上篇文章带大家实践了 Fluss 部署实践,感兴趣的小伙伴可以去看一下这一篇文章
今天给大家继续带来 Fluss 数据入湖的部分,让大家可以快速上手 Fluss 这个服务组件。
Fluss 入湖环境准备
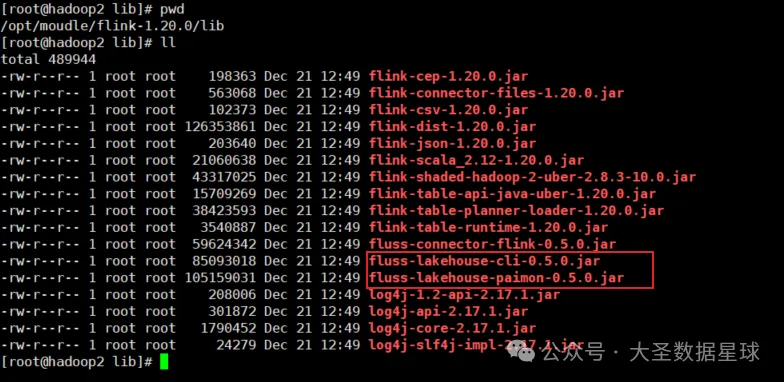
继续上一篇文章的机器环境来说,首先需要把 fluss 的 opt 目录下的两个 jar 给复制到 flink 的 lib 目录下,如下图:

然后到 flink 的lib 目录下就可以看到下面的两个 jar,然后重启 Flink 集群 如下图:
接着修改 Fluss conf 目录下的 server.yaml 配置文件,如下图:
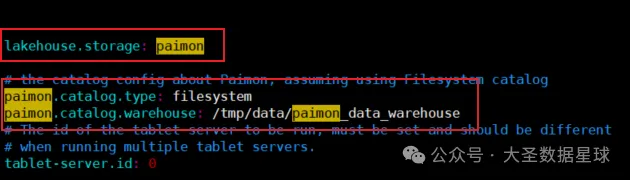
这里 paimon.catalog.warehouse 这个参数需要注意,如果你的 Flink 使用的是集群或者 Flink 服务和 Fluss 服务不再同一台机器上面,这个参数需要配置成分布式的存储路径,比如 HDFS。
我这里填写的是本地路径,是因为我的 Flink 集群虽然是 Standalone 模式的,但是我的 StandaloneSessionClusterEntrypoint 和 TaskManagerRunner 都在同一台机器,并且Fluss 服务也在这一台机器上面,可以这样写。
要不然你在使用 Fluss 往 数据湖里面写数据的时候会报找不到表的错误,如下图: 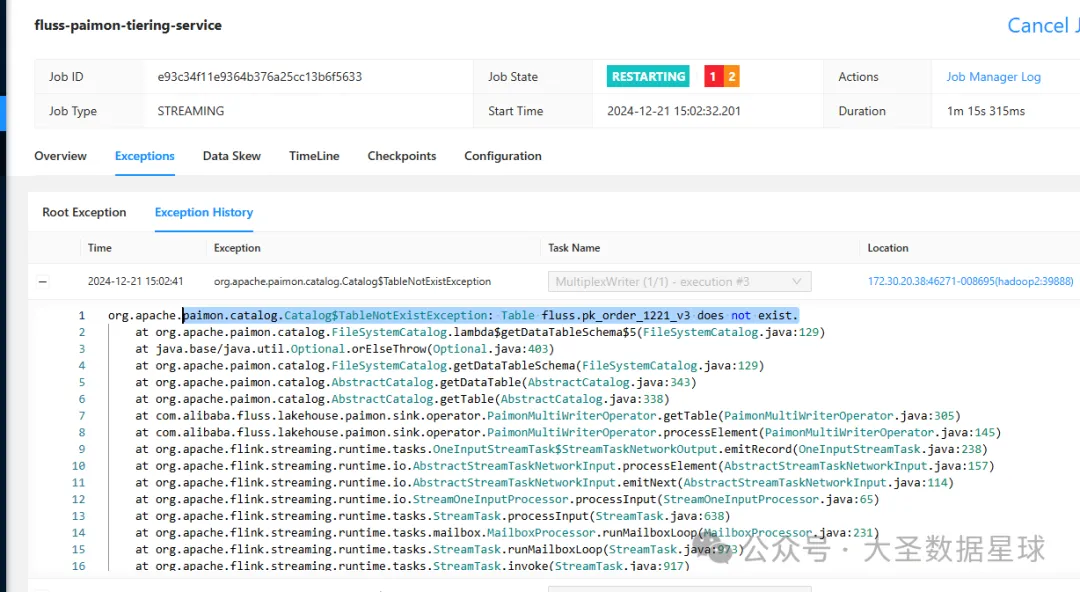
