前提:建议先学过hadoop再看,涉及大量hadoop知识点
一、理论先知
1、Spark四种运行模式
1)Local模式(开发环境)
用于开发和测试阶段,在单机节点上,一个Spark程序就只是一个进程,通过在一个进程里用多个线程的方式,模拟整个Saprk集群模式
;
这种模式的安装部署文章:全网最干最详细,没有之一!!:(CentOs系统虚拟机)Local单机模式下安装部署"基于Python编写"的Spark框架-CSDN博客
2)Standalone模式(生产环境)
Spark内部也像YARN一样,由各个角色构成,来为Spark调度管路资源
然后Standalone就是:Spark各个【角色】以单独的进程,来共同组成真实的Spark集群模式
;
不了解YARN的可以去看一下我往期文章:大数据之------Hadoop的HDFS、YARN、MapReduce_hadoop三大核心组件-CSDN博客
3)Hadoop Yarn模式(生产环境)
Spark各个【角色】运行在【Yarn容器内部】,由这些【Yarn容器】共同组成Spark集群模式
4)Kubernetes模式(生产环境)
容器集群,Spark中的各个角色运行在Kubernetes的容器内部,并组成Spark集群环境
5)云服务模式(生产环境)
运行在云平台上......
2、Spark架构角色
1、回顾Yarn知识点
学过Hadoop的Yarn的都知道,Yarn内部是分了各个角色来执行不同的任务分工的,回顾Yarn:
对于整Yarn资源管理层面(多个服务器节点总管理):
YARN管理的不是数据,而是【硬件和内存...等资源的调度】
【NodeManager (NM)】管理单个节点的资源(比如4G内存和2个CPU)
;
【ResourceManager (RM)】管理所有节点的资源分配(假如有三个节点【NodeManager (NM)】,每个节点都是4G内存和2个CPU,那他就管理12G内存和6个CPU)
对于单个任务计算层面(单个NodeManager服务器节点内):
【ApplicationMaster (AM)】就是单个NodeManager节点【Task任务】的老大,【Task】就是他的小弟,而【Container容器】就是【ApplicationMaster (AM)】和【Task】执行任务操作的 "工作室"。【ApplicationMaster (AM)】相当于一个包工头,在总指挥部指挥众多【Task】干活,他只负责向上级申请经费、指挥调节下面的工人怎么协调工作。
;
打个比方:一个客户端client需要用Hadoop做点什么事,那YARN就会在其中一个NodeManager节点生成一个【Container容器】,然后里面的【ApplicationMaster (AM)】来判断一下这个 "工程" 需要多少资源,然后报告上级(ResourceManager (RM)),然后上级再多分配几个【Container容器】,这些【Container容器】里面就都是【Task】了,然后【ApplicationMaster (AM)】就指挥他们完成任务。
;
【Container】也相当于一个独立的"虚拟云服务器",里面有供【ApplicationMaster (AM)】运行的内存、CPU,当然这些资源也是单个节点内靠【NodeManager (NM)】分配的虚拟资源,这样一来,如果【ApplicationMaster (AM)】执行任务时如果发现 所需要的CPU、内存这些资源不够,还可以再申请用多几个【Container】来提供这些资源。

2、Saprk的角色分析
那么Spark也差不多:
- Master角色:管理整个集群的资源,类比与YARN的ResouceManager
- Worker角色:管理单个服务器的资源,类比于YARN的NodeManager
- Driver角色:管理单个Spark任务,在运行的时候的工作,类比于YARN的ApplicationMaster
- Executor角色:单个任务运行的时候的一堆工作者,干活的,类比于YARN的容器内运行的TASK
注:正常情况下Executor才是干活的角色,不过在特殊场景下(Local模式),Driver也可以即管理又干活

3、Standalone的运行流程
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
StandAlone 是完整的Spark运行环境,其中:
- Master角色以Master进程存在
- Worker角色以Worker进程存在
- Driver角色 在运行时存在于Master进程内,Executor角色运行于Worker进程内
大概流程图,自行理解:


三、Standalone模式前置准备(必做)
前置准备: 这里略过搭配三台虚拟机集群的步骤,请自行参考下面文章或别的教程,先准备好3台VMware的CentOs系统的虚拟机,名字分别叫node1、node2、node3,然后一定一定要把网段、网关、jdk 、hadoop也都配置好!!!
有能力的话最好把Finalshell也配好,方便下面跟着我一样直接在Finalshell执行三台虚拟机的终端命令(当然直接在虚拟机里执行命令也可以)
;
参考文章,上面讲到的内容全部都有讲,自行阅读:大数据之------(分布式集群式) VWare、Ubuntu、CentOs、Hadoop安装配置-CSDN博客
然后完成上面步骤之后,这里说明一下我们的node1、node2、node3分别怎么部署配置,分布表做什么:
- node1运行:Spark的Master进程 和 1个Worker进程
- node2运行:spark的1个worker进程
- node3运行:spark的1个worker进程
- 整个集群提供: 1个master进程和3个worker进程
(是不是很像hadoop里,node1运行namenode和datanode,node2运行datanode,node3运行datanode)
四、在node1安装Anaconda (或直接安装Python3)
如果跟着我这篇Local模式安装部署的:全网最干最详细,没有之一!!:(CentOs系统虚拟机)Local单机模式下安装部署"基于Python编写"的Spark框架-CSDN博客
;
或者安装过anaconda或python的,可以先跳过这点直接看第六大点

