〇、安装基础环境
1. 制作启动盘并安装Centos
为了更直观的看到GPU的工作效果,这次打算直接在物理机上整个Centos系统,所以就涉及到使用启动盘了。我是使用UtralISO把Centos Stream 8的dvd1安装包弄到了U盘里,然而在安装的时候遇上找不到启动镜像的问题。
实际上,将dvd1直接写到U盘里,确实会带来这样的问题------因为安装程序默认的路径仍然是光盘镜像。于是在启动的时候,几个绿色的【OK】以后,就一直"Start cancel waiting for multipath sibling of sda"这一步,等啊等,然后蹦出一个dracut提示符。
我们需要在dracut提示符下通过ls /dev查看一下当前的设备。一般来说,U盘会在sdb4这里。通常存储设备是按照sda,sdb,sdc,sdd这样的顺序依次向下排的,如果哪个下面确实挂了一张盘,那么就会增加一个带编号的同名设备。多数情况下,电脑里就一张硬盘,那么它就会是sda1;而U盘自然就是sdb下面,不过不是1,而是4。然而在我的机器中硬盘有点多,所以我的U盘在sdg4上。
弄明白U盘在哪里后,直接reboot。在BIOS中,继续将U盘设为第一启动项。在出现开机选项界面的时候,动一下上下方向键以便将页面留住。然后看看说明,一般来说是选择e或者tab可以进入配置更改的模式。在centos stream 8中是tab键。选择后,屏幕下方会出现诸如 vmlinuz initrd.img inst.stage2=hd:LABEL=CentOS......。这里直接把hd:后面的设备名换了就行了:
vmlinuz initrd.img inst.stage2=hd:/dev/sdg4,然后ctrl+x启动。
2. 多路径硬盘挂载
在使用Spark时,最头疼的是读入数据这个阶段,一个Read后等版个多小时是常态。这次我打算直接把硬盘IO提到顶。拜国货之光的福,今年存储价格已经被打到接近白菜价,所以我非常土豪的整了两条NVME 2T的梵想790,7.5GB的吞吐能力,基本在PCIE4下,应该是到顶了。
由于满插硬盘加满插NVME的关系,不幸的遭遇了多路径问题。系统将两块NVME都识别成了mpatha设备,造成没有安装系统的那条NVME无法格式化。
有关多路径的设置可以参考centos安装多路径,及安装后新增磁盘无法格式化处理方法这篇文章。不过相关的服务其实我们在centos stream 8中都已经有了,所以我们唯一需要做的就是更改多路径的配置。
先使用ls /dev和lsblk命令看一下,可以知道我们装了系统的那个叫做nvme0,我们想挂上的这个叫做nvme1
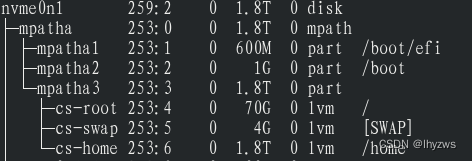
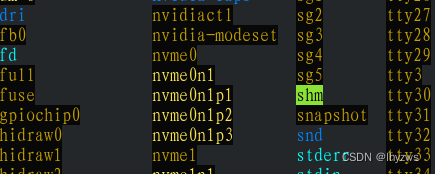
然后直接vim /etc/multipath.conf,将nvme1添加到blacklist里面,重启服务或者重启系统,就可以挂载并格式化了。
defaults {
find_multipaths yes
user_friendly_names yes
}
blacklist {
devnode "nvme1"
}3 . 异构文件系统格式存储介质挂载
不知道stream 8是不是对异构文件系统的支持有所变动,总之是exfat相关的两个软件包很难装上了。先不管了,还好ntfs-3g还是很容易装上的
[root@bogon ~]# yum install -y ntfs-3g
上次元数据过期检查:0:14:15 前,执行于 2023年09月09日 星期六 18时40分14秒。
依赖关系解决。
=========================================================================================================
软件包 架构 版本 仓库 大小
=========================================================================================================
安装:
ntfs-3g x86_64 2:2022.10.3-1.el8 epel 133 k
安装依赖关系:
ntfs-3g-libs x86_64 2:2022.10.3-1.el8 epel 187 k
事务概要
=========================================================================================================
安装 2 软件包
总下载:320 k
安装大小:690 k
下载软件包:
(1/2): ntfs-3g-2022.10.3-1.el8.x86_64.rpm 1.5 MB/s | 133 kB 00:00
(2/2): ntfs-3g-libs-2022.10.3-1.el8.x86_64.rpm 2.0 MB/s | 187 kB 00:00
---------------------------------------------------------------------------------------------------------
总计 842 kB/s | 320 kB 00:00
运行事务检查
事务检查成功。
运行事务测试
事务测试成功。
运行事务
准备中 : 1/1
安装 : ntfs-3g-libs-2:2022.10.3-1.el8.x86_64 1/2
安装 : ntfs-3g-2:2022.10.3-1.el8.x86_64 2/2
运行脚本: ntfs-3g-2:2022.10.3-1.el8.x86_64 2/2
验证 : ntfs-3g-2:2022.10.3-1.el8.x86_64 1/2
验证 : ntfs-3g-libs-2:2022.10.3-1.el8.x86_64 2/2
已安装:
ntfs-3g-2:2022.10.3-1.el8.x86_64 ntfs-3g-libs-2:2022.10.3-1.el8.x86_64
完毕!安装GPU驱动
一、重要的预备动作
安装GPU有几个重要的预备动作需要做,不做的话后果很严重......
