)
# 建议分布的标准差尺度
scale.sigma <- 1一旦定义了所有用于拟合具有三个组件的混合模型的参数,就可使用INLAMH()函数进行模型拟合:
然后,可按照之前类似的方法计算这个具有三个组件的混合模型的边际似然。首先,获取具有最大条件边际似然((z^{*}))的(z)值:
登录后复制 代码解读
bash
## 条件(在z上)边际似然
mliks3 <- do.call(rbind, lapply(inlamh.res3$model.sim, function(X){X$mlik}))
# 具有最大条件边际似然的z^*
z.idx3 <- which.max(mliks3)接下来,从MCMC样本中估计(z^{*})的对数后验概率:
最后,通过将这两个值与(z^{*})的先验概率相结合来估计边际似然:
登录后复制 代码解读
bash
# 边际似然
mlik.mix3 := mliks3[z.idx3] + prior.z(inlamh.res3$b.sim[[z.idx3]]$z) -
log.pprob3
mlik.mix3输出结果如下:
登录后复制 代码解读
plain
## [1] -291.4需要注意的是,现在获得的边际似然估计值比具有1个和2个组件的模型的估计值要大。这意味着数据中可能(至少)有三个组,而非如Zucchini、MacDonald和Langrock(2016)所讨论的只有两个组。
为了汇总使用具有2个和3个组件的模型的拟合情况,图展示了利用模型参数的后验均值得到的混合情况。将使用函数inla.merge()来合并在Metropolis - Hastings算法中获得的所有模型。这将提供模型中均值和精度的后验均值。权重(w)的后验均值将从每个组中观测值比例的后验均值中获得(假设先验是非常模糊的均匀先验)。
类似地,对于具有3个组件的模型:
生存模型治愈模型在INLA中的应用及相关分析
生存模型假设所有个体最终都会经历感兴趣的事件。然而,在某些情况下,个体可能被治愈,因此不会再经历该事件。典型的情况是患者在接受适当治疗后从疾病中康复。
这种情况可以方便地用一个包含两组的混合模型来表示:一组是治愈的个体,另一组是未治愈且已经经历或最终会经历事件的个体。这是一种特殊的只有两类的混合模型。此外,由于一些个体已经经历了事件,所以会自动被分配到第二组。这使得治愈模型更容易识别,因为这些个体有助于识别第二组,进而有助于识别第一组。
模型描述
该模型可以描述如下:
