一、数据获取方法
1. 开源数据集
免费,成本低
-
开源数据集imagenet:https://image-net.org/
-
Hugging Face数据集:https://huggingface.co/datasets
-
kaggle数据集下载网址:https://www.kaggle.com/datasets
-
各种网站:
2. 外包平台
效果好,成本高
外包平台(Amazon Mechanical Turk,阿里众包,百度数据众包,京东微工等)
3.自己采集和标注
质量高、效率低、成本高。
labelimg、labelme工具的使用。
4. 通过网络爬虫获取
爬虫工具
二、数据本地化
使用公开数据集时,会自动保存到本地。如果已下载,就不会重复下载。如果需要以图片的形式保存到本地以方便观察和重新处理,可以按照如下方式处理。
1. 图片本地化
使用一下代码保存图片到本地
python
dir = os.path.dirname(__file__)
def save2local():
trainimgsdir = os.path.join(dir, "MNIST/trainimgs")
testimgsdir = os.path.join(dir, "MNIST/testimgs")
if not os.path.exists(trainimgsdir):
os.makedirs(trainimgsdir)
if not os.path.exists(testimgsdir):
os.makedirs(testimgsdir)
trainset = torchvision.datasets.MNIST(
root=datapath,
train=True,
download=True,
transform=transforms.Compose([transforms.ToTensor()]),
)
for idx, (img, label) in enumerate(trainset):
labdir = os.path.join(trainimgsdir, str(label))
os.makedirs(labdir, exist_ok=True)
pilimg = transforms.ToPILImage()(img)
# 保存成单通道的灰度图
pilimg = pilimg.convert("L")
pilimg.save(os.path.join(labdir, f"{idx}.png"))
# 加载测试集
testset = torchvision.datasets.MNIST(
root=datapath,
train=False,
download=True,
transform=transforms.Compose([transforms.ToTensor()]),
)
for idx, (img, label) in enumerate(testset):
labdir = os.path.join(testimgsdir, str(label))
os.makedirs(labdir, exist_ok=True)
pilimg = transforms.ToPILImage()(img)
# 保存成单通道的灰度图
pilimg = pilimg.convert("L")
pilimg.save(os.path.join(labdir, f"{idx}.png"))
print("所有图片保存成功~~")2. 加载图片数据集
直接下载的图片文件目录也可以直接使用
python
trainpath = os.path.join(dir, "MNIST/trainimgs")
trainset = torchvision.datasets.ImageFolder(root=trainpath, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=32, shuffle=True)3. 本地图片序列化
把本地图片存储为 pickle序列化格式 ,然后通过 tar格式的形式分发。
python
#自己写代码:找个学生来讲一下++今天自己把本地的图片进行一个序列化处理。++
三、过拟合处理
1. 数据增强
可以使用transform完成对图像的数据增强,防止过拟合发生
https://pytorch.org/vision/stable/transforms.html
1.1 数据增强的方法
-
随机旋转

