引言
今天和大家分享一下一个在 Java 开发中非常重要的概念------ SPI(Service Provider Interface)。SPI 直译叫做服务提供者接口,是一种用于动态加载服务的机制。它不仅能够帮助我们构建更加灵活和可扩展的应用程序,还能让我们的代码更加简洁和易于维护。希望通过本文,大家能够对 SPI 有一个全面而深刻的理解,并能学会在实际项目中去运用它。
Java SPI 机制概述
定义与发展
SPI 是一种服务发现机制,它允许我们的应用程序在运行时动态地发现和加载服务提供者。简单来说,SPI 就是通过一种标准化的方式来进行功能扩展,而无需修改核心代码。这种机制使得应用程序可以更加灵活地适应不同的需求和环境。
SPI 是 Java 的一个内置标准,Java 中 JDBC 就是使用 SPI 机制来加载不同的数据库驱动,如 MySQL、PostgreSQL 等。随着 Java 平台的发展,SPI 机制也逐渐被广泛应用于 Java 生态中的各种其他场景,如日志框架、消息队列等。作为 Java 的标准扩展机制,SPI 极大地简化了插件化开发,使得应用更易于扩展。
SPI 机制的组成要素
SPI 机制主要由以下几个关键组件构成(以 JDBC 中 MySQL 驱动程序为例):
- 服务接口 :定义服务的标准接口,所有服务提供者必须实现此接口。 java.sql.Driver
- 服务提供者 :实现了服务接口的具体实现类。 com.mysql.cj.jdbc.Driver
- 配置文件 :位于
META-INF/services目录下的文件,文件名是服务接口的全限定名,文件内容是服务提供者实现类的全限定名列表。
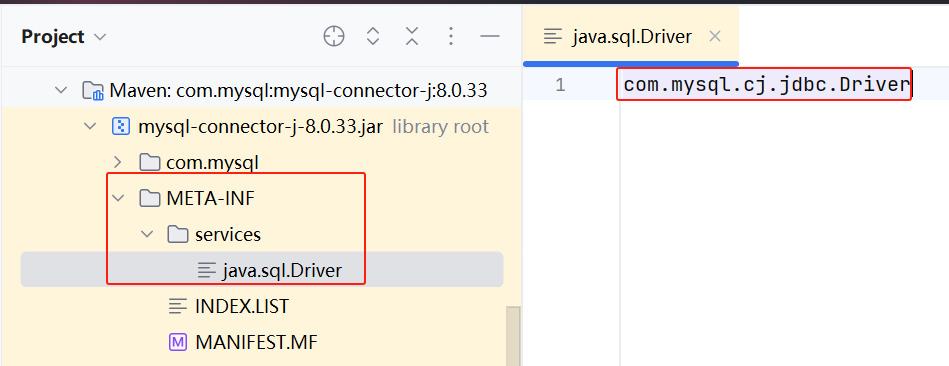
- 服务加载器 :
ServiceLoader类,负责读取配置文件并加载服务提供者。 java.util.ServiceLoader
总结 :通过上述这几个关键要素,我们不难看出,其实 SPI 机制的核心思想就是:解耦合。它制定了一套接口规范和一套服务发现机制,将服务的具体实现转移到应用之外,通过标准化配置的方式动态进行服务的加载,提高的应用的灵活性和扩展性。
Java SPI 的工作原理及源码分析
工作原理
Java SPI 机制通过 ServiceLoader 类来实现服务的动态加载。ServiceLoader 会查找 META-INF/services 目录下的配置文件,然后根据配置文件中的信息加载相应的服务提供者。
源码分析
接下来,我们通过阅读源码的方式,来看一下 ServiceLoader 的工作流程,搞清楚 ServiceLoader 如何解析并加载服务的,我们就掌握了 SPI 的工作原理了。
先来看一下 ServiceLoader 类的成员变量:
java
public final class ServiceLoader<S> implements Iterable<S> {
// 配置文件目录
private static final String PREFIX = "META-INF/services/";
// 需要被 SPI 加载的服务
private final Class<S> service;
// 用于加载和实例化 SPI 服务的类加载器
private final ClassLoader loader;
// 创建 ServiceLoader 时的访问控制上下文
private final AccessControlContext acc;
// 按实例化顺序缓存 SPI 服务提供者
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
// 当前的懒查找迭代器
private LazyIterator lookupIterator;
}下面,我们以 JDBC 加载数据库驱动程序时的代码片段为例,看一下 SPI 是如何使用的:
java
public class DriverManager {
static {
// 通过检查系统属性 jdbc.properties 加载初始 JDBC 驱动程序,然后使用 ServiceLoader 机制
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
}
private static void loadInitialDrivers() {
// 加载 java.sql.Driver 类型的服务,返回 ServiceLoader 实例
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