Fluss 数据写入数据湖的操作目前只支持 Paimon,Fluss 入湖操作是自己维护 Compaction Service 了一个,这个 Compaction Service 其实就是一个 常驻的 Flink 进程,目前这个 Compaction Service 服务是需要我们手动开启的,开启的过程如下,首先确保 Flink 集群和 Fluss 服务是正常的,如下图:
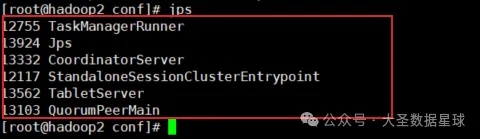
开启 Compaction Service 服务,执行 ./bin/lakehouse.sh -D flink.rest.address=hadoop2 -D flink.rest.port=8081 这个命令,如下图:
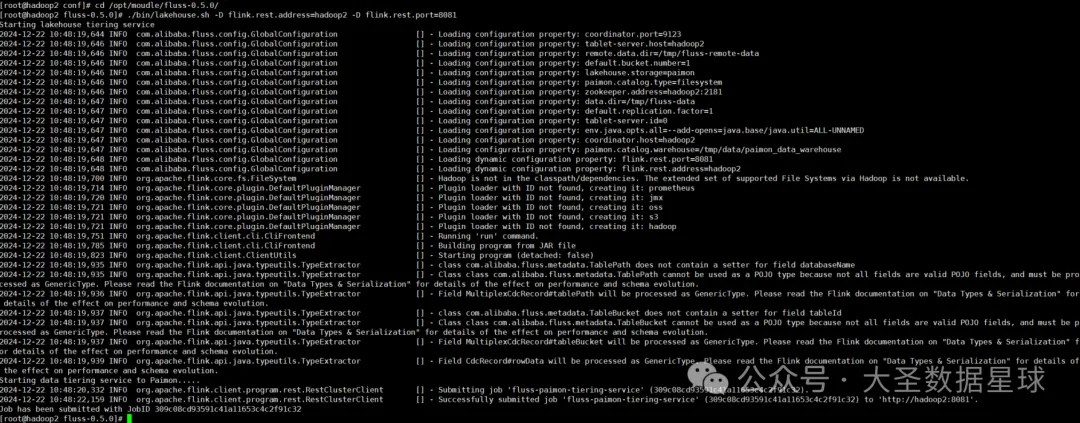
其实你可以看到,这个 Compaction Service 服务就是往你的 Flink 集群上面提交一个 Fluss 自己封装好的一个 Flink 任务,最后我们在 Flink 的 UI 界面上也可以看到这个任务,如下图:
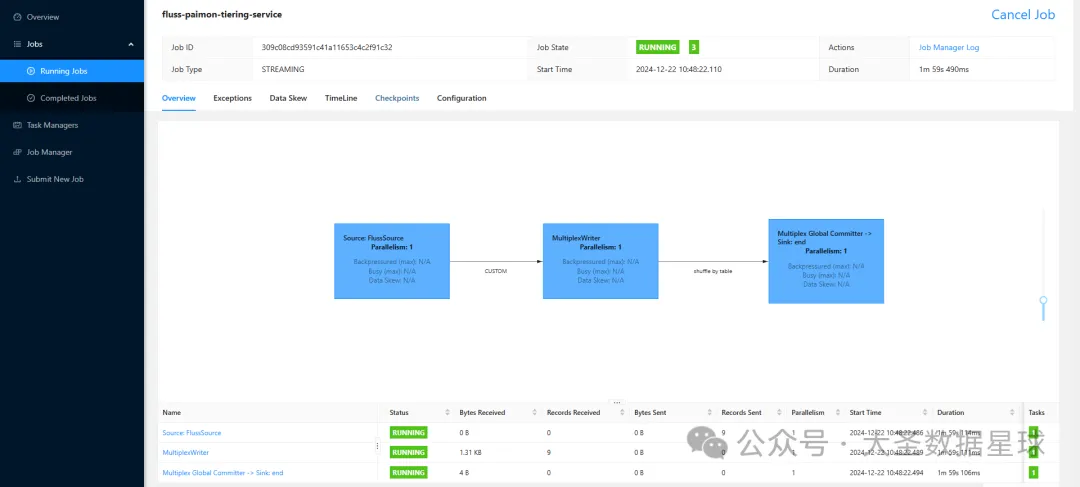
至此 Fluss 入湖操作的前置准备就做完了,总结一下有以下几个步骤:
-
复制 jar 到 flink lib 目录下
-
修改 Fluss 的 server.yaml 配置文件
-
启动 Compaction Service 服务
Fluss 数据写入数据湖实操
创建 CATALOG:
sql
CREATE CATALOG fluss_catalog WITH (
'type'='fluss',
'bootstrap.servers' = 'hadoop2:9123'
);
USE CATALOG `fluss_catalog`;如下图:
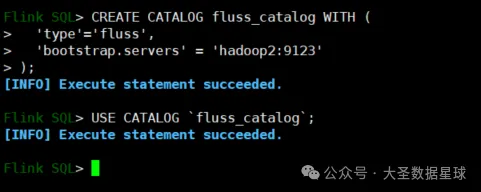
创建数据表:
sql
CREATE TABLE pk_order_1222_v1 (
shop_id BIGINT,
user_id BIGINT,
num_orders INT,
total_amount INT,
PRIMARY KEY (shop_id, user_id) NOT ENFORCED
) WITH (
'bucket.num' = '2',
'table.datalake.enabled' = 'true'
);这里是 'table.datalake.enabled' 用这个参数来控制这张表是不是数据湖表,如果是 true 则说明这张表是数据湖表,在你往这张表里面插入数据的时候会同时把数据写入到数据湖里面,写到哪个数据湖里面,就是上面在 server.yaml 里面配置的,这个参数默认是 false
如下图:
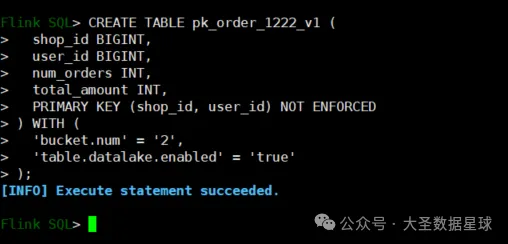
往数据表里面插入数据:
sql
INSERT INTO pk_order_1222_v1 VALUES
