目录
-
- 前言
- [一、Depth Anything推理(Python)](#一、Depth Anything推理(Python))
-
- [1. Depth Anything预测](#1. Depth Anything预测)
- [2. Depth Anything预处理](#2. Depth Anything预处理)
- [3. Depth Anything后处理](#3. Depth Anything后处理)
- [4. Depth Anything推理](#4. Depth Anything推理)
- [二、Depth Anything推理(C++)](#二、Depth Anything推理(C++))
-
- [1. ONNX导出](#1. ONNX导出)
- [2. Depth Anything预处理](#2. Depth Anything预处理)
- [3. Depth Anything后处理](#3. Depth Anything后处理)
- [4. Depth Anything推理](#4. Depth Anything推理)
- [三、Depth Anything部署](#三、Depth Anything部署)
-
- [1. 源码下载](#1. 源码下载)
- [2. 环境配置](#2. 环境配置)
-
- [2.1 配置CMakeLists.txt](#2.1 配置CMakeLists.txt)
- [2.2 配置Makefile](#2.2 配置Makefile)
- [3. ONNX导出](#3. ONNX导出)
- [4. engine生成](#4. engine生成)
- [5. 源码修改](#5. 源码修改)
- [6. 运行](#6. 运行)
- [7. 补充说明](#7. 补充说明)
- 结语
- 下载链接
- 参考
前言
在 Depth-Anything推理详解及部署实现(上) 文章中我们有提到如何导出 Depth Anything 的 ONNX 模型,这篇文章就来看看如何在 tensorRT 上推理得到结果
Note :开始之前大家需要参考 Depth-Anything推理详解及部署实现(上) 将对应的环境配置好,并将 Depth Anything 的 ONNX 导出来,这里博主就不再介绍了
repo :https://github.com/Melody-Zhou/tensorRT_Pro-YOLOv8
reference :https://github.com/spacewalk01/depth-anything-tensorrt
Depth-Anything-V1

Depth-Anything-V2

一、Depth Anything推理(Python)
1. Depth Anything预测
我们先尝试利用官方预训练权重来推理一张图片并保存,看能否成功(以 V2 版本为主)
将下载好的预训练权重放在 Depth-Anything-V2/checkpoints 项目下,准备开始推理,执行如下指令即可进行推理:
shell
python run.py --encoder vitl --img-path assets/examples --outdir depth_vis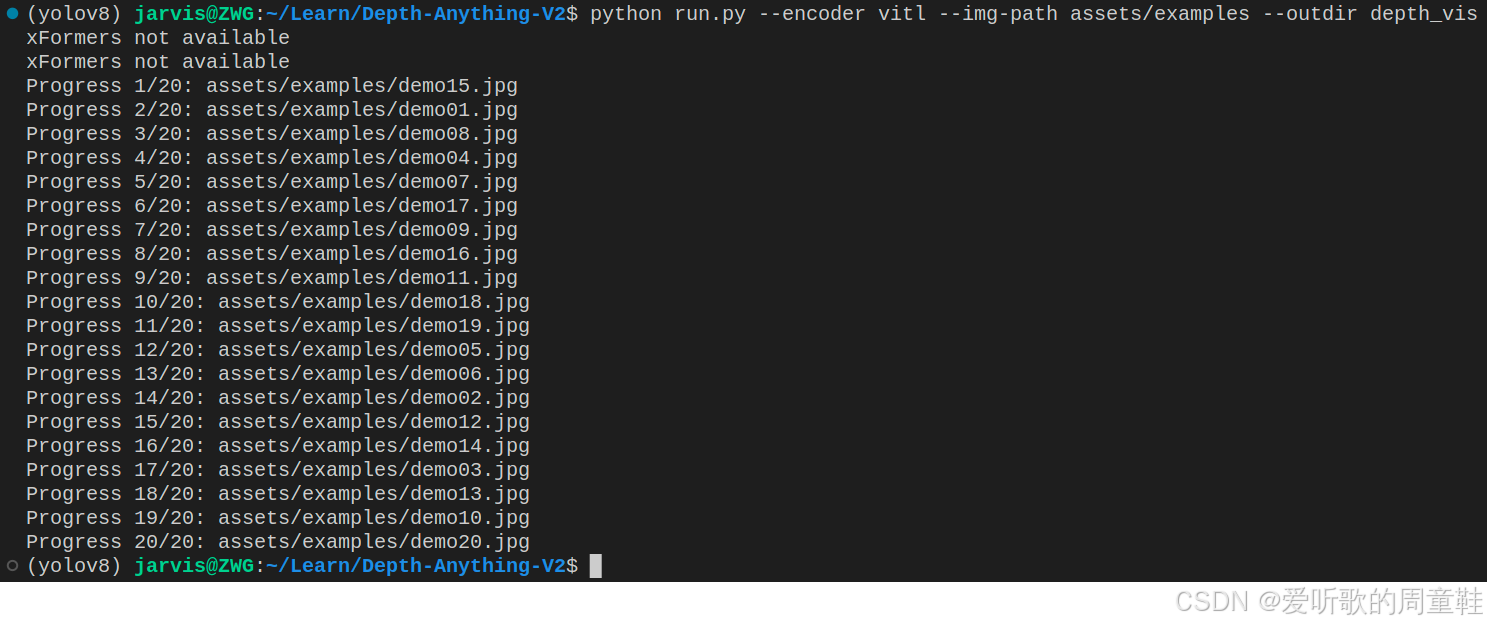
可以看到推理成功了,结果保存在 depth_vis 文件夹下,如下图所示:


2. Depth Anything预处理
模型推理成功后我们就要来梳理下 Depth Anything 的预处理和后处理,方便后续在 C++ 上实现,我们先看预处理的实现。
我们来调试 run.py 文件:
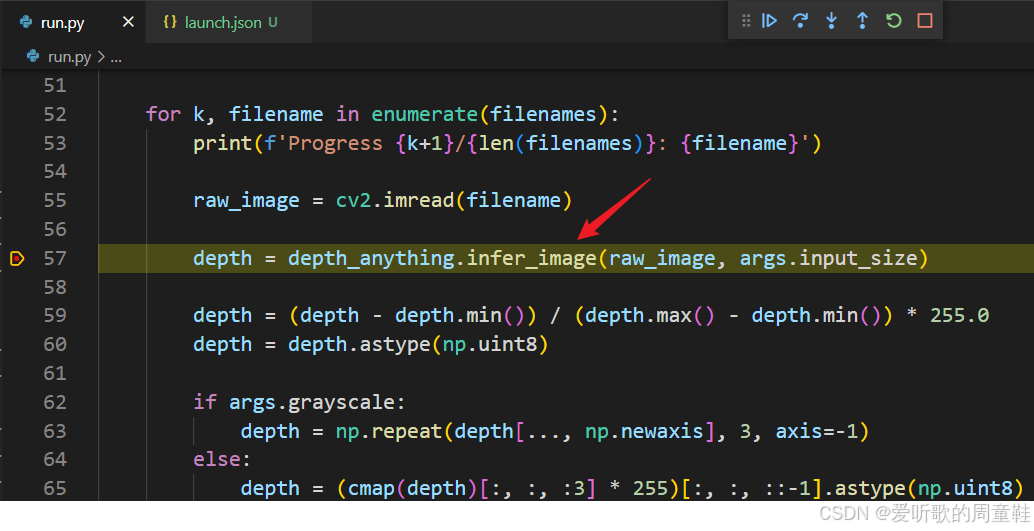
博主这里采用的是 vscode 进行代码的调试,其中的 launch.json 文件内容如下:
json
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"args": [
"--encoder", "vitl",
"--img-path", "assets/examples",
"--outdir", "depth_vis"
],
"program": "${file}",
"console": "integratedTerminal",
"justMyCode": true
}
]
}可以清晰的看到代码中首先通过 opencv 读取了一张图像,然后通过 DepthAnythingV2 类的 infer_image 方法推理,我们进入该函数看下内部具体的实现:
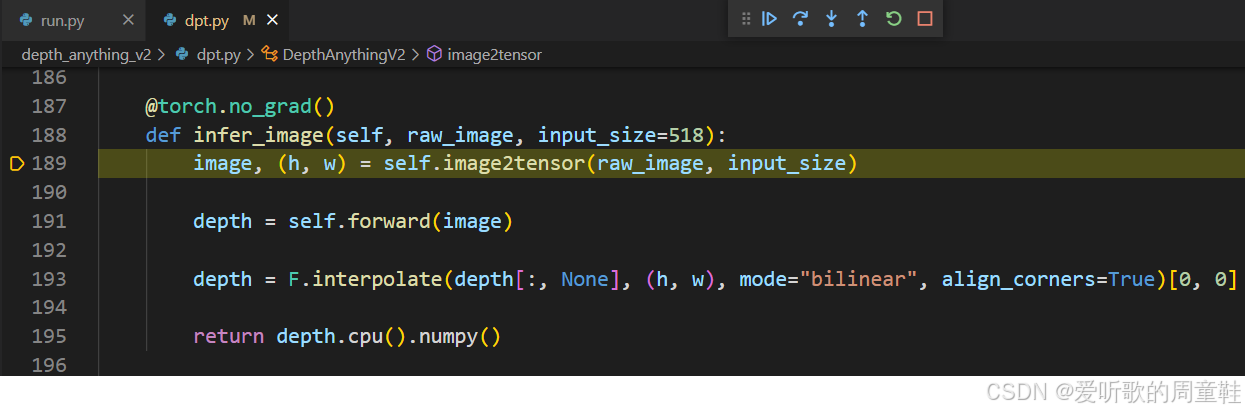
可以看到代码结构非常清晰,通过 self.image2tensor 做预处理,然后 forward 前向传播推理得到结果,接着插值恢复到原图,最后将结果返回
我们这里主要分析的是预处理,所以重点看 self.image2tensor 函数内部的实现即可
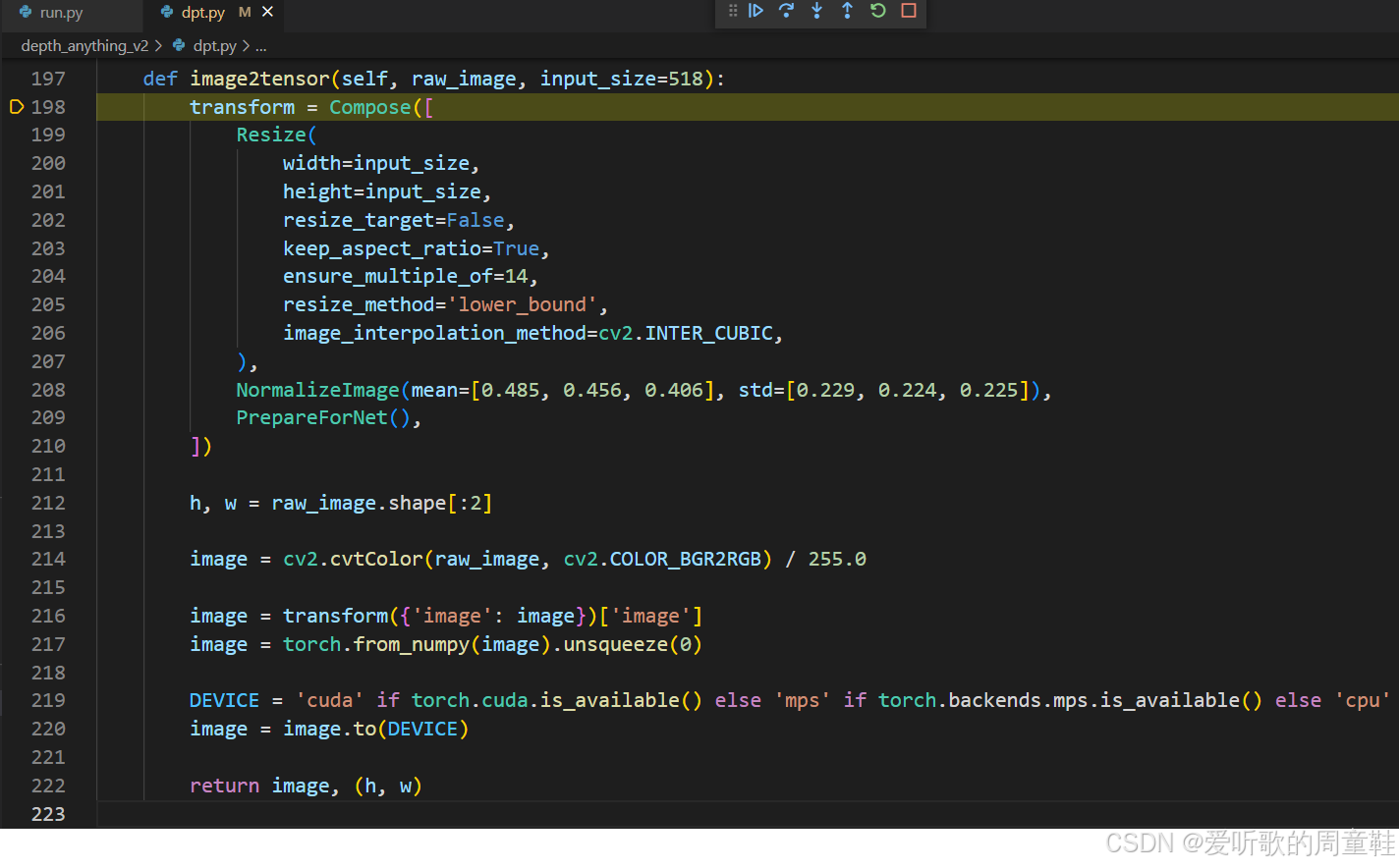
整个预处理函数内容如上图所示,非常清晰,其中的 Resize、NormalizeImage 以及 PrepareForNet 操作我们可以在 depth_anything_v2/util/transform.py 文件中找到相关的实现:
python
import numpy as np
import cv2
class Resize(object):
"""Resize sample to given size (width, height).
"""
def __init__(
self,
width,
height,
resize_target=True,
keep_aspect_ratio=False,
ensure_multiple_of=1,
resize_method="lower_bound",
image_interpolation_method=cv2.INTER_AREA,
):
"""Init.
Args:
width (int): desired output width
height (int): desired output height
resize_target (bool, optional):
True: Resize the full sample (image, mask, target).
False: Resize image only.
Defaults to True.
keep_aspect_ratio (bool, optional):
True: Keep the aspect ratio of the input sample.
Output sample might not have the given width and height, and
resize behaviour depends on the parameter 'resize_method'.
Defaults to False.
ensure_multiple_of (int, optional):
Output width and height is constrained to be multiple of this parameter.
