一、数据写入的核心流程
当向 ES 索引写入数据时,整体流程如下:
1、客户端发送写入请求
客户端向 ES 集群的任意节点(称为协调节点 ,Coordinating Node)发送一个写入请求,比如 index(插入或更新)或 delete(删除)请求。
2、协调节点处理请求
- 协调节点接收到请求后,确定数据应该存储在哪个索引和分片上。
- 通过路由计算 确定目标分片,默认的路由规则是通过文档的
_id取哈希值,再对分片数取模来定位分片。
bash
shard = hash(_id) % number_of_primary_shards3、请求转发给主分片
协调节点将请求转发给对应的 主分片(Primary Shard)所在的节点,主分片负责执行写入操作。
4、主分片写入阶段
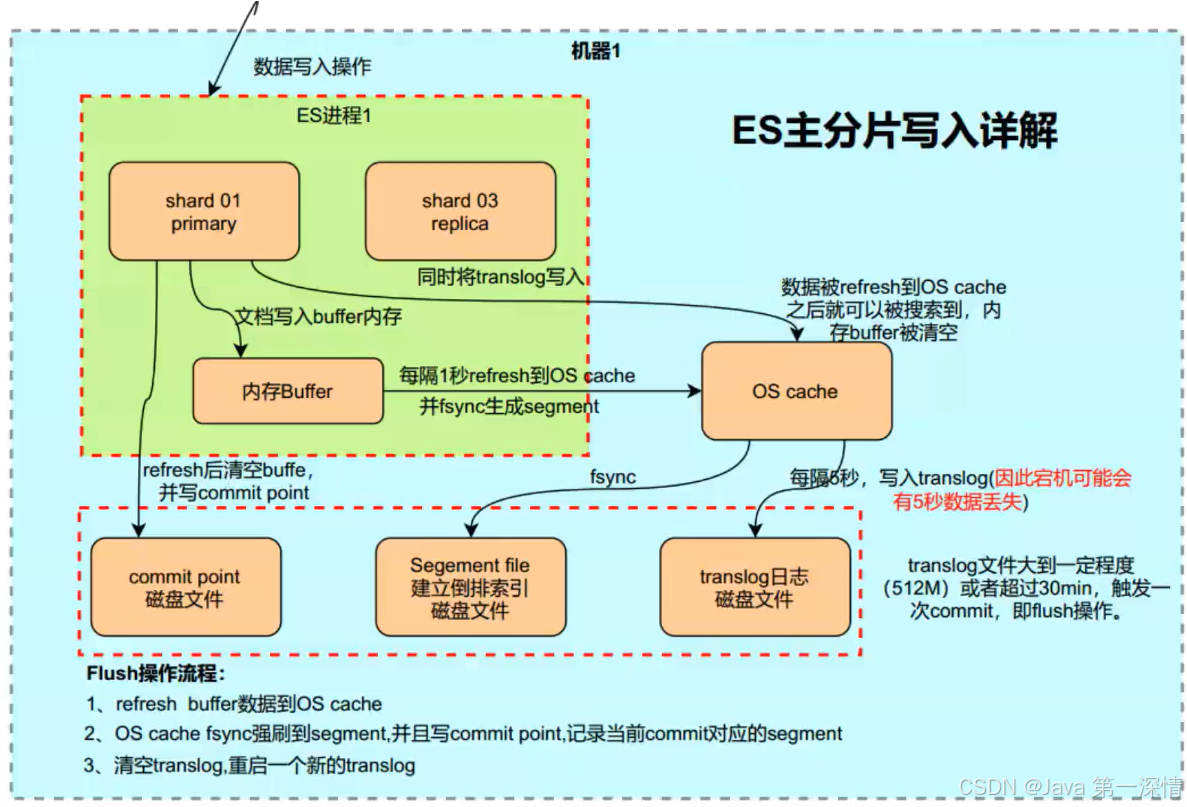
主分片接收到写入请求后,执行以下操作:
- 写入内存缓冲区(Buffer) :首先将数据写入到内存中的写入缓冲区,这是一块内存区域,用于快速接收新数据。
- 写入事务日志(Translog) :同时,将数据写入事务日志(Translog)。Translog 是一个顺序写入的日志文件,用于在节点宕机时进行数据恢复,确保数据不会丢失。
5、数据刷新到段(Segment)
- 定期刷新(Flush):每隔一定时间(默认是 1 秒)或当缓冲区达到一定大小时,ES 会将内存缓冲区中的数据刷新到段(Segment)中。段是倒排索引的基本存储单元。
- 生成新的段文件:数据被写入段后,段文件会被写入磁盘,段文件一旦生成便是不可更改的(只读的)。
- 清空缓冲区 :刷新后,内存缓冲区被清空,但 Translog 依然保留,直到执行
flush操作。
6、同步到副本分片
- 主分片写入成功后,将请求转发给对应的 副本分片(Replica Shard) 所在的节点。
- 副本分片执行与主分片相同的写入操作,确保主副本数据一致。
- 当所有副本分片写入成功后,主分片向协调节点返回写入成功的确认。
7、返回写入结果给客户端
协调节点收到主分片和副本分片的成功确认后,向客户端返回写入成功的响应。
二、核心组件介绍
1、内存缓冲区(Buffer)
- 作用:用于临时存储写入的数据,提高写入性能。
- 刷新机制:每隔一段时间(默认 1 秒)或当缓冲区满时,数据会被刷新到段(Segment)。
2、事务日志(Translog)
- 作用:用于记录所有未持久化到段的数据,防止数据丢失。
- 持久化:写入操作在返回成功之前,必须确保数据被写入 Translog。
- Flush 操作:定期将数据从缓冲区刷新到段,并清空 Translog,生成新的空的 Translog。
3、段(Segment)
下一节将详细讲
4、主分片与副本分片
- 主分片(Primary Shard):负责处理写入和查询请求。
- 副本分片(Replica Shard):主分片的冗余副本,用于提高数据可用性和查询性能。
- 一致性:写入时,主分片和副本分片保持数据一致,确保容错能力。
三、段的深度剖析
什么是段
段(Segment) 是倒排索引的基本存储单元。每当数据被写入或更新时,ES 并不会立即将其合并到现有的数据结构中,而是将数据写入新的段。段存储在磁盘上,并以不可变的形式存在。这种设计有助于提升写入和查询的性能,同时简化了数据管理。
