测试环境
prometheus-2.26.0.linux-amd64.tar.gz
prometheus-2.54.1.linux-amd64.tar.gz
CentOS 7.9
下载并运行Prometheus
shell
# wget https://github.com/prometheus/prometheus/releases/download/v2.26.0/prometheus-2.26.0.linux-amd64.tar.gz
# tar xvzf prometheus-2.26.0.linux-amd64.tar.gz
# cd prometheus-2.26.0.linux-amd64
# ls
console_libraries consoles LICENSE NOTICE prometheus prometheus.yml promtool开始运行之前,先对它进行配置。
配置Prometheus自身监控
Prometheus通过抓取度量HTTP端点来从目标收集指标。由于Prometheus以同样的方式暴露自己的数据,它也可以搜集和监控自己的健康状况。
虽然只收集自身数据的Prometheus服务器不是很有用,但它是一个很好的开始示例。保存以下Prometheus基础配置到一个名为prometheus.yml的文件(安装包自动解压后,解压目录下,默认就就有一个名为prometheus.yml的文件)
yaml
global:
scrape_interval: 15s # 默认,每15秒采样一次目标
# 与其它外部系统(比如federation, remote storage, Alertmanager)交互时,会附加这些标签到时序数据或者报警
external_labels:
monitor: 'codelab-monitor'
# 一份采样配置仅包含一个 endpoint 来做采样
# 下面是 Prometheus 本身的endpoint:
scrape_configs:
# job_name 将被被当作一个标签 `job=<job_name>`添加到该配置的任意时序采样.
- job_name: 'prometheus'
# 覆盖全局默认值,从该job每5秒对目标采样一次
scrape_interval: 5s
static_configs:
# 如果需要远程访问, localhost 也可以替换为具体IP,比如10.118.71.170
- targets: ['localhost:9090'] 有关配置选项的完整说明,请参阅配置文档。
启动Prometheus
使用新创建的配置文件来启动 Prometheus,切换到包含 Prometheus 二进制文件的目录并运行
shell
# 启动 Prometheus.
# 默认地, Prometheus 在 ./data 路径下存储其数据库 (flag --storage.tsdb.path).
# ./prometheus --config.file=prometheus.yml通过访问 localhost:9000 来浏览状态页。等待几秒让他从自己的 HTTP metric endpoint 来收集数据。
还可以通过访问到其 metrics endpoint(http://localhost:9090/metrics) 来验证 Prometheus 是否正在提供有关其自身的 metrics
开放防火墙端口
shell
# firewall-cmd --permanent --zone=public --add-port=9090/tcp
success
# firewall-cmd --reload
success使用expressin browser
使用 Prometheus 内置的expressin browser访问 localhost:9090/graph,选择 Graph 导航菜单下的 Table tab页 (Classic UI下为Console tab页)。