Defaults to 1.
resize_method (str, optional):
"lower_bound": Output will be at least as large as the given size.
"upper_bound": Output will be at max as large as the given size. (Output size might be smaller than given size.)
"minimal": Scale as least as possible. (Output size might be smaller than given size.)
Defaults to "lower_bound".
"""
self.__width = width
self.__height = height
self.__resize_target = resize_target
self.__keep_aspect_ratio = keep_aspect_ratio
self.__multiple_of = ensure_multiple_of
self.__resize_method = resize_method
self.__image_interpolation_method = image_interpolation_method
def constrain_to_multiple_of(self, x, min_val=0, max_val=None):
y = (np.round(x / self.__multiple_of) * self.__multiple_of).astype(int)
if max_val is not None and y > max_val:
y = (np.floor(x / self.__multiple_of) * self.__multiple_of).astype(int)
if y < min_val:
y = (np.ceil(x / self.__multiple_of) * self.__multiple_of).astype(int)
return y
def get_size(self, width, height):
# determine new height and width
scale_height = self.__height / height
scale_width = self.__width / width
if self.__keep_aspect_ratio:
if self.__resize_method == "lower_bound":
# scale such that output size is lower bound
if scale_width > scale_height:
# fit width
scale_height = scale_width
else:
# fit height
scale_width = scale_height
elif self.__resize_method == "upper_bound":
# scale such that output size is upper bound
if scale_width < scale_height:
# fit width
scale_height = scale_width
else:
# fit height
scale_width = scale_height
elif self.__resize_method == "minimal":
# scale as least as possbile
if abs(1 - scale_width) < abs(1 - scale_height):
# fit width
scale_height = scale_width
else:
# fit height
scale_width = scale_height
else:
raise ValueError(f"resize_method {self.__resize_method} not implemented")
if self.__resize_method == "lower_bound":
new_height = self.constrain_to_multiple_of(scale_height * height, min_val=self.__height)
new_width = self.constrain_to_multiple_of(scale_width * width, min_val=self.__width)
elif self.__resize_method == "upper_bound":
new_height = self.constrain_to_multiple_of(scale_height * height, max_val=self.__height)
new_width = self.constrain_to_multiple_of(scale_width * width, max_val=self.__width)
elif self.__resize_method == "minimal":
new_height = self.constrain_to_multiple_of(scale_height * height)
new_width = self.constrain_to_multiple_of(scale_width * width)
else:
raise ValueError(f"resize_method {self.__resize_method} not implemented")
return (new_width, new_height)
def __call__(self, sample):
width, height = self.get_size(sample["image"].shape[1], sample["image"].shape[0])
# resize sample
sample["image"] = cv2.resize(sample["image"], (width, height), interpolation=self.__image_interpolation_method)
if self.__resize_target:
if "depth" in sample:
sample["depth"] = cv2.resize(sample["depth"], (width, height), interpolation=cv2.INTER_NEAREST)
if "mask" in sample:
sample["mask"] = cv2.resize(sample["mask"].astype(np.float32), (width, height), interpolation=cv2.INTER_NEAREST)
return sample
class NormalizeImage(object):
"""Normlize image by given mean and std.