要执行Spark我们通常都是使用python语言来操作Spark,那么自然要安装python环境,但是anaconda这个工具就自带了python3,而且能轻松管理python环境,因此安装python不如直接安装anaconda
安装anaconda ==> 等于安装了python3(当然你要非要单独安装python也行,记住是3.x版本就行 )
这里注意一点,在分布式集群的配置下,我们的这些**环境文件统一放在【/export/server】下,**如果前面已经配置过了hadoop的就肯定有这么一层目录了,如果没有的话就【mkdir /export/server】创建一下
1、下载
1)离线下载步骤:(在原机手动下载,再移到虚拟机)
最新版下载官方地址(默认下载最新版本):Anaconda | The Operating System for AI
离线安装就是我们先在原机下载好ANACONDA的Linux安装包,然后再上传到虚拟机并解压安装
2)在线wget安装:(在虚拟机里命令行下载,但简单)
清华大学下载镜像源:Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
首先到其中一个虚拟机 (因为反正是单机模式,哪个节点都一样),执行以下命令【yum install wget】,这样才能下载wget这个工具有了wget,才能使用 "
wget命令" 来下载各种安装包(这里图片例子我用的是Finalshell远程连接工具连接三个虚拟机,执行命令操作)
然后去刚刚给的 "清华镜像源" 这个网站,找到你要的Anaconda的版本,复制他的名字,然后到虚拟机命令终端,使用下面这种命令来执行下载安装(注意要安装到/export/server路径下):
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/[你的anaconda的版本名] -P /export/server/比如这里我选的是 [Anaconda3-5.3.1-Linux-x86_64.sh](https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.3.1-Linux-x86_64.sh "Anaconda3-5.3.1-Linux-x86_64.sh"),那就可以这样写:
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.3.1-Linux-x86_64.sh -P /export/server/
提示:1、选择的是Anaconda的3的版本
2、一般人的电脑都是64位的,直接选 "Linux-x86_64" 版本的
3、点击就是跟第一个离线安装方式一样,复制名字拼接上""才是wget在线下载方式
2、安装Anaconda
如果你是用刚刚第一种离线下载方式下载了anaconda安装包的话
安装包需要我们手动上传到虚拟机
这里我用的例子是Finalshell直接上传文件,当然你们也可以直接在虚拟机通过【共享文件夹】、【VMTools复制粘贴】各种办法来把文件上传到虚拟机,都是一样的我就不一 一演示了
;
注意一点,用Finalshell上传文件的话要先执行命令:【cd /export/server】,因为你在哪个位置他就自动给你上传到哪(直接虚拟机上操作的话就无所谓了,反正你最后直接复制粘贴到/export/server路径下就行)
如果你是用第二种wget的方法直接把anaconda下载到【/export/server】下
那就不需要上传了,它已经在我们的虚拟机里,并且在指定位置了
那就直接到这层目录检查有没有就行了
输入【ll】查看有没有这个文件
然后不管是方法一、方法二,现在这里都一样了,输入命令【sh 你的Anaconda文件名】来启动Anaconda安装文件
出现下面内容之后摁【回车】
然后下面是大量的阅读协议文档,你可以一直按【回车】,也可以直接按【q】键直接跳过阅读
直到出现下面界面,输入【yes】同意协议
然后就是输入你要【安装的位置】,像我一样安装到【/export/server/anaconda3】就行了
注意这里如果你写错了,它是不支持你删除重写的,你必须必须要摁【Ctrl + C】退出安装,然后再次重新进入安装步骤
最后再输入一次yes,就结束安装了
注意安装完之后,执行命令:【init 6】重启虚拟机,这样才算完整安装成功
再次连接的时候,就会发现左边有一个 "(base)" 的符号,就说明安装成功了


输入:【python】也能显示我们的python版本

输入【python】也就是进入了python的解释器控制台,就可以输入一些python代码了
直到我们输入【exit()】就是退出解释器,回到正常的Linux终端界面


然后我们最后再执行一下【vim ~/.condarc】这个命令,意思是在【~】创建一个文件,用来配置anaconda以后下载工具包的下载源,因为它是外网的,下载东西很慢,清华大学和阿里巴巴提供了很多国内的镜像源能加快下载速度:
请一字不漏的完完整整的复制粘贴过去!!!!
channels: - defaults show_channel_urls: true default_channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2 custom_channels: conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud最后最好多执行一个命令:【conda clean -i】
这是为了清除 conda 缓存,是一个好习惯
3、使用python编写spark的语言:pyspark
1)pyspark是什么
当我们全局启动spark时,可以发现有个红色的 "scale"

这意味着spark自带默认使用【scale】语言来编写spark
摁【:quit】可以退出,回到正常的终端控制台
但是我们并不是要用scale来写,我们是要用python来写!!!
那么PySpark就是Python专门用来写spark的一个库,可以理解为一个语言吧,类似numpy、pytorch、pandas......