通过查看localhost:9090/metrics 页面内容可知,Prometheus 导出了关于其自身的一个名为 prometheus_target_interval_length_seconds指标(目标采样之间的实际间隔)。将其作为搜索表达式,输入到表达式搜索框中,点击 Execute 按钮,如下,将返回多个不同的时间序列(以及每个时间序列的最新值),所有时间序列的 metric 名称均为 prometheus_target_interval_length_seconds,但具有不同的标签。 这些标签具有不同的延迟百分比和目标组间隔(target group intervals)。
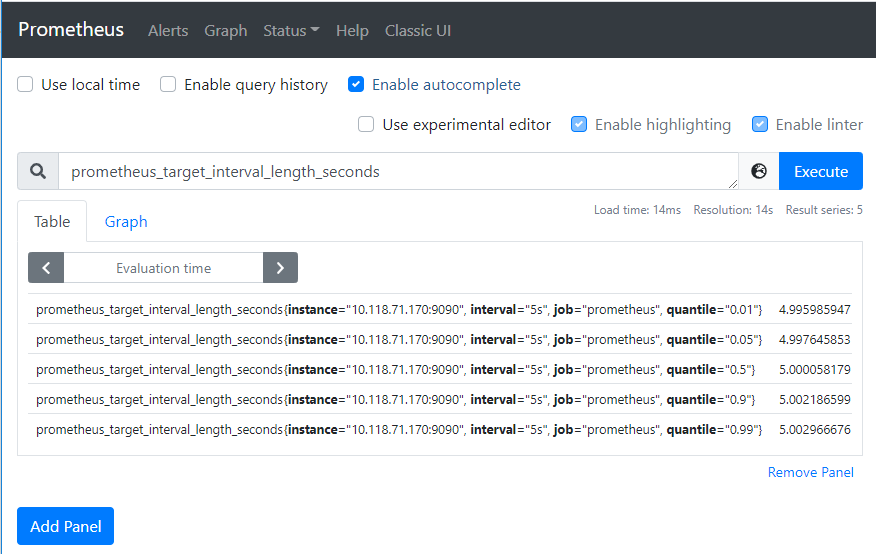
如果我们只对第 99 个百分位延迟感兴趣,则可以使用以下查询来检索该信息:
prometheus_target_interval_length_seconds{quantile="0.99"}如果需要计算返回的时间序列数,可以修改查询如下:
count(prometheus_target_interval_length_seconds)更多有关 expression language 的更多信息,请查看 expression language 文档。
使用绘图界面
要绘制图形表达式,请使用 "Graph" 选项卡。
例如,输入以下表达式以绘制在自采样的 Prometheus 中每秒创建 chunk 的速率:
rate(prometheus_tsdb_head_chunks_created_total[1m])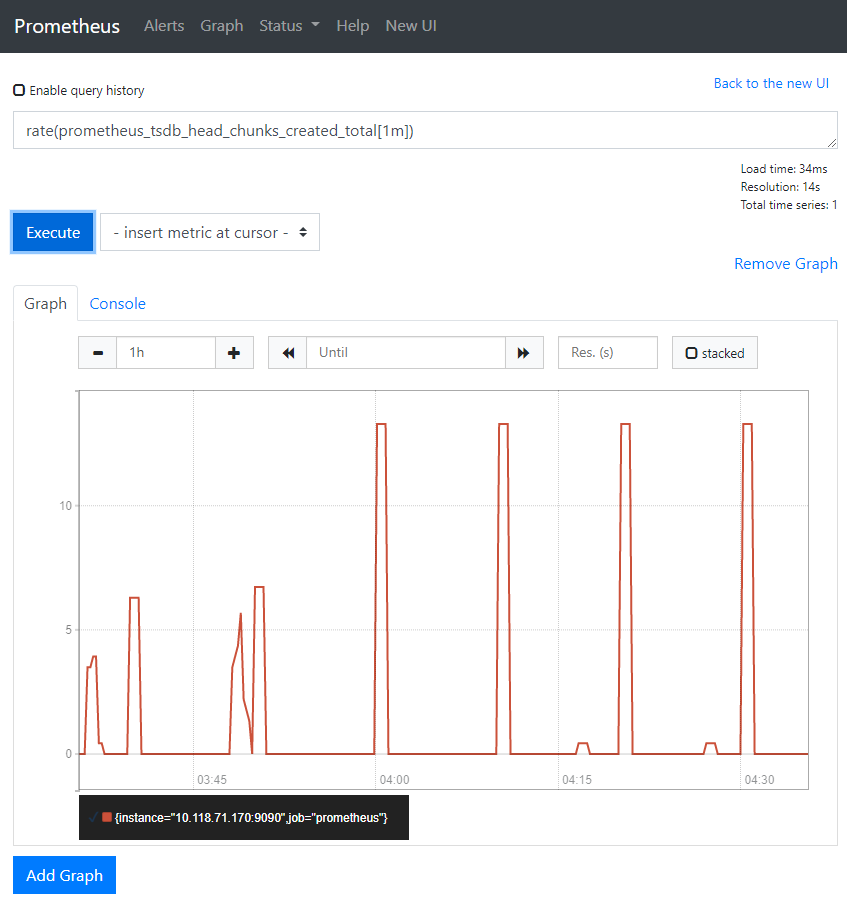
启动一些采样目标
现在让我们增加一些采样目标供 Prometheus 进行采样。
使用Node Exporter作为采样目标,多关于它的使用请查阅
shell
# wget https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.linux-amd64.tar.gz
# tar -xvzf node_exporter-1.1.2.linux-amd64.tar.gz
# ./node_exporter --web.listen-address 127.0.0.1:8001
# ./node_exporter --web.listen-address 127.0.0.1:8002
# ./node_exporter --web.listen-address 127.0.0.1:8003现在,应该存在监听 http://localhost:8080/metrics, http://localhost:8081/metrics 和http://localhost:8082/metrics的示例目标
配置 Prometheus 来监控示例目标
现在,我们将配置 Prometheus 来采样这些新目标。 让我们将所有三个 endpoint 分组为一个称为 "node" 的 job。 但是,假设前两个 endpoint 是生产目标,而第三个 endpoint 代表金丝雀实例。 为了在 Prometheus 中对此建模,我们可以将多个端组添加到单个 job 中,并为每个目标组添加额外的标签。 在此示例中,我们将 group=" production" 标签添加到第一个目标组,同时将 group=" canary" 添加到第二个目标。
为此,请将以下job定义添加到 prometheus.yml 中的 scrape_configs 部分,然后重新启动 Prometheus 实例。修改后的 prometheus.yml内容如下
yaml
global:
scrape_interval: 15s # 默认,每15秒采样一次目标
# 与其它外部系统(比如federation, remote storage, Alertmanager)交互时,会附加这些标签到时序数据或者报警
external_labels:
monitor: 'codelab-monitor'
# 一份采样配置仅包含一个 endpoint 来做采样
# 下面是 Prometheus 本身的endpoint:
scrape_configs:
# job_name 将被被当作一个标签 `job=<job_name>`添加到该配置的任意时序采样.
- job_name: 'prometheus'
# 覆盖全局默认值,从该job每5秒对目标采样一次
scrape_interval: 5s
static_configs:
- targets: ['10.118.71.170:9090']
- job_name: 'node'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:8001', 'localhost:8002']
labels:
group: 'production'
- targets: ['localhost:8003']
labels:
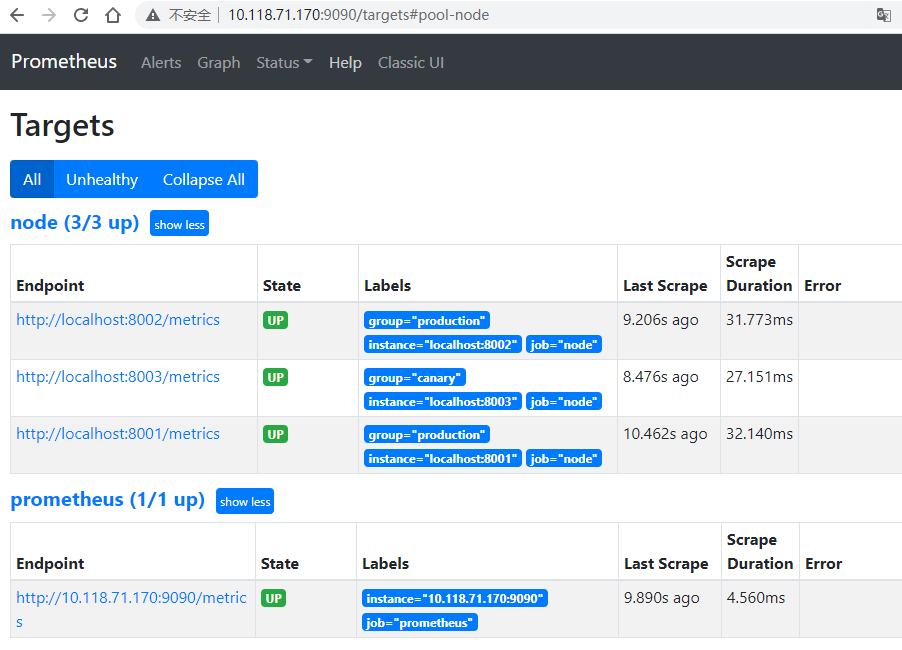
group: 'canary'查看Targets(Status -> Targets)
Graph查询
配置规则以将采样的数据聚合到新的时间序列
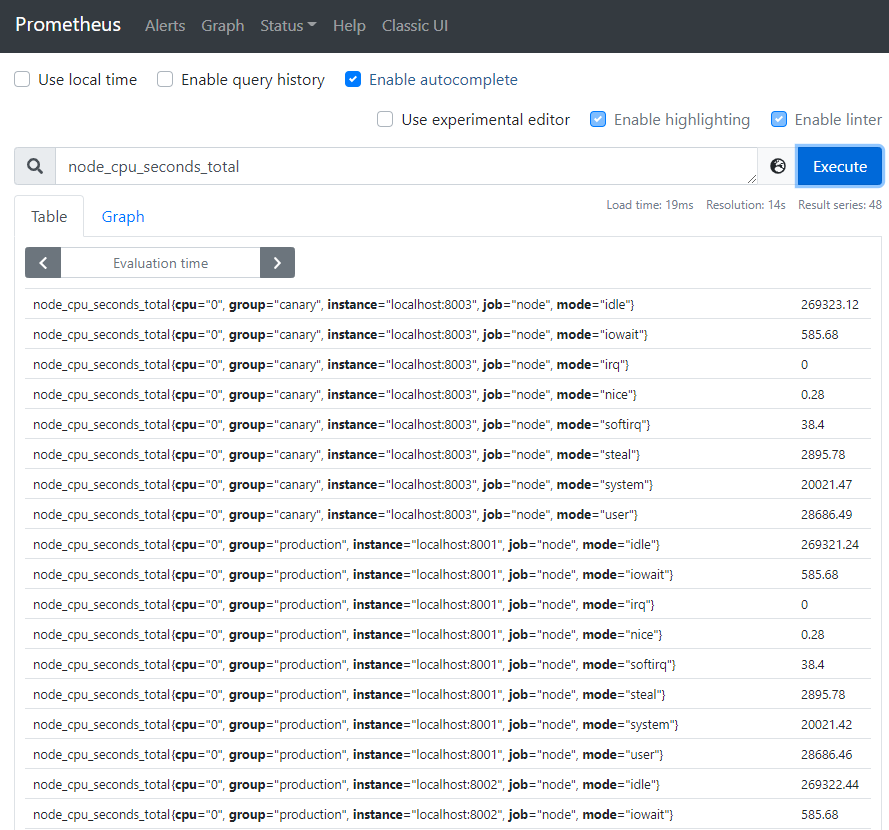
尽管在我们的示例中并不会有问题,但是在聚集了数千个时间序列中查询时可能会变慢。 为了提高效率,Prometheus 允许通过配置的记录规则将表达式预记录到全新的持久化的时间序列中。 假设我们感兴趣的是 5 分钟的窗口内测得的每个实例的所有cpu上平均的cpu时间(node_cpu_seconds_total,保留 Job,instance,和mode 维度))。 我们可以这样写:
avg by (job, instance, mode) (rate(node_cpu_seconds_total[5m]))Graph中执行查询,结果如下
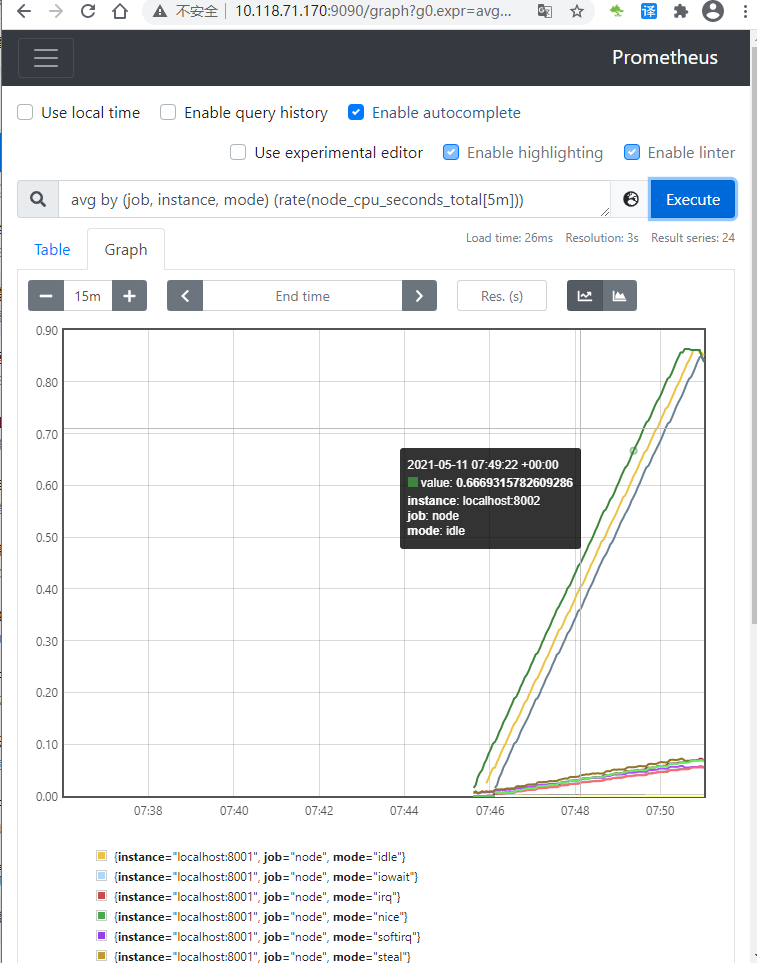
现在,要将由该表达式产生的时间序列记录到一个名为:job_instance_mode:node_cpu_seconds:avg_rate5m 的新指标,使用以下记录规则创建文件并将其保存 prometheus.rules.yml
yaml
groups:
- name: cpu-node
rules:
- record: job_instance_mode:node_cpu_seconds:avg_rate5m
expr: avg by (job, instance, mode) (rate(node_cpu_seconds_total[5m]))在 prometheus.yml 中添加 rule_files 语句,以便 Prometheus 选择此新规则。 现在,prometheus.yml配置应如下所示:
yaml
global:
scrape_interval: 15s # 默认,每15秒采样一次目标
# 与其它外部系统(比如federation, remote storage, Alertmanager)交互时,会附加这些标签到时序数据或者报警
external_labels:
monitor: 'codelab-monitor'
rule_files:
- 'prometheus.rules.yml'
# 一份采样配置仅包含一个 endpoint 来做采样
# 下面是 Prometheus 本身的endpoint:
scrape_configs:
# job_name 将被被当作一个标签 `job=<job_name>`添加到该配置的任意时序采样.
- job_name: 'prometheus'
# 覆盖全局默认值,从该job每5秒对目标采样一次
scrape_interval: 5s
static_configs:
- targets: ['10.118.71.170:9090']
- job_name: 'node'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['localhost:8001', 'localhost:8002']
labels:
group: 'production'
- targets: ['localhost:8003']
labels:
group: 'canary'通过新的配置重新启动 Prometheus,并通过expression brower查询 job_instance_mode:node_cpu_seconds:avg_rate5m,结果如下
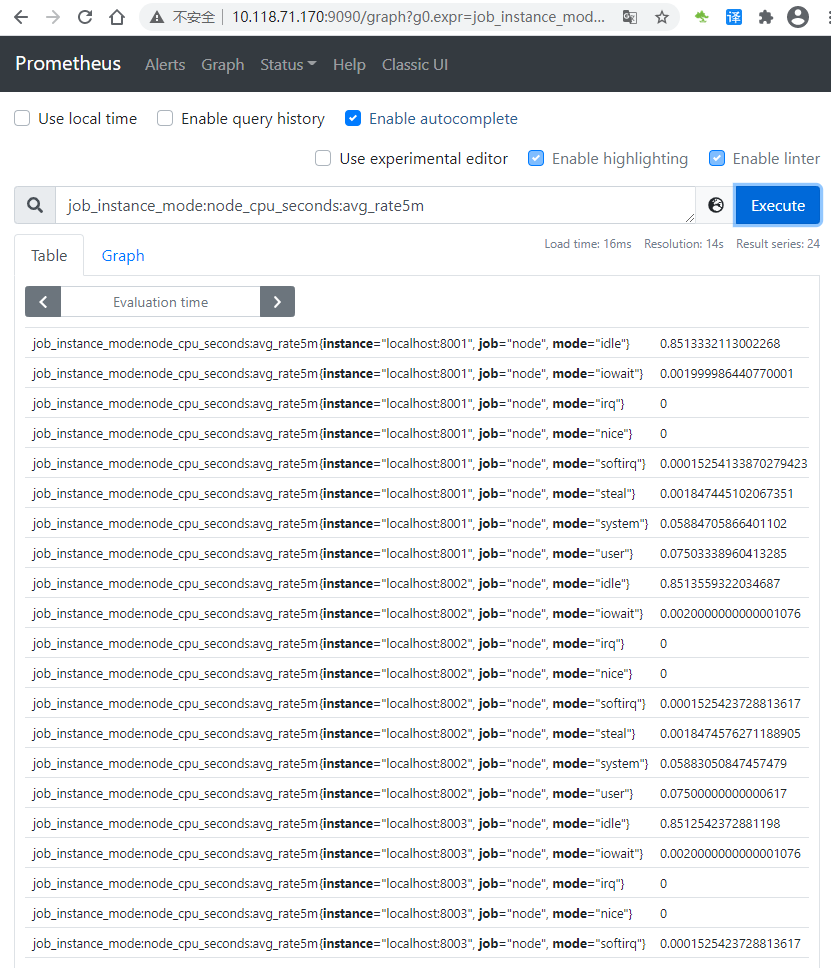
参考连接
https://www.kancloud.cn/nicefo71/prometheus-doc-zh/1331204
https://prometheus.io/docs/prometheus/latest/getting_started/