"""
def __init__(self, mean, std):
self.__mean = mean
self.__std = std
def __call__(self, sample):
sample["image"] = (sample["image"] - self.__mean) / self.__std
return sample
class PrepareForNet(object):
"""Prepare sample for usage as network input.
"""
def __init__(self):
pass
def __call__(self, sample):
image = np.transpose(sample["image"], (2, 0, 1))
sample["image"] = np.ascontiguousarray(image).astype(np.float32)
if "depth" in sample:
depth = sample["depth"].astype(np.float32)
sample["depth"] = np.ascontiguousarray(depth)
if "mask" in sample:
sample["mask"] = sample["mask"].astype(np.float32)
sample["mask"] = np.ascontiguousarray(sample["mask"])
return sample我们总结下 Depth Anything 预处理包含以下步骤:
- cv2.cvtColor:BGR2RGB
- /255.0:除以 255,归一化
- Resize :将图像缩放到一定尺寸
- 默认是
lower_bound模式,保持长宽比的情况下,选择较大的缩放比例 - 假设输入图像是 1920x1080,目标大小是 518x518,
lower_bound模式下最终缩放的图像尺寸是 921x518 - 更多细节可以查看相关代码:depth_anything_v2/util/transform.py#L68
- 默认是
- NormalizeImage:减均值除以标准差
- PrepareForNet:维度变换,HWC->CHW
- unsqueeze:添加 batch 维度,CHW->BCHW
因此我们不难写出对应的预处理代码,如下所示:
python
def constrain_to_multiple_of(x, min_val=0, max_val=None, multiple_of=14):
y = (np.round(x / multiple_of) * multiple_of).astype(int)
if max_val is not None and y > max_val:
y = (np.floor(x / multiple_of) * multiple_of).astype(int)
if y < min_val:
y = (np.ceil(x / multiple_of) * multiple_of).astype(int)
return y
def preprocess(img, dst_width=518, dst_height=518):
# 0. BGR2RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 1. /255.0
img = (img / 255.0).astype(np.float32)
# 2. resize (lower_bound mode)
height = img.shape[0]
width = img.shape[1]
scale_height = dst_height / height
scale_width = dst_width / width
if scale_width > scale_height:
scale_height = scale_width
else:
scale_width = scale_height
new_height = constrain_to_multiple_of(scale_height * height, min_val=dst_height)
new_width = constrain_to_multiple_of(scale_width * width, min_val=dst_width)
img = cv2.resize(img, (new_width, new_height), interpolation=2)
# 3. normalize
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = np.array(mean).reshape(1, 1, 3).astype("float32")
std = np.array(std).reshape(1, 1, 3).astype("float32")
img = (img - mean) / std
# 4. to bchw
img = img.transpose(2, 0, 1)[None]
img = torch.from_numpy(img)
return img3. Depth Anything后处理
我们再来看看后处理的实现
后处理的代码在 infer_image 方法中就有实现,如下所示:
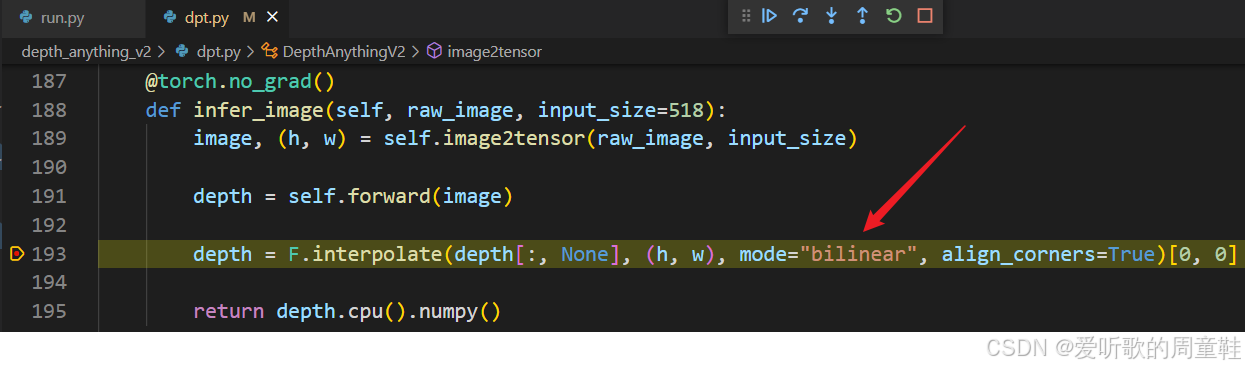
它包含以下步骤:
- F.interpolate:插值
后处理的实现非常简单,因为本来模型输出的就是一张深度图,我们只需要做双线性插值将它缩放回原图大小即可
因此我们不难写出对应的后处理代码,如下所示:
python
def postprocess(depth, origin_w, origin_h):
# depth->1x1x518x518
depth = F.interpolate(depth[:, None], (origin_h, origin_w), mode="bilinear", align_corners=True)[0, 0]
return depth.cpu().numpy()4. Depth Anything推理
通过上面对 Depth Anything 的预处理和后处理分析之后,整个推理过程就显而易见了。Depth Anything 的推理包括图像预处理、模型推理、预测结构后处理三部分,其中预处理主要包括 resize、normalize 等操作,后处理主要包括 interpolate 操作
完整的推理代码如下:
python
import cv2
import torch
import matplotlib
import numpy as np
import torch.nn.functional as F
from depth_anything_v2.dpt import DepthAnythingV2
def constrain_to_multiple_of(x, min_val=0, max_val=None, multiple_of=14):
y = (np.round(x / multiple_of) * multiple_of).astype(int)
if max_val is not None and y > max_val:
y = (np.floor(x / multiple_of) * multiple_of).astype(int)