2)创建pyspark的环境或者导入库
对于单个全局的python环境下,也就是你只安装了在指定的一个版本的python,那么你这个虚拟机整个python环境就固定了,那么你只需要用python的下载包的命令:"pip 工具库",把pyspark这个工具库下载下来就能用了
对于安装了anaconda的,那么你只需要营造一个适合写pyspark的"虚拟环境"就行,只用 【conda create -n "自定义虚拟环境名" python="任意一个指定的版本"】,anaconda就会根据 "python='任意一个指定的版本' " 来创造一个这个版本的python运行环境下的、叫 "自定义虚拟环境名" 的一个 "虚拟环境",不管你整个虚拟机的python环境是多少,并不影响这个虚拟环境
打个比方:
- 有两个项目,A项目需要3.8的python环境,B项目需要2.0版本的python环境,如果你只下载了python,而且版本是1.0版本的,那么你就需要卸载了,然后写A项目时安装3.8的,写B项目时再卸载再安装2.0版本的python;
- 但是如果你安装了anaconda,那么可能anaconda自带的python环境的4.0,但是不影响。你只需要写A项目时【conda create -n A python=3.8】,写B项目时【conda create -n B python=2.0】,就创建了适配这两个项目的两个版本的python虚拟环境,完美。
提示1: 如果你不是安装 anaconda,是直接安装python的,请确保你有 pyspark 这个库,可能只安装python的话是没有这个库的,还需要另外手动执行pip下载命令,下载好pyspark先:
pip install pyspark # 使用国内代理镜像网站更快(清华大学源) pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark
提醒2: 如果是用anaconda安装的 ,请确保我们做了这一步------------>为【pyspark】创建一个属于它自己的运行虚拟环境(这里推荐使用3.8版本的,因为是最稳定兼容的版本环境)
conda create -n pyspark python=3.8
;
如果你执行完【conda create -n pyspark python=3.8】之后出现了这样的界面
就是成功创建了pyspark的虚拟环境
;
最后只需要输入命令:【conda activate pyspark】
就可以成功激活这个虚拟环境了!!
3)十大未解之谜,诡异灵异事件
但是成功的道路永远不可能一帆风顺,我本人执行【conda create -n pyspark python=3.8】的时候就遇到了问题,我足足花了两天下午加晚上的时间,中途只拉了2次尿,才搞定
但是如果出现错误了,推荐各位去我的这个文章看解决问题办法,全都写在这里太臃肿了:
我自己的:全网最干最详细,没有之一!!:(CentOs系统虚拟机)Local单机模式下安装部署"基于Python编写"的Spark框架-CSDN博客
centOs的node1的用conda创建pyspark虚拟环境遇到的灵异事件_服务器-CSDN问答
;
【Python】conda镜像配置,.condarc文件详解,channel镜像-CSDN博客
4)最后配置一下环境变量
执行【vim /etc/profile】,将下面内容复制进去
export JAVA_HOME=/export/server/jdk export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/export/server/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export SPARK_HOME=/export/server/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin export PATH=$PATH:$PYSPARK_PYTHON/python3.8 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$PATH:$HADOOP_CONF_DIR
5)最后最后,【~/.bashrc】配置文件的配置
还没完....还有一个【~/.bashrc】配置文件需要配置我们的【JAVA_HOME 】和 【PYSPARK_PYTHON】
执行:【vim ~/.bashrc】,然后将下面内容复制进去:
export JAVA_HOME=/export/server/jdk export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8
五、在node1安装spark
1、下载
清华镜像下载源:Index of /apache/spark
华为镜像下载源:Index of apache-local/spark
清华源镜像指引


华为镜像下载指引


2、安装Spark
有了压缩包之后,安装很简单,就是把它上传到虚拟机
然后,解压压缩包就是安装好了,就这么简单
还是一样的,要先上传到【/export/server】下,就先执行【cd /export/server】,然后再点击上传Saprk压缩包
输入【ll】检查一下


然后接着解压安装,就解压在上传的路径下就行,怕出错就用 "全局路径"
tar -zxvf /export/server/[你的spark压缩包名字] -C /export/server

然后给安装目录换个名字(名字太长了不好找):2种方式任选
1、直接整个文件夹换名字:
mv [你的spark目录路径全名] [spark]2、或者采用软连接,也就是源文件名不变,添加一个"快捷方式":
ln -s [你的spark目录路径全名] [spark]

然后启动,启动方式:(也是2种方式,任你选择)
1、直接到【/export/server/spark/bin/spark-shell】下执行这个spark启动文件,直接输入命令【/export/server/spark/bin/spark-shell】就行


2、将【/export/server/spark/bin】、【/export/server/spark/sbin】都配置到Path环境变量,这样在全局范围内任意路径下,只需要输入【spark-shell】就能启动了!
配置环境变量也有2种方式,任你选择:
(1)直接将下面命令行一条一条粘贴到终端控制台执行(除了#注释)
echo 'export SPARK_HOME=/export/server/spark' >> /etc/profile echo 'export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin' >> /etc/profile #执行完之后 source /etc/profile;
;
(2)用vim编辑/etc/profile文件,来配置
先执行【vim /etc/profile】,然后将下面内容复制到最底部,":wq" 保存退出
export SPARK_HOME=/export/server/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin



六、将node1的安装配置移到node2、node3
现在你的node1已经安装好了anaconda、spark、pysaprk,并配置好了环境变量,现在只需要让node2、node3也一样就行了
1、在node1用scp命令,把anaconda安装包复制过去
先【cd /eexport/server】,然后用【ll】命令检查一下你的anaconda的安装文件的全名叫什么
然后分别执行下面的两条命令,把你的anaconda安装文件从node1复制到node2
scp [你的anaconda的安装文件名] node2:`pwd`/ scp [你的anaconda的安装文件名] node3:`pwd`/ # 注意包住pwd的是``,不是'',而且不要漏了/

2、分别到node2、node3手动安装传过来的anaconda安装文件
先【cd /export/server】,然后用【ll】命令检查一下你的anaconda的安装文件的全名叫什么
然后分别到node1、node2执行下面的这条命令,也就是安装它
sh ./[你的anaconda安装文件名]

安装完之后,node2、node3都执行【init 6】重启一下
3、然后配置node2、node3的conda的镜像源文件
在node2、node3分别执行【vim ~/.condarc】
将这些内容再次复制到node2、node3的【~/.condarc】文件里面
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud4、然后在node2、node3创建pyspark虚拟环境,并激活
在node1、node2分别执行下面两个命令
conda create -n pyspark python=3.8
conda activate pyspark再次出现网络失败问题的,请好好查阅下面文章来解决
我自己的:全网最干最详细,没有之一!!:(CentOs系统虚拟机)Local单机模式下安装部署"基于Python编写"的Spark框架-CSDN博客
centOs的node1的用conda创建pyspark虚拟环境遇到的灵异事件_服务器-CSDN问答
;
【Python】conda镜像配置,.condarc文件详解,channel镜像-CSDN博客
https://wenku.csdn.net/answer/a6goczrrwn
https://zhuanlan.zhihu.com/p/643482964?utm_id=0
当然还有一种情况,我当时一开始配置分布式集群的时候就粗心大意,煞笔一样把node2的网卡配置文件写错了,直到一直问老师才发现问题:不要忘记【service network restart】或者【systemctl restart network】



5、配置环境变量
直接去node2、node3,把pyspark、hadoop、jdk、spark......这些环境变量配上
执行【vim /etc/profile】,把下面内容复制进去(这里我默认各位node2、node3的jdk和hadoop环境变量已经配好了,我就不复制了)
export SPARK_HOME=/export/server/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8 export PATH=$PATH:$PYSPARK_PYTHON export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$PATH:$HADOOP_CONF_DIR

然后执行【vim ~/.bashrc】,将下面内容复制进去
export JAVA_HOME=/export/server/jdk export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8

七、在node1配置集群式spark
前提:必须三台虚拟机都已经创建过hadoop用户,还是那句话,没有做的回去看我上面给的我的往期分布式集群配置hadoop的文章,里面有讲怎么创建hadoop用户以及赋予权限
1、将使用hadoop用户身份来执行spark
现在我们需要做的就是在node1上,把spark的读写权限全部赋予给hadoop用户
先执行这个命令,授权
chown -R hadoop:hadoop /export/server/spark*然后执行下面命令,从root用户切换到hadoop用户
su - hadoop2、配置workers配置文件
然后执行【cd cd /export/server/spark/conf】,执行【ll】可以看到这里有一个叫【workers.template】的文件,这文件就是用来指定配置集群化节点的
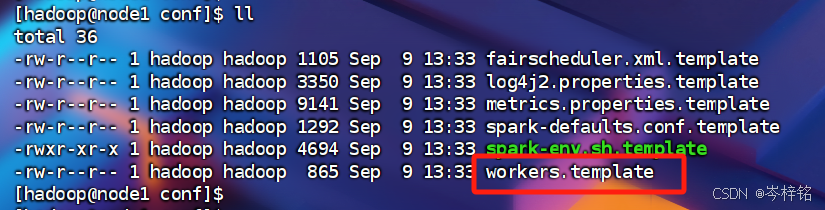
我们先将他改名为【workers】,方便以后找他
mv workers.template workers然后执行【vim workers】,将里面的 "localhost"删掉,换成下面内容
node1 node2 node3