1. 关闭安全启动和UEFI选项
这个是最容易被忽略的一个预备动作。具体为什么需要这样干不知,我只知道在我没有设置这个之前,虽然安装GPU驱动很顺利,但是在安装CUDA Toolkit以后,就会造成屏幕黑屏,或者左上角光标不停闪烁,无法再启动图形界面。基本无法抢救。
对于华硕x570的主板而言,这个Secure Boot选项是默认打开的,需要先删除默认的密钥,才能将其关闭。
另一个,只要在启动系统中选择"其他系统",而不要选择"windows UEFI",大致就是关闭了吧。
总之把这两个干掉以后,我算是安装成功了。
2. 安装开发语言包套件和Java
由于NVIDIA驱动是现编译的,所以在安装它之前,需要将gcc、gcc-c++、make等一系列语言工具安装好。简单起见,直接组安装:
yum group install -y "Development Tools"
也许会把gdb漏了,补一下就好。不过nvidia并不需要,只是我自己强迫症而已
yum install -y gdb
然后,把java也装上(其实java已经有了,只不过javac还没有,同样强迫症)
[root@bogon ~]# yum install java-1.8.0-*
上次元数据过期检查:0:05:45 前,执行于 2023年09月09日 星期六 19时14分05秒。
依赖关系解决。
=========================================================================================================
软件包 架构 版本 仓库 大小
=========================================================================================================
安装:
java-1.8.0-openjdk x86_64 1:1.8.0.362.b08-3.el8 appstream 544 k
java-1.8.0-openjdk-accessibility x86_64 1:1.8.0.362.b08-3.el8 appstream 115 k
java-1.8.0-openjdk-demo x86_64 1:1.8.0.362.b08-3.el8 appstream 2.1 M
java-1.8.0-openjdk-devel x86_64 1:1.8.0.362.b08-3.el8 appstream 9.8 M
java-1.8.0-openjdk-headless-slowdebug x86_64 1:1.8.0.362.b08-3.el8 appstream 36 M
java-1.8.0-openjdk-javadoc noarch 1:1.8.0.362.b08-3.el8 appstream 15 M
java-1.8.0-openjdk-javadoc-zip noarch 1:1.8.0.362.b08-3.el8 appstream 42 M
java-1.8.0-openjdk-slowdebug x86_64 1:1.8.0.362.b08-3.el8 appstream 524 k
java-1.8.0-openjdk-src x86_64 1:1.8.0.362.b08-3.el8 appstream 45 M
安装依赖关系:
java-atk-wrapper x86_64 0.33.2-6.el8 appstream 86 k这样就都在了:
[root@bogon ~]# javac -version
javac 1.8.0_362
[root@bogon ~]# java -version
openjdk version "1.8.0_362"
OpenJDK Runtime Environment (build 1.8.0_362-b08)
OpenJDK 64-Bit Server VM (build 25.362-b08, mixed mode)3. 卸载并禁止nouveau
安装前需要禁用第三方驱动,否则会和nvidia驱动起冲突。使用lsmod命令查看nouveau是否存在:
[root@bogon ~]# lsmod|grep nouveau
nouveau 2461696 21
drm_ttm_helper 16384 1 nouveau