if y < min_val:
y = (np.ceil(x / multiple_of) * multiple_of).astype(int)
return y
def preprocess(img, dst_width=518, dst_height=518):
# 0. BGR2RGB
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 1. /255.0
img = (img / 255.0).astype(np.float32)
# 2. resize (lower_bound mode)
height = img.shape[0]
width = img.shape[1]
scale_height = dst_height / height
scale_width = dst_width / width
if scale_width > scale_height:
scale_height = scale_width
else:
scale_width = scale_height
new_height = constrain_to_multiple_of(scale_height * height, min_val=dst_height)
new_width = constrain_to_multiple_of(scale_width * width, min_val=dst_width)
img = cv2.resize(img, (new_width, new_height), interpolation=2)
# 3. normalize
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
mean = np.array(mean).reshape(1, 1, 3).astype("float32")
std = np.array(std).reshape(1, 1, 3).astype("float32")
img = (img - mean) / std
# 4. to bchw
img = img.transpose(2, 0, 1)[None]
img = torch.from_numpy(img)
return img
def postprocess(depth, origin_w, origin_h):
# depth->1x1x518x518
depth = F.interpolate(depth[:, None], (origin_h, origin_w), mode="bilinear", align_corners=True)[0, 0]
return depth.cpu().numpy()
def visualization(depth):
cmap = matplotlib.colormaps.get_cmap('Spectral_r')
depth = (depth - depth.min()) / (depth.max() - depth.min()) * 255.0
depth = depth.astype(np.uint8)
depth = (cmap(depth)[:, :, :3] * 255)[:, :, ::-1].astype(np.uint8)
return depth
if __name__ == "__main__":
encoder = 'vitl'
chekpoint = f"checkpoints/depth_anything_v2_{encoder}.pth"
DEVICE = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
model_configs = {
'vits': {'encoder': 'vits', 'features': 64, 'out_channels': [48, 96, 192, 384]},
'vitb': {'encoder': 'vitb', 'features': 128, 'out_channels': [96, 192, 384, 768]},
'vitl': {'encoder': 'vitl', 'features': 256, 'out_channels': [256, 512, 1024, 1024]},
'vitg': {'encoder': 'vitg', 'features': 384, 'out_channels': [1536, 1536, 1536, 1536]}
}
depth_anything = DepthAnythingV2(**model_configs[encoder])
depth_anything.load_state_dict(torch.load(chekpoint, map_location='cpu'))
depth_anything = depth_anything.to(DEVICE).eval()
raw_image = cv2.imread("assets/examples/demo16.jpg")
origin_h = raw_image.shape[0]
origin_w = raw_image.shape[1]
# 1. preprocess
image = preprocess(raw_image)
image = image.to(DEVICE)
# 2. infer
with torch.no_grad():
depth = depth_anything.forward(image)
# 3. postprocess
depth = postprocess(depth, origin_w, origin_h)
# 4. visualization
depth_image = visualization(depth)
split_region = np.ones((raw_image.shape[0], 50, 3), dtype=np.uint8) * 255
combined_result = cv2.hconcat([raw_image, split_region, depth_image])
cv2.imwrite("result.jpg", combined_result)
print("save done.")推理效果如下图:

至此,我们在 Python 上面完成了 Depth Anything 的整个推理过程,下面我们去 C++ 上实现
二、Depth Anything推理(C++)
C++ 上的实现我们使用的 repo 依旧是 tensorRT_Pro,博主在部署过程中主要参考的是 depth-anything-tensorrt 这个 repo,现在我们就基于 tensorRT_Pro 完成 Depth Anything 在 C++ 上的推理
1. ONNX导出
ONNX 导出的细节请参考 Depth-Anything推理详解及部署实现(上),这边博主不再赘述
2. Depth Anything预处理
之前有提到 Depth Anything 的预处理就是 resize 操作,但并不是直接 resize 到 518x518 而是采用的 lower_bound mode,这意味着每次 resize 的尺寸不一致,需要考虑动态宽高,但博主并不太想让模型的宽高动态,这边先借鉴下 depth-anything-tensorrt 看这个 repo 的预处理是如何实现的
