
**前言:**大型语言模型(LLMs)的发展历程可以说是非常长,从早期的GPT模型一路走到了今天这些复杂的、公开权重的大型语言模型。最初,LLM的训练过程只关注预训练,但后来逐步扩展到了包括预训练和后训练在内的完整流程。后训练通常涵盖监督指导微调和对齐过程,而这些在ChatGPT的推广下变得广为人知。
自ChatGPT首次发布以来,训练方法学也在不断进化。在这几期的文章中,我将回顾近1年中在预训练和后训练方法学上的最新进展。
关于LLM开发与训练流程的概览,特别关注本文中讨论的新型预训练与后训练方法
每个月都有数百篇关于LLM的新论文提出各种新技术和新方法。然而,要真正了解哪些方法在实践中效果更好,一个非常有效的方式就是看看最近最先进模型的预训练和后训练流程。幸运的是,在近1年中,已经有四个重要的新型LLM发布,并且都附带了相对详细的技术报告。
• 在本文中,我将重点介绍以下模型中的**苹果的 AFM智能基础语言模型 **预训练和后训练流程:
• 阿里巴巴的 Qwen 2
• 苹果的 智能基础语言模型
• 谷歌的 Gemma 2
• Meta AI 的 Llama 3.1
我会完整的介绍列表中的全部模型,但介绍顺序是基于它们各自的技术论文在arXiv.org上的发表日期,这也巧合地与它们的字母顺序一致。
- 苹果的苹果智能基础语言模型(AFM)
我很高兴在arXiv.org上看到苹果公司发布的另一篇技术论文,这篇论文概述了他们的模型训练。这是一个意想不到但绝对是积极的惊喜!
2.1 AFM 概述
在《苹果智能基础语言模型》论文中,研究团队阐述了为"苹果智能"环境在苹果设备上使用而设计的两个主要模型的开发过程。为了简洁,本节将这些模型简称为AFM,即"苹果基础模型"。
具体来说,论文描述了两个版本的AFM:一个是30亿参数的设备上模型,用于在手机、平板或笔记本电脑上部署,另一个是更高能力的服务器模型,具体大小未指明。
这些模型是为聊天、数学和编程任务开发的,尽管论文并未讨论任何编程特定的训练和能力。
与Qwen 2一样,AFM是密集型的LLM,不使用混合专家方法。
2.2 AFM 预训练
我想向研究人员表示两大致敬。首先,他们不仅使用了公开可用的数据和出版商授权的数据,而且还尊重了网站上的robots.txt文件,避免爬取这些网站。其次,他们还提到进行了使用基准数据的去污染处理。
为了加强Qwen 2论文的一个结论,研究人员提到质量比数量更重要。(设备模型的词汇大小为49k词汇,服务器模型为100k词汇,这些词汇大小明显小于使用了150k词汇的Qwen 2模型。)
有趣的是,预训练不是进行了两个阶段,而是三个阶段!
1.核心(常规)预训练
2.持续预训练,其中网络爬取(较低质量)数据被降权;数学和代码被增权
3.通过更长的序列数据和合成数据增加上下文长度

AFM模型经历的三步预训练过程概述。让我们更详细地看看这三个步骤。
**2.2.1 预训练I:核心预训练 **
核心预训练描述了苹果预训练流程中的第一阶段。这类似于常规预训练,AFM服务器模型在6.3万亿个标记上进行训练,批量大小为4096,序列长度为4096个标记。这与在7万亿标记上训练的Qwen 2模型非常相似。
然而,对于AFM设备上的模型更为有趣,它是从更大的64亿参数模型(从头开始训练,如上一段所描述的AFM服务器模型)中提炼和修剪得到的。
除了"使用蒸馏损失,通过将目标标签替换为真实标签和教师模型的top-1预测的凸组合(教师标签分配0.9的权重)"之外,关于蒸馏过程的细节不多。我觉得知识蒸馏对于LLM预训练越来越普遍且有用(Gemma-2也使用了)。我计划有一天更详细地介绍它。现在,这里是一个高层次上如何工作的简要概述。

