241124_基于MindSpore学习GPT1
在实际中,往往未标注的文本数据远多于已标注的,这些未标注的文本数据无法投入训练,又浪费
提出了一种方法,基于大量未标注的文本数据,训练预训练语言模型,学习到一些general的特征。然后使用已标注的文本数据,对模型针对某一特定下游任务进行finetune,微调,仅更改output layer,就是GPT1
存在问题:多元的下游任务难以有统一的优化目标。同时较难将预训练模型学到的信息传递到下游任务中。
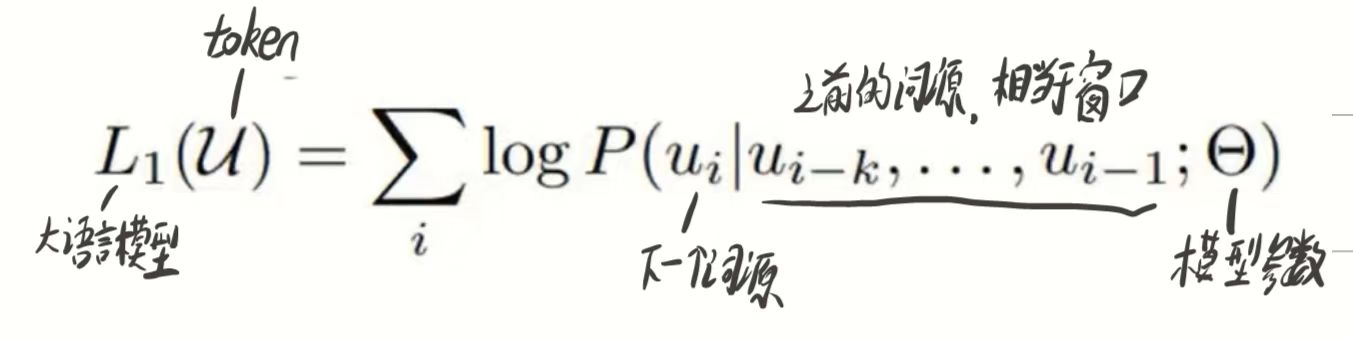
这里就体现出来和bert的区别
bert两个任务:一个完形填空,一个上下文判断
gpt1只能实现单向的任务,根据前向的词判断后面的词,在文本生成的任务中表现较好
两个模型都是基于transformer衍生的分支,bert是双向的,需要看到前后文的整体信息,使用的是encoder结构,gpt1是单向的,看不到当前词后面的内容,用的decoder结构。