depth-anything-tensorrt 这个 repo 中预处理的代码非常清晰,主要在 utils.cpp 文件中,如下图所示:
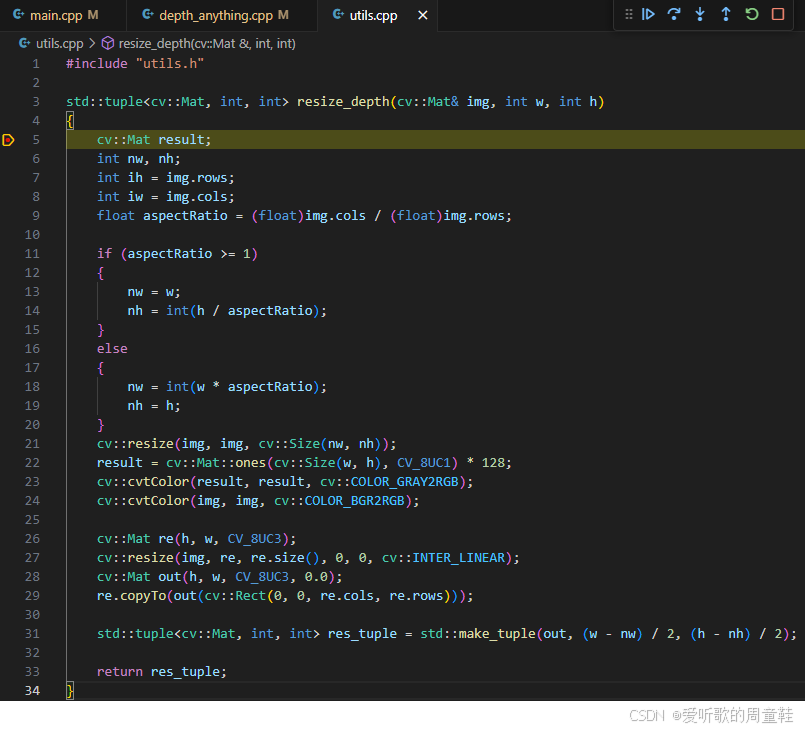
通过 resize_depth 即可完成 C++ 上 Depth Anything 的预处理操作,其中的 cv::Mat result 变量并没有使用到,而且总感觉逻辑有些奇怪
另外经过博主的分析貌似 resize_depth 函数做了两次 resize,第一次是保持宽高比 resize,第二次是直接 resize 到目标宽高(518x518),这个博主也没太看懂是什么意思
博主这边的预处理操作打算将原图直接 resize 到 518x518,值得注意的是在 tensorRT_Pro 中有提供现成的 CUDA 核函数来实现 resize,我们拿过来直接使用即可
预处理代码如下:
cpp
// same to opencv
// reference: https://github.com/opencv/opencv/blob/24fcb7f8131f707717a9f1871b17d95e7cf519ee/modules/imgproc/src/resize.cpp
// reference: https://github.com/openppl-public/ppl.cv/blob/04ef4ca48262601b99f1bb918dcd005311f331da/src/ppl/cv/cuda/resize.cu
/*
可以考虑用同样实现的resize函数进行训练,python代码在:tools/test_resize.py
*/
__global__ void resize_bilinear_and_normalize_kernel(
uint8_t* src, int src_line_size, int src_width, int src_height, float* dst, int dst_width, int dst_height,
float sx, float sy, Norm norm, int edge
){
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (position >= edge) return;
int dx = position % dst_width;
int dy = position / dst_width;
float src_x = (dx + 0.5f) * sx - 0.5f;
float src_y = (dy + 0.5f) * sy - 0.5f;
float c0, c1, c2;
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = limit(y_low + 1, 0, src_height - 1);
int x_high = limit(x_low + 1, 0, src_width - 1);
y_low = limit(y_low, 0, src_height - 1);
x_low = limit(x_low, 0, src_width - 1);
int ly = rint((src_y - y_low) * INTER_RESIZE_COEF_SCALE);
int lx = rint((src_x - x_low) * INTER_RESIZE_COEF_SCALE);
int hy = INTER_RESIZE_COEF_SCALE - ly;
int hx = INTER_RESIZE_COEF_SCALE - lx;
int w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
float* pdst = dst + dy * dst_width + dx * 3;
uint8_t* v1 = src + y_low * src_line_size + x_low * 3;
uint8_t* v2 = src + y_low * src_line_size + x_high * 3;
uint8_t* v3 = src + y_high * src_line_size + x_low * 3;
uint8_t* v4 = src + y_high * src_line_size + x_high * 3;
c0 = resize_cast(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0]);
c1 = resize_cast(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1]);
c2 = resize_cast(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2]);
if(norm.channel_type == ChannelType::Invert){
float t = c2;
c2 = c0; c0 = t;
}
if(norm.type == NormType::MeanStd){
c0 = (c0 * norm.alpha - norm.mean[0]) / norm.std[0];
c1 = (c1 * norm.alpha - norm.mean[1]) / norm.std[1];
c2 = (c2 * norm.alpha - norm.mean[2]) / norm.std[2];
}else if(norm.type == NormType::AlphaBeta){
c0 = c0 * norm.alpha + norm.beta;
c1 = c1 * norm.alpha + norm.beta;
c2 = c2 * norm.alpha + norm.beta;
}
int area = dst_width * dst_height;
float* pdst_c0 = dst + dy * dst_width + dx;
float* pdst_c1 = pdst_c0 + area;
float* pdst_c2 = pdst_c1 + area;
*pdst_c0 = c0;
*pdst_c1 = c1;
*pdst_c2 = c2;
}
void resize_bilinear_and_normalize(
uint8_t* src, int src_line_size, int src_width, int src_height, float* dst, int dst_width, int dst_height,
const Norm& norm,
cudaStream_t stream) {
int jobs = dst_width * dst_height;
auto grid = CUDATools::grid_dims(jobs);
auto block = CUDATools::block_dims(jobs);
checkCudaKernel(resize_bilinear_and_normalize_kernel << <grid, block, 0, stream >> > (
src, src_line_size,
src_width, src_height, dst,
dst_width, dst_height, src_width/(float)dst_width, src_height/(float)dst_height, norm, jobs
