业务场景
假设批量有一张商户表,表字段中有商户名称和商户分类两个字段。
批量需要将最新的商户名称和分类的映射关系推到hbase供实时使用。
原实现方案
a.原方案内容
为解决批量晚批问题,批量推送hbase表时一份数据产生两类rowkey:T-1和T日两类。
即使批量晚批,也能用前一日推送的数据。

原文链接:实时离线融合计算的数据同步实践
b.原方案缺陷
如果2号的分区中有客户A,但是3号的分区中没有客户A。
但是原有方案会造一条客户号_3号的数据在hbase中,这种"假"数据不符合数据规范。
优化方案
准备两张hbase表,一张存放业务数据(数据表),一张存放数据版本日期(配置表)。
每次批量推送最新分区的业务数据到数据表后,向配置表插入一条此份数据的业务日期。
比如前一天向数据表中推送了主键rowkey为客户号_2号的业务数据后,将配置表的数据日期字段更新为2号。
同样今天向数据表推送完rowkey客户号_3号的业务数据后,将配置表的数据日期字段更新为3号。
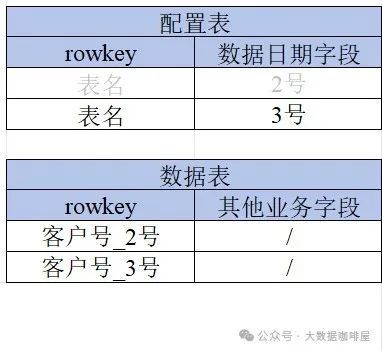
实时使用数据表的时候,会取出配置表中的数据日期字段,再和客户号进行拼接作为查询数据表的字段即客户号_日期。
如果批量今日晚批没有将客户号_3号的业务数据送过来后,从在配置表中取出的数据日期为2号,再用客户号_2号作为主键查询数据表。
这样即使批量晚批,优化后的新方案中实时一直能使用数据表最新分区的数据,而且也没有原方案的"假"数据问题。