这里写目录标题

为何需要因果分析
在本例中,我们将快速进行一次因果分析,以估计戒烟对十年内体重增加的因果效应。
我们将这些结果与观察到的效果进行比较,后者来源于简单的描述性统计。
然后我们会深入探讨数据,看看为什么会存在这样的差异。
数据
我们将使用来自NHEFS观察性研究的数据。NHANS(全国健康与营养调查)流行病学随访研究(NHEFS)是一项由美国国家健康统计中心和美国国家老龄化研究所共同发起的全国性的纵向研究。这项研究旨在跟踪吸烟者,其中一些人戒烟,并记录他们在11年期间的体重(以及其他测量指标):从1971年到1982年。
关于数据的更多信息可以在NHEFS笔记本(NHEFS Notebook)中找到。
python
from causallib.datasets import load_nhefs
data = load_nhefs()
data.X.join(data.a).join(data.y).head()
数据已经被分为三个部分:
X: 需要控制的混杂因素:- 人口统计数据:如
age,race,sex和education水平(多少年学校教育) - 吸烟习惯:一个人吸烟了多少年(
smokeyrs)以及每天吸多少支香烟(smokeintensity) - 健康习惯:参与者每天有多活跃(
active)以及他们做多少运动休闲(exercise) - 研究开始时的体重(
wt71)
- 人口统计数据:如
a: 治疗分配 - 是否戒烟y: 结果 - 在十年追踪期内个体增加了多少体重
估计因果效应
因果模型
为了演示,我们将遵循最简单且众所周知的因果模型:逆概率治疗加权(也称为IPTW或IPW)。
该模型要求根据每个参与者的个人特征来估计其戒烟的可能性。
python
from causallib.estimation import IPW
from sklearn.linear_model import LogisticRegression
learner = LogisticRegression(penalty='none', # No regularization, new in scikit-learn 0.21.*
solver='lbfgs',
max_iter=500) # Increased to achieve convergence with 'lbfgs' solver
ipw = IPW(learner)应用因果分析
一旦定义了因果模型,我们就可以计算潜在结果和影响了。
python
ipw.fit(data.X, data.a)
potential_outcomes = ipw.estimate_population_outcome(data.X, data.a, data.y)
causal_effect = potential_outcomes[1] - potential_outcomes[0]
causal_effect
3.5175400213088306我们的因果分析得出结论,在十年的时间里,戒烟平均使人们的体重增加了3.5公斤(7.7磅)。
换句话说,如果所有参与者都戒烟了,他们的体重会比继续吸烟多3.5公斤。
估计观测效果
假设你被要求估算戒烟对体重增加的影响,但你不熟悉因果分析。
乍一看,这可能听起来很简单。你只需测量持续吸烟的人的体重增加量,测量戒烟的人的体重增加量,并将两者进行比较,看戒烟的人比坚持吸烟的人增加了多少(或减少了多少)。
python
observed_outcomes = data.y.groupby(data.a).mean()
observed_effect = observed_outcomes[1] - observed_outcomes[0]
observed_effect
2.540581454955888如果你避免因果分析,你会估计戒烟只会导致体重增加2.5公斤(5.5磅),而我们上面计算的是3.5公斤。这是一个接近30%的低估!
这种描述性统计计算和基于因果的估计之间的差异可能是由什么引起的?