));
}其中 ChannelType 需要指定为 Invert 即执行 BGR2RGB 这个操作,NormType 需要指定为 MeanStd 即执行减均值除标准差这个操作
关于预处理部分其实就是调用了上述 CUDA 核函数来实现 resize,由于在 CUDA 中我们是对每个像素进行操作,因此非常容易实现 BGR2RGB,/255.0 等操作
3. Depth Anything后处理
之前我们有提到 Depth Anything 的后处理非常简单,对模型输出的深度图做一个插值即可
我们接着看下 depth-anything-tensorrt 这个 repo 中后处理是如何做的,具体的代码主要在 depth_anything.cpp 文件中,如下图所示:
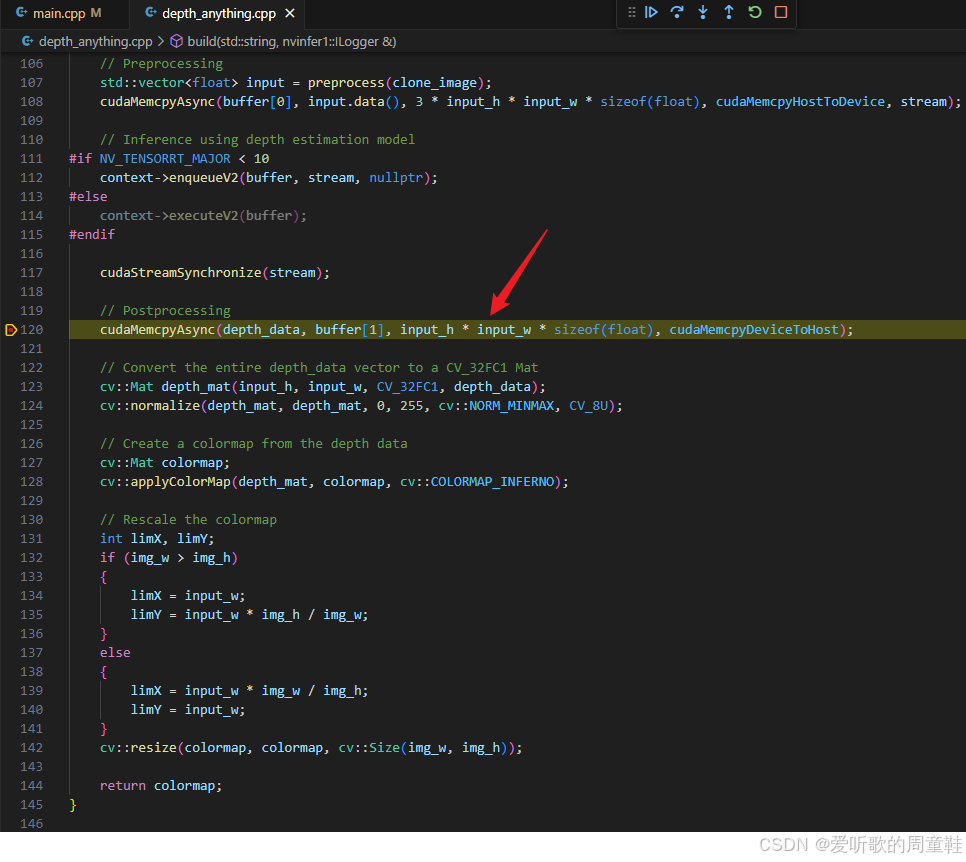
包括以下操作:(from ChatGPT)
- cudaMemcpyAsync :将模型推理结果从 GPU 拷贝回 CPU,存储在
depth_data变量中 - cv::Mat depth_map :将
depth_data转换为 opencv 的Mat对象,方便后续处理 - cv::normalize:将深度图数据归一化到 0~255 范围
- cv::applyColorMap:将深度数据转换为伪彩色图像,增加可视性
- cv::resize :将生成的彩色深度图像
colormap调整到原始输入图像尺寸
那实际任务中我们只需要知道每个像素的深度估计值就行,也就是得到 depth_map 然后 resize 缩放到原图尺寸就行,至于后续的只是为了方便可视化
因此我们不难写出后处理的代码:
cpp
if(interpolation_device_ == InterpolationDevice::CPU){
for(int ibatch = 0; ibatch < infer_batch_size; ++ibatch){
auto& job = fetch_jobs[ibatch];
auto& depth_image = job.output;
float* parry = output->cpu<float>(ibatch);
cv::Mat depth_mat(input_height_, input_width_, CV_32FC1, parry);
depth_image = depth_mat;
job.pro->set_value(depth_image);
}
fetch_jobs.clear();
}在上述代码中我们首先将模型的输出数据从 GPU 拷贝回 CPU,然后转换为 cv::Mat 的格式并返回,至于 resize 操作则是在外部实现的
当然我们也可以将模型输出的 518x518 的深度图直接通过 Kernel 核函数来做 resize,之后再拷贝回 CPU,在 tensorRT_Pro 中就有 resize 相关核函数的实现,我们简单修改下即可,如下所示:
cpp
#define INTER_RESIZE_COEF_BITS 11
#define INTER_RESIZE_COEF_SCALE (1 << INTER_RESIZE_COEF_BITS)
template<typename _T>
static __inline__ __device__ _T limit(_T value, _T low, _T high){
return value < low ? low : (value > high ? high : value);
}
__global__ void resize_bilinear_depth_kernel(
float* src, int src_width, int src_height,
float* dst, int dst_width, int dst_height,
float sx, float sy, int edge
){
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (position >= edge) return;
int dx = position % dst_width;
int dy = position / dst_width;
float src_x = (dx + 0.5f) * sx - 0.5f;
float src_y = (dy + 0.5f) * sy - 0.5f;
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = limit(y_low + 1, 0, src_height - 1);
int x_high = limit(x_low + 1, 0, src_width - 1);
y_low = limit(y_low, 0, src_height - 1);
x_low = limit(x_low, 0, src_width - 1);
int ly = rint((src_y - y_low) * INTER_RESIZE_COEF_SCALE);
int lx = rint((src_x - x_low) * INTER_RESIZE_COEF_SCALE);
int hy = INTER_RESIZE_COEF_SCALE - ly;
int hx = INTER_RESIZE_COEF_SCALE - lx;
int w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
float v1 = src[y_low * src_width + x_low];
float v2 = src[y_low * src_width + x_high];
float v3 = src[y_high * src_width + x_low];
float v4 = src[y_high * src_width + x_high];
float interpolated_value = (w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4) / INTER_RESIZE_COEF_SCALE;
dst[dy * dst_width + dx] = interpolated_value;
}那么这么做存在着一些问题,我们后面再做说明
4. Depth Anything推理
通过上面对 Depth Anything 的预处理和后处理分析之后,整个推理过程就显而易见了。C++ 上 Depth Anything 的预处理部分直接沿用 tensorRT_Pro 中的 resize 核函数,后处理部分将深度图缩放为原图尺寸即可
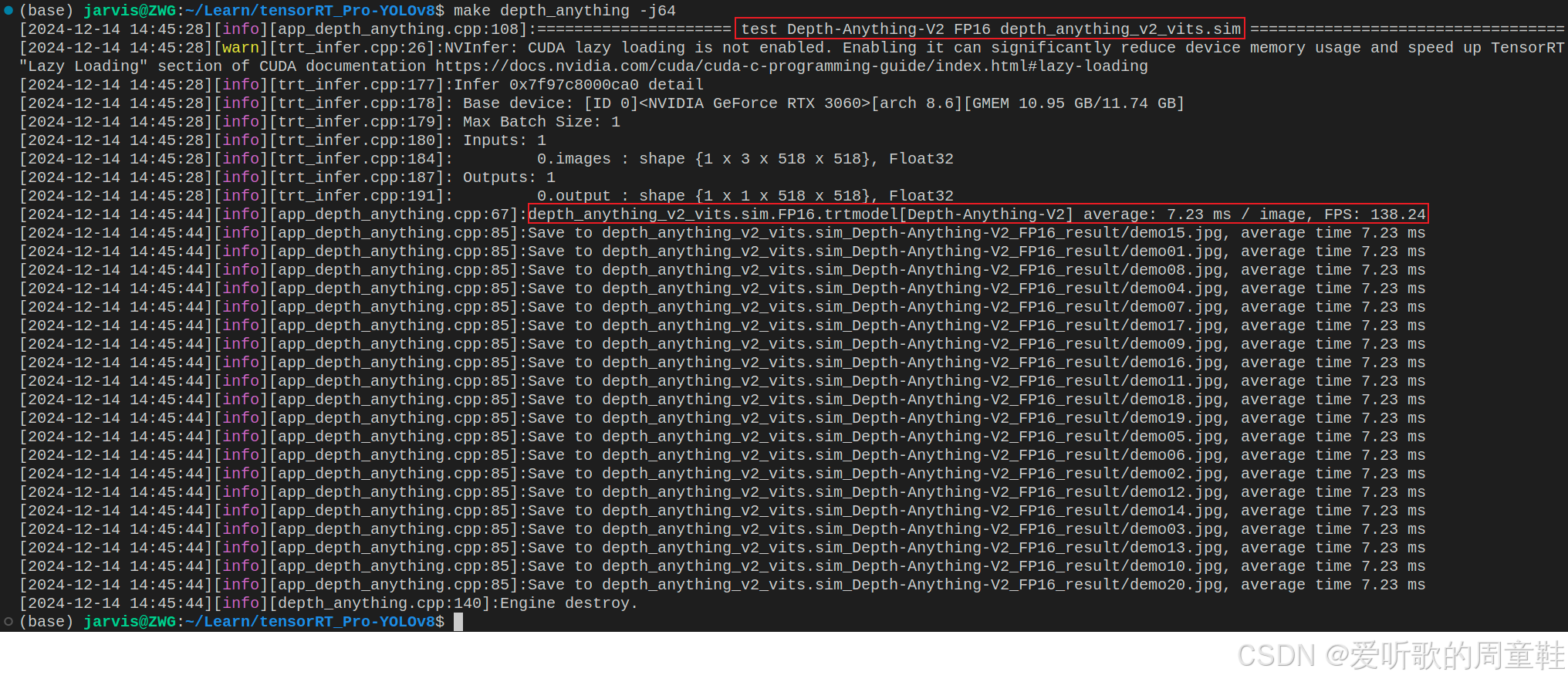
我们在终端执行如下指令即可完成推理(注意!完整流程博主会在后续内容介绍,这边只是简单演示):
shell
make depth_anything -j64编译图解如下所示:
推理结果如下图所示:



至此,我们在 C++ 上面完成了 Depth Anything 的整个推理过程,下面我们将完整的走一遍流程
三、Depth Anything部署
博主新建了一个仓库 tensorRT_Pro-YOLOv8,该仓库基于 shouxieai/tensorRT_Pro,并进行了调整以支持 YOLOv8 的各项任务,目前已支持分类、检测、分割、姿态点估计任务。
