对于Hive分区表,在我们插入数据的时候需要指定对应的分区值,而这里就会涉及很多种情况。比如静态分区插入、动态分区插入、提供的分区值和分区字段类型不一致,或者提供的分区值是NULL的情况,下面我们依次来展现下不同情况下的表现。
1. 静态分区和动态分区
假如建表如下:
create table tbl_name(xxx) partitioned by(pt xxx, online xxx);
Hive默认是静态分区,即明确指定分区值,写法如下:
insert overwrite table tbl_name partition(pt=20121023, if_online=1)
select field1, field2, ..., fieldn
from tbl where xxx;
有时,我们就需要使用动态分区,因为需要根据某些字段来选择插入对应的分区里,不能指定分区值。首先要开启动态分区设置:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
然后写法如下(注意select最后的字段值就是对应这分区值):
insert overwrite table tbl_name partition(pt, if_online)
select field1, field2, ..., pt, if_online
from tbl where xxx;
动态分区与静态分区还有一个细微的差别是,静态分区一定会创建分区,不管SELECT语句的结果有没有数据。而动态分区,只有在SELECT结果的记录数>0的时候,才会创建分区。因此在不同的业务场景下,可能会选择不同的方案。静态和动态并不是分区的属性,而只是指定值与不指定值的区别。另外可以混合使用动态和静态分区,不过要注意,静态分区列一定要在动态分区列前面。
2. 提供的分区值和分区字段类型不一致
这会导致数据会被插入到对应的分区值里,show partitions xxx也能显示出对应的分区值,但是在s查询时,有可能分区值是NULL,是不是NULL要看分区字段类型是否能兼容提供的分区值。
比如:
情况1:分区字段类型是int,提供的分区值是string(含有非数字)
create table t2(a int, b string) partitioned by(dt int);
insert into t2 partition(dt='2222') values(1, 'xxxx');
insert into t2 partition(dt='asd') values(2, 'xxxx');


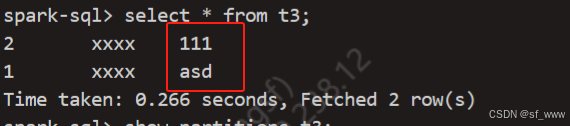
情况2:分区字段类型是string,提供的分区值是int
create table t3(a int, b string) partitioned by(dt string);
insert into t3 partition(dt=111) values(2, 'xxxx');
insert into t3 partition(dt='asd') values(1, 'xxxx');

3. 提供的分区值是NULL
只有动态分区才能提供分区值是NULL的情况,即
Insert into table partition(分区字段) select f1,f2...分区值 from xxx
然后分区值又没有值,即是null的情况下,这会导致Hive写入到默认分区 __HIVE_DEFAULT_PARTITION__里去。