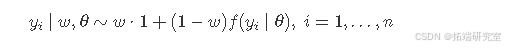
这里,f(⋅∣θ)f(⋅∣θ)表示威布尔分布,在INLA中其参数化如下:
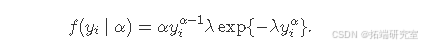
注意,威布尔分布的这种参数化类似于似然函数weibull中variant = 0的威布尔族。
在上述方程中,yiyi表示生存时间,它是一个非负变量,αα是正形状参数,λλ是与线性预测因子相关的参数。这种关联如下:
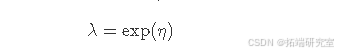
该模型的先验是在参数αα和ww的内部表示上定义的。特别地,内部参数化如下:
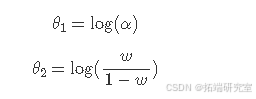
这种参数化确保了θ1θ1和θ2θ2不在有界区间内,这简化了优化和模型拟合。θ1θ1的默认先验是参数为25和25的对数伽马分布,θ2θ2的先验是均值为 - 1、精度为0.2的高斯分布。
(Cai等人)提供了来自东部肿瘤协作组(ECOG)III期临床试验e1684的数据集(详见Kirkwood等人)。该临床试验是为了测试干扰素α - 2b(IFNα - 2b)在转移性黑色素瘤中是否具有抗肿瘤活性。
原始数据集可以按如下方式加载:
为了使总结结果更具信息量,将为数据集中的因子分配这些标签:
登录后复制 代码解读
bash
# 为因子分配标签
e1684$TRT <- as.factor(e1684$TRT)
levels(e1684$TRT) <- c("Control", "IFN")
e1684$SEX <- as.factor(e1684$SEX)
levels(e1684$SEX) <- c("Female", "Male")最后,由于存在缺失观测值,将删除第37个观测值:
登录后复制 代码解读
bash
# 删除第37个观测值,因为它有缺失值
d <- na.omit(e1684)现在,可以对数据进行如下总结:
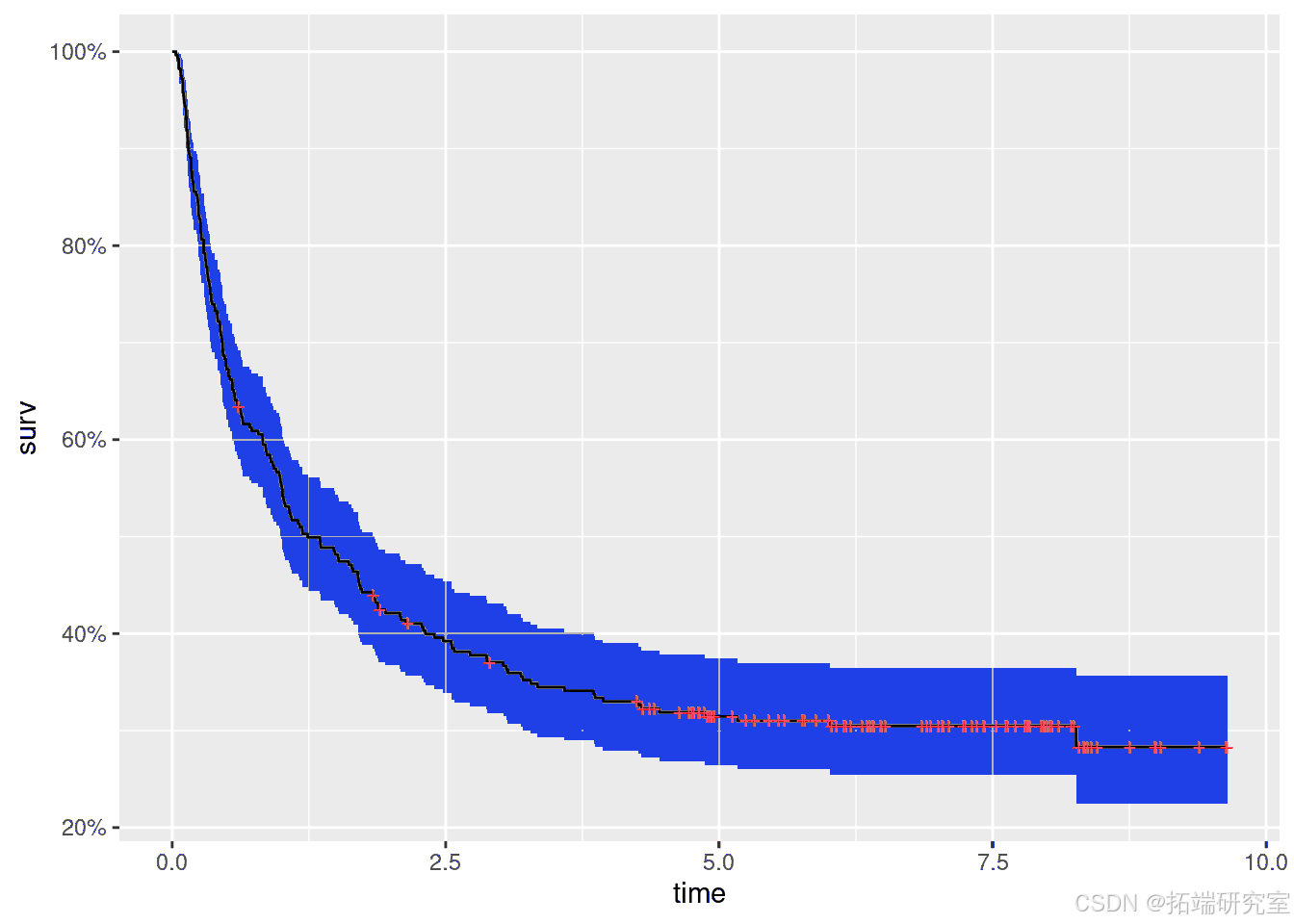
接下来,使用survival包中的survfit()函数获得生存时间的Kaplan - Meier估计:
登录后复制 代码解读
bash
# 加载survival库
library("survival")
# 使用survfit函数计算Kaplan - Meier估计
km <- survfit(Surv(d$FAILTIME, d$FAILCENS) ~ 1)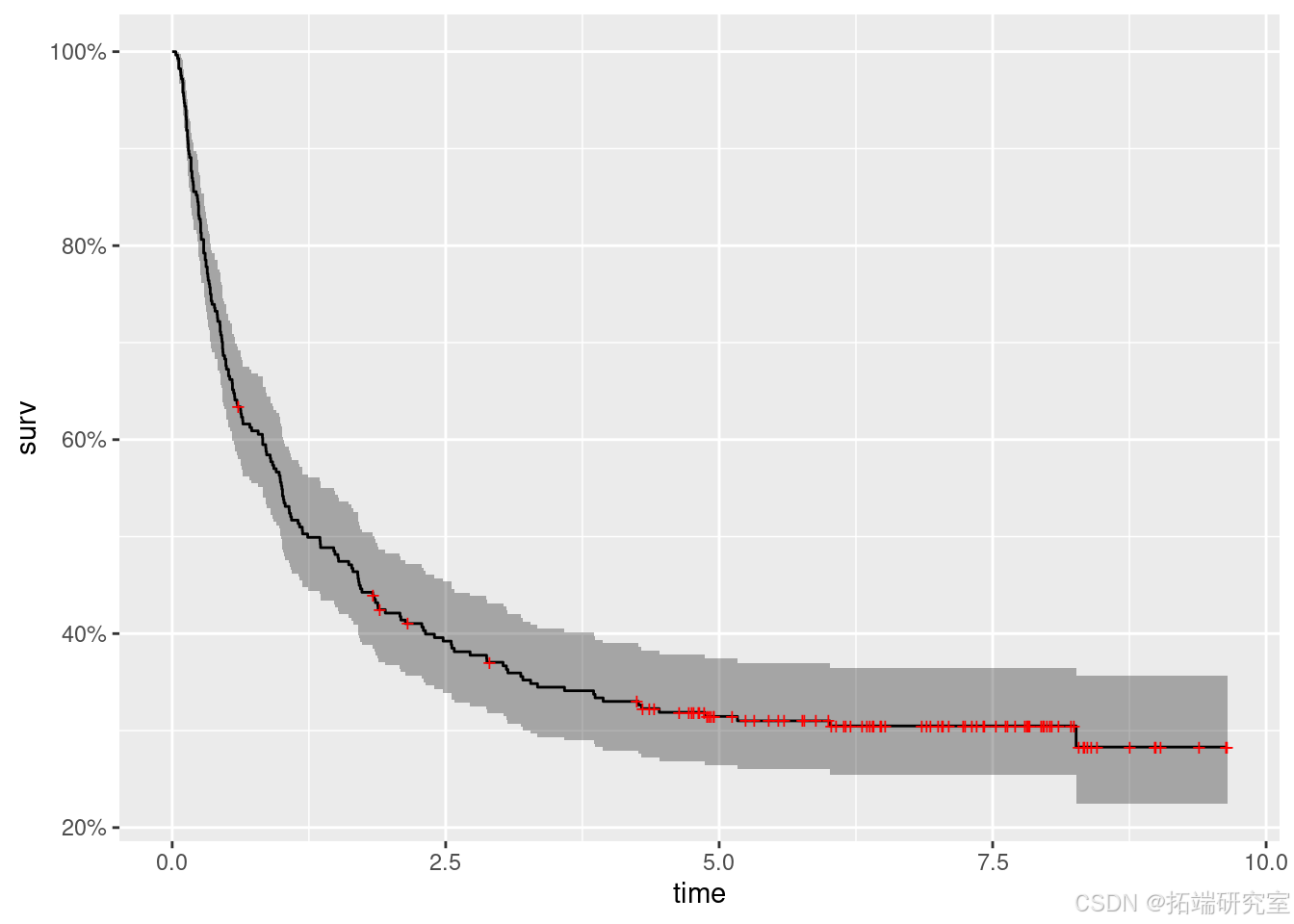