ttm 81920 2 drm_ttm_helper,nouveau
video 53248 1 nouveau
i2c_algo_bit 16384 1 nouveau
mxm_wmi 16384 1 nouveau
drm_display_helper 155648 1 nouveau
drm_kms_helper 180224 4 drm_display_helper,nouveau
drm 598016 11 drm_kms_helper,drm_display_helper,drm_ttm_helper,ttm,nouveau
wmi 32768 2 mxm_wmi,nouveau实际为该软件包(xorg-x11-drv-nouveau.x86_64)造成,所以需要使用yum remove xorg-x11-drv-nouveau.x86_64 -y将其卸载掉。
[root@bogon ~]# yum list xorg-x11-*
上次元数据过期检查:0:32:47 前,执行于 2023年09月09日 星期六 19时14分05秒。
已安装的软件包
xorg-x11-drv-ati.x86_64 19.1.0-1.el8 @appstream
xorg-x11-drv-evdev.x86_64 2.10.6-2.el8 @appstream
xorg-x11-drv-fbdev.x86_64 0.5.0-2.el8 @appstream
xorg-x11-drv-intel.x86_64 2.99.917-41.20210115.el8 @appstream
xorg-x11-drv-libinput.x86_64 0.29.0-1.el8 @appstream
xorg-x11-drv-nouveau.x86_64 1:1.0.15-4.el8.1 @appstream
xorg-x11-drv-qxl.x86_64 0.1.5-11.el8 @appstream
xorg-x11-drv-vesa.x86_64 2.4.0-3.el8 @appstream
xorg-x11-drv-vmware.x86_64 13.2.1-8.el8 @appstream
xorg-x11-drv-wacom.x86_64 0.38.0-1.el8 @appstream
xorg-x11-drv-wacom-serial-support.x86_64 0.38.0-1.el8 @appstream
xorg-x11-font-utils.x86_64 1:7.5-41.el8 @appstream
xorg-x11-fonts-Type1.noarch 7.5-19.el8 @appstream
xorg-x11-server-Xorg.x86_64 1.20.11-17.el8 @appstream
xorg-x11-server-Xwayland.x86_64 21.1.3-12.el8 @appstream
xorg-x11-server-common.x86_64 1.20.11-17.el8 @appstream
xorg-x11-server-utils.x86_64 7.7-27.el8 @appstream
xorg-x11-utils.x86_64 7.5-28.el8 @appstream
xorg-x11-xauth.x86_64 1:1.0.9-12.el8 @appstream
xorg-x11-xinit.x86_64 1.3.4-18.el8 @appstream
xorg-x11-xinit-session.x86_64 1.3.4-18.el8 @appstream
xorg-x11-xkb-utils.x86_64 7.7-28.el8 @appstream当然,仅仅只是卸载还是不够的,还需要将其列入到modprobe的黑名单中:
在/etc/modprobe.d下,生成一个conf文件,貌似名字是啥都行,有直接叫blacklist的,也有如我这样,叫blacklist-nouveau.conf这么具体的:
root@bogon ~]# vim /etc/modprobe.d/blacklist-nouveau.conf
[root@bogon ~]# cat /etc/modprobe.d/blacklist-nouveau.conf
blacklist nouveau
options nouveau modeset=0