描述性统计和因果估计之间的差异分析
我们看到,由于戒烟造成的观察到的差异是2.5公斤,而因果推断分析表明它更接近3.5公斤。
因果分析本质上试图在计算差异之前平衡治疗组和对照组之间。
体重增加可以由许多因素引起。例如,男性平均比女性大,而且平均增重更多。如果大多数戒烟的人都不是男性呢?那就会降低观测效果。**我们的观测分析没有考虑到治疗组之间此类特征的不同分布,因此观测效果受到混淆,并且很可能"污染"了虚假的相关性。**只有当控制了这些相关性并消除了它们的影响时,我们才能声称体重增加的差异真正只归因于吸烟状态。
观测差异仅表示选择戒烟的人比选择不戒烟的人多增重2.5公斤。
为了了解治疗组和对照组之间的分布差异,我们可以计算每个性质上各组均值的差异。我们在一个名为Love plot(以Thomas Love博士命名)的图表中可视化这些差异。
python
from causallib.evaluation import evaluate
import matplotlib.pyplot as plt
evaluations = evaluate(ipw, data.X, data.a, data.y, metrics_to_evaluate={})
fig, ax = plt.subplots(figsize=(6, 6))
evaluations.plot_covariate_balance(kind="love", ax=ax);
橙色三角形显示了应用平衡前每个协变量的平均值差异。
我们发现年龄在治疗组之间差异最大,并怀疑它可能导致描述性统计和因果分析的结果差异。
为了进一步调查这一点,让我们来看看年龄与体重增加的关系:
python
%matplotlib inline
import seaborn as sns
ax = sns.scatterplot(data.X["age"], data.y, hue=data.a, alpha=0.7)
ax.get_figure().set_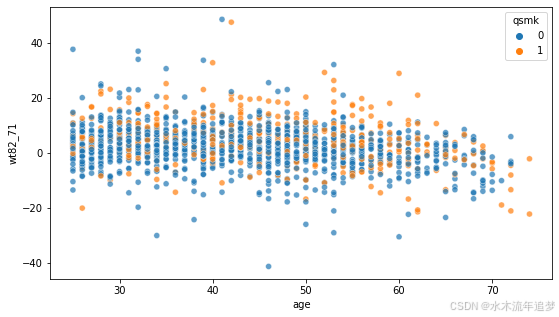
size_inches(9, 5);
我们观察到对于较老的人来说,体重增加减少了,以至于在非常高的年龄下负数比正数更频繁出现。
让我们按每五年一组的年龄段分解观测到的差异:
python
import pandas as pd
step_size = 5
age_groups = range(data.X["age"].min(),
data.X["age"].max() + step_size,
step_size)
print(list(age_groups))
age_grouped = pd.cut(data.X["age"], bins=age_groups, include_lowest=True)
age_grouped.head()
[25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75]
0 (40.0, 45.0]
1 (35.0, 40.0]
2 (55.0, 60.0]
3 (65.0, 70.0]
4 (35.0, 40.0]
Name: age, dtype: category
Categories (10, interval[float64, right]): [(24.999, 30.0] < (30.0, 35.0] < (35.0, 40.0] < (40.0, 45.0] ... (55.0, 60.0] < (60.0, 65.0] < (65.0, 70.0] < (70.0, 75.0]]现在我们检查每个年龄段的体重增加有何不同:
python
observed_diff_by_age = data.y.groupby([data.a, age_grouped]).mean()
observed_diff_by_age = observed_diff_by_age.xs(1) - observed_diff_by_age.xs(0)
observed_diff_by_age = observed_diff_by_age.rename("observed_effect")
ax = observed_diff_by_age.plot(kind="barh")
ax.set_xlabel("observed_effect");
python
age_frequency = age_grouped.value_counts(sort=False)
age_frequency.rename("counts", inplace=True)
ax = age_frequency.plot(kind="barh")
ax.set_xlabel("counts");
python
by_age = observed_diff_by_age.to_frame().join(age_frequency)
by_age
事实上,对于最大的群体,即40至55岁的群体,观测效果大于整体平均观测效果(2.5公斤)。
这有点类似于辛普森悖论:为什么合并效果大的群体会导致小效果?