接下来拟合模型。
登录后复制 代码解读
bash
# 创建用于INLA分析的数据列表
d.inla <- list(y = inla.surv(d$FAILTIME, d$FAILCENS),
Treatment = d$TRT, Age = d$AGE, Female = d$SEX)
# 使用INLA拟合治愈模型
cure.inla <- inla(y ~ Treatment + Age + Female, family = "weibullcure",
data = d.inla)
summary(cure.inla)
这些估计值与Lázaro、Armero和Gómez - Rubio报告的相似,他们比较了MCMC和一种与INLA中的吉布斯采样类似的不同模型拟合方法。
注意,治愈模型估计治愈患者比例的后验均值为0.2968。使用典型的威布尔生存模型(即忽略被治愈的可能性)将得到以下结果:
登录后复制 代码解读
bash
# 使用INLA拟合威布尔生存模型
weibull.inla <- inla(y ~ Treatment + Age + Female, family = "weibullsurv",
data = d.inla, control.family = list(list(variant = 0)))
summary(weibull.inla)
注意现在治疗的效果是显著的。因此,假设患者可以被治愈对模型中主要效应的估计有重要影响。此外,治愈模型的边缘似然大于威布尔模型的边缘似然,这表明治愈模型拟合得更好。然而,请记住,边缘似然不会对模型的复杂性进行惩罚。过度拟合的模型往往有更高的边缘似然值。
参考文献
Azzalini, A., and A. W. Bowman. 1990. "A Look at Some Data on the Old Faithful Geyser." Applied Statistics 39: 357--65.
Cai, Chao, Yubo Zou, Yingwei Peng, and Jiajia Zhang. 2012a. "Smcure: An R-Package for Estimating Semiparametric Mixture Cure Models." Computer Methods and Programs in Biomedicine 108 (3): 1255--60.