3、配置spark-env.sh
然后看到绿色的这个文件,接下来配置他
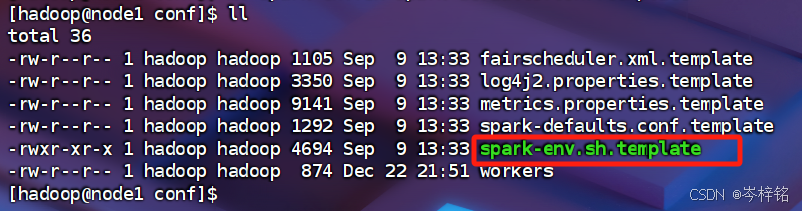
还是一样,换名字
mv spark-env.sh.template spark-env.sh然后【vim spark-env.sh】,把下面内容复制进去
## 设置JAVA安装目录 JAVA_HOME=/export/server/jdk ## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群 HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop YARN_CONF_DIR=/export/server/hadoop/etc/hadoop ## 指定spark老大Master的IP和提交任务的通信端口 # 告知Spark的master运行在哪个机器上 export SPARK_MASTER_HOST=node1 # 告知sparkmaster的通讯端口 export SPARK_MASTER_PORT=7077 # 告知spark master的 webui端口 SPARK_MASTER_WEBUI_PORT=8080 # worker cpu可用核数 SPARK_WORKER_CORES=1 # worker可用内存 SPARK_WORKER_MEMORY=1g # worker的工作通讯地址 SPARK_WORKER_PORT=7078 # worker的 webui地址 SPARK_WORKER_WEBUI_PORT=8081 ## 设置历史服务器 # 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"

4、在hdfs文件系统创建 "历史服务器的日志目录"
刚刚我们那一大段配置里有一部分是设置了日后我们的历史日志输入到哪,但是问题是我们现在并没有这个目录

我们可以先【start-dfs.sh】启动hadoop服务,然后到我们的hdfs文件系统查看一下
【hadoop fs -ls /】或者直接打开浏览器【node1:9870】都可以看到文件系统
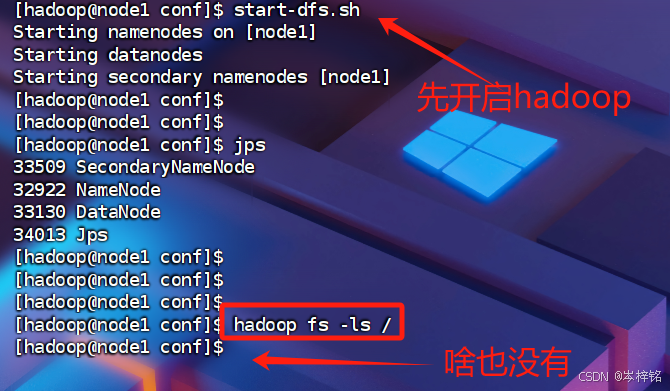
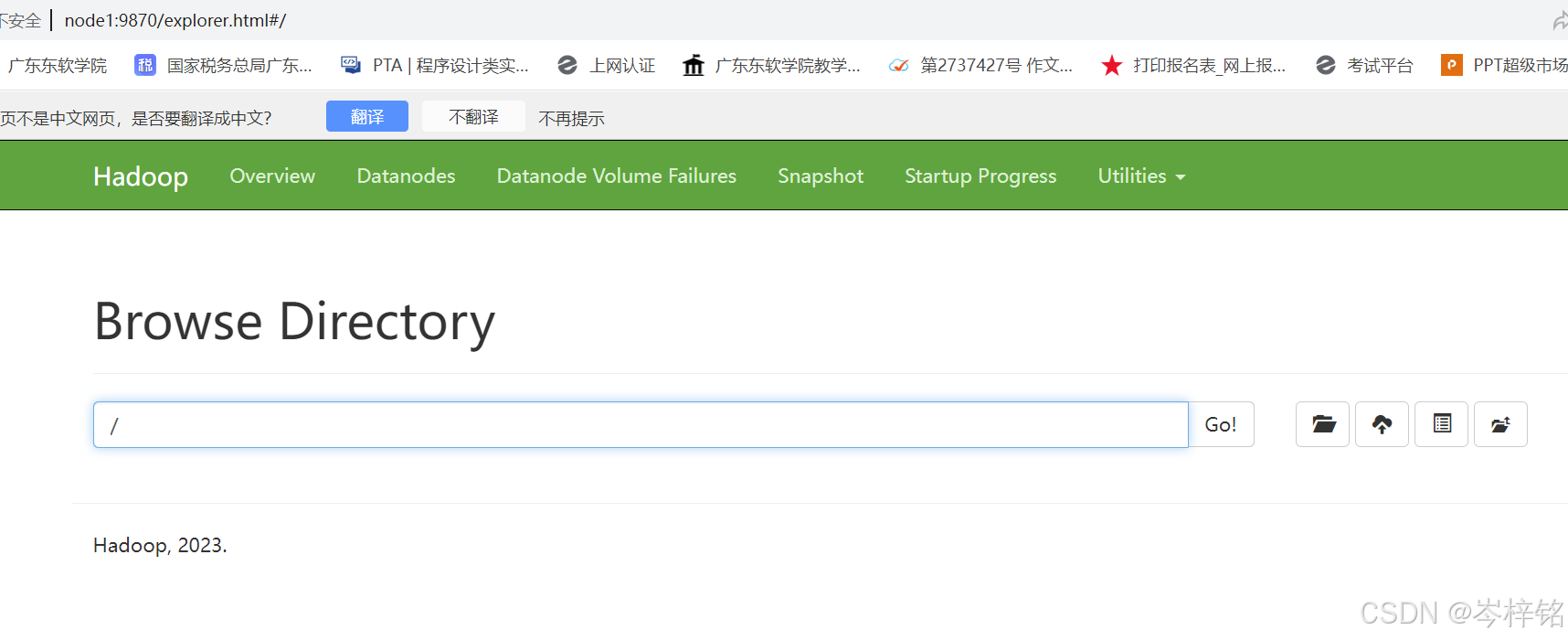
那么我们就分别执行下面两条命令
hadoop fs -mkdir /sparklog hadoop fs -chmod 777 /sparklog此时再看,就会发现hdfs的文件系统里多了这么一个叫 "sparklog" 的目录,而且读和写的权限是hadoop用户

5、配置spark-defaults.conf
还是先改名
mv spark-defaults.conf.template spark-defaults.conf然后【vim spark-defaults.conf】,这里留意,先摁【Esc】,然后输入【:set paste】,然后再摁【i】进行编辑
然后再把下面内容复制进去
# 开启spark的日期记录功能 spark.eventLog.enabled true # 设置spark日志记录的路径 spark.eventLog.dir hdfs://node1:8020/sparklog/ # 设置spark日志是否启动压缩 spark.eventLog.compress true


6、改一下log4j2.properties.template名字
mv log4j2.properties.template log4j2.properties八、然后将node1改好的spark文件移到node2、node3
现在在node1配置完spark的standalone模式之后,我们只需要将这个spark文件复制给node2、node3就行了,执行下面的命令:
scp -r [你的spark文件全名] node2:`pwd`/
scp -r [你的spark文件全名] node3:`pwd`/这里有一个很严重的问题!!!一定要留意两点:
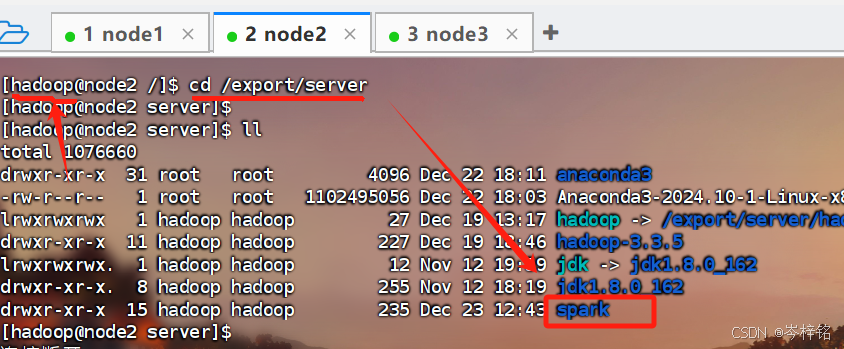
1、如果你的spark文件是用【ln -s 原文件名 新文件名】的软连接形式,那么注意,用上面【scp -r ...】复制命令的时候,一定要用这个文件的原名,因为软连接的新名字只是一个快捷方式
那如果你的spark文件使用【mv 原文件名 新文件名】,那么【scp -r ...】复制命令就可以用新名字,因为【mv】改名字是直接把源文件名字改了,不存在快捷方式,比如下图例子:
;
2、使用我上面那个【scp ...】复制命令的时候,一定要在【/export/server】这个路径下,因为注意这行命令的最后的 "pwd/" 的意思,就是指把你这个文件发送到node2、node3的你当前node1所在的位置
打比方:你在 "~/Dowmloads" 这个路径执行 "scp -r xxx node2:`pwd`/ ",意思就是把xxx发送到node2的 "~/Dowmloads" 这个位置下


复制完成之后,先别急,一定要去node2、node3好好检查一下有没有这个文件
而且要执行【su - hadoop】切换【hadoop】用户,因为可能root用户还看不到,以防万一
然后如果你在node1对spark使用的是软连接,那么还要记得在node2、node3也要用【ln -s 原文件名 新文件名】设置软连接,不然node2、node3的spark文件还是源文件那个很长的原名(用【mv ...】改名的就不用了,你传过去的文件名字本来就是改过的了)
九、启动!!!
现在,完事具备,只需最后几步
到node1,执行【cd /export/server/spark】进入到spark目录
然后执行命令【sbin/start-history-server.sh】,spark下的sbin里的start-history-server.sh脚本就是启动历史服务器,开启了这个进程就可以记录spark的历史日志

执行【jps】检查一下有没有【HistoryServer】这个进程开启,这个就是spark的历史服务器的进程
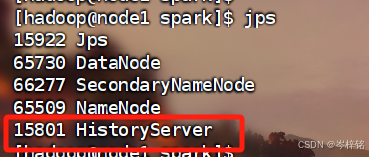
有的人可能还有一个叫【JobHistoryServer】的进程,这个是hadoop的yarn的历史服务器的进程,因为我只用【start-dfs.sh】开启了hdfs,没有开yarn;如果是用【start-all.sh】就是把hdfs和yarn都开启了,就会有这个【JobHistoryServer】进程

然后最后,执行这个命令:【sbin/start-all.sh】
这样就正式同时启动了node1、node2、node3整个集群的spark了

最后执行到node1、node2、node3都执行【jps】,node1要看到worker和master两个进程,node2、node3要看到worker进程


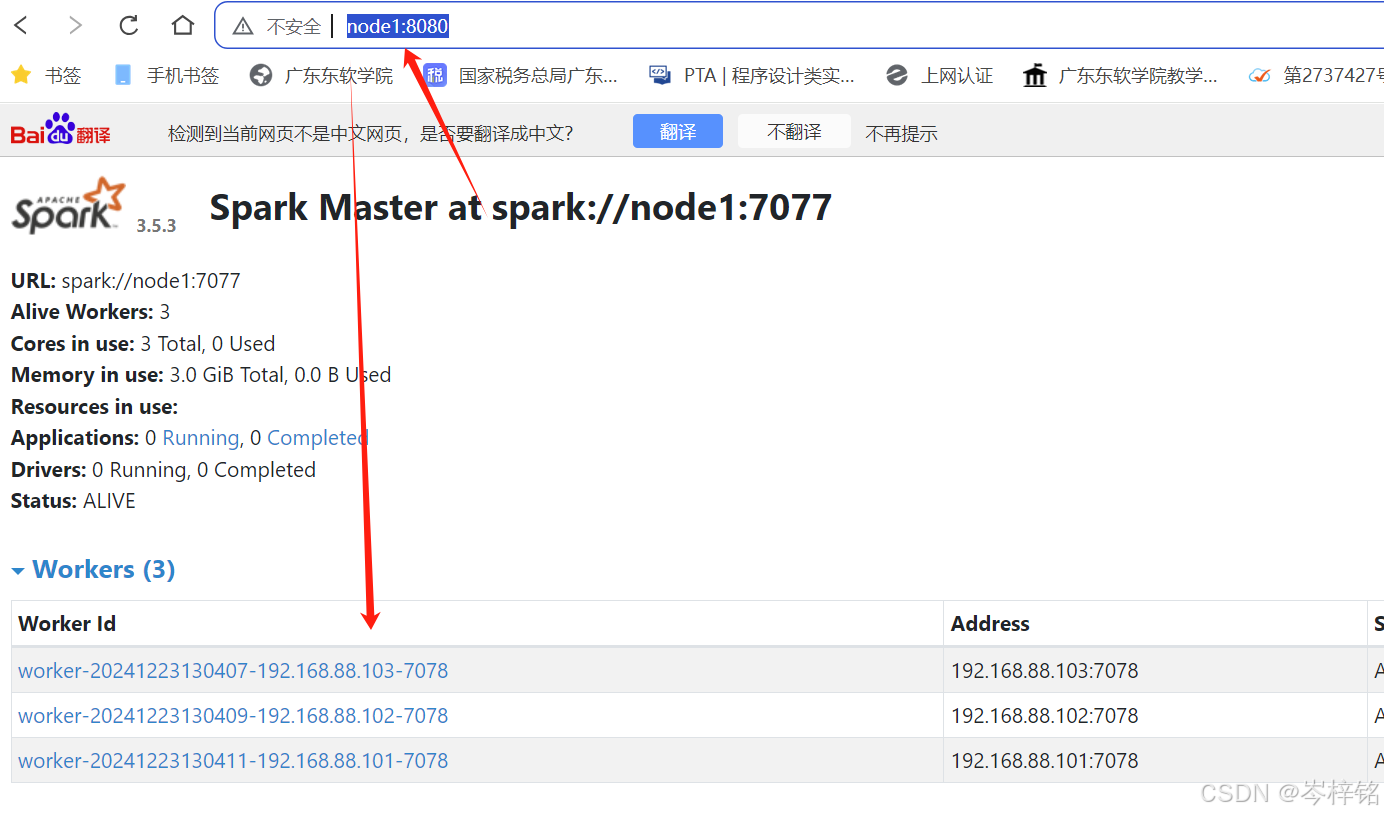
然后在浏览器输入【http://node1:8080/】网址,可以看到spark的standalone模式的GUI界面(或者叫 webUI)
那么如果这里还有问题的,请先回去仔细排查上面有无哪一个步骤没有做好,需要注意的是,在重新检查完之后,因为刚刚我们执行过【sbin/start-history-server.sh】和【sbin/start-all.sh】,此时node1、node2、node3已经开启了spark的进程,那么你要么通过【kill 进程编号】的形式一个一个关掉,要么直接执行【sbin/stop-history-server.sh】和【sbin/stop-all.sh】一键关闭整个服务,然后再开启
十、使用
那么现在,一切成功之后我们就可以去使用他了
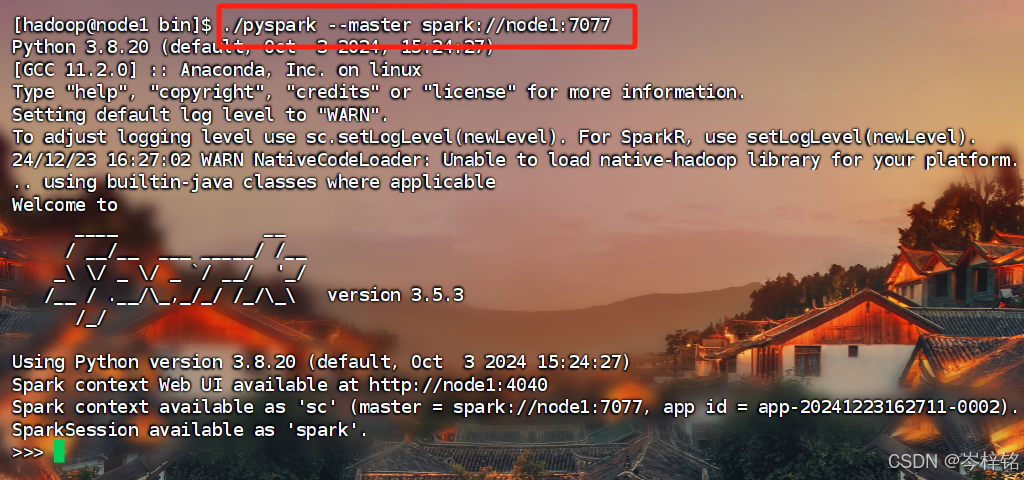
首先到spark的bin下执行【./pyspark】脚本
执行命令【cd /export/server/spark/bin】,然后和执行【.pyspark】
此时你有两种命令选择,可以切换【Local单机模式】还是【Standalone集群模式】
- 1、Local 模式:./pyspark --master local\*
- 2、Standalone 模式:./pyspark --master <你的master连接路径>
这里需要注意,这个<你的master连接路径>就是你打开的 【http://node1:8080/】网址里,下图那个路径

