监控docker,Prometheus监控栈:Prometheus+Grafana+Alertmanager
一、概述
1.1 监控docker的意义
基于程序运行的性能、便捷性、隔离性等优点,docker程序事实上已经成为了企业云原生部署的标准选择。那么docker环境是否稳定docker上运行的各类容器程序cpu使用率、内存使用、网络、磁盘空间等性能参数,就非常有必要。
1.2 docker stats命令
最简单的docker容器性能监控命令是
[root@localhost docker-compose]# docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
140431bf950a rabbitmq-exporter 0.00% 17.18MiB / 1.698GiB 0.99% 21.3kB / 16.9kB 19.1MB / 0B 9
511fd54a30ee rabbitmq 0.12% 81.42MiB / 1.698GiB 4.68% 7.54kB / 14.8kB 89MB / 5.47MB 88
5d4431494b53 redis_exporter 0.00% 16.65MiB / 1.698GiB 0.96% 50.8kB / 23.7kB 19MB / 0B 8
7c5ed9c5bcb3 redis 0.12% 11.01MiB / 1.698GiB 0.63% 7.44kB / 44.6kB 25MB / 0B 5
abfbeea9c8b2 tomcat 0.06% 122.3MiB / 1.698GiB 7.03% 21.3kB / 131kB 140MB / 324kB 34
a677312e0a4f mysql 0.57% 403.5MiB / 1.698GiB 23.20% 16.6kB / 194kB 159MB / 34.7MB 38
4cf34c624eb3 mongo 0.52% 83.96MiB / 1.698GiB 4.83% 42kB / 412kB 116MB / 1.08MB 35
fa9c15e17146 nginx 0.00% 5.066MiB / 1.698GiB 0.29% 5.36kB / 2.82kB 18.5MB / 8.19kB 2
e91b588c19b1 nginx-exporter 0.00% 6.164MiB / 1.698GiB 0.35% 7.02kB / 6.98kB 1.72MB / 0B 7
546daf48ef30 mysqld_exporter 0.00% 11.1MiB / 1.698GiB 0.64% 200kB / 82.7kB 18.9MB / 0B 7
65a825b21669 mongodb_exporter 0.01% 18.16MiB / 1.698GiB 1.04% 420kB / 117kB 28.2MB / 0B 5
#这里是实时监控的1.3 基于cAdvisor组件的docker容器监控
之前prometheus部罢时,已经安装了prometheus、node_exporter以及cAdvisor(监控容器)的组件。yaml的回顾
#监控docker容器
cadvisor: #它是整个监控栈的"容器资源探针",专门负责自动收集宿主机上所有运行容器的实时性能数据。监控容器
