文章目录
- 前言
- 1、img2pdf库的使用
-
- [1.1 安装img2pdf库](#1.1 安装img2pdf库)
- [1.2 案例演示(模板代码)](#1.2 案例演示(模板代码))
- 2、Pillow库的使用
-
- [2.1 pillow库的安装](#2.1 pillow库的安装)
- [2.2 案例演示(模板代码)](#2.2 案例演示(模板代码))
- 3、PyMuPDF库的使用
-
- [3.1 安装pymupdf库](#3.1 安装pymupdf库)
- [3.2 案例演示(模板代码)](#3.2 案例演示(模板代码))
- [3.3 扩展:将多张图片完美拼接到一张pdf页面上,没有间隙](#3.3 扩展:将多张图片完美拼接到一张pdf页面上,没有间隙)
前言
在python中将图片转换为pdf格式的方法有多种,每种方法依赖于不同的库和工具,本篇文章我将介绍三种常用的库,包括
img2pdf 库 和 pillow库、PyMuPDF(fitz)库,下面我将通过实际案例教会大家如何使用这三种库,同时针对每一种库不同的转换方法,准备相应的模板代码,让新手小白也能轻松驾驭。
图片准备: 可以看到我在下面准备了4张图片,后续案例中使用的都是这4张图片
1、img2pdf库的使用
在Python中,img2pdf 是一个方便的库,用于将图片转换为 PDF 格式。它基于 Pillow(PIL 的一个分支)库,并提供了一个简单的接口来完成图片到 PDF 的转换。
1.1 安装img2pdf库
命令:
pip install img2pdf
1.2 案例演示(模板代码)
案例演示:
python
# 1、导入模块
from img2pdf import convert
# 2、准备图片路径列表,将需要转换的图片路径全部放进一个列表中,若只有一张图片,同样也将其路径放入列表中即可
image_paths = ['all_images/01.png', 'all_images/02.png', 'all_images/03.png','all_images/04.png']
# 3、使用convert函数将图片文件列表转换为 PDF,这里我们直接传递图片文件路径的列表
pdf_bytes = convert(image_paths)
# 注意:convert 函数只能接受一个图片文件对象的列表,或者一个包含图片文件路径的列表
# 3、将转换后的图片,保存到指定路径下的pdf文件中
with open('output.pdf', 'wb') as pdf_file:
pdf_file.write(pdf_bytes)
print("PDF 文件已成功创建!")执行效果:

