外面,阳光明媚,一切正好。
就在我欢天喜地准备迎来愉快的双休时,忽然之间,天塌了。
刚上线一小时的服务内存异常OOM了!
老实说,在我印象里OOM问题只存在于网上案例中,练习编码时常两年半,还是第一次遇到。不过既然遇到了,那就要尽快排查问题并解决掉,不然真要和群里大哥说的一样:要领盒饭了。
问题
下午两点新版本上线,其中一个消费者服务的内存增长速度异常迅速,在短短五分钟内就用完了2G内存并自动重启了pod,之后又在五分钟内OOM了,在四十分钟内服务的pod已经重启了八十几次,要知道我们之前这个消费者服务正常运行时候只用了不到500M。
分析
首先进行初步分析,这是一个消费者服务并且新版本的需求中并没有新增消费topic,并且业务量也没有大的波动,不存在是业务访问量骤增导致OOM,所以极大概率会是代码问题。当然,每一个版本的新代码都非常多,需求也比较庞杂,直接去看代码肯定是不行的,这时候就要麻烦部门的运维大佬了,让他给我们dump一下,给出一个内存溢出时的性能记录文件,通过这个文件可以分析内存分配、线程创建、CPU使用、阻塞、程序详细跟踪信息等。
我这里使用的Go语言开发,一般用pprof文件进行分析,运维给出的文件有以下6个:
- main-1-trace-1227152939.pprof:记录程序执行的详细跟踪信息,包括函数调用、Goroutine 的创建和调度等