(1234, 1234, 1, 1),
(12345, 12345, 2, 2),
(123456, 123456, 3, 3);如下图:
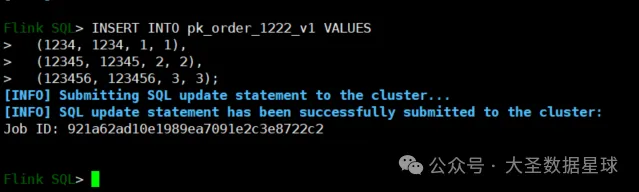
我们这边执行 Insert 语句的时候,之前启动的 Compaction Service 服务的 Flink 任务就会读取到我们插入的这三条数据,然后帮我们写入到数据湖里面,如下图:
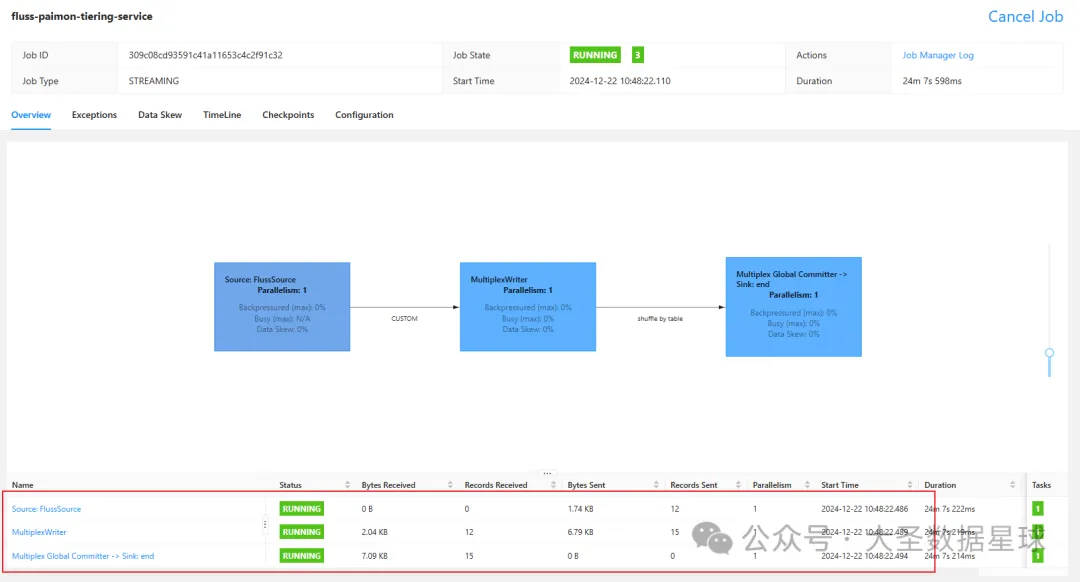
这里的 Records Sent 不是三条,是因为我之前就启动过这个服务了,并且我一直都是在 fluss_catalog 这个 CATALOG 里面操作的,它这个 fluss-paimon-tiering-service 任务会从之前的 Checkpoint 启动,把之前的数据重放一遍(我猜测是这样的)。
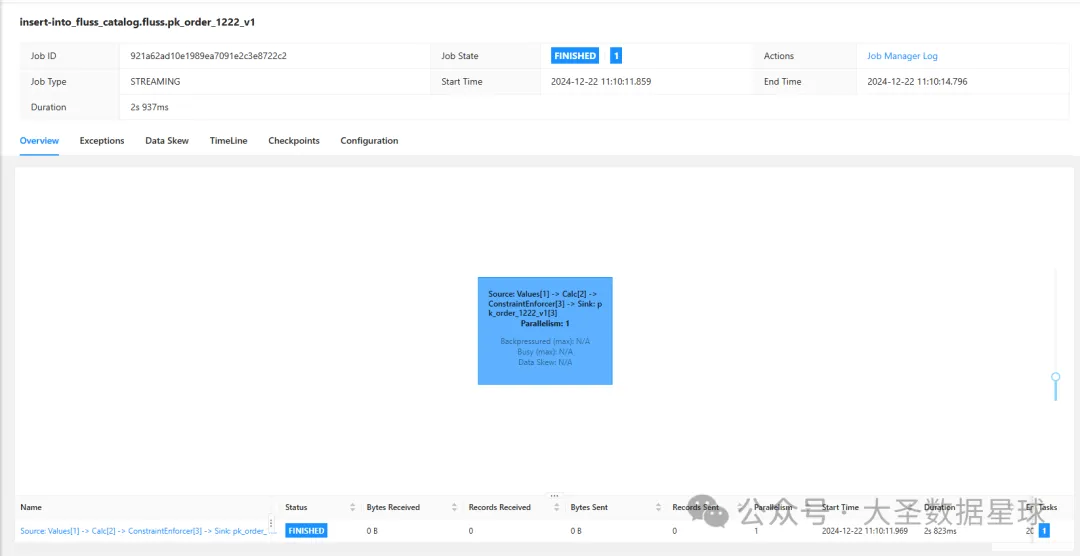
同时发现我们的 Flink 集群里面还会启动一个 Flink 批作业的任务,把我们刚才插入的三条数据写到 Fluss 存储组件里面,如下图:
接着去我们server.yaml 配置文件里面配置的数据湖地址去看,数据也生成了,如下图:
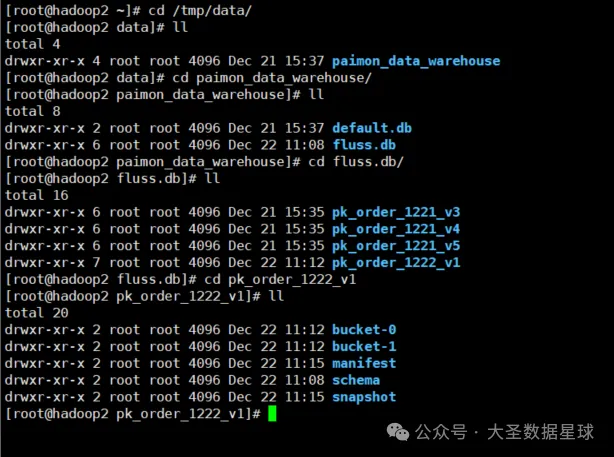
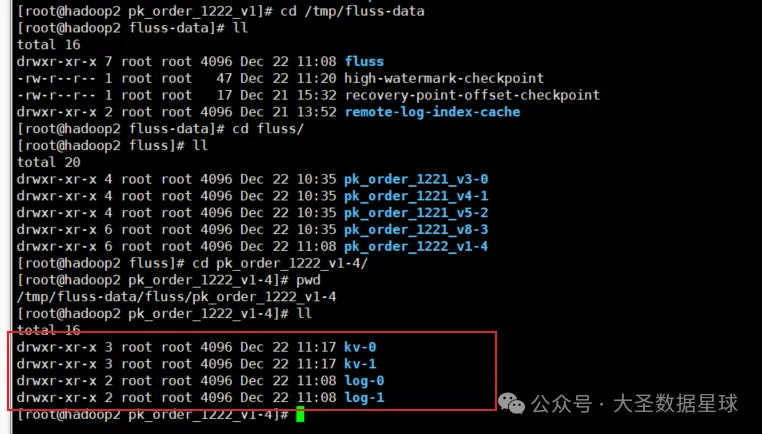
再去 Fluss 的存储路径去看一下,数据也生成了,如下图:
Fluss 查询数据湖实操
上面详细讲了 Fluss 把数据写入到 Paimon 数据湖的操作,接着我们说一下利用 Fluss 查询数据湖的操作。
为了方便演示,我们先设置成查询模式为批读,SET 'execution.runtime-mode' = 'batch'; 执行 sql 如下:
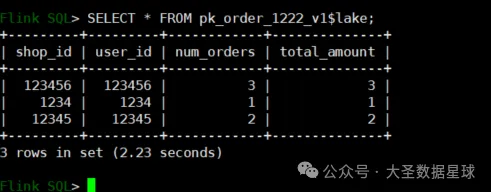
sql
SELECT * FROM pk_order_1222_v1$lake;结果如下:
我们先执行上一篇文章中那个报错的语言,来查询 pk_order_1222_v1 表,如下图:
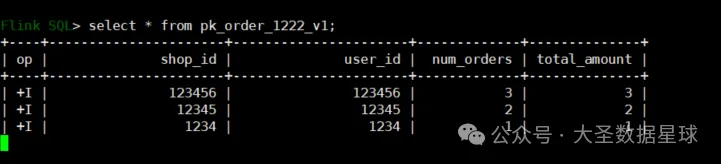
可以看到这样就查询出来了,这是因为我们这样查询的是数据湖的表,也印证了上篇文章中那个报错。
写在最后
注意上面的数据写入数据湖和从数据湖里面读取数据,只是说明了 Fluss 跑通了这个流程,具体数据的准确性,每种查询方式的作用等
我会在后续的文章里面逐步讲解的,在这里大家可以了解到 Fluss 简单的数据写入数据湖的流程,就是当我们建表的时候通过 'table.datalake.enabled'
这个参数来说明这个表为数据湖表,然后当我们写入数据的时候 Fluss 就会利用之前启动的 Compaction Service 服务把数据写入到我们配置的数据湖里面。
最后欢迎大家一起来讨论大数据技术,一起进步!
本文由博客一文多发平台 OpenWrite 发布!