// ServiceLoader 实现了 Iterable 接口并重写了 iterator 方法,调用 iterator 方法返回一个迭代器
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
// 迭代器的遍历操作,获取所有可用的服务提供者实例
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
}在这段代码中:
DriverManager在静态代码块中调用了loadInitialDrivers方法。ServiceLoader.load(Driver.class):创建了一个ServiceLoader实例,该实例负责查找并加载实现了Driver接口的所有服务提供者。loadedDrivers.iterator():获取一个迭代器,用于遍历所有已加载的Driver实例。
可以看到,当使用 SPI 机制动态加载服务时,主要是通过 ServiceLoader.load 方法来实现的,这个方法会创建一个 ServiceLoader 实例。然后调用 iterator 方法,通过返回的迭代器获取所有可用的服务提供者实例。当调用 iterator 方法时,在方法内部 ServiceLoader 会先判断缓存 providers 中是否有数据:如果有,则直接返回缓存 providers 的迭代器;如果没有,则返回懒查找迭代器的迭代器。接下来,我们来看下这部分的源码:
java
// service是需要被加载的 SPI 接口类型
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
// 获取当前线程上下文的类加载器,用于加载 SPI 服务,然后调用重载构造方法。
return ServiceLoader.load(service, cl);
}
public static <S> ServiceLoader<S> load(Class<S> service, ClassLoader loader) {
// 创建 ServiceLoader 实例
return new ServiceLoader<>(service, loader);
}
// 私有构造方法
private ServiceLoader(Class<S> svc, ClassLoader cl) {
// 非空校验
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
// 调用 reload 方法,重新加载 SPI 服务
reload();
}
public void reload() {
// 清空缓存中所有已实例化的 SPI 服务
providers.clear();
// 创建懒查找迭代器,用于延迟加载服务提供者。
lookupIterator = new LazyIterator(service, loader);
}
// Iterable 接口实现,返回一个匿名内部类迭代器
public Iterator<S> iterator() {
return new Iterator<S>() {
// 已缓存的 SPI 服务提供者的迭代器
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
// 优先判断缓存中是否存在,有则返回
if (knownProviders.hasNext())
return true;
// 没有,则返回懒查找迭代器的迭代器
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}从上述源码中可以看出,如果缓存中没有的话,那么会执行懒查找迭代器 lookupIterator 的方法,下面我们看下 LazyIterator 类中的核心方法:hasNextService 与 hasNextService
java
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
// 拼接 META-INF/services/ + SPI 接口的全限定名
String fullName = PREFIX + service.getName();
// 通过类加载器,加载 fullName 路径的资源文件,也就是 SPI 的配置文件
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
// 解析配置文件的内容,文件内容是服务提供者实现类的全限定名列表
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