- main-1-threadcreate-1227152939.pprof:记录线程创建的剖析数据,帮助分析线程创建的频率和开销。
- main-1-mutex-1227152939.pprof:记录互斥锁(mutex)的使用情况,帮助分析锁竞争和锁等待的开销。
- main-1-mem-1227152939.pprof:记录内存分配的剖析数据,帮助分析内存使用的热点和分配情况。
- main-1-cpu-1227152939.pprof:记录 CPU 使用的剖析数据,帮助分析 CPU 时间的消耗情况。
- main-1-block-1227152939.pprof:记录阻塞操作的剖析数据,帮助分析阻塞操作的频率和开销。
内存OOM,那最重要的当然是mem文件,也就是内存分配剖析数据,不过很不幸,服务重启速度太快了,运维大佬dump的时候正好处于服务刚重启的时候,所以mem文件中显示的内存才占用不到20M,并且占比上也没看出有什么问题。想让运维再帮忙dump一下内存快要OOM的时候,但是为了线上服务的稳定性版本已经回退了,无法重新dump,只能从其他几个文件中查找问题了。

除了内存占用分析,在性能问题分析中CPU占用分析也是极为重要的一环,这一查看就有意思了,CPU总的使用率虽然不高,但是这个占比就比较奇怪了。第一占比的runtime.step是Go的运行时系统负责管理内存分配、垃圾回收、调度goroutine等底层操作,这个暂且不管,占比第二的居然是runtime.selectgo,这个就非常诡异了,select一般用于channel的非阻塞调用,但是问题是新增代码中没有地方显示地调用了select,那可以初步判断是底层源码中某处一直在调用select函数,不过目前还不知道是谁触发的这个调用,还需要继续查看其他文件。
之后继续查看互斥锁的情况,其实这个文件在目前这种情况下排查的价值已经不大了,因为出现问题的是内存溢出而不是CPU占用率,并且CPU占用率确实不是很高,而且Go中是有检索死锁的机制,大部分死锁是能够被Go发现并报一个deadlock错误,打开文件之后发现果然没有死锁发生。
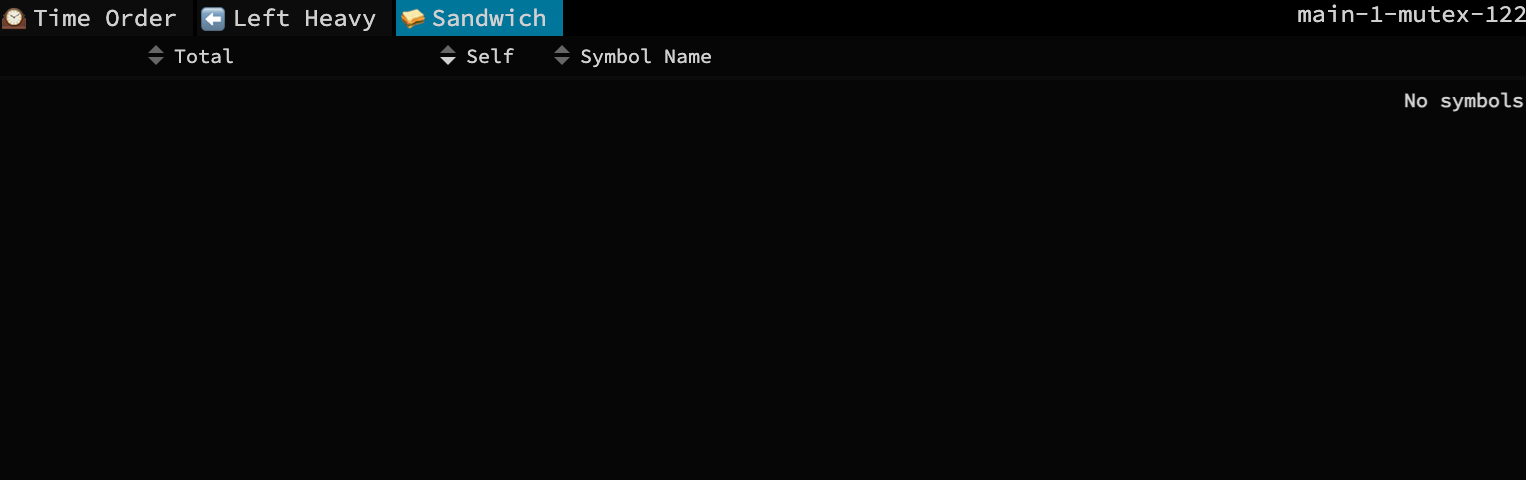
接下来查看阻塞操作的分析情况,从解析结果中可以看出,select的阻塞时间遥遥领先,select出现这种情况只会是存在case但是没有default的时候,当所有case不符合的时候,负责这个select的goroutine会阻塞住直到存在符合的case出现才会唤醒继续走下去,当时我看到这我满脑子问号,谁家好人select不加default啊?