-
镜像

-
缩放
-
图像模糊

-
裁剪

-
翻转
-
饱和度、亮度、灰度、色相

-
噪声、锐化、颜色反转

-
多样本增强
SamplePairing操作:随机选择两张图片分别经过基础数据增强操作处理后,叠加合成一个新的样本,标签为原样本标签中的一种。

①、多样本线性插值:Mixup 标签更平滑

②、直接复制:CutMix, Cutout,直接复制粘贴样本

③、Mosic:四张图片合并到一起进行训练

1.2 数据增强的好处
查出更多训练数据:大幅度降低数据采集和标注成本;
提升泛化能力:模型过拟合风险降低,提高模型泛化能力
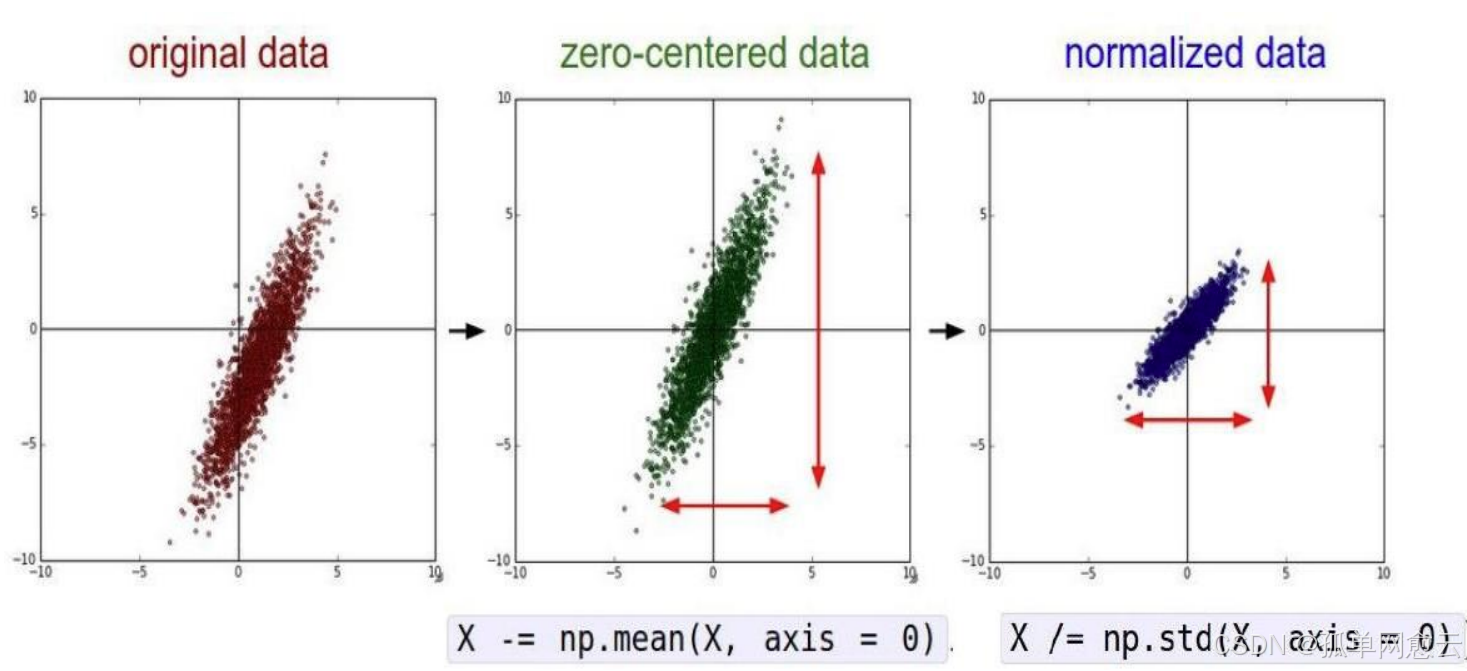
2. 标准化
3. DROP-OUT
处理过拟合问题的