[root@bogon ~]# dracut --force加上这么两行nouveau彻底禁掉,然后将其在/usr/lib/modprobe.d目录下也拷贝一份。当然更标准的官方做法,是如下存放和命名:
/usr/lib/modprobe.d/nvidia-installer-disable-nouveau.conf
/etc/modprobe.d/nvidia-installer-disable-nouveau.conf然后,备份镜像后执行dracut构建新的镜像的操作:
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r)-nouveau.img
dracut /boot/initramfs-$(uname -r).img $(uname -r)
reboot当然,暴力一点的方法也有,这个命令得多等会,完成后直接reboot回车。:
dracut --force
reboot这两种方法我都尝试过,均可用。不过,暴力的方法我在安装CUDA toolkit的时候遇到黑屏错误了,当然这也有可能(或者说大概率)是没有关闭安全启动的原因;而为了解决这个问题,我在禁用安全启动后的安装中也使用了稳妥的备用镜像方法然后成功。所以也没有再去较真这个问题。
4. 进入命令行模式
如上完成配置重启后,如果禁用成功,系统重新启动起来的时候,桌面会比较难看和拉扯------毕竟第三方驱动没有了。这也就能够说明mouveau被禁用了。所以期望它难看点儿的好。然后在系统启动后,有两种方式可以进入命令行模式:
init 3命令
直接在shell中使用init 3命令,可进入命令行模式;使用init 5可以从命令行方式重新回到交互式界面,当然前提是GNOME得有。
更改默认启动方式
使用 systemctl get-default命令可以获得当前默认的启动方式:
pig$ systemctl get-default
graphical.target然后使用systemctl set-default命令可以将其设定为命令行模式:
pig$ systemctl set-default multi-user.target重启系统就可以进入命令行模式了。回头安装完了,再将其改为图形模式即可。
显然,第一种方式更方便些,但安全起见,还是第二种好------因为我就有一次一冲动,再忘记切换到命令行模式的情况下启动了驱动安装,一般来说这种情况应该会收到如下报警:
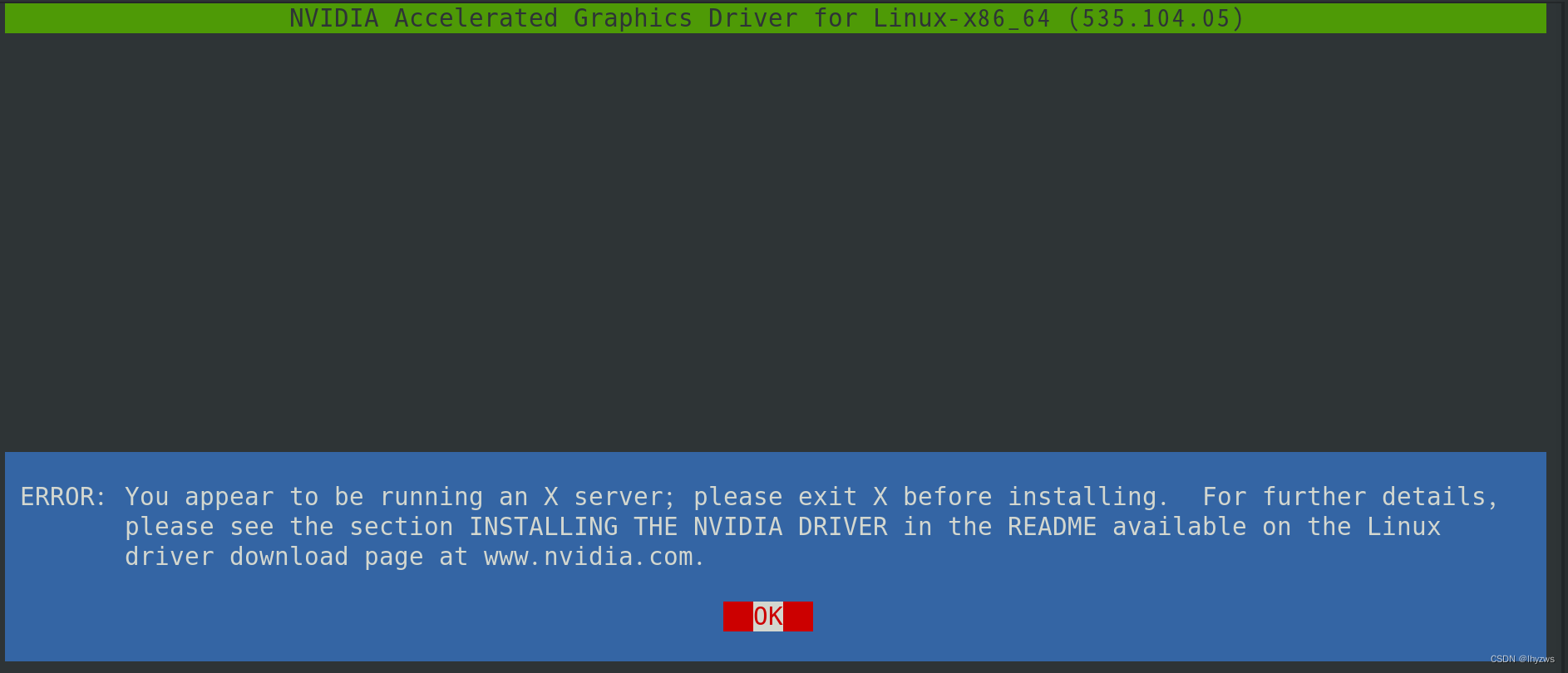
然而,就这次我没有收到任何告警,驱动就莫名奇妙的装完了------然后当然是各种不正常,无解情况下我只好重头再来......
二、 安装nvidia驱动
1. 下载正确的驱动程序
这个安装说难不难,说容易也挺不容易。关键在于很容易受官方误导------给了一个选择驱动的窗口让你进陷阱。如果你按照官方的型号填,大概率到这个地方:

然而实际上应该在填表的页面上再往下拉点:
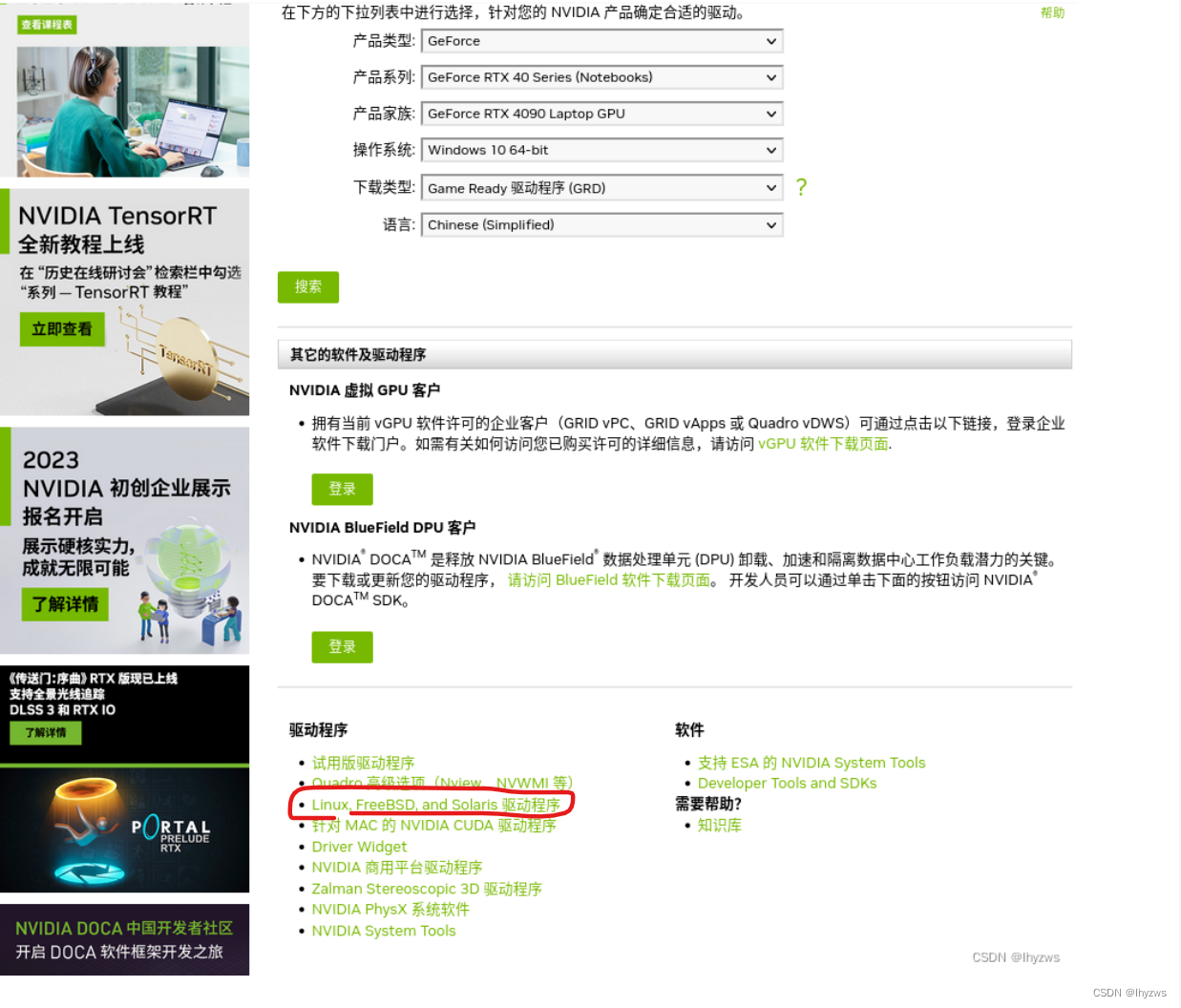
进驱动程序的第三项:Linux、FreeBSD、and Solaris驱动程序
当然,如果你人品好,官方还会假装AI小人告诉你,页面找不到了......
多试几次,或则干脆直接从这个网址进:Unix Drivers | NVIDIA
我是stream 8,估计是啥也都差不多,总之不能选择535,要选那个"传统GPU超级新版本"(470.***)系列的。------官方这个取名的人看起来就十分doubility。
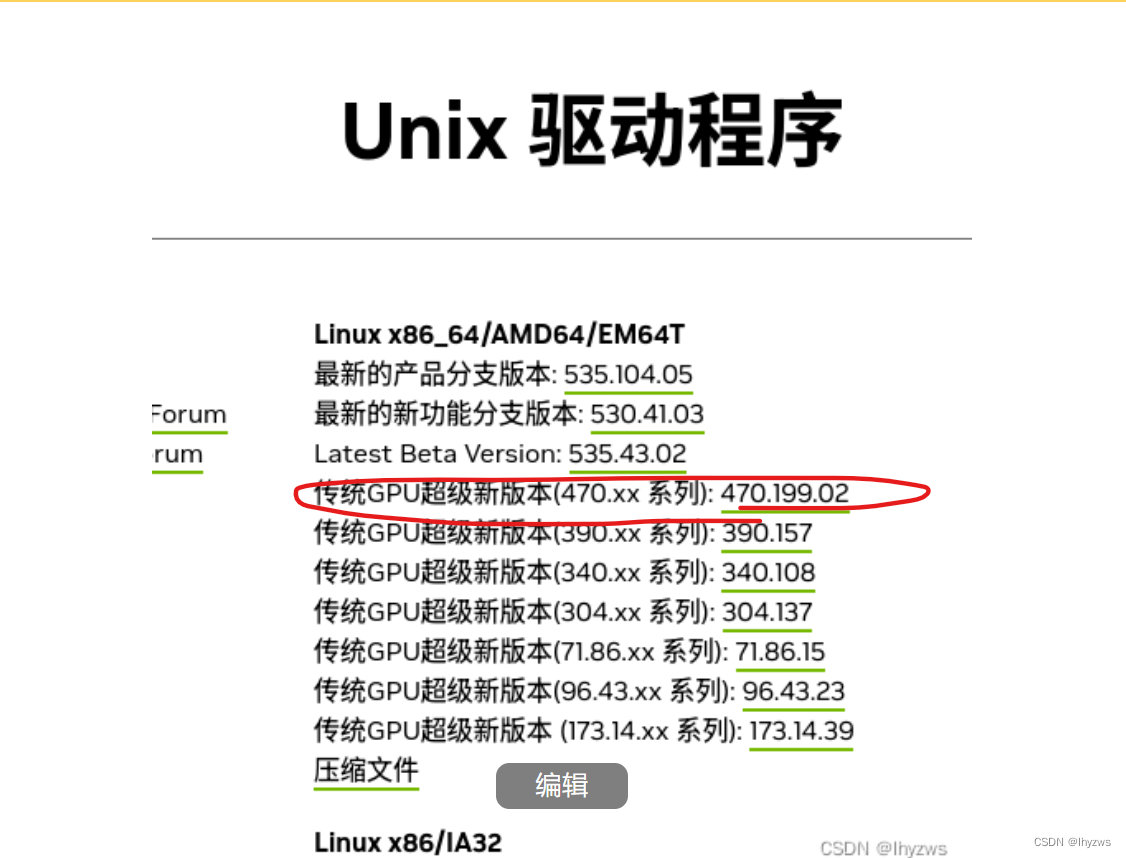
下载到run文件后,需要改一下属性才能运行:
[root@bogon ~]# chmod 777 NVIDIA-Linux-x86_64-535.104.05.run 2. 前提条件检查
以下的几个前提一般来说都是自满足的,不过也还是检查一下的好,别装了半天整个寂寞
(1)显卡存在
确认显卡是装上的,以及型号确如所想:
[root@bogon ~]# lshw -numeric -C display
*-display
description: VGA compatible controller
product: GP104 [GeForce GTX 1080] [10DE:1B80]
vendor: NVIDIA Corporation [10DE]