下面我们就来看看如何利用 tensorRT_Pro-YOLOv8 这个 repo 完成 Depth Anything 模型的推理。
1. 源码下载
tensorRT_Pro-YOLOv8 的代码可以直接从 GitHub 官网上下载,源码下载地址是 https://github.com/Melody-Zhou/tensorRT_Pro-YOLOv8,Linux 下代码克隆指令如下:
shell
git clone https://github.com/Melody-Zhou/tensorRT_Pro-YOLOv8.git也可手动点击下载,点击右上角的 Code 按键,将代码下载下来。至此整个项目就已经准备好了。也可以点击 here 下载博主准备好的源代码(注意代码下载于 2024-12-14 日,若有改动请参考最新)
2. 环境配置
需要使用的软件环境有 TensorRT、CUDA、cuDNN、OpenCV、Protobuf ,所有软件环境的安装可以参考 Ubuntu20.04软件安装大全,这里不再赘述,需要各位看官自行配置好相关环境😄,外网访问较慢,这里提供下博主安装过程中的软件安装包下载链接 Baidu Drive【pwd:yolo】🚀🚀🚀
tensorRT_Pro-YOLOv8 提供 CMakeLists.txt 和 Makefile 两种方式编译,二者选一即可
2.1 配置CMakeLists.txt
主要修改五处
1. 修改第 13 行,修改 OpenCV 路径
cpp
set(OpenCV_DIR "/usr/local/include/opencv4")2. 修改第 15 行,修改 CUDA 路径
cpp
set(CUDA_TOOLKIT_ROOT_DIR "/usr/local/cuda-11.6")3. 修改第 16 行,修改 cuDNN 路径
cpp
set(CUDNN_DIR "/usr/local/cudnn8.4.0.27-cuda11.6")4. 修改第 17 行,修改 tensorRT 路径(版本必须大于 8.6)
cpp
set(TENSORRT_DIR "/home/jarvis/lean/TensorRT-8.6.1.6")5. 修改第 20 行,修改 protobuf 路径
cpp
set(PROTOBUF_DIR "/home/jarvis/protobuf")2.2 配置Makefile
主要修改五处
1. 修改第 4 行,修改 protobuf 路径
cpp
lean_protobuf := /home/jarvis/protobuf2. 修改第 5 行,修改 tensorRT 路径(版本必须大于 8.6)
cpp
lean_tensor_rt := /home/jarvis/lean/TensorRT-8.6.1.63. 修改第 6 行,修改 cuDNN 路径
cpp
lean_cudnn := /usr/local/cudnn8.4.0.27-cuda11.64. 修改第 7 行,修改 OpenCV 路径
cpp
lean_opencv := /usr/local5. 修改第 8 行,修改 CUDA 路径
cpp
lean_cuda := /usr/local/cuda-11.63. ONNX导出
导出细节可以查看 Depth-Anything推理详解及部署实现(上),这边不再赘述。记得将导出的 ONNX 模型放在 tensorRT_Pro-YOLOv8/workspace 文件夹下。
4. engine生成
在 workspace 下新建 depth_anything_build.sh ,其内容如下:(静态 batch 模型)
shell
#! /usr/bin/bash
TRTEXEC=/home/jarvis/lean/TensorRT-8.6.1.6/bin/trtexec
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/jarvis/lean/TensorRT-8.6.1.6/lib
${TRTEXEC} \
--onnx=depth_anything_v2_vits.sim.onnx \
--memPoolSize=workspace:2048 \
--saveEngine=depth_anything_v2_vits.sim.FP16.trtmodel \
--fp16 \
> depth_anything_v2_vits.static.log 2>&1其中需要修改 TRTEXEC 的路径为你自己的路径,终端执行如下指令:
shell
cd tensorRT_Pro-YOLOv8/workspace
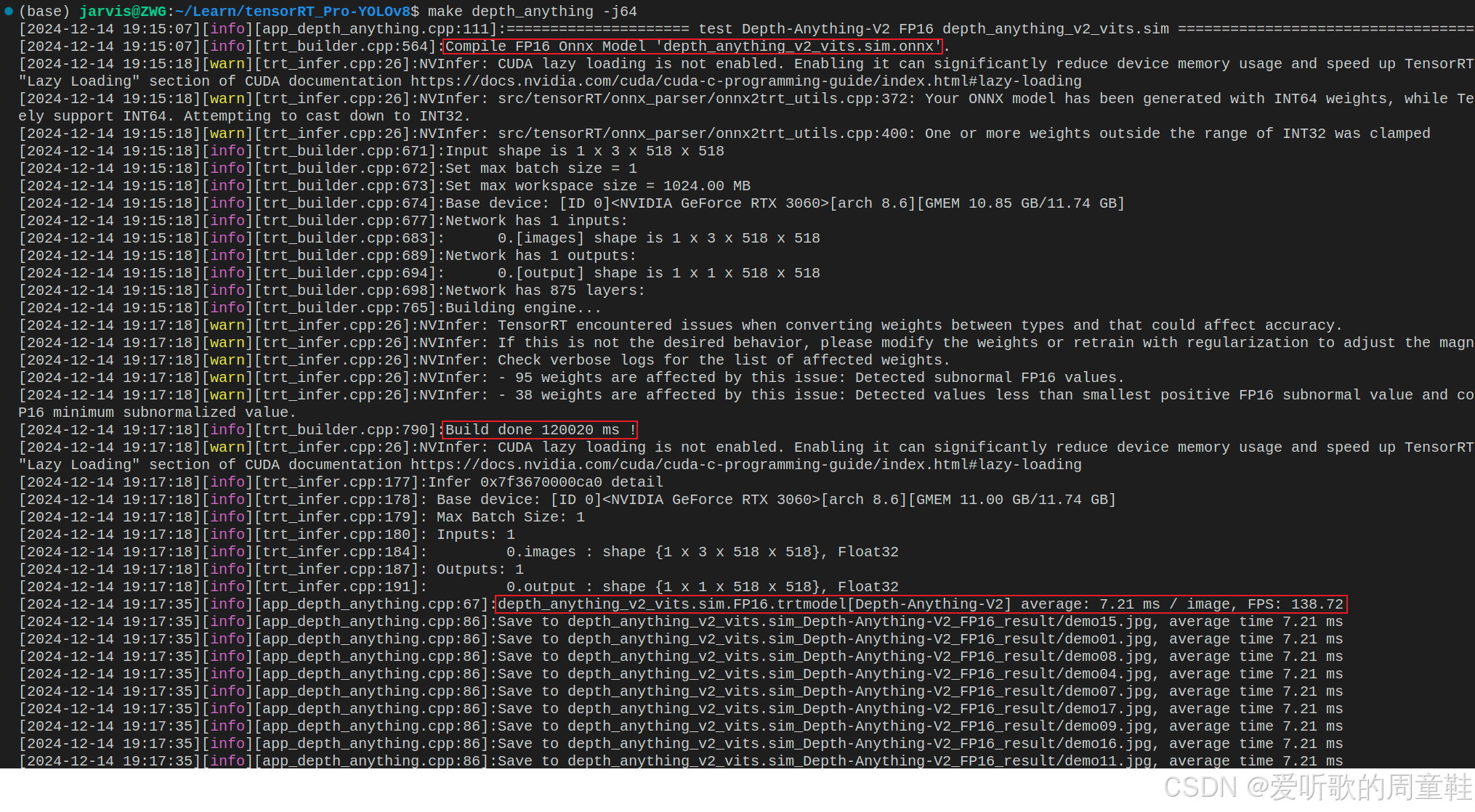
bash depth_anything_build.sh执行后等待一段时间会在当前文件夹生成 depth_anything_v2_vits.sim.FP16.trtmodel 即模型引擎文件,注意终端看不到任何日志打印输出,这是因为博主将 tensorRT 输出的日志信息保存到了 depth_anything_v2.static.log 文件中,大家也可以删除保存直接在终端显示相关日志信息
Note :杜老师在 tensorRT_Pro 中也提供了 TRT::compile 接口生成 engine 文件,不过在反序列化的时候可能会出现如下的问题:
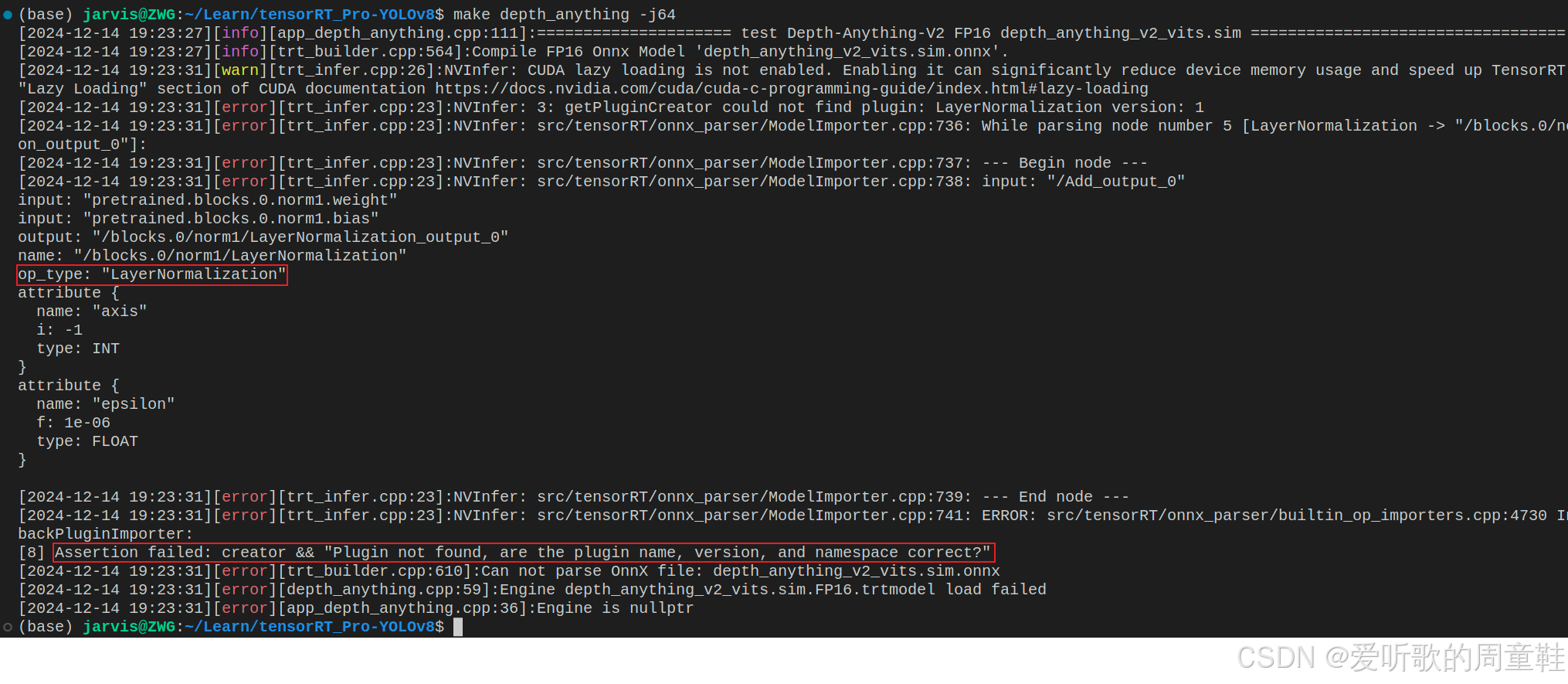
这个主要是因为 tensorRT_Pro-YOLOv8 自己构建的 onnxparser 版本太老,不支持 LayerNormalization 节点的解析,我们可以手动替换 onnxparser 解析器,具体可以参考:RT-DETR推理详解及部署实现
TRT::compile 接口编译模型过程如下图所示:
5. 源码修改
如果你想推理其它权重的模型还需要修改下源代码,Depth Anything 模型的推理代码主要在 app_depth_anything.cpp 文件夹,我们就只需要修改这一个文件的内容即可,源码修改较简单主要有以下几点:
- app_depth_anything.cpp 235 行,"depth_anything_v2_vits.sim" 修改为其它权重的 ONNX 模型名
具体修改示例如下:
cpp
// 修改1 235 行 "depth_anything_v2_vits.sim" 改成 "depth_anything_v2_vitl.sim"
test(DepthAnything::Type::V2, TRT::Mode::FP16, DepthAnything::InterpolationDevice::CPU, "depth_anything_v2_vitl.sim");6. 运行
OK!源码修改好了,Makefile 编译文件也搞定了,engine 模型也准备好了,现在可以编译运行了,直接在终端执行如下指令即可:
shell
make depth_anything -j64推理结果如下图所示:
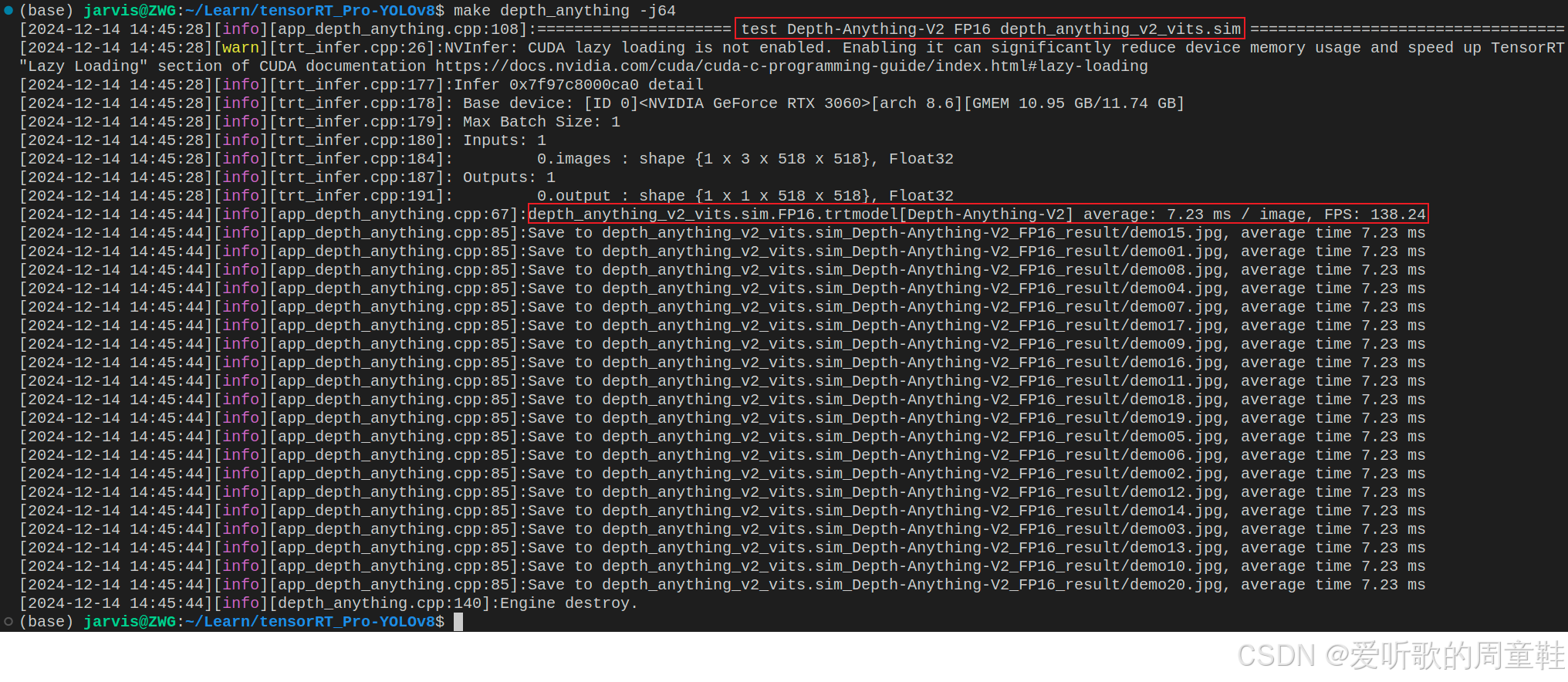
推理成功后会生成 depth_anything_v2_vits.sim_Depth-Anything-V2_FP16_result 文件夹,该文件夹下保存了推理的图片。
模型推理效果如下图所示:

OK,以上就是使用 tensorRT_Pro-YOLOv8 推理 Depth Anything 的大致流程,若有问题,欢迎各位看官批评指正。
7. 补充说明
