目录
- [1. What](#1. What)
- [2. 架构](#2. 架构)
- [2.1 CoordinatorServer](#2.1 CoordinatorServer)
- [2.2 TabletServer](#2.2 TabletServer)
- [2.3 LogStore](#2.3 LogStore)
- [2.4 KvStore](#2.4 KvStore)
- [2.5 Tablet / Bucket](#2.5 Tablet / Bucket)
- [2.6 Zookeeper](#2.6 Zookeeper)
- [2.7 Remote Storage](#2.7 Remote Storage)
- [2.8 Client](#2.8 Client)
- [3. 表设计](#3. 表设计)
- [3.1 概述](#3.1 概述)
- [3.1.1 Database](#3.1.1 Database)
- [3.1.2 Table](#3.1.2 Table)
- [3.1.3 Table 数据组织](#3.1.3 Table 数据组织)
- [3.1.3.1 Partition](#3.1.3.1 Partition)
- [3.1.3.2 Bucket](#3.1.3.2 Bucket)
- [3.1.3.3 LogTablet](#3.1.3.3 LogTablet)
- [3.1.3.4 KvTablet](#3.1.3.4 KvTablet)
- [3.2 表类型](#3.2 表类型)
- [3.2.1 Log Table](#3.2.1 Log Table)
- [3.2.2 PrimaryKey Table](#3.2.2 PrimaryKey Table)
- [3.3 数据分布](#3.3 数据分布)
- [3.3.1 Bucketing](#3.3.1 Bucketing)
- [3.3.2 分区表](#3.3.2 分区表)
- [3.3.3 TTL](#3.3.3 TTL)
- [3.4 数据类型](#3.4 数据类型)
- [3.1 概述](#3.1 概述)
- [4. 流式湖仓](#4. 流式湖仓)
- [5. How](#5. How)
- [5.1 安装docker](#5.1 安装docker)
- [5.2 启动所需要的组件](#5.2 启动所需要的组件)
- [5.3 进入SQL客户端](#5.3 进入SQL客户端)
- [5.4 创建Fluss表格](#5.4 创建Fluss表格)
- [5.4.1 创建fluss catalog](#5.4.1 创建fluss catalog)
- [5.4.2 创建表](#5.4.2 创建表)
- [5.5 流式写入 Fluss](#5.5 流式写入 Fluss)
- [5.6 在 Fluss 表上运行临时查询](#5.6 在 Fluss 表上运行临时查询)
- [5.7 Update/Delete rows on Fluss Tables](#5.7 Update/Delete rows on Fluss Tables)
- [5.7.1 Update](#5.7.1 Update)
- [5.7.2 Delete](#5.7.2 Delete)
- [5.8 集成pamion](#5.8 集成pamion)
- [5.8.1 启动 Lakehouse 分层服务](#5.8.1 启动 Lakehouse 分层服务)
- [5.8.2 将数据流式写入 Fluss 数据湖启用的表](#5.8.2 将数据流式写入 Fluss 数据湖启用的表)
- [5.8.3 Fluss 数据湖启用表上的实时分析](#5.8.3 Fluss 数据湖启用表上的实时分析)
- [5.9 clean up](#5.9 clean up)
- [6. Reference](#6. Reference)
1. What
Fluss 是一个用于实时分析的可扩展流存储,可以作为 Lakehouse 架构的实时数据层。
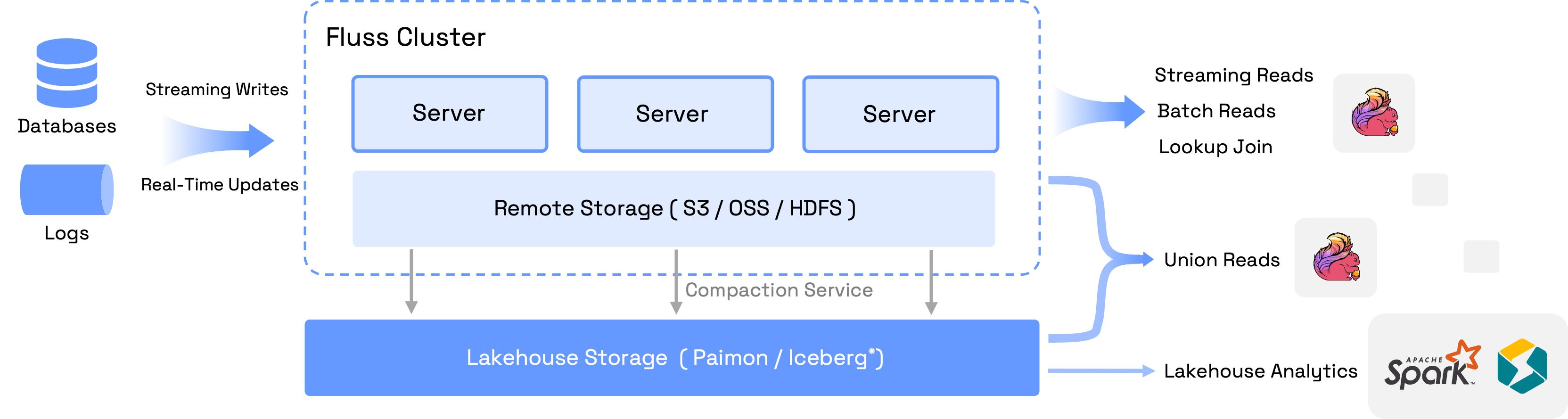
它通过实现低延迟、高吞吐量的数据摄取和处理,弥合了流数据和数据湖之间的差距,同时无缝集成流行的计算引擎,如Apache Flink,而Apache Spark和StarRocks也即将推出。
Fluss 支持亚秒级延迟的 流式读取 和 写入,并以列式格式存储数据,从而提高查询性能并降低存储成本。 它提供灵活的表类型,包括仅追加的 日志表 和可更新的 主键表,以满足各种实时分析和处理需求。
内置的复制功能可提供容错性、水平扩展性以及高级功能,如高QPS的查找连接和批量读写操作,Fluss非常适合用于支持实时分析、AI/ML流水线和流数据仓库。
fluss(德语:河流,发音为/flus/)能够持续地流式传输数据,将其汇聚、分发并流入湖泊,就像一条河流
2. 架构
一个Fluss集群由两个主要进程组成:CoordinatorServer和TabletServer。
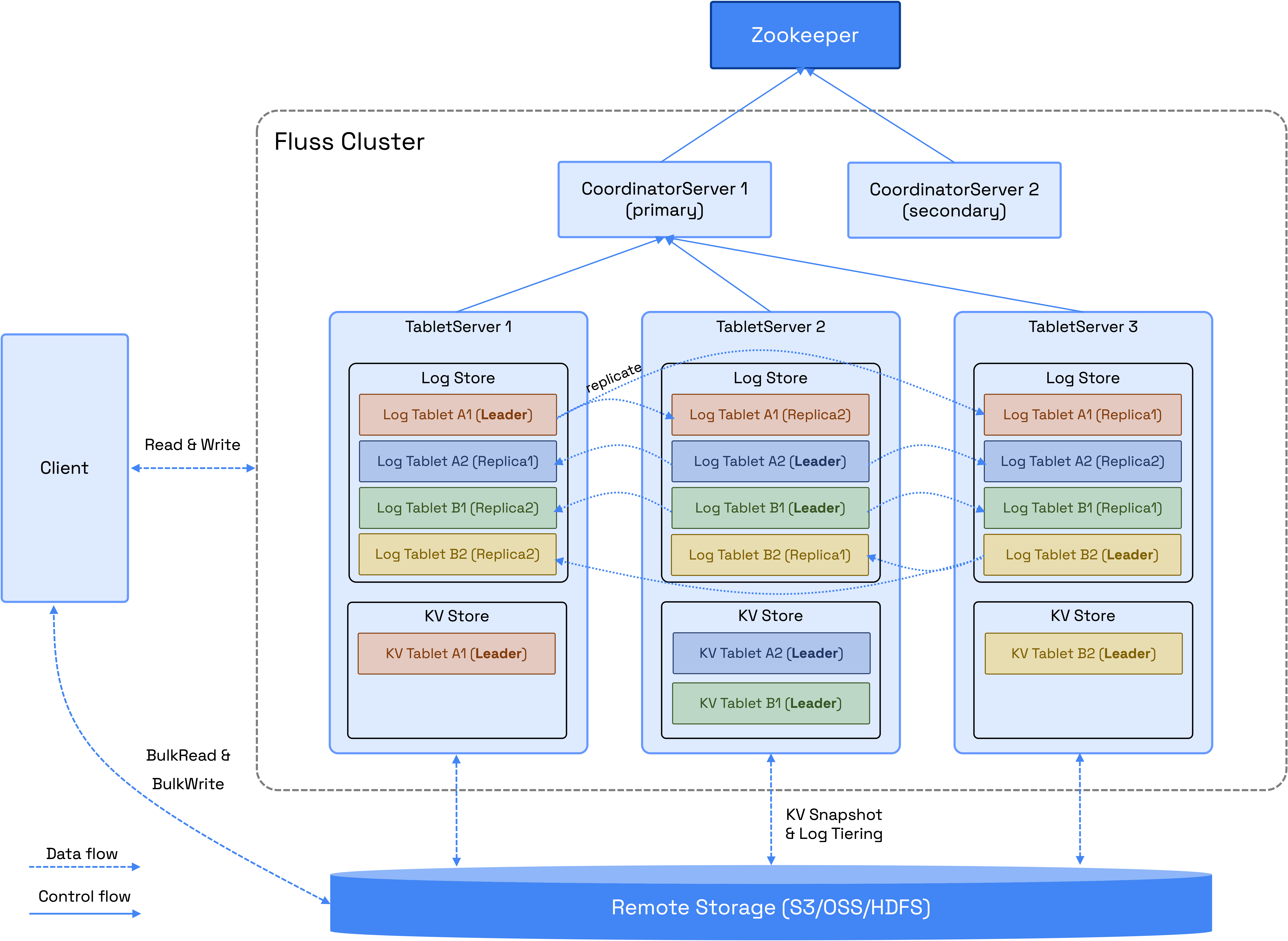
2.1 CoordinatorServer
CoordinatorServer是集群的中心控制和管理工作组件。它负责维护元数据、管理表分配、列出节点和处理权限
此外,它协调关键操作,如:
- 在节点扩缩期间重新平衡数据
- 在节点故障的情况下,管理数据迁移和服务节点切换。
- 监督表管理任务,包括创建或删除表以及更新桶计数
CoordinatorServer作为集群的大脑,协调服务器确保集群的高效运行和资源的无缝管理
2.2 TabletServer
TabletServer 负责数据存储、持久化,并向用户提供直接的 I/O 服务。它由两个关键组件组成:LogStore 和 KvStore
- 对于支持更新的主键表,LogStore和KvStore都会被激活。KvStore用于高效地支持更新和点查找。LogStore用于存储表的变化日志
- 对于仅支持追加操作的日志表,仅激活LogStore,以优化写入密集型工作负载的性能
这种架构确保TabletServer能够根据表类型提供定制的数据处理能力
2.3 LogStore
LogStore 设计用于存储日志数据,功能类似于数据库的二进制日志。 消息只能追加,不能修改,以确保数据完整性。 其主要目的是实现低延迟的流式读取,并作为KvStore的预写日志(WAL)
2.4 KvStore
KvStore 用于存储表数据,功能类似于数据库表。它支持数据更新和删除,从而实现高效的查询和表管理。此外,它还生成全面的变更日志,以跟踪数据修改
2.5 Tablet / Bucket
表数据根据定义的桶策略被划分为多个桶
LogStore 和 KvStore 的数据存储在Tablet中。每个Tablet由一个 LogTablet 和一个可选的 KvTablet 组成,具体取决于表是否支持更新。 LogStore 和 KvStore 都遵循相同的桶分割和Tablet分配策略。因此,具有相同 tablet_id 的 LogTablets 和 KvTablets 总是分配到同一个 TabletServer,以便高效地管理数据
LogTablet 支持基于表配置的复制因子进行多个副本,确保高可用性和容错性。目前,KvTablets 不支持复制
2.6 Zookeeper
Fluss 目前使用 ZooKeeper 进行集群协调、元数据存储和集群配置管理。 在即将发布的版本中,ZooKeeper 将被替换 为 KvStore 用于元数据存储,Raft 用于集群协调和确保一致性。这一过渡旨在简化操作并提高系统可靠性
2.7 Remote Storage
远程存储有两个主要用途:
1.LogStores的分层存储:通过卸载LogStore数据,它减少了存储成本并加速了扩展操作
2.KvStores 的持久存储: 它确保 KvStore 数据的持久存储,并与 LogStore 协作以实现故障恢复。
此外,远程存储允许客户端对log和Kv数据进行批量读取操作,从而提高数据分析效率并减少Fluss服务器上的开销。未来,它还将支持批量写入操作,优化数据导入工作流程,以实现更大的可扩展性和性能。
2.8 Client
Fluss 客户端/SDK 支持流式读取/写入、批量读取/写入、DDL 和点查询。目前,客户端的主要实现是 Flink Connector。用户可以使用 Flink SQL 轻松操作 Fluss 表和数据。
3. 表设计
3.1 概述
3.1.1 Database
数据库是表对象的集合。您可以在数据库中创建/删除数据库或创建/修改/删除表
3.1.2 Table
在Fluss中,表是用户数据存储的基本单元,由行和列组成。表存储在特定的数据库中,遵循层次结构(数据库 -> 表)
根据主键的存在与否,表格分为两种类型:
- Log Tables
专为仅追加场景设计,仅支持 INSERT 操作。 - PrimaryKey Tables
用于更新和管理业务数据库中的数据,支持基于定义的主键的 INSERT、UPDATE 和 DELETE 操作。
当定义了分区列时,一个表会变成一个分区表。具有相同分区值的数据存储在同一个分区中。分区列可以应用于日志表和主键表,但需要考虑特定的因素:
- 对于日志表,分区通常用于日志数据,通常基于日期列,以促进数据分离和清理
- 对于主键表,分区列必须是主键的子集,以确保唯一性
该设计确保了高效的数据组织、处理不同用例的灵活性以及遵守数据完整性约束
3.1.3 Table 数据组织

3.1.3.1 Partition
一个分区是根据一个或多个指定列(称为分区列)的值,将表的数据逻辑地划分为更小、更易于管理的子集。 分区列中的每个唯一值(或值的组合)定义了一个不同的分区
3.1.3.2 Bucket
一个Bucket水平地将表/分区的数据根据桶策略划分为N个Bucket。 每个表可以配置N个Bucket的数量。Bucket是数据迁移和备份的最小单位。 Bucket的数据由一个LogTablet和一个(可选的)KvTablet组成
3.1.3.3 LogTablet
每个日志和主键表都需要生成一个LogTablet。 对于日志表,LogTablet既是primary table 数据又是日志数据。对于主键表,LogTablet充当primary table数据的日志数据
- Segment: LogTablet 中日志存储的最小单元。一个Segment由一个 .index 文件和一个 .log 数据文件组成
- .index: 一个offset稀疏索引,用于存储消息中相对于offset的物理字节地址与.log文件之间的映射
- .log: 日志数据的紧凑排列
3.1.3.4 KvTablet
PrimaryKey 表中的每个桶都需要生成一个 KvTablet。底层上,每个 KvTablet 对应一个嵌入的 RocksDB 实例。RocksDB 是一个 LSM(log structured merge)引擎,它帮助 KvTablet 支持高性能更新和查找查询
3.2 表类型
3.2.1 Log Table
日志表是Fluss中的一种表,用于按写入顺序存储数据。日志表仅支持追加记录,不支持更新/删除操作。 通常,日志表用于存储高吞吐量的日志,例如Apache Kafka的典型用例
日志表是在CREATE TABLE语句中未指定PRIMARY KEY子句时创建的。例如,以下Flink SQL语句将创建一个包含3个桶的日志表
CREATE TABLE log_table (
order_id BIGINT,
item_id BIGINT,
amount INT,
address STRING
)
WITH ('bucket.num' = '3');bucket.num 应该是一个正整数。如果未提供此值,集群将使用默认值作为表中的桶号
bucket 分配
bucket是Fluss并行性和可扩展性的基本单元。Fluss中的一个表被划分为多个bucket。bucket是读取和写入的最小存储单元
当将记录写入日志表时,Fluss会根据桶分配策略将每个记录分配到特定的桶中。Fluss中有3种桶分配策略:
-
Sticky Bucket Strategy: 作为默认策略,随机选择一个桶,并持续写入该桶,直到记录批次填满。将client.writer.bucket.no-key-assigner=sticky设置为表属性以启用此策略
-
Round-Robin Strategy: 在写入记录之前,以轮询方式选择一个桶。将client.writer.bucket.no-key-assigner=round_robin设置为表属性以启用此策略
-
Hash-based Bucketing: 如果在表属性中设置了bucket.key属性,Fluss将根据指定桶键的哈希值来确定将记录分配到哪个桶,并且属性client.writer.bucket.no-key-assigner将被忽略。例如,设置'bucket.key' = 'c1,c2'将根据列c1和c2的值来分配桶。不同的列名应该用逗号分隔
Data Consumption
Fluss 中的日志表允许实时数据消费,同时保留每个桶中数据的写入顺序。具体来说
- 对于来自同一表和同一桶的两个数据记录,首先写入Fluss表的数据将被优先消费
- 对于来自同一分区但不同桶的两个数据记录,消费顺序无法保证,因为不同的桶可能会被不同的数据消费作业同时处理
Log Tiering
日志表支持将数据分层存储到不同的存储层级
3.2.2 PrimaryKey Table
Fluss中的主键表确保指定主键的唯一性,并支持INSERT、UPDATE和DELETE操作
通过在CREATE TABLE语句中指定PRIMARY KEY子句来创建一个主键表。例如,以下Flink SQL语句创建了一个主键表,其中shop_id和user_id作为主键,并将数据分布到4个桶中:
CREATE TABLE pk_table (
shop_id BIGINT,
user_id BIGINT,
num_orders INT,
total_amount INT,
PRIMARY KEY (shop_id, user_id) NOT ENFORCED
) WITH (
'bucket.num' = '4'
);在Fluss主键表中,每行数据都有一个唯一的主键。 如果向Fluss主键表中写入多个具有相同主键的条目,则只保留最后一个条目
对于分区主键表,主键必须包含分区键。
bucket分配
对于主键表,Fluss总是根据每个记录的主键哈希值来确定数据属于哪个bucket。 具有相同哈希值的数据将被分配到同一个bucket中
Partial Update
对于主键表,Fluss 支持部分列更新,允许您只写入部分列来逐步更新数据,最终实现完整数据。请注意,写入的列必须包括主键列
例如,考虑以下Fluss主键表:
CREATE TABLE T (
k INT,
v1 DOUBLE,
v2 STRING,
PRIMARY KEY (k) NOT ENFORCED
);假设在开始时,只有k和v1列写入数据+I(1, 2.0)、+I(2, 3.0),T中的数据如下:
| k | v1 | v2 |
|---|---|---|
| 1 | 2.0 | null |
| 2 | 3.0 | null |
然后,将数据 +I(1, 't1')、+I(2, 't2') 写入 k 和 v2 列,结果 T 中的数据如下:
| k | v1 | v2 |
|---|---|---|
| 1 | 2.0 | t1 |
| 2 | 3.0 | t2 |
数据查询
对于主键表,Fluss 支持直接根据键查询数据
Changelog Generation
Fluss 将捕获在主键表上插入、更新、删除记录时的变化,这被称为变更日志。下游消费者可以直接消费变更日志以获取表中的变化。例如,考虑 Fluss 中的以下主键表:
CREATE TABLE T (
k INT,
v1 DOUBLE,
v2 STRING,
PRIMARY KEY (k) NOT ENFORCED
);如果写入主键表的数据是顺序的 +I(1, 2.0, 'apple')、+I(1, 4.0, 'banana')、-D(1, 4.0, 'banana'),那么将生成以下变更数据:
+I(1, 2.0, 'apple')
-U(1, 2.0, 'apple')
+U(1, 4.0, 'banana')
-D(1, 4.0, 'banana')Data Consumption
对于主键表,默认的消费方式是先全量快照,然后是增量数据。首先,消费表的全量快照数据,然后是表的binlog数据。
也可以只消费表中的binlog数据
3.3 数据分布
3.3.1 Bucketing
桶策略是一种数据分布技术,它将表数据分成小块,并将数据分布到多个主机和服务中
当创建Fluss表时,您可以通过为表设置'bucket.num' = ' '属性来指定桶的数量。 目前,Fluss支持3种桶策略:Hash Bucketing、Sticky Bucketing和Round-Robin Bucketing。 主键表只允许使用Hash Bucketing。日志表默认使用Sticky Bucketing,但也可以使用其他两种桶策略。
Hash Bucketing
哈希桶划分在OLAP场景中很常见。 其优势在于可以非常均匀地分布到多个节点上,充分利用分布式计算的能力,并且具有出色的可扩展性(重新划分桶或集群),以应对海量数据。
用法:为表设置'bucket.key' = 'col1, col2'属性,以指定哈希分桶的桶键。 主键表默认使用主键(不包括分区键)作为桶键
Sticky Bucketing
Sticky Bucketing在将记录写入日志表时,能够支持更大的批次并减少延迟。发送一个批次后,Sticky Bucketing会发生变化。随着时间的推移,记录会均匀地分布在所有桶中。 Sticky Bucketing策略是日志表的默认桶策略。这非常重要,因为日志表使用Apache Arrow作为底层数据格式,对于大批次来说非常高效。
用法:为表设置'client.writer.bucket.no-key-assigner'='sticky'属性以启用此策略。主键表不支持此策略
Round-Robin Bucketing
轮询桶策略是一种简单的策略,在写入记录之前,随机选择一个桶。这种策略适用于数据分布相对均匀且数据没有偏斜的场景
用法:为表设置'client.writer.bucket.no-key-assigner'='round_robin'属性以启用此策略。PrimaryKey表不支持此策略
3.3.2 分区表
在Fluss中,一个分区表根据一个或多个分区键组织数据,提供了一种提高查询性能和管理大型数据集的方法。分区允许系统将数据划分为不同的段,每个段对应于分区键的特定值
对于分区表,Fluss 支持自动分区创建。可以根据在创建表时配置的自动分区规则自动创建分区,并且过期的分区会自动删除,确保数据不会无限扩展
分区表的主要好处:
- 改进查询性能:通过将查询范围缩小到特定的分区,系统读取的数据更少,从而减少了查询执行时间
- 数据组织:分区有助于逻辑地组织数据,使其更容易管理和查询
- 可扩展性:对大型数据集进行分区可以将数据分布到更小、更易于管理的块中,从而提高可扩展性
限制:
- 只支持一个分区键,分区键的类型必须是字符串
- 如果表是主键表,则分区键必须是主键的子集
- 自动分区规则只能在创建分区表时进行配置;在表创建后修改自动分区规则是不支持的
自动分区选项
自动分区规则通过表选项进行配置。以下示例演示了如何使用Flink SQL创建一个名为site_access的表,该表支持自动分区。
CREATE TABLE site_access(
event_day STRING,
site_id INT,
city_code STRING,
user_name STRING,
pv BIGINT,
PRIMARY KEY(event_day, site_id) NOT ENFORCED
) PARTITIONED BY (event_day) WITH (
'table.auto-partition.enabled' = 'true',
'table.auto-partition.time-unit' = 'YEAR',
'table.auto-partition.num-precreate' = '5',
'table.auto-partition.num-retention' = '2',
'table.auto_partitioning.time-zone' = 'Asia/Shanghai'
);在这种情况下,当自动分区发生时(Fluss 将定期在后台对所有表进行操作),会预先创建四个分区,分区粒度为"年",保留两个历史分区。时区设置为"Asia/Shanghai"
分区生成规则
自动分区表的时间单位 auto-partition.time-unit 可以取值为 HOUR、DAY、MONTH、QUARTER 或 YEAR。自动分区将使用以下格式创建分区
| Time Unit | Partition Format | Example |
|---|---|---|
| HOUR | yyyyMMddHH | 2024091922 |
| DAY | yyyyMMdd | 20240919 |
| MONTH | yyyyMM | 202409 |
| QUARTER | yyyyQ | 20241 |
| YEAR | yyyy | 2024 |
Fluss集群配置
以下是与Fluss集群和自动分区相关的配置项。
| Option | Type | Default | Description |
|---|---|---|---|
| auto-partition.check.interval | Duration | 10 minutes | 自动分区检查的时间间隔默认设置为10分钟,这意味着它每10分钟检查一次表的分区状态,以查看是否符合自动分区的标准。如果不符合标准,分区将自动创建或删除。 |
3.3.3 TTL
Fluss 支持通过为表设置 TTL 属性来支持数据 TTL,格式为 'table.log.ttl' = ' '(默认值为 7 天)。Fluss 可以定期自动检查并清理表中过期的数据
对于日志表,此属性表示日志表数据的过期时间。 对于主键表,此属性表示其binlog的过期时间,并不代表主键表数据的过期时间。如果您也想让主键表中的数据自动过期,请使用自动分区
3.4 数据类型
Fluss 为用户提供了一组丰富的本地数据类型。Fluss 的所有数据类型如下:
| Data Type | Description |
|---|---|
| BOOLEAN | 一个带有(可能)三值逻辑的布尔值:TRUE, FALSE, UNKNOWN。 |
| TINYINT | 1字节有符号整数,范围从 -128 到 127。 |
| SMALLINT | 2字节有符号整数,范围从 -32,768 到 32,767。 |
| INT | 4字节有符号整数,范围从 -2,147,483,648 到 2,147,483,647。 |
| BIGINT | 8字节有符号整数,范围从 -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807。 |
| FLOAT | 4字节单精度浮点数。 |
| DOUBLE | 8字节双精度浮点数。 |
| CHAR(n) | 固定长度字符字符串,其中 n 是代码点的数量。n 必须在 1 和 Integer.MAX_VALUE 之间(包括两端)。 |
| STRING | 可变长度字符字符串。 |
| DECIMAL(p, s) | 精度和比例固定的十进制数,其中 p 是数字的总位数(=精度),s 是小数点右侧的位数(=比例)。p 必须在 1 和 38 之间(包括两端)。s 必须在 0 和 p 之间(包括两端)。 |
| DATE | 年-月-日格式的日期,范围从 0000-01-01 到 9999-12-31。 |
| TIME | 默认情况下没有时区且无分数秒的时间。实例由小时:分钟:秒组成,精度最高可达秒,范围从 00:00:00 到 23:59:59。不支持闰秒(23:59:60 和 23:59:61),语义上更接近 java.time.LocalTime。 |
| TIME(p) | 没有时区的时间,p 表示分数秒的位数(=精度)。p 必须在 0 和 9 之间(包括两端)。实例由小时:分钟:秒.小数部分组成,精度最高可达纳秒,范围从 00:00:00.000000000 到 23:59:59.999999999。不支持闰秒(23:59:60 和 23:59:61),语义上更接近 java.time.LocalTime。 |
| TIMESTAMP | 默认情况下没有时区的时间戳,分数秒有 6 位。实例由年-月-日 小时:分钟:秒.小数部分组成,精度最高可达微秒,范围从 0000-01-01 00:00:00.000000 到 9999-12-31 23:59:59.999999。不支持闰秒(23:59:60 和 23:59:61),语义上更接近 java.time.LocalDateTime。 |
| TIMESTAMP(p) | 没有时区的时间戳,p 表示分数秒的位数(=精度)。p 必须在 0 和 9 之间(包括两端)。实例由年-月-日 小时:分钟:秒.小数部分组成,精度最高可达纳秒,范围从 0000-01-01 00:00:00.000000000 到 9999-12-31 23:59:59.999999999。不支持闰秒(23:59:60 和 23:59:61),语义上更接近 java.time.LocalDateTime。 |
| TIMESTAMP_LTZ | 带有时区的时间戳,默认分数秒有 6 位。实例由年-月-日 小时:分钟:秒.小数部分 组成,精度最高可达微秒,范围从 0000-01-01 00:00:00.000000 +14:59 到 9999-12-31 23:59:59.999999 -14:59。不支持闰秒(23:59:60 和 23:59:61),语义上更接近 java.time.OffsetDateTime。 |
| TIMESTAMP_LTZ(p) | 带有时区的时间戳,p 表示分数秒的位数(=精度)。p 必须在 0 和 9 之间(包括两端)。实例由年-月-日 小时:分钟:秒.小数部分 组成,精度最高可达纳秒,范围从 0000-01-01 00:00:00.000000000 到 9999-12-31 23:59:59.999999999。不支持闰秒(23:59:60 和 23:59:61),语义上更接近 java.time.LocalDateTime。 |