为了验证这一点,我们将深入研究这些年龄组中治疗组与对照组的分布:
python
tx_distribution_by_age = data.a.groupby(age_grouped).value_counts()
tx_distribution_by_age = tx_distribution_by_age.unstack("qsmk")
tx_distribution_by_age["propensity"] = tx_distribution_by_age[1] / tx_distribution_by_age.sum(axis="columns")
by_age = by_age.join(tx_distribution_by_age)
by_age
我们看到每个年龄组的治疗组和对照组的比例不同,也就是说,每个治疗组的个体有不同的戒烟倾向。
我们可以继续将每个年龄组的观测效果作为功能可视化(蓝色点),并与整体平均值(绿色线)和因果分析得到的效果(橙色线)进行比较:
python
ax = sns.scatterplot(x="propensity", y="observed_effect", data=by_age.reset_index(),
size="counts", size_norm=(20, 200))
ax.axhline(y=causal_effect, linestyle="--", color="C1", label="causal effect", zorder=0)
ax.axhline(y=observed_effect, linestyle=":", color="C2", label="observed effect", zorder=0)
ax.legend();
可以看出,那些戒烟者比例较小(戒烟倾向较小)的群体(图左上角)效果较大。效果较小的群体对观测效果的贡献不成比例。因此,总体观测效果小于如果所有群体的比例相同的情况下所观测到的效果。实际上,它更接近于因果分析预测的3.5值。
更一般地讲,效果大小和治疗流行率在年龄组之间变化,因此年龄是效果的一个混杂因素。因此,只能通过使用每个年龄组的大小加权观测组差来计算总体人群效果。
所以如果我们平均观测效果并考虑每个年龄组的大小,我们会得到:
python
import numpy as np
np.average(by_age["observed_effect"], weights=by_age["counts"])
3.1002018883702944手动构建基于年龄的IPW模型
python
# Give each individual their propensity according their age group:
individual_age_weights = age_grouped.map(by_age["propensity"])
# Give each individual the pobability to be in their original treatment group,
# i.e. the treated get their propensity (=probability to be treated)
# and the control get 1 minus that propensity (=probability to by untreated)
individual_age_weights = (data.a * individual_age_weights) + ((1-data.a) * (1-individual_age_weights))
# We then inverse these propensity:
individual_age_weights = 1 / individual_age_weights
# We use the inversed propensities to create a weighted outcome:
weighted_outcome = individual_age_weights * data.y
# Finaly, we take the weighted average of the weighted outcome in each treatment group:
weighted_outcome = weighted_outcome.groupby(data.a).sum() / individual_age_weights.groupby(data.a).sum()
# And we can
weighted_outcome[1] - weighted_outcome[0]确实,我们得到了与上述加权平均值相同的效果。
然而,请记住我们只有10个独特的倾向值,因为我们任意地将年龄变量分成了10个年龄组。
同时,使用机器学习模型允许我们使用连续年龄建模倾向。
让我们通过建立一个使用年龄作为唯一特征建模倾向的IPW模型来检查使用连续年龄会发生什么。
python
learner = LogisticRegression(penalty='none', solver='lbfgs', max_iter=500)
ipw = IPW(learner)
ipw.fit(data.X[["age"]], data.a)
outcomes = ipw.estimate_population_outcome(data.X[["age"]], data.a, data.y)
outcomes[1] - outcomes[0]
3.098787136071221确实,当我们在IPW模型中仅校正年龄时,我们得到了几乎相同的效果。
我们可以假设,在纠正更多变量并在此过程中消除更多的偶然相关性时,我们将得到3.5公斤的因果效应。
总结
我们发现使用简单描述性统计得出的"效果"与因果分析得出的因果效应之间存在差异。
这种差异源于各组(戒烟或不戒烟)具有不同的特征分布,因此不可比。
我们发现参与者的年龄在治疗组中具有最大的分布变化,并且专注于它。
我们发现不同年龄组的观察效果不同,并且不同年龄组的人数不同,这表明简单的平均数混杂了不同的效果。
我们展示了当考虑到每个年龄组的参与者数量时,"效果"从原始观察效果向因果效果转变。
我们发现当我们构建一个仅对年龄进行控制(而不是对所有混杂因素)的因果模型时,我们得到了类似的结果。