博主在代码中提供了两种插值方式,分别是 CPU 和 FastGPU,CPU 默认采用 cv::Resize,GPU 默认采用 CUDA 核函数处理,经过博主测试有以下几点需要说明:
1. CPU 插值方式比 FastGPU 快,测试代码如下:
cpp
auto t0 = iLogger::timestamp_now_float();
auto depth_image = engine->commit(frame).get();
if(interpolation_device == DepthAnything::InterpolationDevice::CPU){
cv::resize(depth_image, depth_image, cv::Size(frame.cols, frame.rows));
}
auto fee = iLogger::timestamp_now_float() - t0;
INFO("fee = %.2f ms, FPS = %.2f", fee, 1 / fee * 1000);测试方式为读取同一张图片循环推理,然后统计 forward 加 resize 的时间(大概取了平均,不一定很准确,仅供参考 )博主在自己主机(RTX3060)上测试了三个不同分辨率大小的视频,测试结果如下:
| model | interpolation device | image | latency(ms) | fps |
|---|---|---|---|---|
| depth_anything_v2_vits.static.FP16 | CPU | davis_dolphins.jpg(960x540) | 6.75ms | 152.32 |
| depth_anything_v2_vits.static.FP16 | CPU | ferris_wheel.jpg(1920x1080) | 8.28ms | 120.78 |
| depth_anything_v2_vits.static.FP16 | CPU | basketball.jpg(2160x4096) | 13.65ms | 73.27 |
| depth_anything_v2_vits.static.FP16 | FastGPU | davis_dolphins.jpg(960x540) | 11.70ms | 85.45 |
| depth_anything_v2_vits.static.FP16 | FastGPU | ferris_wheel.jpg(1920x1080) | 12.72ms | 78.67 |
| depth_anything_v2_vits.static.FP16 | FastGPU | basketball.jpg(2160x4096) | 17.28ms | 57.86 |
从上表结果中可以看到三种分辨率下的图片在 CPU 和 FastGPU 两种插值方式对比下,直接通过 cv::resize 即 CPU 插值的耗时都是要少的
2. 动态 batch 模型在 FastGPU 插值方式下不同 max batch size 影响推理性能
| model | interpolation device | image | latency(ms) | fps |
|---|---|---|---|---|
| depth_anything_v2_vits.dynamic.FP16(max_batch=4) | FastGPU | davis_dolphins.jpg(960x540) | 28.04ms | 35.66 |
| depth_anything_v2_vits.dynamic.FP16(max_batch=4) | FastGPU | ferris_wheel.jpg(1920x1080) | 29.04ms | 34.44 |
| depth_anything_v2_vits.dynamic.FP16(max_batch=4) | FastGPU | basketball.jpg(2160x4096) | 33.60ms | 29.76 |
| depth_anything_v2_vits.dynamic.FP16(max_batch=8) | FastGPU | davis_dolphins.jpg(960x540) | 49.45ms | 20.22 |
| depth_anything_v2_vits.dynamic.FP16(max_batch=8) | FastGPU | ferris_wheel.jpg(1920x1080) | 51.80ms | 19.30 |
| depth_anything_v2_vits.dynamic.FP16(max_batch=8) | FastGPU | basketball.jpg(2160x4096) | 55.24ms | 18.10 |
| depth_anything_v2_vits.dynamic.FP16(max_batch=16) | FastGPU | davis_dolphins.jpg(960x540) | 93.32ms | 10.72 |
| depth_anything_v2_vits.dynamic.FP16(max_batch=16) | FastGPU | ferris_wheel.jpg(1920x1080) | 93.97ms | 10.64 |
| depth_anything_v2_vits.dynamic.FP16(max_batch=16) | FastGPU | basketball.jpg(2160x4096) | 98.05ms | 10.20 |
从上表结果中可以看到随着 max_batch 的增加同分辨率的图片耗时逐渐增加,按理来说是不会出现这个问题的,并且在 max_batch 等于 16 时,不同的分辨率图片的耗时差不多,这说明耗时肯定是其它的地方导致的
由于 FastGPU 插值方式要在提前 GPU 上申请一块内存,而输入图像的尺寸又多种多样,因此博主申请了一个足够大的空间,如下所示:
cpp
TRT::Tensor output_array_device(TRT::DataType::Float);
if(interpolation_device_ == InterpolationDevice::FastGPU){
output_array_device.resize(max_batch_size, max_input_width_ * max_input_height_).to_gpu();
}其中 max_input_width_ 和 max_input_height_ 博主设置的是 4K 图像的宽高即 4096x2160
当 batch size 逐渐增加时,申请的内存也会逐渐增加,这会影响模型的推理速度
Note:因此大家如果无特殊需求,推荐直接使用静态 batch 模型推理,另外插值方式需要考虑硬件性能和图像分辨率,在博主测试的 RTX3060 设备多种分辨率图像下 CPU 插值方式总体速度要快,但在 Jetson 板端博主并未测试
结语
博主在这里参考 depth-anything-tensorrt 对 Depth Anything 的预处理和后处理做了简单分析,同时与大家分享了 C++ 上的实现流程,目的是帮大家理清思路,更好的完成后续的部署工作😄。感谢各位看到最后,创作不易,读后有收获的看官请帮忙点个👍⭐️
最后大家如果觉得 tensorRT_Pro-YOLOv8 这个 repo 对你有帮助的话,不妨点个 ⭐️ 支持一波,这对博主来说非常重要,感谢各位🙏。