// 根据从配置文件中解析到的 `SPI` 实现类的全限定名,通过反射获取其 Class 对象
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
// 类型检验,校验下提供的 SPI 实现是否为 SPI 服务接口类型
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
// 创建 SPI 服务对象
S p = service.cast(c.newInstance());
// 加入到缓存当中
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}好了,到这里的话 Java SPI 的核心代码我们基本已经分析完了,通过上述对 ServiceLoader 的源码分析,相信大家对 Java SPI 机制的工作原理已经有了深入的理解,正所谓"实践出真知",大家可以去自定义 SPI 手动实践一下啦~
API 与 SPI 的区别
API (Application Programming Interface)
API 是应用程序编程接口,定义了一组规则和协议,用于不同软件组件之间的交互。API 通常由一组函数、方法、类、变量等组成,为开发者提供了访问特定功能或数据的方式。API 的设计目的是为了封装复杂性,提供一个清晰、一致的接口,使得开发者可以更方便地使用底层功能。通过 API,开发者可以利用预定义的功能而无需了解其内部实现细节。
SPI (Service Provider Interface)
SPI 是一种服务提供者接口,它定义了一种服务的标准接口,允许不同的服务提供者实现这个接口。SPI 的主要目的是为了实现服务的动态发现和加载,从而提高系统的灵活性和可扩展性。与 API 不同,SPI 强调的是服务提供者的发现和加载,而不是直接提供功能。
综上所述,API 与 SPI 的本质区别在于:
API由服务提供方提供接口规范,定义了如何使用其功能,并向外部暴露这些接口。SPI由服务调用方提供接口规范,定义了一个标准接口,然后由不同的服务提供者实现这个接口,从而实现服务的动态发现和加载。
区别对比
为了方便理解,请看下图:

SPI 机制的优劣势
优势
- 解耦服务接口与实现:将服务接口和实现分离,使得服务接口无需关注服务实现类的具体实现,实现了服务接口与服务实现的解耦。
- 便于扩展和维护:比如在新增服务提供者时,只需添加新的实现类和配置文件,无需修改现有代码。
不足
- 强依赖类加载器 :
SPI强依赖于类加载器,它的实现类必须放置在应用的类路径下才能被动态的发现和加载,这限制了服务发现的灵活性。 - 不能按需加载 :
SPI会对类路径下的实现进行全部加载,在大量服务提供者的情况下,加载过程可能会有性能开销。
Spring 框架中的 SPI
Spring 框架并没有直接使用 Java 的 SPI 机制,而是采用了类似 SPI 的机制实现了自己的扩展点机制。以 Spring Boot 的自动装配为例:Spring Boot 的自动装配机制通过扫描 spring.factories 文件中的配置,加载相应的自动配置类,而这种约定配置的方式就是通过 SPI 机制实现的。
按需加载
Spring Boot 的自动配置机制可通过条件注解(如 @ConditionalOnClass、@ConditionalOnMissingBean 等)来决定是否加载某个配置类。这种方式使得 Spring Boot 可以根据当前环境和依赖情况,按需加载配置类,避免了 Java SPI 中全部加载造成的不必要的性能开销。
关于 Spring Boot 自动装配的原理,请看我的这篇文章 SpringBoot 自动装配原理
还有哪些 SPI 应用案例?
- JDBC :
JDBC使用SPI机制来加载不同的数据库驱动。例如,MySQL和PostgreSQL都有各自的JDBC驱动实现,但它们都实现了java.sql.Driver接口。通过SPI机制,JDBC可以动态加载所需的数据库驱动,而无需硬编码。 - Dubbo :
Dubbo是一个高性能的Java RPC框架,它使用SPI机制来扩展其功能。Dubbo通过META-INF/dubbo/目录下的配置文件来加载各种扩展点,如协议、过滤器、注册中心等。这使得Dubbo具有高度的可扩展性和灵活性。 - SLF4J :它利用
SPI机制来发现和加载具体的日志实现。用户可以根据需要选择或更换日志实现,而无需修改应用程序代码。
结语
到这里,关于 Java 的 SPI 机制就介绍完了,感谢大家的阅读!如果你有任何疑问或建议,欢迎在评论区留言交流。
更多精彩内容,请微信搜索并关注【Java驿站】公众号。