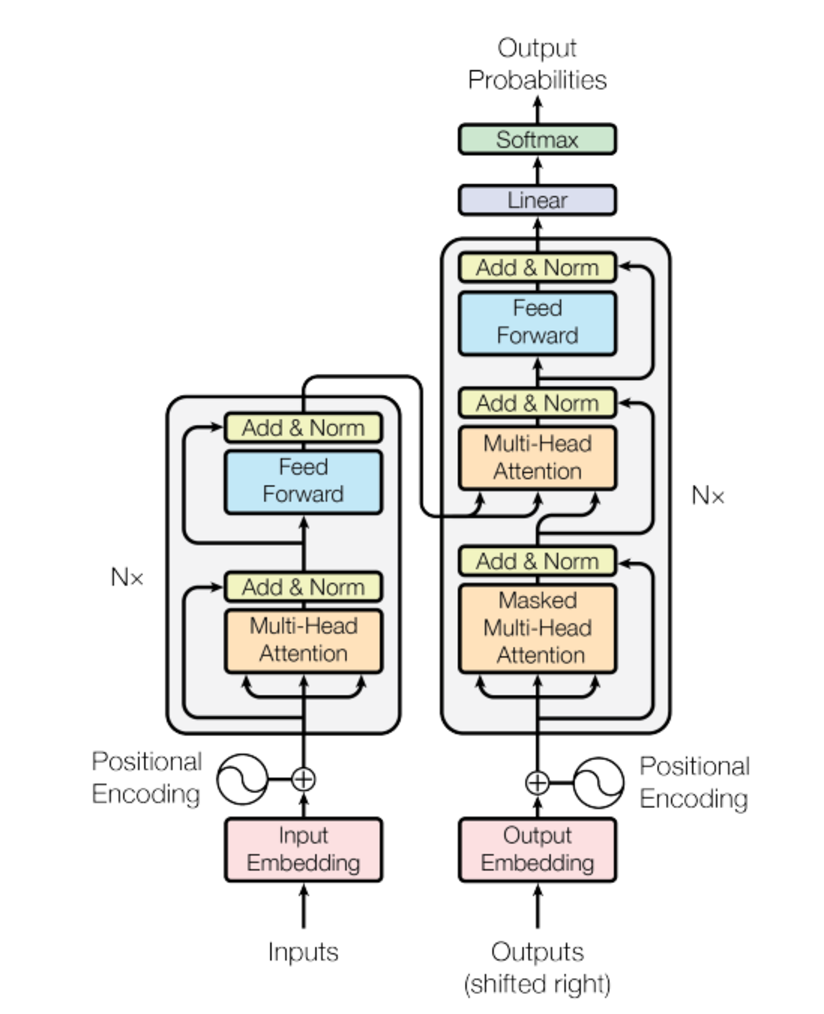
这里我们可以看到,右侧decoder结构中,中间那一层multihead attention层是用于处理从encoder中拿来的信息的,我们在gpt中没有encoder结构,所以此处也不需要这个多头注意力了,所以gpt使用的decoder是从transformer的decoder中去除了中间那层Multi-Head Attention。
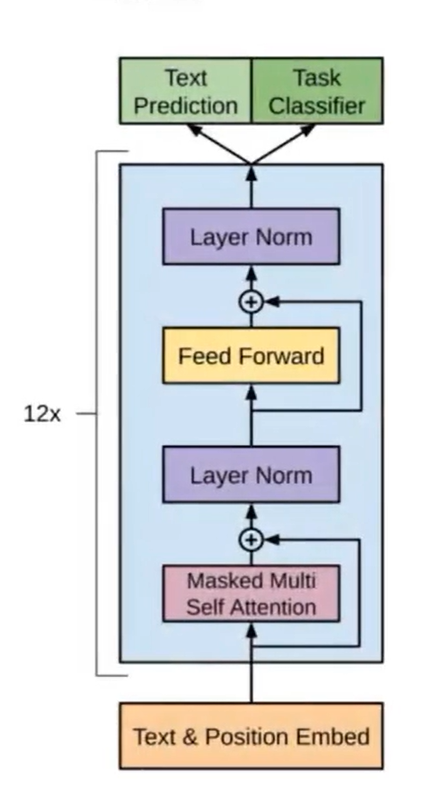
Fine-Tuning
在已经训练好的gpt上额外加一层线性层。然后使用已经标注好的数据进行训练
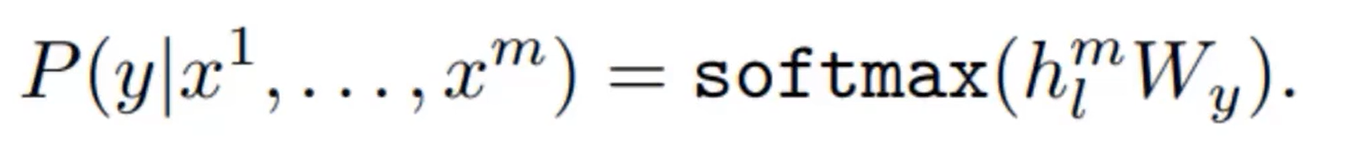
这样出来的结果是模型自己计算出来的label,然后和正确的label进行计算误差,通过缩小目标与计算结果的误差进行模型优化
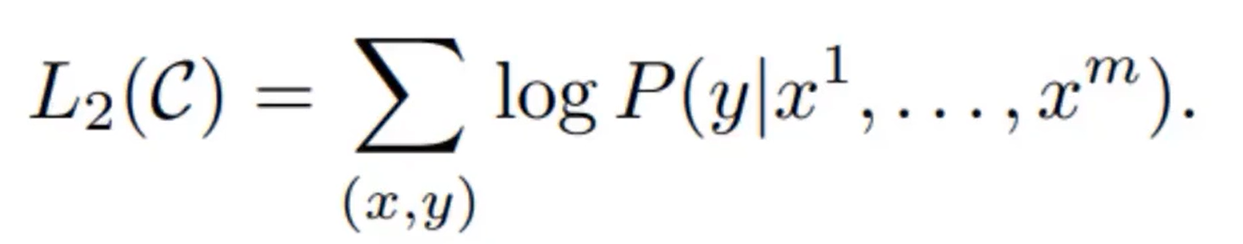