physical id: 0
bus info: pci@0000:01:00.0
logical name: /dev/fb0
version: a1
width: 64 bits
clock: 33MHz
capabilities: pm msi pciexpress vga_controller bus_master cap_list rom fb
configuration: depth=32 driver=nouveau latency=0 resolution=3840,2160
resources: irq:31 memory:f6000000-f6ffffff memory:e0000000-efffffff memory:f2000000-f3ffffff ioport:bc00(size=128) memory:c0000-dffff(2)kernel-devel存在
一般来说,这个在/usr/src/kernels下面,按版本号存放,应该是有的。我在AMD的硬件平台上,从来没有遇到不存在的情况;然而在Intel i3的平台上装的时候,确实遇到过,不知道是不是CPU型号较老的关系。
[root@bogon ~]# yum list|grep kernel-devel
kernel-devel.x86_64 4.18.0-513.el8 @baseos
[root@bogon ~]# ls /usr/src/kernels/
4.18.0-513.el8.x86_64无所谓,安装上就行了:
yum install kernel-devel-$(uname -r) kernel-headers-$(uname -r)(3)dkms存在
我也不知道这玩意干啥的,貌似有没有都没有关系。同样是有时候系统自带,有时候不自带,不知道是否和epel-release库的安装有关系。管它有没有都安装一下好了:
yum install epel-release -y
yum install --enablerepo=epel dkms貌似直接yum install epel-release dkms也行。
(4)nouveau不存在
准备完成后检查一下家人们是否都在,以及该走的是不是都走了(应该走了,毕竟界面这么丑):
[root@bogon ~]# lsmod |grep nouveau然后,深吸一口气,行不行的就看这一把了:
3. 安装驱动
[root@bogon ~]# ./NVIDIA-Linux-x86_64-470.199.02.run \
> --no-opengl-files \
> --kernel-source-path=/usr/src/kernels/4.18.0-513.el8.x86_64这一段因为在命令行环境里面,就没有截图了。不过据说no-opengl-files参数是非常必要的,不要一激动直接run了。
如果没问题,会提示是否要register kernel mode source,默认no,所以no;
以及是否32位,默认yes,所以yes。
最后是一个是否要nvidia接管xserver配置的,默认no。
以上最好按照默认的选项选,总之按默认选没问题,不按默认选,出过问题,但是不是非默认的原因,就无法确认了。
安装完成,重启系统。如果是init 3进来的,也可以直接命令行中执行init 5转入图形化系统,安装成功的话,图形界面应该重归美好。如果是更改默认启动配置的,最好先在命令行下使用nvidia-smi测试一下(不要急于回到图形界面中,因为后面还有需要安装的东西):
[root@bogon ~]# nvidia-smi
Sat Sep 9 20:51:53 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.199.02 Driver Version: 470.199.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 On | N/A |
| 45% 38C P8 8W / 200W | 24MiB / 8119MiB | 1% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 61319 G /usr/libexec/Xorg 22MiB |
+-----------------------------------------------------------------------------+4. 安装CUDA Toolkit
(1)Linux中安装
CUDA Toolkit最好也不要从NVIDIA官方给的链接中进入,否则会被导入到最新版本的驱动(535那个)和最新版本的CUDA Toolkit(12)的捆绑包中,这个安装会和我们之前的470安装产生冲突,同样可能是造成黑屏现象的幕后凶手。
从spark-rapids的官方网址进入:On-Prem | spark-rapids
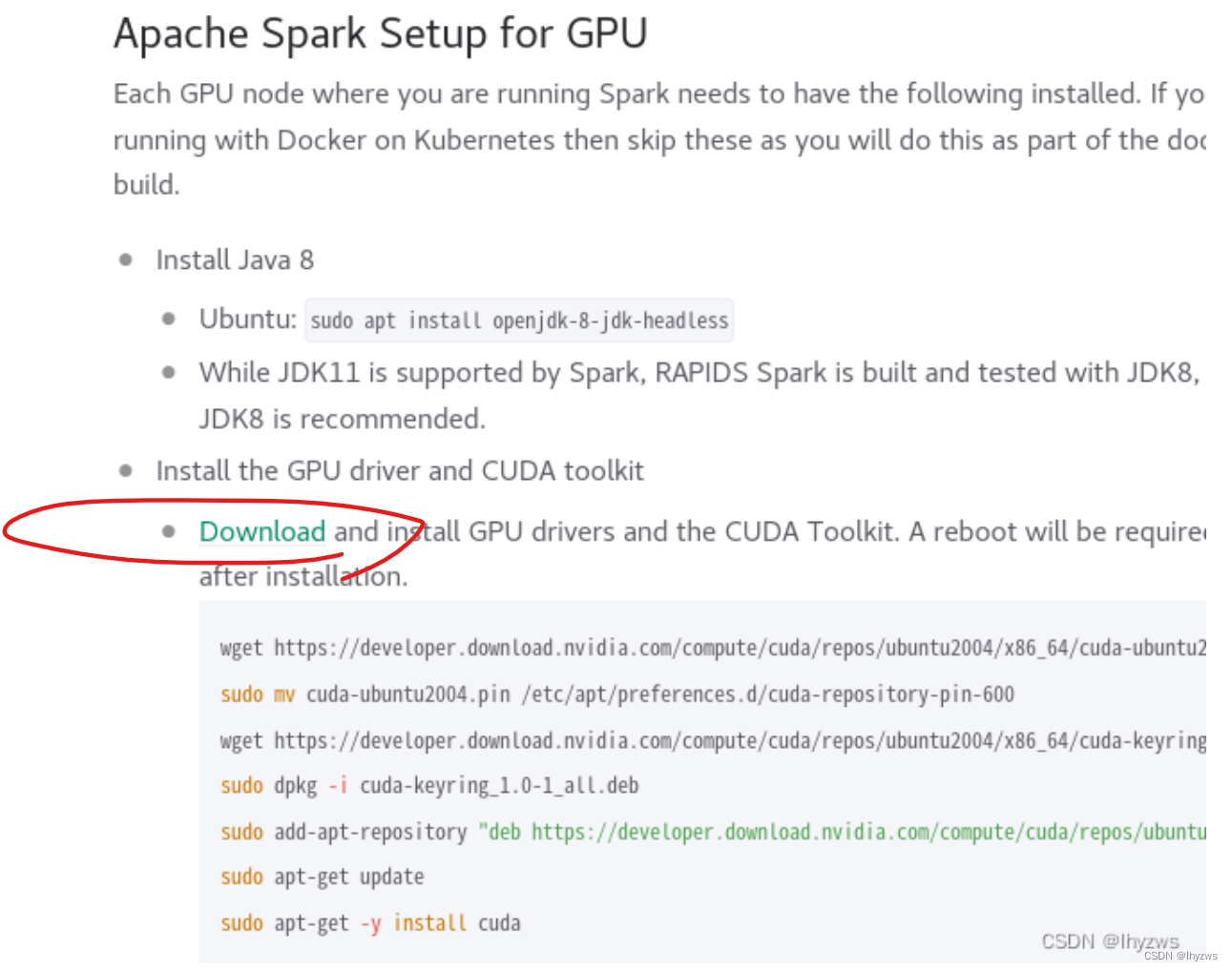
从download进去,实际指向的是11版本(小版本号是11.6),和我们使用nvidia-smi看见的11.4非常接近。
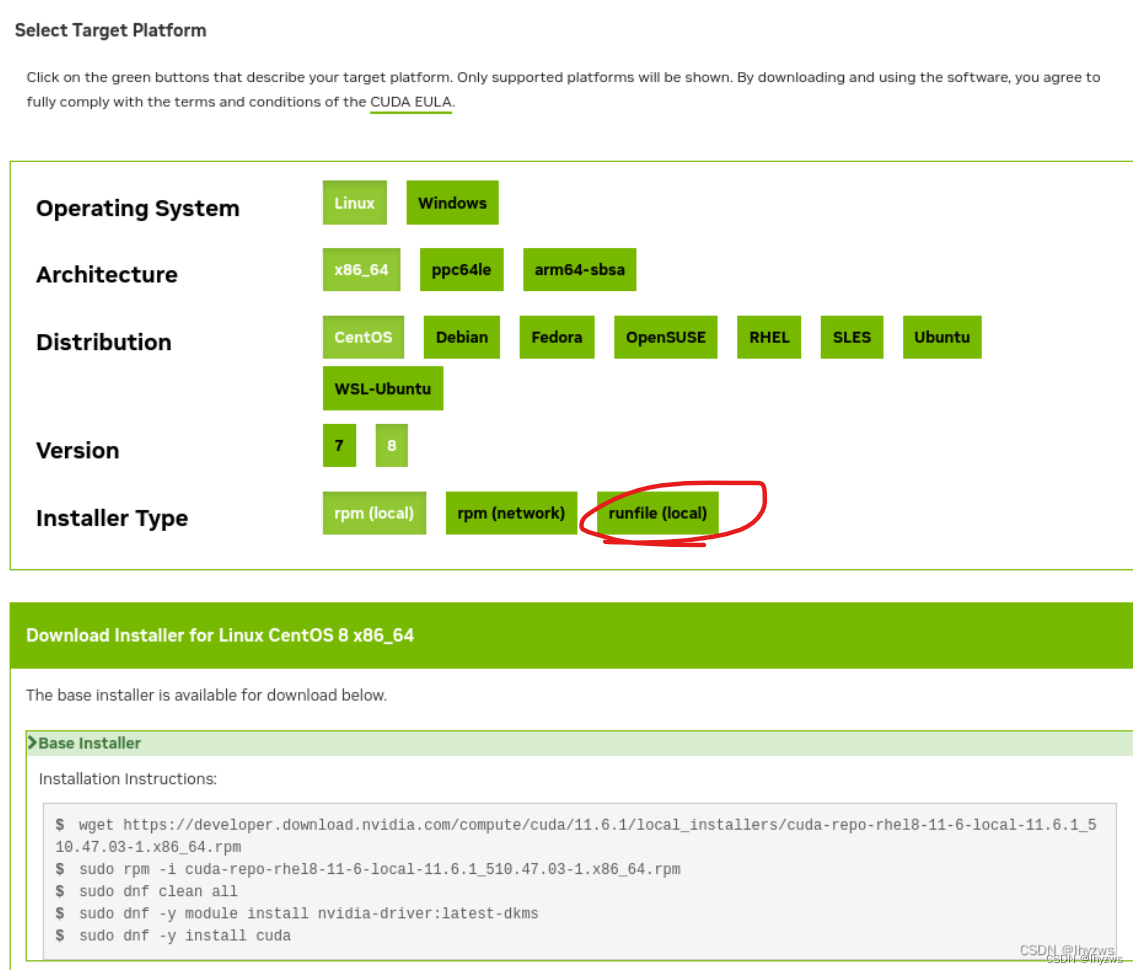
习惯上,我们都会选择rpm。不幸的是,选择rpm按照指示安装,我就没有装成功过。简单的办法,应该仍然是如驱动一般,选择runfile。
同样,更改权限后直接运行。这里,toolkit会给我们一个机会勾掉捆绑的nvidia驱动程序,这样就不会和之前安装好的驱动冲突了。
由于我们采用的是更改默认启动配置的方式,所以toolkit的安装也是在命令行形式下的,这样保险一点。结果就是没有截图了。不过吧,只要勾掉驱动,然后一路默认,貌似就不会发生什么大的问题了。
Toolkit安装完以后,就可以切换回图形界面了。如果这时候nvidia-smi仍然正常,大概率就是都装对了。
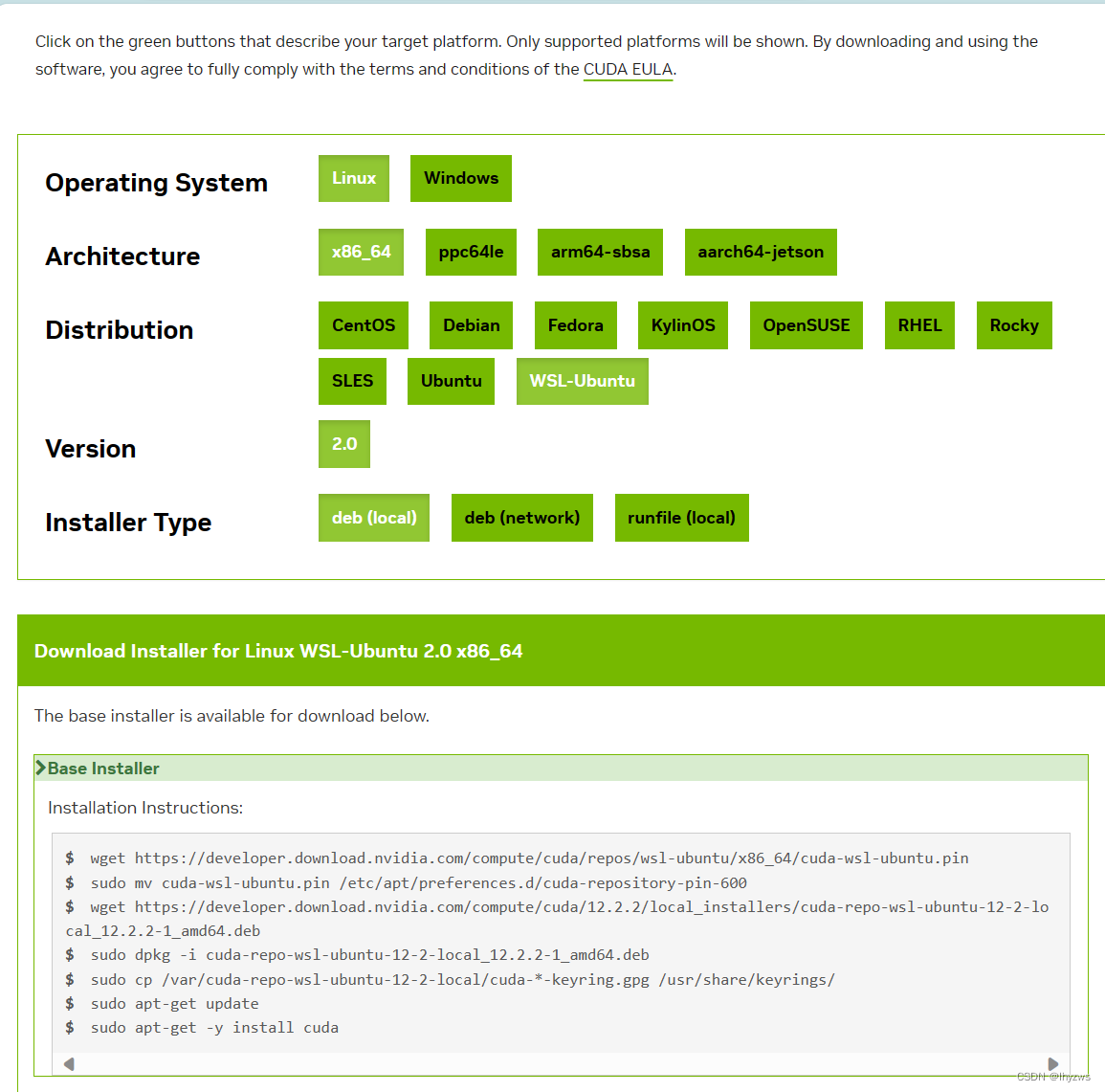
(2)在Windows的WSL上安装
基本还是参考官方的指南,不过这里也有一些误导的链接
1. NVIDIA GPU Accelerated Computing on WSL 2 --- wsl-user-guide 12.2 documentation
实际上,如果主机上已经有了 docker desktop,一般也就有了wsl,而且如果wsl不是wsl2,估计烦也被提示烦死了。
C:\Users\lhyzw>wsl --set-default-version 2
有关与 WSL 2 关键区别的信息,请访问 https://aka.ms/wsl2
操作成功完成。
C:\Users\lhyzw>wsl --version
WSL 版本: 1.2.5.0
内核版本: 5.15.90.1
WSLg 版本: 1.0.51
MSRDC 版本: 1.2.3770
Direct3D 版本: 1.608.2-61064218
DXCore 版本: 10.0.25131.1002-220531-1700.rs-onecore-base2-hyp
Windows 版本: 10.0.22000.2295
C:\Users\lhyzw>wsl -l -v
NAME STATE VERSION
* docker-desktop-data Running 2
docker-desktop Running 2保险起见,还是看看的好,直接设置到版本2。
如果nvidia的驱动安装好了,应该smi也管用;只要smi管用,gpu应该就能在spark中用得上。
如果smi没有,重新安装一下驱动,再不济的,安装一下CUDA toolkit应该也就得了。
C:\Users\lhyzw>nvidia-smi
Sun Sep 10 21:27:28 2023
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 536.67 Driver Version: 536.67 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3070 ... WDDM | 00000000:01:00.0 Off | N/A |
| N/A 38C P8 9W / 140W | 30MiB / 8192MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+从这个地方进去
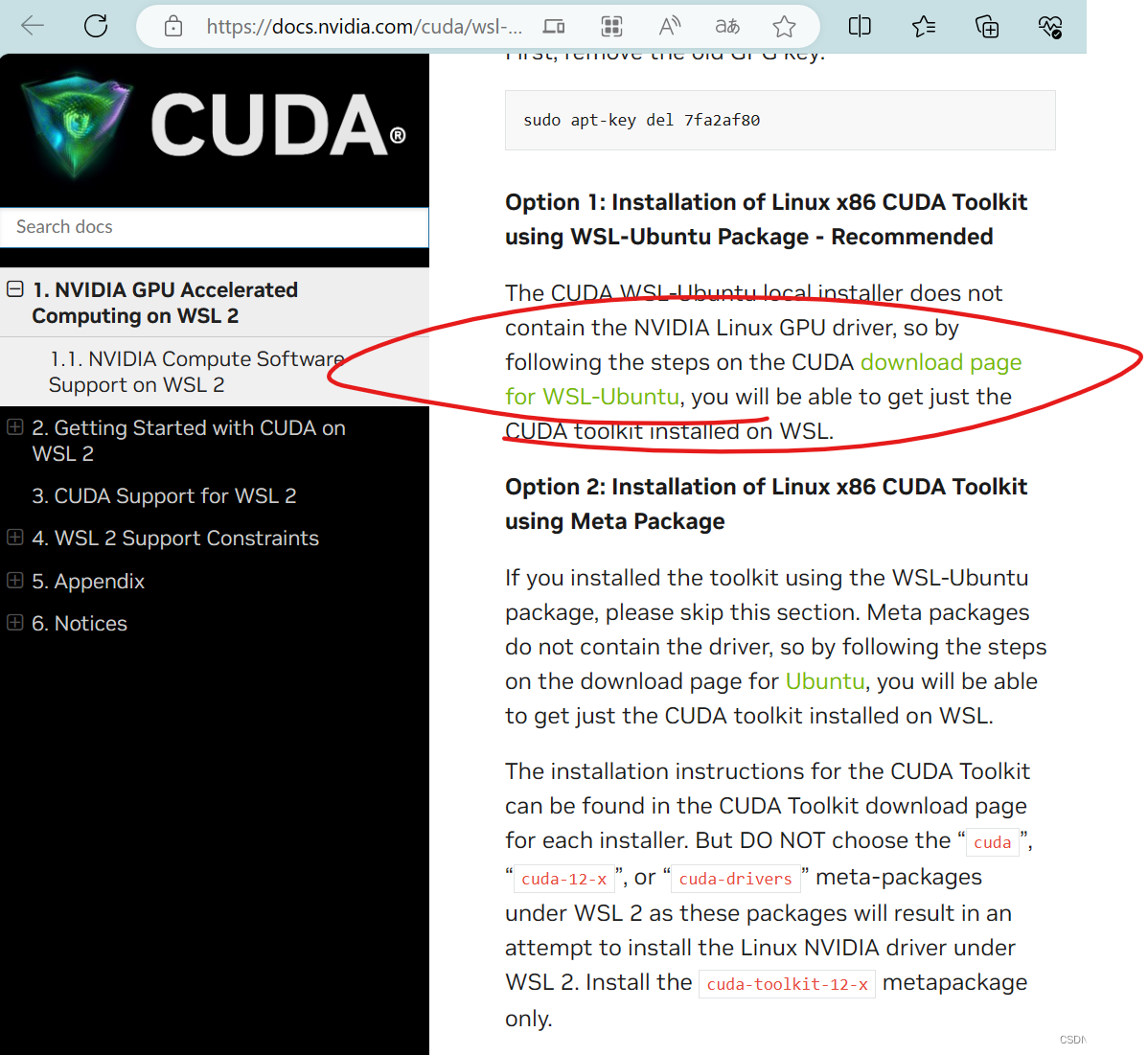 然后在cmd中使用wsl命令进入子系统,在子系统中安装驱动:
然后在cmd中使用wsl命令进入子系统,在子系统中安装驱动:
三、其它工具安装
1. wireshark
wireshark一直都是需要的,顺手也装了。