段 是一种包含索引数据的小型文件集合,每个段都包含:
- 倒排索引(Inverted Index):用于快速搜索文档的内容。
- 文档元数据(如 _id、分数等)。
- 存储字段(Stored Fields):用于存储完整的文档内容或字段值。
- 删除标记(Deletion Markers):标记哪些文档被逻辑删除。
什么时候生成段?
当 ES 将数据从内存缓冲区刷新(Refresh)到磁盘时,就会创建新的段。这些段会持续累积,直到 ES 触发合并(Merge)操作,将多个小段合并成更大的段。
为什么使用段
-
高效写入
- ES 将数据先写入内存缓冲区,然后批量刷新到新的段,而不是直接修改现有的段。
- 这种批量写入减少了频繁的磁盘操作,提高了写入性能。
-
并发查询与写入
- 由于段是只读的,多个查询可以并发访问这些段,而不会影响写入操作。
- 新数据写入时,不会影响正在查询的旧段,保证了数据的可用性。
-
快速删除与更新
- ES 的删除和更新操作不直接修改段内的数据,而是通过逻辑标记(标记文档为删除)来实现。
- 这种方式避免了频繁的磁盘重写操作,提高了性能。
-
增量合并
- ES 通过定期将多个小段合并成大段,减少段的数量,优化查询性能。
- 合并过程是在后台异步进行的,不影响前台查询和写入。
为什么段是不可变的
-
简化并发控制
- 因为段是不可变的,多个查询可以安全地并发读取相同的段,而无需担心数据被修改或锁定。
- 不需要复杂的并发控制机制,简化了系统设计。
-
提高查询性能
- 由于段不变,ES 可以预先构建和优化倒排索引,确保查询时能够快速检索数据。
- 不可变的段使得查询操作可以直接访问磁盘数据,无需等待写入操作完成。
-
高效的删除和更新
- 删除和更新不会直接修改段内的数据,而是通过生成新的段和标记旧段来完成。
- 这种方式避免了频繁的随机写入,提高了磁盘写入性能。
-
崩溃恢复与数据安全
- 不可变的段一旦写入磁盘,就不会被更改。这意味着即使 ES 崩溃,已写入的段不会丢失或损坏。
- 恢复时,只需要重新应用事务日志(Translog)中尚未刷新的数据。
四、为什么说ES的检索是近实时的
如果ES像MySQL一样,等到数据真正落盘完毕,才返回写入成功,这叫直接写入方式,这能达到实时搜索。但是这会有什么样的问题呢?
直接写入存在的问题
提交一个新的段到磁盘需要 fsync操作,确保段被物理地写入磁盘,即时电源失效也不会丢失数据。
但是 fsync 是昂贵的,严重影响性能,当写数据量大的时候会造成ES 停顿卡死,查询也无法做到快速响应新文档在几分钟之内即可被检索,并且这样还是不够快,磁盘在这里成为了瓶颈。
延时写策略
所以 fsync不能在每个文档被索引的时就触发,需要一种更轻量级的方式使新的文档可以被搜索,所以为了提升写的性能,ES没有每新增一条数据就增加一个段到磁盘上而是采用延时写的策略。
具体做法如下:
每当有新增的数据时,就将其先写入到内存中
在内存和磁盘之间是文件系统缓存,当达到默认的时间(1秒钟)或者内存的数据达到一定量时,会触发一次刷新(Refresh),将内存中的数据生成到一个新的段上并缓存到文件缓存系统上,稍后再被刷新到磁盘中并生成提交点。