image: m.daocloud.io/gcr.io/cadvisor/cadvisor:v0.47.2
container_name: cadvisor #指定容器名称,便于管理。
restart: always #确保服务中断后自动重启。
privileged: true
devices:
- /dev/kmsg
volumes:
- /etc/localtime:/etc/localtime:ro #同步宿主机时间
- /:/rootfs:ro #挂载宿主机根目录(只读)。cAdvisor从这里读取主机整体的文件系统使用情况、容器镜像层等信息。
- /var/run:/var/run:rw #挂载Docker运行时目录(读写)。这是唯一需要读写权限的挂载。cAdvisor通过该目录下的Unix套接字(如 /var/run/docker.sock)与Docker守护进程通信,动态发现和查询所有容器的详细信息(如状态、配置)。
- /sys/fs/cgroup:/sys/fs/cgroup:ro #挂载系统信息目录(只读)。/sys 是Linux内核暴露硬件和设备信息的虚拟文件系统,cAdvisor从这里获取CPU、内存、网络设备等全局硬件指标。
- /var/lib/docker/:/var/lib/docker:ro #挂载Docker数据目录(只读)。这里存储了容器的镜像、可写层等实际数据,cAdvisor通过分析它来计算各容器的精确磁盘使用量。
networks: #加入监控专用网络,使Prometheus能通过 cadvisor:8080 访问其指标接口。
- monitoring
expose: #仅暴露端口给内部网络。但不映射到宿主机。
- '8080'二、cAdvisor组件介绍
CAdvisor是谷歌开源的一款用于展示和分析容器运行状态的可视化工具,通过在主机上运行
CAdvisor用户可以轻松的获取到当前主机上容器的运行统计信息,并以图标的形式向用户展示
通过默认的8080端口,可以访问到cAdvisor的数据信息。
2.1 cAdvisor的图形界面暴露
修改prometheus中对自身docker平台的cAdvisor组件配置,露8080端口
cd /data/docker-compose
vi docker-compose.yaml
cadvisor: #它是整个监控栈的"容器资源探针",专门负责自动收集宿主机上所有运行容器的实时性能数据。
image: m.daocloud.io/gcr.io/cadvisor/cadvisor:v0.47.2
container_name: cadvisor #指定容器名称,便于管理。
restart: always #确保服务中断后自动重启。
privileged: true
devices:
- /dev/kmsg
volumes:
- /etc/localtime:/etc/localtime:ro #同步宿主机时间
- /:/rootfs:ro #挂载宿主机根目录(只读)。cAdvisor从这里读取主机整体的文件系统使用情况、容器镜像层等信息。