知识蒸馏的概述,其中一个小型模型(此处为AFM设备3B模型)在原始训练标记上训练,外加来自一个更大的教师模型(此处为6.4B模型)的输出。注意,a)中的交叉熵损失是用于预训练LLM的常规训练损失(有关如何实现常规预训练步骤的更多细节,请参阅我的《从零开始构建大型语言模型》一书第5章)。
如上所示,知识蒸馏仍然涉及在原始数据集上训练。然而,除了数据集中的训练标记之外,被训练的模型(称为学生)还从更大的(教师)模型接收信息,这比没有知识蒸馏的训练提供了更丰富的信号。缺点是你必须:1)首先训练更大的教师模型,2)使用更大的教师模型计算所有训练标记的预测。这些预测可以提前计算(需要大量存储空间)或在训练期间计算(可能会减慢训练过程)。
2.2.2 预训练II:持续预训练
持续预训练阶段包括了一个从4096个标记到8192个标记的小幅上下文延长步骤,使用的数据集包含1万亿个标记(核心预训练集是其五倍大)。然而,主要关注点是使用高质量数据混合进行训练,特别强调数学和编码。
有趣的是,研究人员发现在这种情况下蒸馏损失并无益处。
2.2.3 预训练III:
上下文延长 第三阶段预训练只涉及1000亿个标记(第二阶段使用的标记的10%),但代表了更显著的上下文延长到32768个标记。为了实现这一点,研究人员用合成的长上下文问答数据增强了数据集。
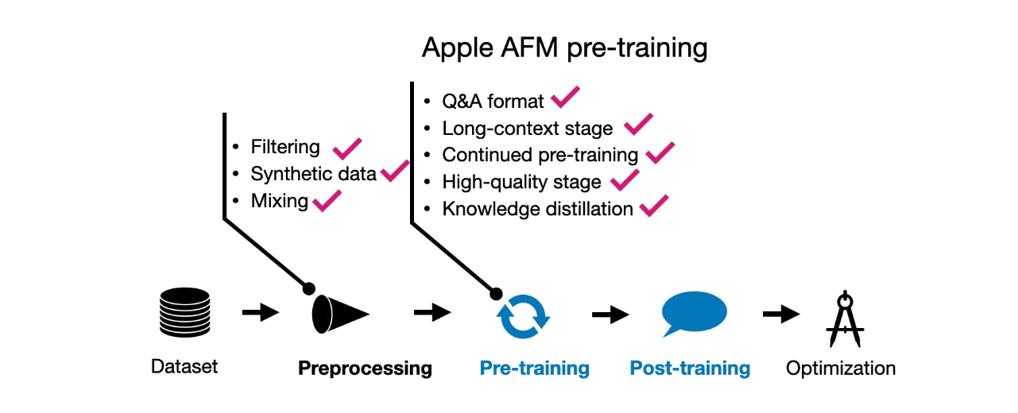
AFM预训练技术概述。**2.3 AFM后训练 **
苹果公司在后训练过程中似乎采取了与预训练相似的全面方法。他们利用了人工标注数据和合成数据,强调优先考虑数据质量而非数量。有趣的是,他们没有依赖预设的数据比例;相反,他们通过多次实验精调数据混合,以达到最佳平衡。
后训练阶段包括两个步骤:监督指令微调,随后进行数轮带有人类反馈的强化学习(RLHF)。
这个过程中一个特别值得注意的方面是苹果引入了两种新算法用于RLHF阶段:
-
带教师委员会的拒绝采样微调(iTeC)
-
带镜像下降策略优化的RLHF
鉴于文章的长度,我不会深入这些方法的技术细节,但这里有一个简要概述:
iTeC算法结合了拒绝采样和多种偏好调整技术------具体来说,是SFT、DPO、IPO和在线RL。苹果没有依赖单一算法,而是使用每种方法独立训练模型。这些模型然后生成响应,由人类评估并提供偏好标签。这些偏好数据被用来在RLHF框架中迭代训练一个奖励模型。在拒绝采样阶段,一个模型委员会生成多个响应,奖励模型选择最佳的一个。
这种基于委员会的方法相当复杂,但应该相对可行,特别是考虑到涉及的模型相对较小(大约30亿参数)。在像Llama 3.1中的70B或405B参数模型上实现这样的委员会,无疑会更具挑战性。
至于第二种算法,带镜像下降的RLHF,之所以选择它是因为它比通常使用的PPO(邻近策略优化)更有效。

AFM后训练技术总结。**2.4 结论 **
苹果在预训练和后训练的方法相对全面,这可能是因为赌注很高(该模型部署在数百万甚至数十亿的设备上)。然而,考虑到这些模型的小型性质,广泛的技术也变得可行,因为一个30亿参数的模型不到最小的Llama 3.1模型大小的一半。
其中一个亮点是,他们的选择不仅仅是在RLHF和DPO之间;相反,他们使用了多种偏好调整算法形成一个委员会。
同样有趣的是,他们在预训练中明确使用了问答数据------这是我在之前文章中讨论的《指令预训练LLM》。
总之,这是一份令人耳目一新且令人愉快的技术报告。