后续优化过程中发现,采用下述优化方式模型收敛速度更快
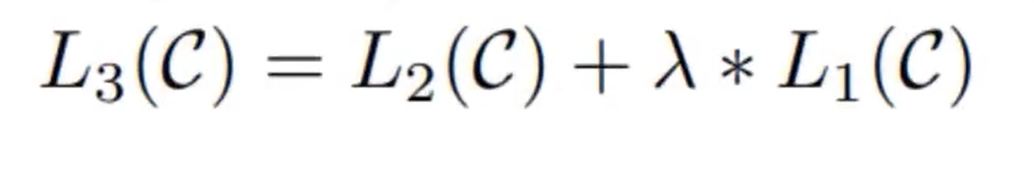
这里的L1说是最开始宏观的产生的output,具体实现如下:

根据下游任务的不同,输入和线性层可能会做一些改变
classification分类任务。entailment推理任务。similarity判断相似任务,multiple choice多项选择任务。
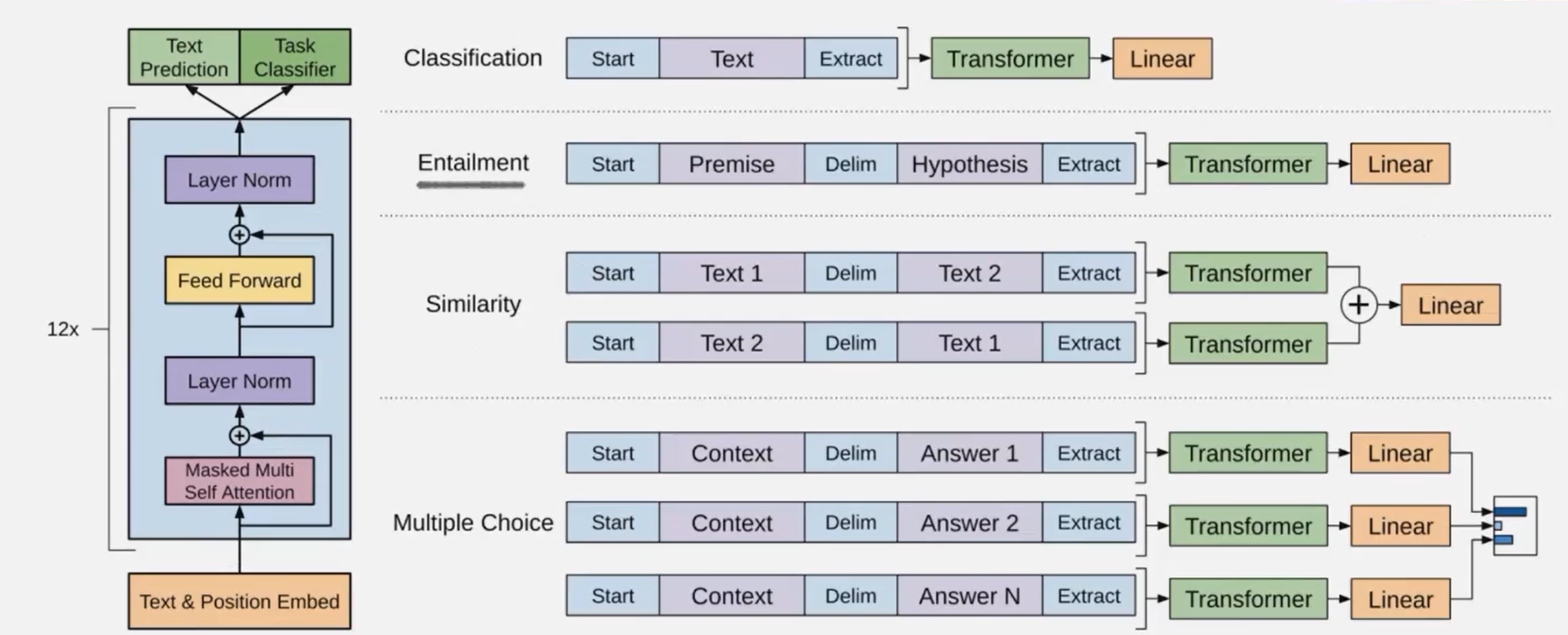
这里面要注意,在Similarity任务判断相似性中,只用一组就只能实现单向对比,比如第一行,只能判断1像不像2,但不能判断2像不像1,所以我们就要送一对进去。
在Multiple Choice任务中,每次都是问题和其中一个选项进行比较,然后通过Linear输出一个logits,最后我们把几个logits拿来进行比较,哪个大就输出哪个。
打卡截图: