一、开发的缘由
最近,有网友想让我帮他做一个批量把png, docx, doc, pptx, ppt, xls, xlsx文件转化为PDF格式的软件,完全傻瓜式的操作,把文件拖进去就进行转化那种,简单实用。之前,有过一个vbs的文件,可以转docx, xlsx, pptx,但是对于图片无能为力,为了完成这个任务还是要请出Python这个强大的利器。
二、开发的过程
-
为了能够实现拖动的功能,我首先想到要设计一个UI界面,然后可以直接接受拖动的文件。另外,因为是批量操作,需要一定的时间来完成操作,最好是可以添加一个进度条,让用户知道是否已经完成了转化。
-
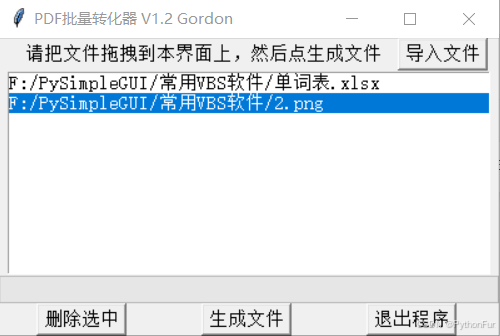
软件的外观本来想着简化,但是想着得让用户看到转化文件名的路径和文件名,避免转错了,同时还得可以删除选中的条目。所以我就设计了一个listbox控件,一个删除按钮、一个生成文件按钮,还有一个导入文件的按钮,为的是不习惯进行拖动的用户设计。
-
由于tkinter是系统自带的,所以可以使软件更小一点。另外,读取图片用到PIL这个模块,而其它如docx, pptx, xlsx文件的转化则需要依靠win32com.client这个模块。
-
我尝试了多种方法来执行拖动的功能,但是打包以后发现无法实现,于时最终采用了windnd这个模块,为了防止拖动时程序假死,我还用了多线程的方法。
三、成品介绍
我们这个软件最终起名为PDF批量转化器,它是一款支持多种文件格式批量转换为PDF格式的工具,特别适用于Word、Excel、PowerPoint、图片文件的转换。它提供了一个直观的界面,允许用户通过拖拽文件或通过文件选择器导入文件,支持多线程处理,提升了文件转换的效率。主要特点有:
多文件格式支持 :支持转换Word、Excel、PowerPoint和图片文件到PDF格式。
拖拽功能: 用户可以直接将文件拖拽至程序界面,简化操作流程。
进度条显示 :转换过程中,进度条实时显示,用户可以了解转换的进度。
批量处理: 一次可以处理多个文件,节省时间和操作精力。
文件管理 :提供文件导入、删除等操作,帮助用户管理文件列表。
**后台处理:**采用多线程方式处理文件转换,避免界面卡顿。
此外,为了增强用户体验,我们还增加了二个小功能,一是把生成的PDF文件统一放在一个PDF文件夹里面,另外就是如果发现同名PDF文件,就自动跳过这个文件,从而避免重复操作。
四、程序源码
为了帮助大家,特地放上这个源码,供大家调试使用,里面有丰富的知识点,认真学习或许还会有意想不到的收获。
python
import tkinter as tk
from tkinter import messagebox,ttk,filedialog
from PIL import Image
import os
import windnd
from threading import Thread
import win32com.client # pywin32 for Word, Excel, PPT processing
class WordProcessorApp:
def __init__(self, root):
self.root = root
self.root.title("PDF批量转化器 V1.2 Gordon ")
self.root.attributes("-topmost", True)
windnd.hook_dropfiles(self.root,func=self.drop_files)
self.file_list = []
self.create_widgets()
os.makedirs("PDF文件", exist_ok=True)
self.path = "PDF文件"
def create_widgets(self):
self.frame = tk.Frame()
self.frame.pack()
# 使用Combobox代替Checkbutton
self.label = tk.Label(self.frame, text = "请把文件拖拽到本界面上,然后点生成文件", font=("宋体", 11), width=38)
self.label.pack(side=tk.LEFT)
self.file_listbox = tk.Listbox(self.root,width=48,font = ("宋体",11))
self.file_listbox.pack()
self.import_button = tk.Button(self.frame, text="导入文件",font = ("宋体",11), command=self.import_file)
self.import_button.pack(sid=tk.LEFT)
frame1 = tk.Frame()
frame1.pack()
# Progress bar
self.progress_bar = ttk.Progressbar(frame1, orient="horizontal", length=400, mode="determinate")
self.progress_bar.pack()
self.delete_button = tk.Button(frame1, text="删除选中", font=("宋体", 11), command=self.delete_selected)
self.delete_button.pack(side=tk.LEFT,padx = 30)
self.generate_button = tk.Button(frame1, text="生成文件",font = ("宋体",11), command=self.generate_files)
self.generate_button.pack(side=tk.LEFT,padx = 30)
self.quit_button = tk.Button(frame1, text="退出程序",font = ("宋体",11), command=self.ui_quit)
self.quit_button.pack(side=tk.LEFT,padx = 30)
def ui_quit(self):
self.root.destroy()
def delete_selected(self):
selected_indices = self.file_listbox.curselection()
if not selected_indices:
messagebox.showwarning("Warning", "请先选择要删除的文件!")
return
for index in reversed(selected_indices):
self.file_listbox.delete(index)
del self.file_list[index]
def thread_it(self,func,*args):
self.thread1=Thread(target=func,args=args)
self.thread1.setDaemon(True)
self.thread1.start()
#---------------定义一个drop_files,然后用thread_it-------------
def drop_files(self,files):
self.thread_it(self.drop_files2,files)
#--------------找开文件对话框的代码--------------
def drop_files2(self,files=None):
for file_path in files:
file_path=file_path.decode("gbk")
file_path = file_path.replace('\\', '/')
if file_path not in self.file_listbox.get(0, tk.END):
# 将文件路径添加到Listbox中
self.file_listbox.insert(tk.END, file_path)
self.file_list.append(file_path)
return
def import_file(self):
filename = filedialog.askopenfilename(filetypes=[("Word files", "*.docx")])
if filename:
self.file_list.append(filename)
self.file_listbox.insert(tk.END, filename)
def generate_files(self):
if not self.file_list:
messagebox.showerror("Error", "文件列表为空!")
return
# for filename in self.file_list:
else:
self.convert_files()
def process_file(self, file_path, convert_func, update_progress):
path_without_extension = os.path.splitext(os.path.basename(file_path))[0]
pdf_path = os.path.join(os.path.abspath(self.path), path_without_extension + ".pdf")
# 检查目标文件是否已经存在
if os.path.exists(pdf_path):
print(f"文件 {pdf_path} 已经存在,跳过转换。")
return False # 文件已经存在,不进行转换
# 如果文件不存在,继续转换
if convert_func(file_path, pdf_path, update_progress):
return True
return False
def convert_files(self):
files = self.file_listbox.get(0, tk.END) # 获取列表框中的所有文件
total_files = len(files)
processed_files = 0
# 重置进度条
self.progress_bar['maximum'] = total_files # 设置进度条最大值
self.progress_bar['value'] = 0 # 重置进度条当前值为0
self.label.config(text="正在处理中...") # 更新提示标签
def update_progress():
nonlocal processed_files
processed_files += 1
self.progress_bar['value'] = processed_files
self.root.update_idletasks() # 更新UI
# 处理文件
excel_count = 0
word_count = 0
ppt_count = 0
img_count = 0
for file_path in files:
if file_path.lower().endswith((".xls", ".xlsx")): # Excel file
if self.process_file(file_path, self.excel_to_pdf, update_progress):
excel_count += 1
elif file_path.lower().endswith((".docx", ".doc")): # Word file
if self.process_file(file_path, self.word_to_pdf, update_progress):
word_count += 1
elif file_path.lower().endswith((".pptx", ".ppt")): # PowerPoint file
if self.process_file(file_path, self.ppt_to_pdf, update_progress):
ppt_count += 1
elif file_path.lower().endswith((".jpg", ".png")): # Image file
if self.process_file(file_path, self.img_to_pdf, update_progress):
img_count += 1
# 更新处理结果
self.label.config(text=f"转化{excel_count}个Excel,{word_count}个Word,"
f"{ppt_count}个PPT,{img_count}个图 ")
def excel_to_pdf(self, input_file, output_file, update_progress):
try:
excel = win32com.client.Dispatch("Excel.Application")
excel.Visible = False
wb = excel.Workbooks.Open(input_file)
wb.ExportAsFixedFormat(0, output_file)
wb.Close()
excel.Quit()
update_progress() # Update progress after conversion
return True
except Exception as e:
print(f"Error converting Excel to PDF: {e}")
return False
def word_to_pdf(self, input_file, output_file, update_progress):
try:
word = win32com.client.Dispatch("Word.Application")
doc = word.Documents.Open(input_file)
doc.SaveAs(output_file, FileFormat=17) # FileFormat=17 for PDF
doc.Close()
word.Quit()
update_progress() # Update progress after conversion
return True
except Exception as e:
print(f"Error converting Word to PDF: {e}")
return False
def ppt_to_pdf(self, input_file, output_file, update_progress):
try:
ppt = win32com.client.Dispatch("PowerPoint.Application")
ppt.Visible = False
presentation = ppt.Presentations.Open(input_file)
presentation.SaveAs(output_file, 32) # 32 for PDF format
presentation.Close()
ppt.Quit()
update_progress() # Update progress after conversion
return True
except Exception as e:
print(f"Error converting PowerPoint to PDF: {e}")
return False
def img_to_pdf(self, input_file, output_file, update_progress):
try:
img = Image.open(input_file)
img.save(output_file, "PDF", resolution=100.0)
update_progress() # Update progress after conversion
return True
except Exception as e:
print(f"Error converting image to PDF: {e}")
return False
if __name__ == "__main__":
root = tk.Tk()
app = WordProcessorApp(root)
root.mainloop()五、注意事项
-
文件类型限制:仅支持特定文件类型的转换,如:doc, docx, ppt, pptx, xls, xlsx和常见图片格式png,jpg格式,其他文件类型暂不适用。
-
软件依赖:需要安装pywin32和Pillow库,且转换Word、Excel、PowerPoint等文件格式时依赖安装Microsoft Office。
-
路径问题:确保文件路径不包含特殊字符,否则可能导致路径无法识别。
-
文件覆盖:如果转换后的PDF文件已存在,程序会跳过该文件以避免覆盖。