- /var/run:/var/run:rw #挂载Docker运行时目录(读写)。这是唯一需要读写权限的挂载。cAdvisor通过该目录下的Unix套接字(如 /var/run/docker.sock)与Docker守护进程通信,动态发现和查询所有容器的详细信息(如状态、配置)。
- /sys/:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro #挂载Docker数据目录(只读)。这里存储了容器的镜像、可写层等实际数据,cAdvisor通过分
析它来计算各容器的精确磁盘使用量。
- /var/run/docker.sock:/var/run/docker.sock:rw
command:
- '--docker_only=true'
- '--housekeeping_interval=10s'
- '--disable_metrics=percpu,sched,tcp,udp,disk' # 减少一些不常用的指标,降低负载
networks: #加入监控专用网络,使Prometheus能通过 cadvisor:8080 访问其指标接口。
- monitoring
expose: #仅暴露端口给内部网络。但不映射到宿主机。
- '8080'
ports:
- '8080:8080'使用docker-compose重启程序
docker-compose up -d访问cAdvisor的图形界面
http://192.168.92.11:8080/containers/
2.2 cAdvisor的监控数据暴露
prometheus中,暴露8080端口后,即可访问到metrics数据(prometheus所需的数据格式)
http://192.168.92.11:8080/metrics2.3 test上cAdvisor的部署
test上,进入docker-compose的目录
vi /data/docker-compose/docker-compose.yaml
#监控docker容器
cadvisor: #它是整个监控栈的"容器资源探针",专门负责自动收集宿主机上所有运行容器的实时性能数据。监控容器
image: m.daocloud.io/gcr.io/cadvisor/cadvisor:v0.47.2
container_name: cadvisor #指定容器名称,便于管理。
restart: always #确保服务中断后自动重启。
privileged: true
devices:
- /dev/kmsg
volumes:
- /etc/localtime:/etc/localtime:ro #同步宿主机时间
- /:/rootfs:ro #挂载宿主机根目录(只读)。cAdvisor从这里读取主机整体的文件系统使用情况、容器镜像层等信息。
- /var/run:/var/run:rw #挂载Docker运行时目录(读写)。这是唯一需要读写权限的挂载。cAdvisor通过该目录下的Unix套接字(如 /var/run/docker.sock)与Docker守护进程通信,动态发现和查询所有容器的详细信息(如状态、配置)。
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro #挂载Docker数据目录(只读)。这里存储了容器的镜像、可写层等实际数据,cAdvisor通过分