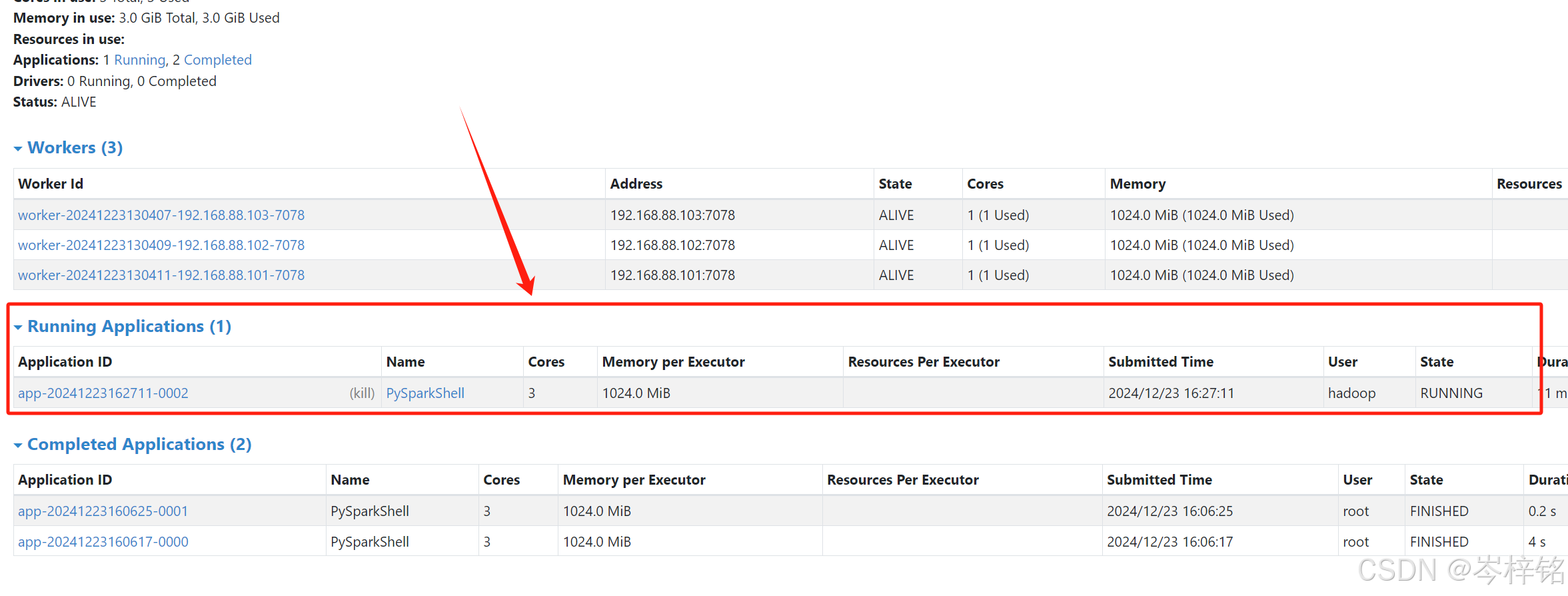
Standalone 模式连接成功之后,就会看到这样的场景 :
这里可能还会有人出错,像下面这样:
此时可以执行这两个代码
mkdir -p /tmp/spark-events chown -R hadoop:hadoop /tmp/spark-events虽然我也不知道为什么,反正把报错信息问了ai,ai这么说的,照做就得了....



另外还有历史服务器,我们在通过【spark-submit命令】完成了某些py脚本之后,他们会被保留在【HistoryServer】,也有他自己的端口,我们可以去浏览器去自行查看