[root@bogon ~]# yum install wireshark -y
上次元数据过期检查:0:39:34 前,执行于 2023年09月09日 星期六 18时29分42秒。
依赖关系解决。
=========================================================================================================
软件包 架构 版本 仓库 大小
=========================================================================================================
安装:
wireshark x86_64 1:2.6.2-17.el8 appstream 3.6 M
安装依赖关系:
libatomic x86_64 8.5.0-20.el8 baseos 26 k
libsmi x86_64 0.4.8-23.el8 appstream 2.4 M
openal-soft x86_64 1.18.2-7.el8 appstream 394 k
pcre2-utf16 x86_64 10.32-3.el8 baseos 229 k
qt5-qtbase x86_64 5.15.3-5.el8 appstream 3.7 M
qt5-qtbase-common noarch 5.15.3-5.el8 appstream 42 k
qt5-qtbase-gui x86_64 5.15.3-5.el8 appstream 6.2 M
qt5-qtdeclarative x86_64 5.15.3-2.el8 appstream 4.2 M
qt5-qtmultimedia x86_64 5.15.3-1.el8 appstream 882 k
wireshark-cli x86_64 1:2.6.2-17.el8 appstream 17 M
xcb-util-image x86_64 0.4.0-9.el8 appstream 21 k
xcb-util-keysyms x86_64 0.4.0-7.el8 appstream 16 k
xcb-util-renderutil x86_64 0.3.9-10.el8 appstream 19 k
xcb-util-wm x86_64 0.4.1-12.el8 appstream 32 k
事务概要
=========================================================================================================
安装 15 软件包2. docker
[root@bogon ~]# yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
添加仓库自:https://download.docker.com/linux/centos/docker-ce.repo
[root@bogon ~]# yum rm podman buildah
依赖关系解决。
=========================================================================================================
软件包 架构 版本 仓库 大小
=========================================================================================================
移除:
buildah x86_64 1:1.31.3-1.module_el8+664+4072b3ae @appstream 29 M
podman x86_64 3:4.6.1-4.module_el8+664+4072b3ae @appstream 50 M
[root@bogon ~]# yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin -y
Docker CE Stable - x86_64 86 kB/s | 50 kB 00:00
上次元数据过期检查:0:00:01 前,执行于 2023年09月09日 星期六 19时14分05秒。