说明:
我们可以看到,img2pdf库的使用是非常简单的,它会将每张图片作为 PDF 文件中的一个独立页面进行添加,有多少张图片就会生成多上张pdf页面
2、Pillow库的使用
通过 Pillow 库,你可以轻松地将单张或多张图片转换为 PDF 格式。这种方法简单高效,适合大多数图片转 PDF 的需求。如果需要更复杂的 PDF 操作(如添加文本、表格等),可以考虑结合 reportlab 库使用,这里我就不详细说明了,大家可以自行扩展。
2.1 pillow库的安装
命令:
pip install Pillow
2.2 案例演示(模板代码)
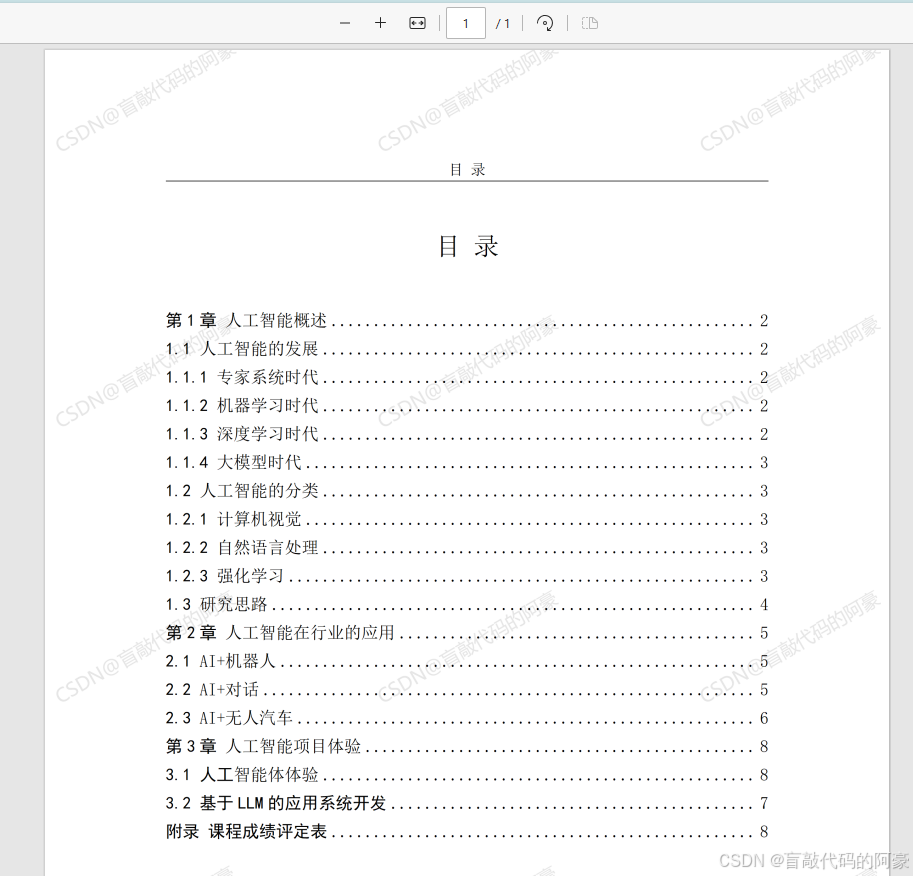
案例1:将单张图片转换为 PDF
python
# 1、导入模块
from PIL import Image
# 2、准备图片路径
image_path = 'all_images/01.png'
# 3、准备输出的 PDF 路径
output_pdf_path = 'output.pdf'
# 4、打开图片,生成图片对象
image = Image.open(image_path)
# 5、将图片转换为pdf格式,并保存至指定路径
image.save(output_pdf_path, "PDF", resolution=100)
'''
参数说明:
参数1:保存路径
参数2:保存格式
参数3:resolution,该参数用于设置pdf的分辨率,不写默认为75
'''
print(f"图片已成功转换为 PDF: {output_pdf_path}")执行效果:
案例2:将多张图片合并为一个 PDF
python
# 1、导入模块
from PIL import Image
# 2、准备图片路径列表
image_paths = ['all_images/01.png', 'all_images/02.png', 'all_images/03.png','all_images/04.png']
# 3、准备输出的 PDF 路径
output_pdf_path = 'output.pdf'
# 4、打开所有图片并使用convert函数将其转换为 RGB 模式,最后全部存入images列表中
images = [Image.open(image).convert('RGB') for image in image_paths]
# 因为pdf需要RGB格式,所以这里需要将其进行转换
# 5、将第一张图片保存为 PDF,并追加其他图片
images[0].save(output_pdf_path, save_all=True, append_images=images[1:]) # 先将第一张图片保存为pdf文件,在通过append_images参数将剩余的图片追加进去
'''
参数说明:
参数1:保存路径
参数2:save_all=True,表示将所有图片都存入一个pdf文件中
参数3:append_images=图片对象列表,指定要追加的图片对象列表
'''
print(f"多张图片已成功合并为 PDF: {output_pdf_path}")执行效果:

说明:
通过上面的案例,我们很轻松的通过pillow库将图片转换为了pdf格式,其中参数的使用也非常简单,但大家可能会对 resolution 参数 抱有疑问,接下来我将针对该参数为大家进行详细说明,如下:
在使用 Pillow 库将图片转换为 PDF 格式时,resolution 参数用于指定输出 PDF 的分辨率(DPI,Dots Per Inch)。分辨率决定了图片在 PDF 中的清晰度和尺寸。
resolution 参数的作用
-
控制图片的清晰度:
分辨率越高,图片在 PDF 中显示的细节越清晰。
分辨率越低,图片可能会显得模糊或像素化。
-
影响图片的尺寸:
分辨率越高,图片在 PDF 中显示的尺寸越小(因为每英寸的像素点更多)。
分辨率越低,图片在 PDF 中显示的尺寸越大。
-
默认值:
如果未指定 resolution 参数,Pillow 会使用默认的分辨率(通常是 72 DPI)。
注意事项
-
图片质量:
分辨率不会改变原始图片的像素数据,但会影响其在 PDF 中的显示效果。
如果原始图片的分辨率较低,即使设置高 resolution 参数,也无法提高其清晰度。
-
文件大小:
分辨率越高,生成的 PDF 文件可能越大。
-
默认分辨率:
如果不指定 resolution 参数,Pillow 会使用默认的 72 DPI。
总结
resolution 参数用于控制图片在 PDF 中的清晰度和显示尺寸。通过调整分辨率,可以优化 PDF 的显示效果,适应不同的需求(如打印或屏幕查看)。在实际使用中,建议根据具体场景选择合适的分辨率值。
3、PyMuPDF库的使用
PyMuPDF(fitz)库提供了强大的PDF和图像处理能力,它是一个强大的PDF处理库,它允许你读取、修改和创建PDF文件。它也支持从图片创建PDF。
3.1 安装pymupdf库
命令:
pip install pymupdf
3.2 案例演示(模板代码)
案例1:将一张图片转换为pdf格式
方法1:
python
# 1、导入模块
import fitz
# 2、打开一个新的PDF文档
pdf_document = fitz.open()
# 3、加载图像文件,生成图片对象
image_file = fitz.open('all_images/01.png') # 替换为需要转换的图片路径
# 4、使用convert_to_pdf函数将图片文件对象转换为pdf格式
image_pdf = image_file.convert_to_pdf()
# 5、以pdf格式打开转换后的图像,生成pdf对象
pdf = fitz.open('pdf', image_pdf)
# 6、向pdf文档中插入pdf对象
pdf_document.insert_pdf(pdf)
# 7、将PDF文档保存至指定路径
pdf_document.save('output.pdf') # 替换为你想要保存的PDF路径
# 8、关闭图片文件和pdf文档,这两步默认可不写,但为了代码规范,我们可以加上
image_file.close()
pdf_document.close()
print('图片已转换为pdf文档!')执行效果:

方法2:
python
# 1、导入模块
import fitz
# 2、打开一个新的PDF文档
pdf_document = fitz.open()
# 3、加载图像文件
image_file = fitz.open('all_images/01.png') # 替换为你的图像路径
# 4、加载图像所在的页面(通常是第一页),一般图片只有一页
image_page = image_file.load_page(0)
# 5、获取图像的矩形区域(尺寸和位置,但这里我们可能只关心尺寸)
image_rect = image_page.rect
print(image_rect) # 返回 Rect(0.0, 0.0, 595.25, 841.75),前两个数字代表图片左上角的坐标,后两个数字代表图片右下角的坐标,同时也是图片的宽度和高度
'''
方法说明:根据下面看两种方法可以得到图片宽度和高度
1、image_rect.width:获取图片的宽度,595.25
2、image_rect.height:获取图片的宽度,841.75
'''
# 6、创建一个新的PDF页面,这里我们指定其尺寸与图像相同(或根据需要调整)
pdf_page = pdf_document.new_page(width=image_rect.width, height=image_rect.height)
'''
参数说明:
参数1:width,指定pdf页面的宽度
参数2:height:指定pdf页面的高度
'''
# 7、在PDF页面上插入图像
# 注意:这里我们假设图像应该覆盖整个页面,因此使用pdf_page.rect作为插入区域
pdf_page.insert_image(rect=pdf_page.rect, filename='all_images/01.png', stream=None)
'''
参数说明:
参数1:rect= ,指定图片插入的位置,通常为pdf页面的矩形区域,也可以是图片的矩形区域,这里两者相同
参数2:filename = 图片路径,指定要插入的图片
参数3:stream=None,默认参数,表示允许指定图片以二进制格式插入pdf文档中
'''
# 8、保存PDF文档
pdf_document.save('output.pdf')
# 9、关闭图像文件和pdf文档,默认可不写,这里为了代码规范,我们可以写上
image_file.close()
pdf_document.close()
print('图片已转换为了pdf文档!')执行效果:

案例2:将多张图片转换为pdf文档
python
# 1、导入模块
import fitz
def images_to_pdf(image_paths, output_pdf):
# 创建一个新的 PDF 文档
pdf_document = fitz.open()
# 遍历每一个图片路径
for image_path in image_paths:
# 打开图像文件,生成图片对象
img = fitz.open(image_path)
# 选择图片的第一页,生成矩形区域,用于获取图片的尺寸
img_page = img.load_page(0).rect
# 生成一张与图片大小相同的空白pdf页面
pdf_page = pdf_document.new_page(width=img_page.width, height=img_page.height) # 根据图像大小设置页面尺寸
# 将图像插入到 PDF 页面的指定位置(这里插入到页面的左上角)
# 注意:如果图像大小与页面大小不匹配,可能需要调整 rect 参数以进行裁剪或缩放
pdf_page.insert_image(rect=fitz.Rect(0, 0, pdf_page.rect.width, pdf_page.rect.height), filename=image_path,
stream=None)
'''
说明:
rect = fitz.Rect(0, 0, pdf_page.rect.width, pdf_page.rect.height)
# 通过fitz.Rect方法可以手动调节图片插入的位置,前两个数字为图片左上角的坐标,后两个数字为图片右下角的坐标,这里就是pdf页面的宽度和高度
'''
# 关闭图像文件(对于 pymupdf,这通常是自动处理的,但显式关闭是个好习惯)
img.close()
# 保存 PDF 文档
pdf_document.save(output_pdf)
# 关闭 PDF 文档(对于 pymupdf,这也通常是自动处理的,但显式关闭可以避免潜在的资源泄露)
pdf_document.close()
# 2、准备图片路径列表
image_paths = ['all_images/01.png', 'all_images/02.png', 'all_images/03.png','all_images/04.png'] # 替换为要转换的图片路径
# 3、替换为你想要输出的 PDF 文件名
output_pdf = 'output.pdf'
# 4、调用函数,并传入参数
images_to_pdf(image_paths, output_pdf)执行效果:

3.3 扩展:将多张图片完美拼接到一张pdf页面上,没有间隙
通过前面的学习,我们已经掌握了三种将图片转换为pdf格式的方法,这三种方法都有一个共同点,它们会将每一张图片单独生成一张pdf页面,有多少张图片就会有多少张pdf页面,且每张pdf页面间都会有一段空白的填充区来分隔每张pdf页面,但是有时我们需要将多张连贯的图片转换为pdf格式,这时若按照原来的方法操作,每张图片间就会出现空白部分,影响观感,所以接下来我会依照这个问题,给出解决方法。
问题演示

解决方法(模板代码)
python
# 1、导入模块
import fitz
def images_to_single_pdf_page(image_paths, output_pdf):
# 打开一个新的PDF文档
pdf_document = fitz.open()
# 初始化pdf页面总高度和最大宽度
total_height = 0
max_width = 0
# 遍历所有图片文件以计算总高度和最大宽度(垂直拼接)
for img_file in image_paths:
# 打开图片文件,生成图片对象
img_document = fitz.open(img_file)
# 选择图片的第1页,一般图片都只有1页
img_page = img_document.load_page(0)
# 得到图片的矩形区域,用于获取图片的尺寸
img_rect = img_page.rect
# 获取图片的宽度和高度
img_width, img_height = img_rect.width, img_rect.height
# 累加高度并更新最大宽度
total_height += img_height
if img_width > max_width:
max_width = img_width
# 关闭图片文档
img_document.close()
# 创建一个新的PDF页面,大小足以容纳所有图片
pdf_page = pdf_document.new_page(width=max_width, height=total_height)
# 初始化当前y位置,用于定义图片左上角的坐标
current_y = 0
# 初始化图片高度,用于定义图片右下角的坐标
point_height = 0
# 遍历所有图片文件并在PDF页面上绘制它们,不留空白
for img_file in image_paths:
# 打开图片文件,生成图片对象
img_document = fitz.open(img_file)
# 指定图片第一页,并形成矩形区域
img_page = img_document.load_page(0).rect
# 累加高度
point_height += img_page.height
# 在PDF页面上绘制图片(紧密排列,不留空白)
pdf_page.insert_image(rect=fitz.Rect(0,current_y, img_page.width, point_height),filename=img_file, stream=None)
'''
说明:
这里通过改变current_y 和 point_height 使图片依次垂直拼接在一张pdf页面上
(0,current_y):表示每张图片插入pdf页面左上角的坐标
(img_page.width, point_height):表示每张图片插入pdf右下角的坐标
'''
# 更新当前y位置以放置下一张图片(直接跳到下一张图片的起始位置)
current_y += img_page.height
# 关闭图片文档
img_document.close()
# 保存PDF文档至指定位置
pdf_document.save(output_pdf)
# 关闭PDF文档
pdf_document.close()
# 2、准备好图片路径列表
image_paths = ['all_images/01.png', 'all_images/02.png', 'all_images/03.png','all_images/04.png'] # 替换为要转换的图片路径
# 3、替换为你想要输出的PDF文件路径
output_pdf = "output_all.pdf"
# 4、调用函数,传入参数
images_to_single_pdf_page(image_paths, output_pdf)
print('所有图片已全部拼接至一张pdf页面上!!!')执行效果:

说明:
从上面我们可以看到,所有图片在转换为pdf格式后,全部拼接在了一张pdf页面上,且每张图片间没有空隙。