4. 欠拟合注意事项
欠拟合: 如果模型在训练集和验证集上表现都不够好,考虑增加模型的层级或训练更多的周期。
四、训练过程可视化
1. wandb.ai
可在控制台看到训练进度。
官方文档有清晰简单的代码及思路,直接使用即可:https://wandb.ai/
1.1 安装
python
pip install wandb1.2 登录
python
wandb login复制平台提供的 API key粘贴回车即可(粘贴之后看不到的)。
1.3 初始化配置
python
import random
# start a new wandb run to track this script
wandb.init(
# set the wandb project where this run will be logged
project="my-awesome-project",
# track hyperparameters and run metadata
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
}
)1.4 写入训练日志
python
# log metrics to wandb
wandb.log({"acc": correct / samp_num, "loss": total_loss / samp_num}) 1.5 添加模型记录
python
# 添加wandb的模型记录
wandb.watch(model, log="all", log_graph=True)1.6 完成
python
# [optional] finish the wandb run, necessary in notebooks
wandb.finish()1.7 查看
根据控制台提供的访问地址去查看训练过程数据即可。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
数据简单说明:
- Process GPU Power Usage (W): GPU功率使用情况,以瓦特(W)为单位。
- Process GPU Power Usage (%): GPU功率使用占GPU总功率的百分比。
- Process GPU Memory Allocated (bytes): 分配给训练过程的GPU内存量,以字节为单位。
- Process GPU Memory Allocated (%): 分配给训练过程的GPU内存占GPU总内存的百分比。
- Process GPU Time Spent Accessing Memory (%): 训练过程中访问GPU内存的时间百分比。
- Process GPU Temp (°C): GPU温度,以摄氏度(°C)为单位。
2. Tensor Board
官方推荐的学习文档:
https://pytorch.org/tutorials/intermediate/tensorboard_tutorial.html
2.1 准备工作
导入tensorboard操作模块
python
from torch.utils.tensorboard import SummaryWriter指定tensorboard日志保存路径:可以指定多个实例对象
python
dir = os.path.dirname(__file__)
tbpath = os.path.join(dir, "tensorboard")
# 指定tensorboard日志保存路径
writer = SummaryWriter(log_dir=tbpath)2.2 保存训练过程曲线
记录训练数据
python
# 记录训练数据到可视化面板
writer.add_scalar("Loss/train", loss, epoch)
writer.add_scalar("Accuracy/train", acc, epoch)训练完后记得关闭
python
writer.close()2.3 曲线查看
安装:安装的是执行指令,是一个本地化的服务器
python
pip install tensorboard在训练完成后,查看训练结果,在当前目录下,打开控制台窗口:
python
tensorboard --logdir .控制台会提示一个访问地址,用浏览器直接访问即可。
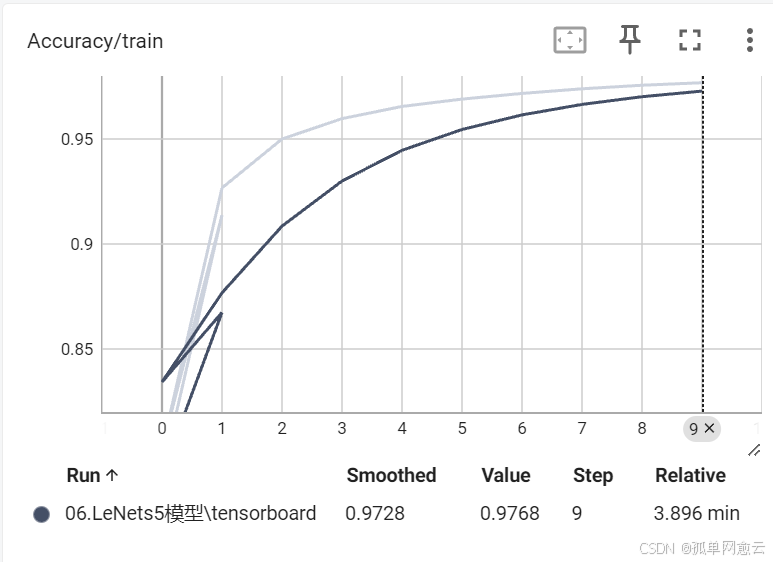
2.4 保存网络结构
保存网络结构到tensorboard
python
# 保存模型结构到tensorboard
writer.add_graph(net, input_to_model=torch.randn(1, 1, 28, 28))
writer.close()启动tensorboard,在graphs菜单即可看到模型结构
2.5 模型参数可视化
python
# 获取模型参数并循环记录
params = net.named_parameters()
for name, param in params:
writer.add_histogram(f"{name}_{i}", param.clone().cpu().data.numpy(), epoch)2.6 记录训练数据
tensorboard中的add_image函数用于将图像数据记录到TensorBoard,以便可视化和分析。这对于查看训练过程中生成的图像、调试和理解模型的行为非常有用,如帮助检查预处理是否生效。
python
#查看预处理的旋转是否生效
for i, data in enumerate(trainloader, 0):
inputs, labels = data
if i % 100 == 0:
img_grid = torchvision.utils.make_grid(inputs)
writer.add_image(f"r_m_{epoch}_{i * 100}", img_grid, epoch * len(trainloader) + i)