依赖关系解决。
=========================================================================================================
软件包 架构 版本 仓库 大小
=========================================================================================================
安装:
containerd.io x86_64 1.6.22-3.1.el8 docker-ce-stable 34 M
docker-ce x86_64 3:24.0.6-1.el8 docker-ce-stable 24 M
docker-ce-cli x86_64 1:24.0.6-1.el8 docker-ce-stable 7.2 M
docker-compose-plugin x86_64 2.21.0-1.el8 docker-ce-stable 13 M3. 使用spark测试安装
这篇文章写了一半以后,搁的时间太久远了,久远到我已经把搭建的环境全拆掉以后又一年的地步......所以没有办法截屏了。不过难点已经过去,后面仅仅是需要按照官网给出的方式启动shark-shell而已:

当然,--jars指示的这两个jar包还是要提前下载一下的,然后使用--conf或者config文件将需要启动gpu支持的参数告知spark-shell。
至于如何优化及配置GPU在spark-shell中的资源,是这篇文章被搁置下来的主要原因------使用GPU支持时,常常会因为没有精细控制数据使用规模而导致spark-shell程序崩溃。而对于我的联机分析场景,GPU挂载的情况下,spark-shell的性能也没有比没有GPU的时候好到多明显的地步,所以用了一段事件以后逐渐放弃了......。
不知现在是否有进一步的优化,回头有空再捡吧。
一些我折腾过的优化参数:
--driver-memory 4g : driver内存大小,一般没有广播变量(broadcast)时,设置4g足够,如果有广播变量,视情况而定,可设置6G,8G,12G等均可
--executor-memory 4g : 每个executor的内存,正常情况下是4g足够,但有时处理大批量数据时容易内存不足,再多申请一点,如6G
--num-executors 15 : 总共申请的executor数目,普通任务十几个或者几十个足够了,若是处理海量数据如百G上T的数据时可以申请多一些,100,200等
--executor-cores 2 : 每个executor内的核数,即每个executor中的任务task数目,此处设置为2,即2个task共享上面设置的6g内存,每个map或reduce任务的并行度是executor数目*executor中的任务数
yarn集群中一般有资源申请上限,如,executor-memory*num-executors < 400G 等,所以调试参数时要注意这一点
----spark.default.parallelism 200 : Spark作业的默认为500~1000个比较合适,如果不设置,spark会根据底层HDFS的block数量设置task的数量,这样会导致并行度偏少,资源利用不充分。该参数设为num-executors * executor-cores的2~3倍比较合适。
-- spark.storage.memoryFraction 0.6 : 设置RDD持久化数据在Executor内存中能占的最大比例。默认值是0.6
----spark.shuffle.memoryFraction 0.2 : 设置shuffle过程中一个task拉取到上个stage的task的输出后,进行聚合操作时能够使用的Executor内存的比例,默认是0.2,如果shuffle聚合时使用的内存超出了这个20%的限制,多余数据会被溢写到磁盘文件中去,降低shuffle性能
----spark.yarn.executor.memoryOverhead 1G : executor执行的时候,用的内存可能会超过executor-memory,所以会为executor额外预留一部分内存,spark.yarn.executor.memoryOverhead即代表这部分内存