再查看线程创建情况,由于pod刚启动不久,所以这个文件也看不出什么东西,很正常的线程创建。

看到这里还是没能定位到问题所在,但是别急,我们还有最重要的文件还没看,那就是trace文件,它可以记录程序执行的详细跟踪信息,包括函数调用、Goroutine 的创建和调度,使用go自带的pprof分析工具打开trace文件
bash
go tool trace main-1-trace-1227102939.pprof会出现以下本地页面:
在Goroutine分析中,可以锁定真正的问题所在了,在go-zero的core包下的collection文件在不到一秒内创建了两万多的Goroutine,虽然两万多数量不多,但是这个速度十分异常,最重要的是这个定时轮就很奇怪,这个项目中根本没有定时任务,接下来就很容易查询了,只要查找这次提交的代码中哪里使用到了collection包。
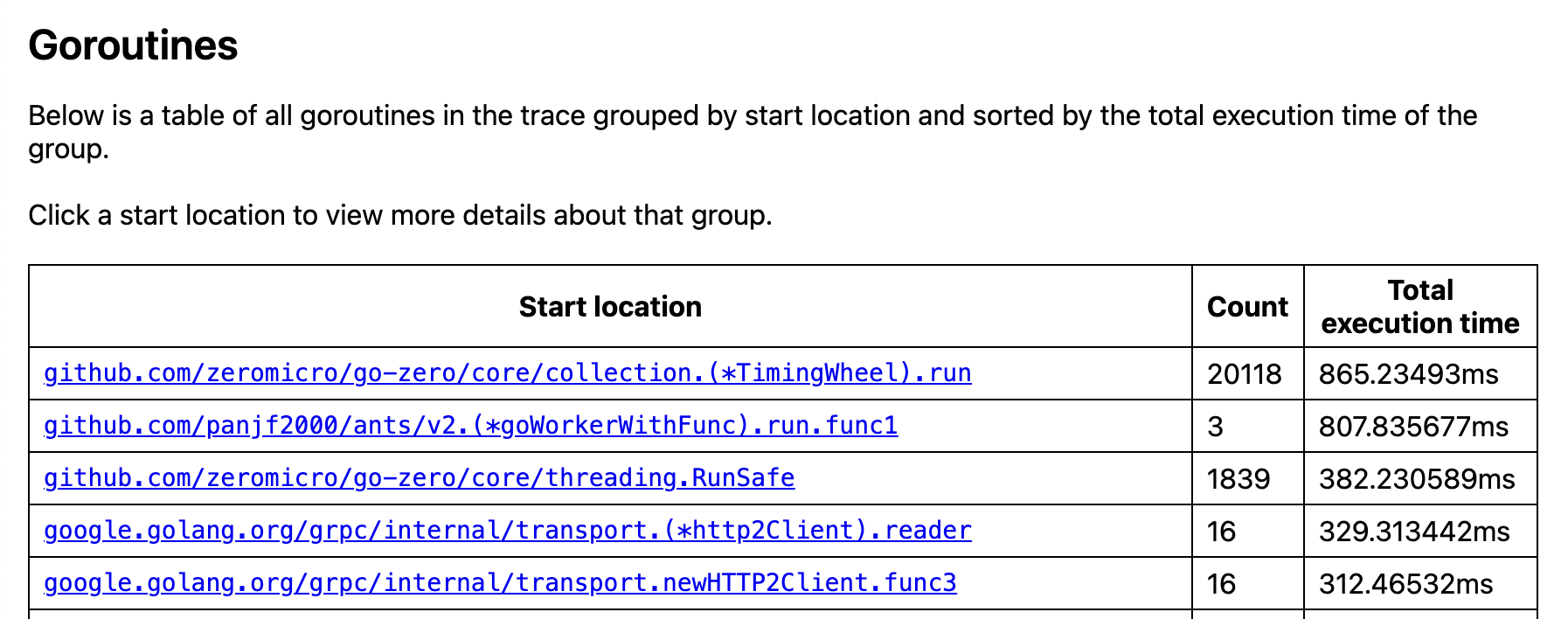
经过一番全局搜索后,最终确定了问题代码:
go
func NewXXXLogic(svcCtx *svc.ServiceContext, ctx context.Context) *XXXLogic {
cache, _ := collection.NewCache(30 * time.Second)
return &XXXLogic{
Logger: logx.WithContext(ctx),
svcCtx: svcCtx,
ctx: ctx,
localCache: cache,
}
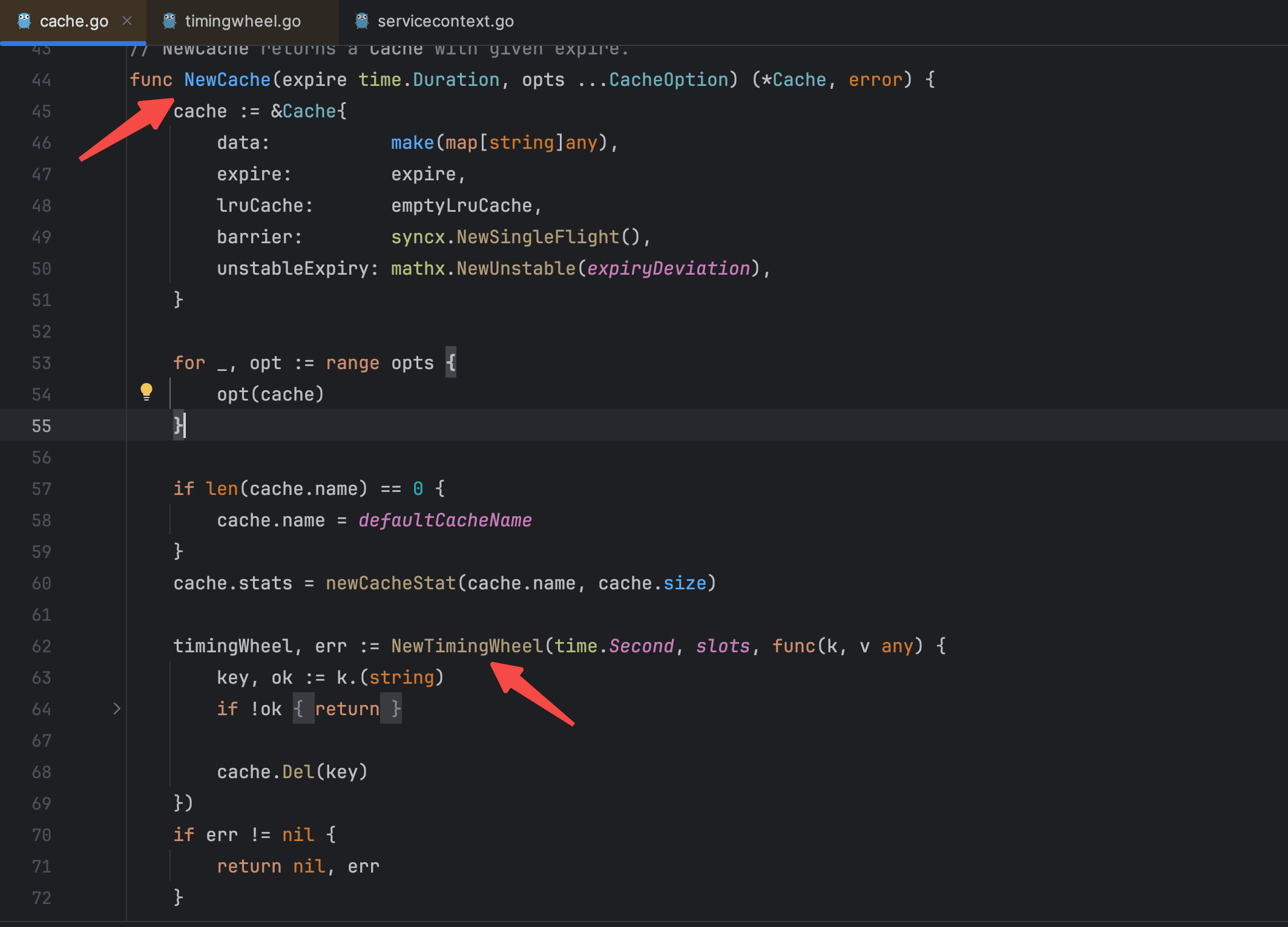
}在新上线的版本中只有这一处用到了collection包,原本这里的意思是将建立一个缓存放到上下文中去传递,但是乍一看我没有看出有什么问题,过期时间也设置了,按照我原有理解过期时间到了就会自动释放掉,为什么还是会内存溢出了?但是我忽然意识到应该不是缓存引发的内存溢出,可能是协程过多引发的内存溢出,因为一个初始协程是2KB左右,如果数量过多也会造成内存不够。
为了探究根本原因,我点进了collection包的源码进行查看,在其中NewCache()方法中找到了造成协程数异常增加的定时轮创建方法NewTimingWheel()。
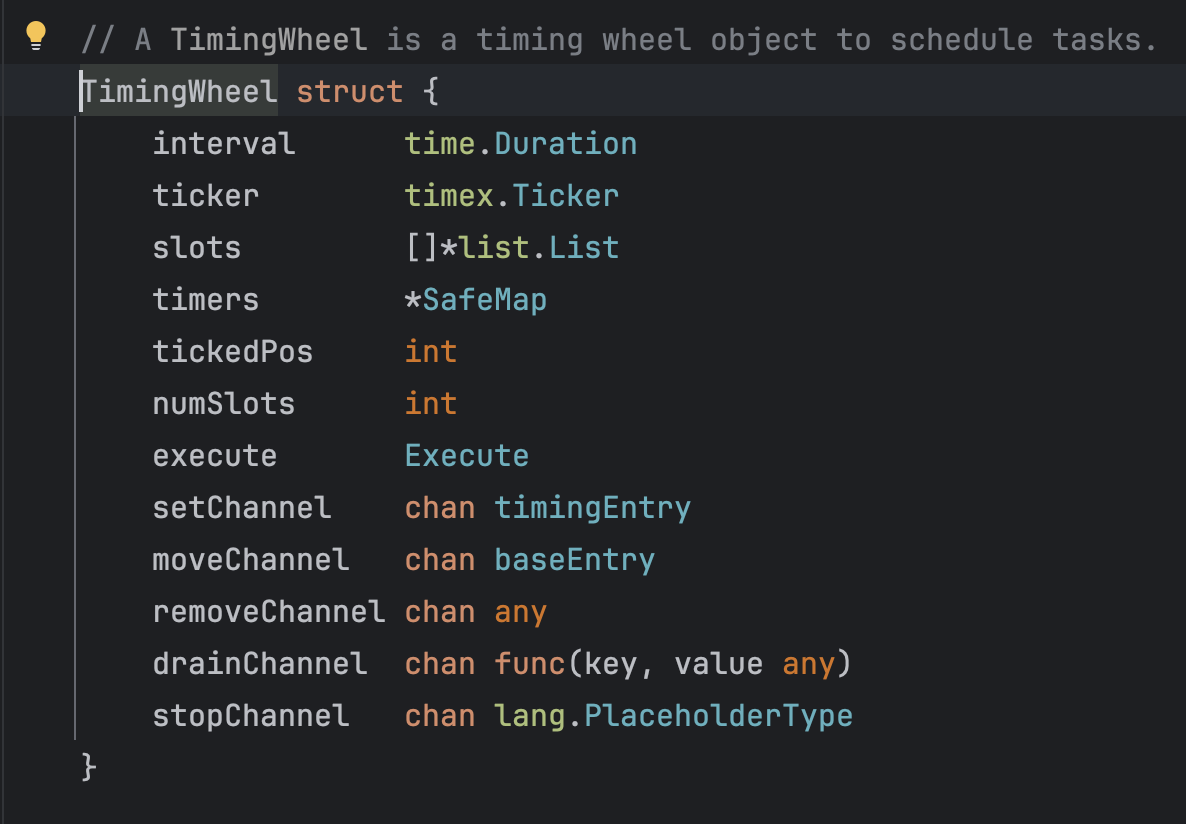
之后点进去这个方法进一步查看,可以看到这个定时轮的结构体,里面包含了四个channel以及一些其他数据结构,粗略估计这一个TimingWheel结构体所占内存要达到一百字节以上,这是一个比较庞大的对象,如果无限制的创建下去很容易造成内存OOM发生。
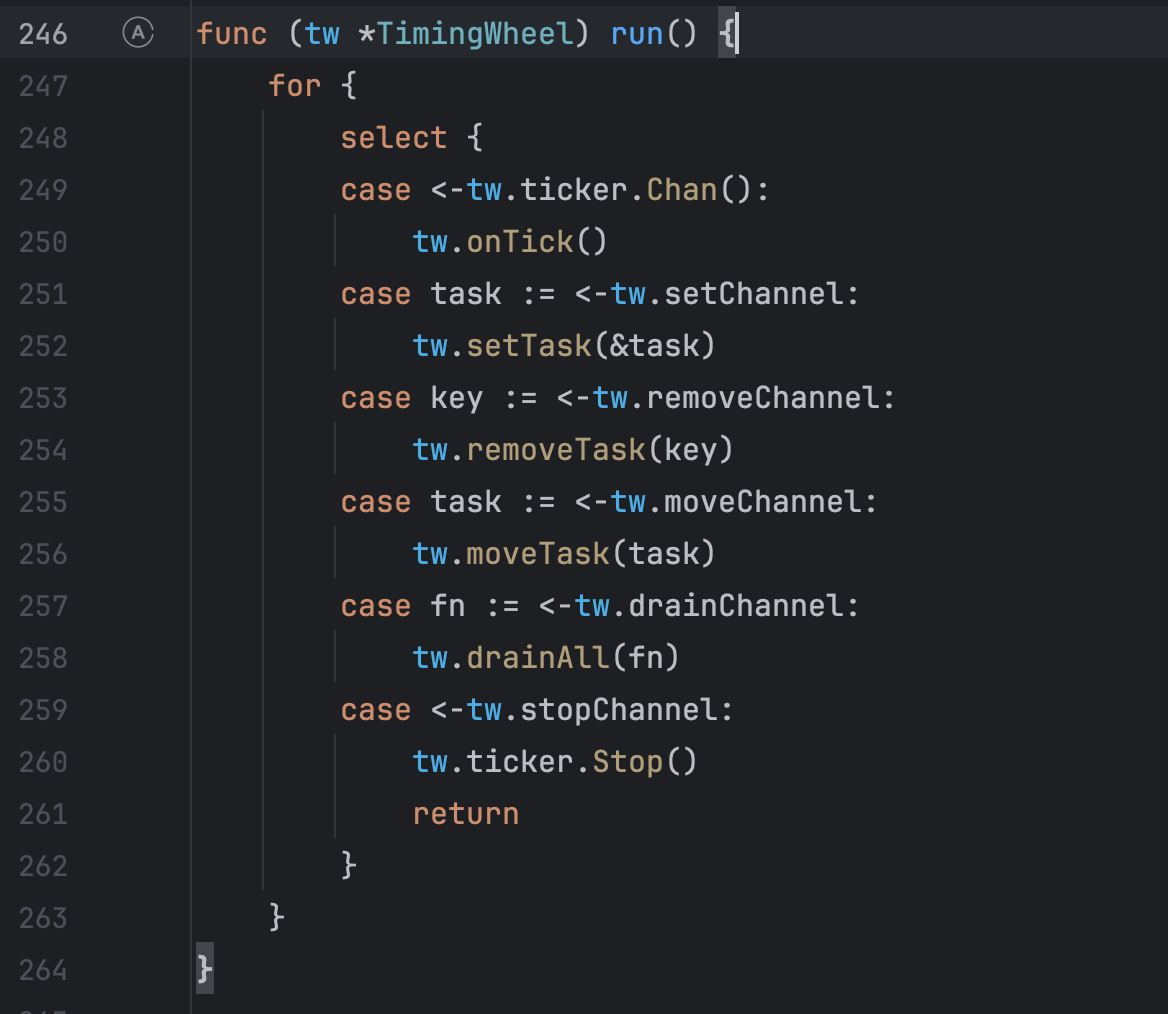
但是这个定时轮为什么会创建那么多呢?为什么不会关闭,按理说go-zero的源码不应该会有这么大的漏洞,继续查看这个定时轮的run()方法,终于发现了问题所在,这个定时轮中开启了select方法,并且没有default方法,所以之前阻塞文件那里才会显示select阻塞时间占比达到了99%,并且唯一关闭这个定时轮的方法是接收到tw.ticker.Stop()才会停止,那么这个stop方法会在什么时候调用呢?
答案是会在程序停止运行的时候进行调用。所以如果程序仍在运行,就会有无限制的协程创建定时轮,这时候定时轮因为无法关闭所以协程也不会进行销毁,有点类似于守护线程,所以在协程无限制的创建下最终导致了线上内存OOM了。
解决
那是不是说明go-zero的这块源码存在问题?其实不是的,是我们使用方法错误,正确的使用方法不应该将缓存创建在上下文中,而应该创建一个全局缓存,让所有的上下文都公用这一个缓存,这样就不会发生定时轮无限创建的问题。
后续将这块缓存放到了全局中,之后再重新发布观察了一小时左右,服务内存稳定在了500M以下,与以往服务消耗内存几乎一致。
历时两小时战斗,终于免于"领盒饭"了。
下班!