析它来计算各容器的精确磁盘使用量。
- /dev/kmsg:/dev/kmsg # 关键:挂载内核日志设备
- /var/run/docker.sock:/var/run/docker.sock:rw
command:
- '--docker_only=true'
- '--housekeeping_interval=10s'
- '--disable_metrics=percpu,sched,tcp,udp,disk' # 减少一些不常用的指标,降低负载
expose: #仅暴露端口给内部网络。但不映射到宿主机。
- '8080'
#添加配置,用于暴露8080端口
ports:
- '8090:8080'访问cAdvisor的链接确保可以访问
http://192.168.92.12:8090/metrics
2.4 prometheus中增加对于tests的docker平台的监控
cd /data/docker-prometheus/prometheus
vi prometheus.yml
# 3. cAdvisor 容器监控,Google开发的容器监控工具
- job_name: 'cadvisor'
scrape_interval: 60s
static_configs:
- targets: ['cadvisor:8080']
labels:
instance: 'Prometheus服务器'
- targets: ['192.168.92.12:8090']
labels:
instance: 'test服务器的docker监控'重新加载配置
#在prometheus中执行
curl -X POST http://localhost:9090/-/reload访问192.168.92.11:9090,看看test的cAdvisor有没有up
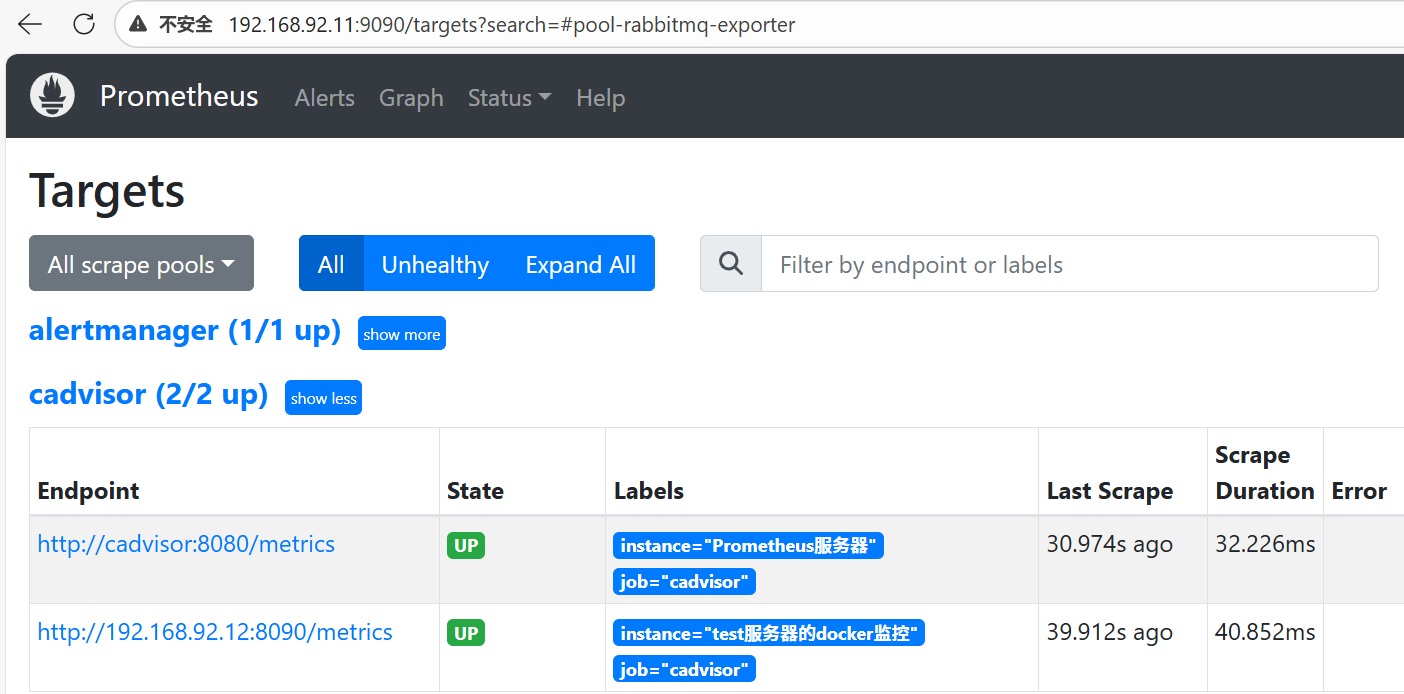
三、常用的docker监控指标
CPU 监控指标
container_cpu_load_average_10s (gauge)
含义:过去10秒容器CPU平均负载
用途:监控容器短期CPU负载情况,反映系统繁忙程度
container_cpu_usage_seconds_total (counter)
含义:容器在每个CPU内核上累计占用时间(单位:秒)
用途:计算CPU使用率的基础指标,需结合时间差计算
container_cpu_system_seconds_total (counter)
含义:System CPU累计占用时间(单位:秒)
用途:监控内核态CPU使用情况,反映系统调用开销
container_cpu_user_seconds_total (counter)
含义:User CPU累计占用时间(单位:秒)
用途:监控用户态CPU使用情况,反映应用代码执行开销
文件系统监控指标
container_fs_usage_bytes (gauge)
含义:容器中文件系统的使用量(单位:字节)
用途:监控容器磁盘空间使用情况
container_fs_limit_bytes (gauge)
含义:容器可以使用的文件系统总量(单位:字节)
用途:了解容器磁盘配额限制
container_fs_reads_bytes_total (counter)
含义:容器累计读取数据的总量(单位:字节)
用途:监控磁盘I/O读取负载,评估读取性能
container_fs_writes_bytes_total (counter)
含义:容器累计写入数据的总量(单位:字节)
用途:监控磁盘I/O写入负载,评估写入性能和磁盘寿命
内存监控指标
container_memory_max_usage_bytes (gauge)
含义:容器的最大内存使用量(单位:字节)
用途:了解历史峰值内存使用情况,用于容量规划
container_memory_usage_bytes (gauge)
含义:容器当前的内存使用量
用途:实时监控内存使用情况,检测内存泄漏
container_spec_memory_limit_bytes (gauge)
含义:容器内存使用量限制
用途:了解容器内存配额,计算使用率
machine_memory_bytes (gauge)
含义:当前主机的内存总量
用途:提供主机资源基准,用于计算整体资源使用率
网络监控指标
container_network_receive_bytes_total (counter)
含义:容器网络累计接收数据总量(单位:字节)
用途:监控入站网络流量,评估带宽使用情况
container_network_transmit_bytes_total (counter)
含义:容器网络累计发送数据总量(单位:字节)
用途:监控出站网络流量,评估带宽使用情况和费用成本
指标类型说明
gauge:瞬时值指标,可增可减,如内存使用量、CPU负载
counter:累积值指标,只增不减(除非重置),如总请求数、总I/O字节数
常用计算公式
CPU使用率:(container_cpu_usage_seconds_total的增量) / (采样时间间隔 × CPU核心数)
内存使用率:container_memory_usage_bytes / container_spec_memory_limit_bytes × 100%
磁盘使用率:container_fs_usage_bytes / container_fs_limit_bytes × 100%
网络吞吐量:container_network_receive/transmit_bytes_total的增量 / 采样时间间隔四、grafana中添加docker的监控模版
id=11600
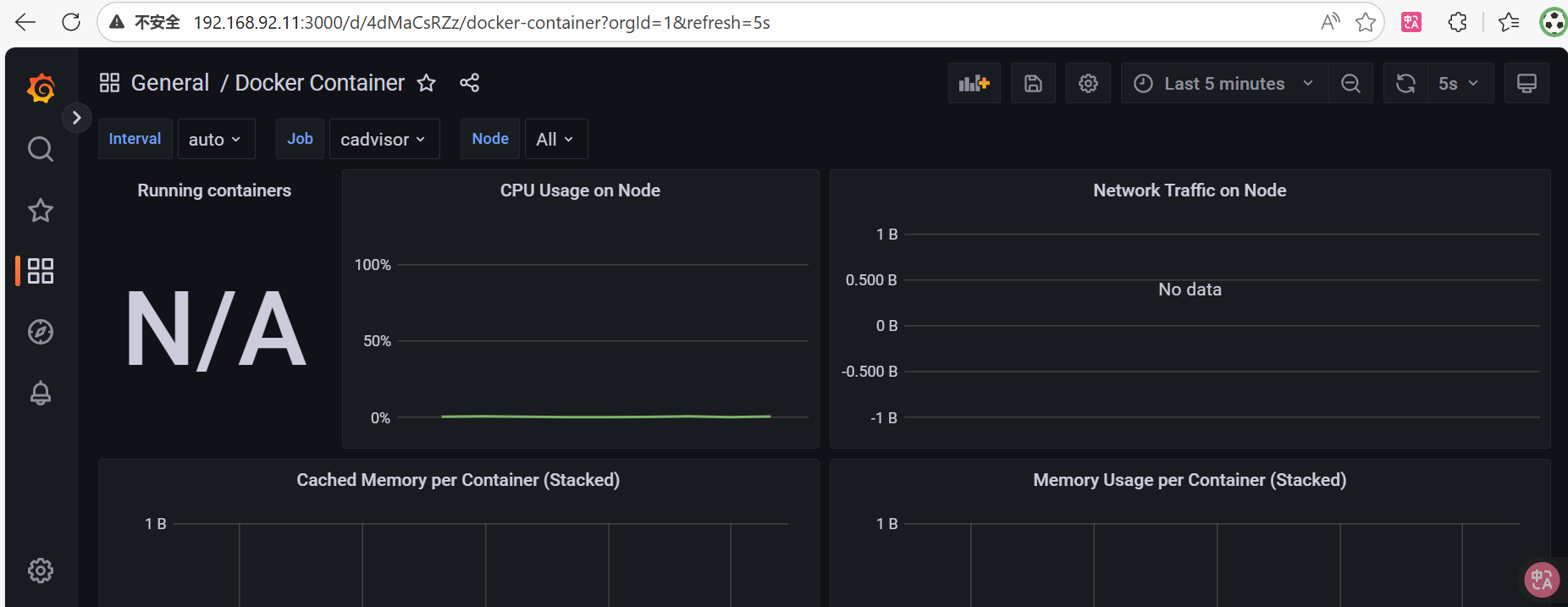
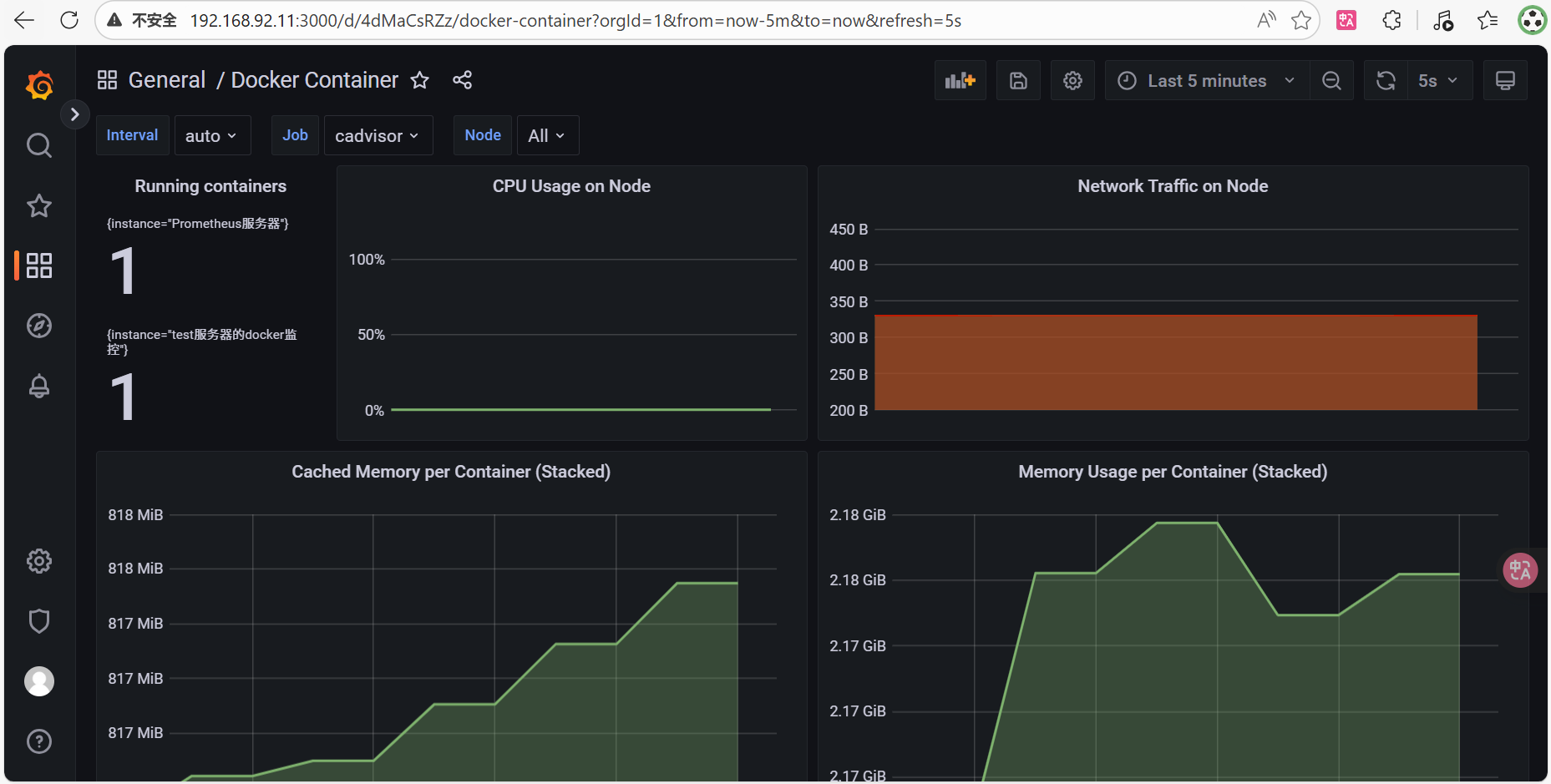
哪里都正常,唯独grafana表盘没有数据
prometheus可以查到,cAdvisor - /可以看到,docker stats也可以看到数据进行监控
gemini:这是cadvisor,docker和rhel系统之间的一个版本代差和权限隔离导致的经典坑,prometheus查到的数据没有name的标签

Grafana仪表盘没有数据,最主要的原因 就是使用的那个预设仪表盘(很可能是Grafana官网的"Docker监控"仪表盘,如ID: 193),它的查询语句里依赖 name 或 image 等容器标识标签来过滤和分组数据。但是prometheus查询返回的没有name和image标签
这时候只能改一下promql(在图表中点击edit,把PromQL换成下面的,点Run queries,再点Apply)
监控进程,Prometheus监控栈:Prometheus+Grafana+Alertmanager
一、软件环境介绍
1.1 为什么要监控进程
之前我们做的监控对象,大多数是比较成熟的中间件(redis、tomcat、springboot程序、mysq!程序等等),实际的企业业务运行过程中,可能出现tomcat容器依然存活、但是其中运行的javaweb程序挂掉的情况(或者mysql-docker容器存在,依然往外统计数据抛数据,但是容器内的mysql进程挂掉的情况)。
因此,对业务访问链路中的核心进程施加监控,是非常有必要的。
1.2 怎么在prometheus中监控进程
如果想要对主机的进程进行监控,例如chronyd,sshd等服务进程以及自定义脚本程序运行状态监控。我们使用node exporter就不能实现需求了,此时就需要使用process-exporter来做进程状态的监控。
1.3 主机清单
| 职责 | ip地址 | 备注 |
|---|---|---|
| Prometheus服务器 | 192.168.92.11 | docker-compose模式的prometheus |
| 待监控Linux | 192.168.92.12 | 待准备组件:process-exporter |
二、prometheus监控进程
docker安装(略)
docker-compose安装(略)
2.1 process_exporter的安装位置及意义
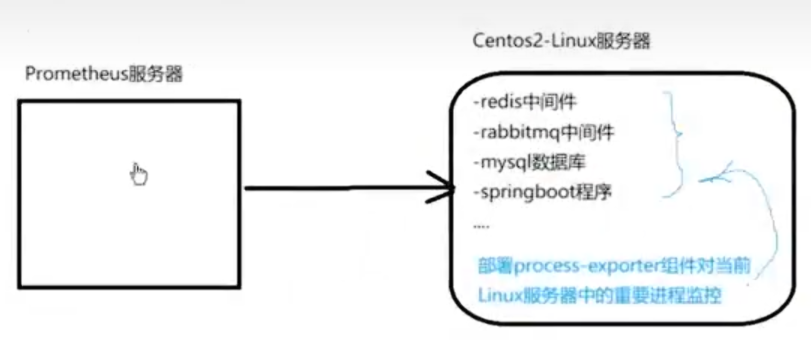
2.2 待监控Linux部署process-exporter
二进制安装或者docker安装(或者docker-compose安装),此处选用docker-compose安装
test(对应上图的Centos2-Linux服务器)机器上,修改process.yaml文件(描述需要监控哪些进程,它是一个配置文件)
# 创建数据目录
mkdir -p /data/process-exporter
cd /data/process-exporter
# 创建配置文件目录
mkdir -p config
# 创建配置文件
cat > config/process.yml << 'EOF'
process_names: #定义一组进程匹配规则。
- name: "{{.Comm}}"
cmdline: #定义匹配进程的命令行规则
- '.+' #'.+' 表示匹配任意非空命令行,即监控所有进程。
EOF
# 监控指定进程配置
process_names:
- name: "{{.Matches}}"
cmdline: ['nginx'] # 唯一标识
- name: "{{.Matches}}"
cmdline: ['mongod']
- name: "{{.Matches}}"
cmdline: ['mysqld']
- name: "{{.Matches}}"
cmdline: ['redis-server']
- name: "{{.Matches}}"
cmdline: ['org.apache.zookeeper.server.quorum.QuorumPeerMain']
- name: "{{.Matches}}"
cmdline: ['org.apache.hadoop.mapreduce.v2.hs.JobHistoryServer']
- name: "{{.Matches}}"
cmdline: ['org.apache.hadoop.hdfs.qjournal.server.JournalNode']
# 注:cmdline为所选进程的唯一标识,可通过 ps -ef 查询
# 如果对应进程不存在,则不会监控该进程部署process-exporter
cd /data/docker-compose
vi docker-compose.yaml增加process-exporter节点
version: '3.3' #指定使用的 Docker Compose 文件格式版本。
services: #定义所有容器服务的根节点。
process-exporter: #服务名称。
image: ncabatoff/process-exporter #指定使用的官方Process Exporter镜像。
container_name: process-exporter #为容器指定一个固定的名称
restart: always #容器异常退出时会自动重启,确保监控服务高可用。
privileged: true #关键权限配置。授予容器访问宿主机内核信息的特权
volumes: #目录挂载,实现容器内外的数据互通。
- /proc:/host/proc:ro
- /data/process-exporter/config:/config:ro
command:
- --procfs=/host/proc
- --config.path=/config/process.yml
ports:
- "9256:9256"启动docker-compose
docker-compose up -d检查:
docker ps -a | grep process
#访问以下url,http://192.168.92.12:9256/metrics2.3 Prometheus中增加process-exporter对象
prometheus中进入prometheus目录
#进入docker-prometheus目录
cd /data/docker-prometheus
#修改prometheus.yml
vi prometheus/prometheus.yml添加待监控的process-exporter
- job_name: 'process-exporter'
scrape_interval: 30s
scrape_timeout: 15s
static_configs:
- targets: ['192.168.92.12:9256']
labels:
instance: 'process进程监控'保存配置后,让配置生效
curl -X POST http://localhost:9090/-/reload刷新访问http://192.168.92.11:9090/targets?search=,确认新监控的process进程监控是否生效
2.4 process进程监控指标说明
namedprocess_namegroup_num_procs - 运行的进程总数
namedprocess_namegroup_num_threads - 进程的线程总数
namedprocess_namegroup_states - 按状态(Running/Sleeping/Other/Zombie)统计的进程数
namedprocess_namegroup_cpu_seconds_total - 进程累计CPU使用时间(秒)
namedprocess_namegroup_read_bytes_total - 进程累计读取字节数
namedprocess_namegroup_write_bytes_total - 进程累计写入字节数
namedprocess_namegroup_memory_bytes - 进程当前内存使用量(字节)
namedprocess_namegroup_open_filedesc - 进程当前打开的文件描述符数量
namedprocess_namegroup_worst_fd_ratio - 进程文件描述符使用率(当前/最大)
namedprocess_namegroup_thread_count - 线程总数
namedprocess_namegroup_thread_cpu_seconds_total - 线程累计CPU使用时间(秒)
namedprocess_namegroup_thread_io_bytes_total - 线程累计I/O字节数2.5 grafana中对进程进行监控
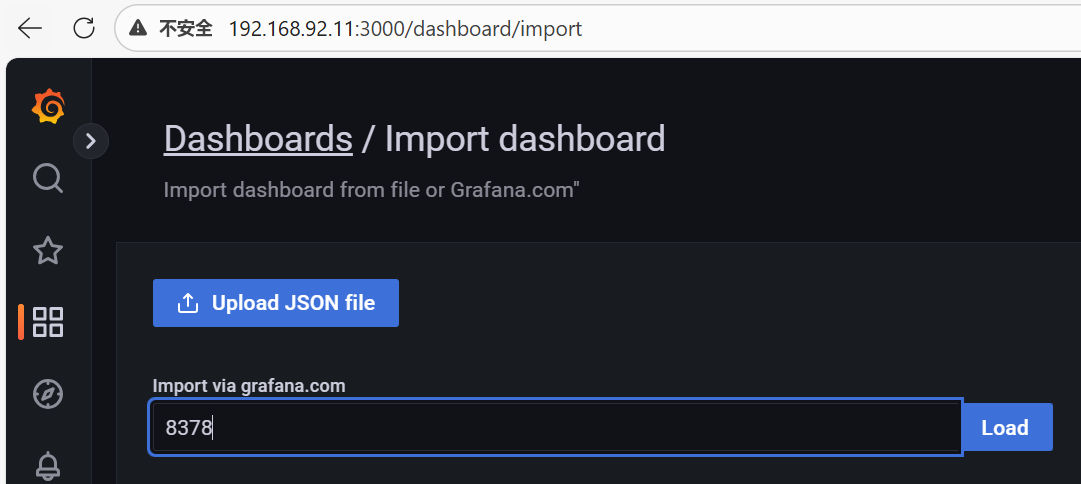
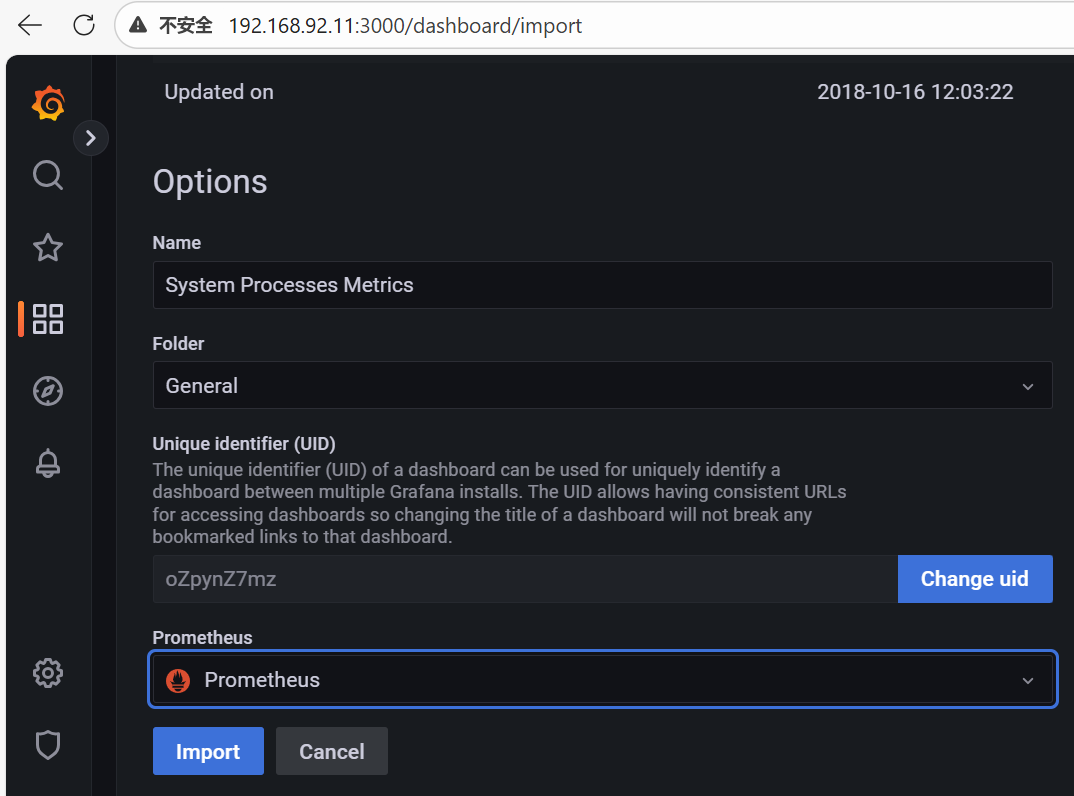
copy id to clipboard->grafana的dashboards中Import dashboard
https:/gralana.com/grafana/dashboards/4279-rabbitmg-monitomng/
https://grafana.com/grafana/dashboards/8378/
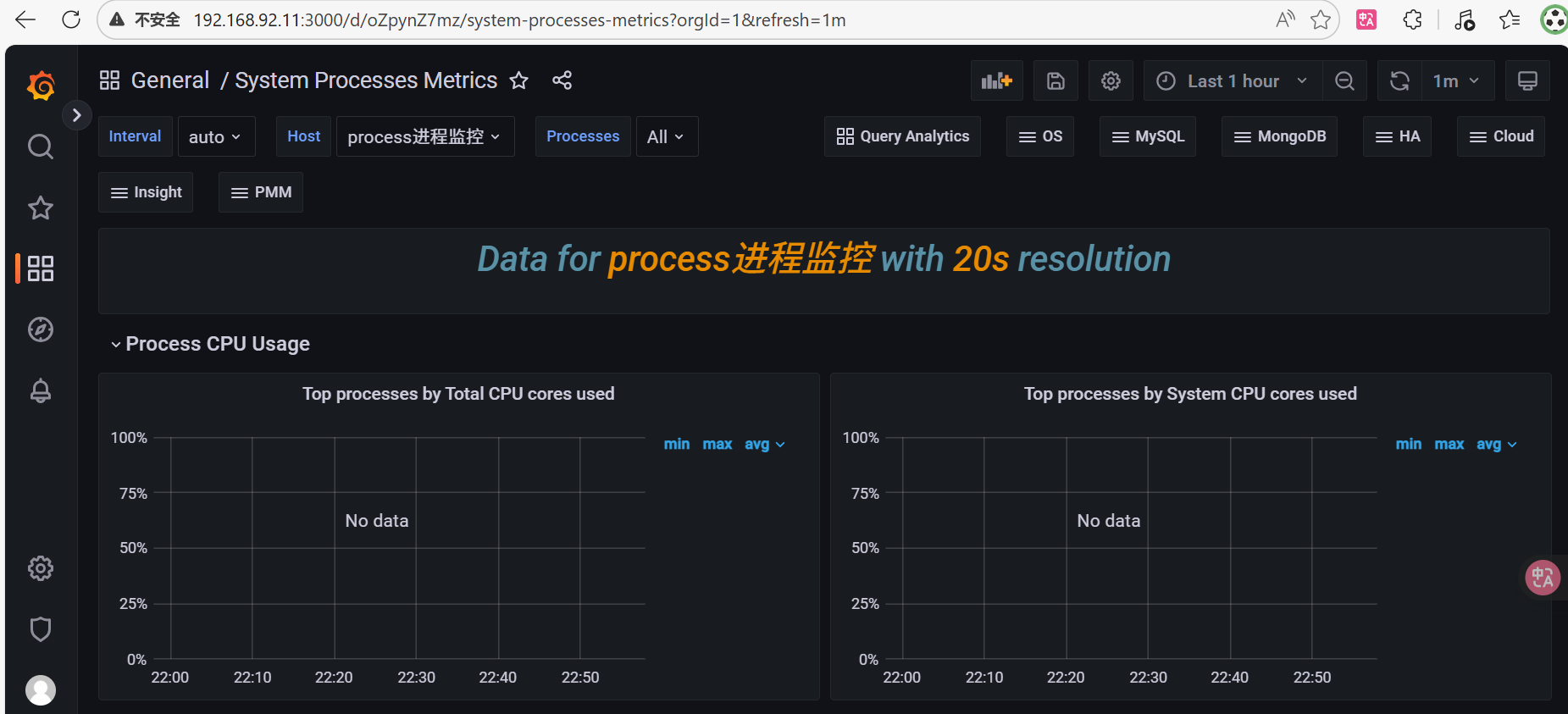
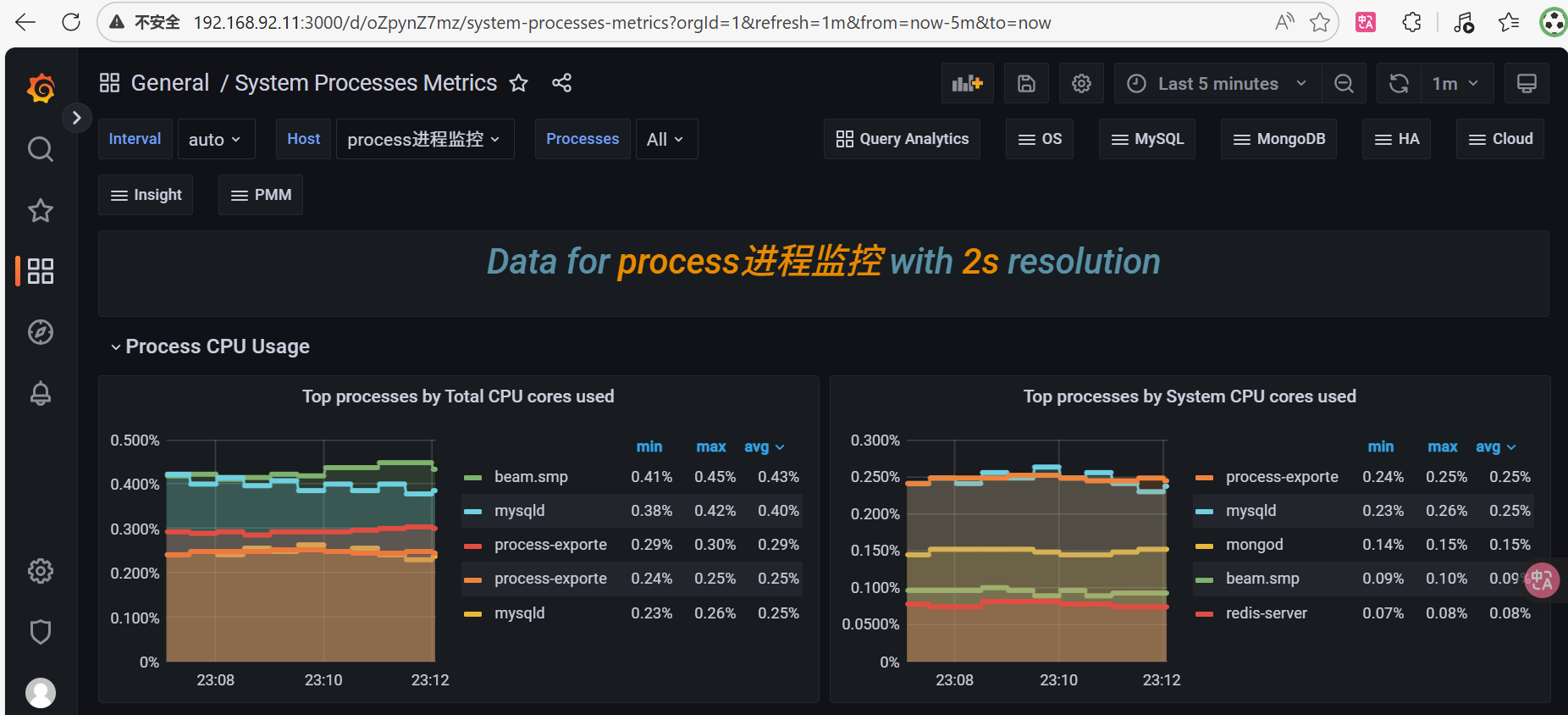
。解决process-exporter升级到0.5.0+之后,cpu相关的两个图形不显示数据的问题Top processes By Total CPU cores used图形脚本(点击edit,把PromQL换成下面的,点Run queries,再点Apply)
topk(5, rate(namedprocess_namegroup_cpu_seconds_total{groupname=~"$processes", instance=~"$host"}[5m]))。Top processes By System CPU cores used图形脚本(点击edit,把PromQL换成下面的,点Run queries,再点Apply)
topk(5, rate(namedprocess_namegroup_cpu_seconds_total{mode="system", groupname=~"$processes", instance=~"$host"}[5m]))最后左侧边栏点Browse,再点Save dashboard,完成更新