| BYTES | 可变长度二进制字符串(=字节序列)。 |
4. 流式湖仓
Lakehouse 代表了一种新的开放架构,它结合了数据湖和数据仓库的最佳元素。 它将数据湖的可扩展性和成本效益与数据仓库的可靠性和性能相结合。 众所周知的数据湖格式,如 Apache Iceberg、Apache Paimon、Apache Hudi 和 Delta Lake 在 Lakehouse 架构中扮演着关键角色, 促进在单一、统一平台内数据存储、可靠性和分析能力之间的和谐平衡。 湖仓作为现代架构,在解决数据管理和分析复杂需求方面非常有效。 但由于它们的实现限制,它们很难满足需要亚秒级数据新鲜度的实时分析场景。 使用这些数据湖格式,你会陷入一个矛盾的局面:
1.如果你需要低延迟,那么你需要频繁地写入和提交,这意味着会有很多小的 Parquet 文件。这对于必须处理大量小文件的读取操作来说变得低效
2.如果你需要读取效率,那么你会累积数据,直到可以写入大型 Parquet 文件,但这会引入 更高的延迟
总体而言,这些数据湖格式在最佳使用条件下,通常也只能达到分钟级的数据新鲜度
流处理与湖仓一体化
Fluss 是一种支持亚秒级低延迟的流式存储,支持流式读取和写入。 Fluss 通过在 Lakehouse 之上提供实时流数据,将数据流和数据 Lakehouse 统一。 这不仅为数据 Lakehouse 带来了低延迟,还为数据流增加了强大的分析功能
为了构建Streaming Lakehouse,Fluss维护了一个压缩服务,用于将Fluss集群中的实时数据压缩到Lakehouse存储中。 Fluss集群中的数据(流式Arrow格式)针对低延迟读写进行了优化,而Lakehouse中的压缩数据(带有压缩的Parquet格式)则针对强大的分析和存储长期数据进行了优化。 因此,Fluss集群中的数据服务于实时数据层,保留具有亚秒级新鲜度的几天数据,而Lakehouse中的数据服务于历史数据层,保留具有分钟级新鲜度的几个月数据
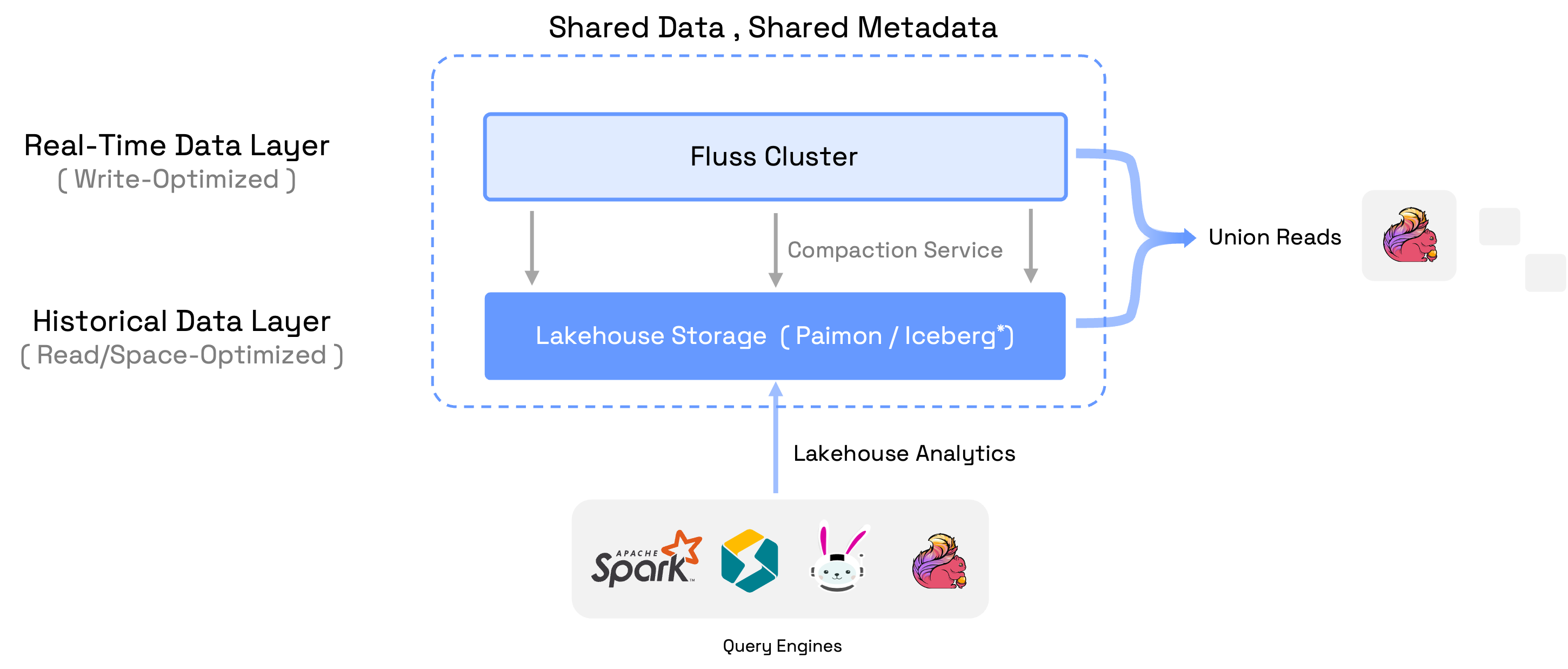
Streaming Lakehouse 的核心思想是流和 Lakehouse 之间的共享数据和共享元数据,避免数据重复和元数据不一致。 它提供的一些强大功能包括:
- 统一元数据:Fluss为Stream和Lakehouse中的数据提供了一个统一的表元数据。因此,用户只需处理一个表,但可以访问实时流数据、历史数据或它们的联合
- Union Reads:计算引擎在表上执行查询时,将读取实时流数据与Lakehouse数据的联合。目前,只有Flink支持联合读取,但更多引擎已在roadmap上
- 实时湖仓:联合读取有助于湖仓从近实时分析发展到真正的实时分析。这使得企业能够从实时数据中获得更有价值的洞察
- 流式分析:该联合读取帮助数据流以具备强大的分析能力。这减少了开发流应用程序的复杂性,简化了调试过程,并允许立即访问实时数据洞察
- 连接到Lakehouse生态系统:Fluss将表元数据与数据湖目录保持同步,同时将数据压缩到Lakehouse中。这使得外部引擎如Spark、StarRocks、Flink、Trino可以直接通过连接到数据湖目录来读取数据
目前,Fluss 支持 Paimon 作为 Lakehouse 存储,更多种类的数据湖格式将在roadmap中
5. How
下面使用Apache Flink进行实时分析,涵盖Fluss的一些强大功能,包括与Paimon的集成
5.1 安装docker
-
设置docker yum源
sudo yum install -y yum-utils
sudo yum-config-manager
--add-repo
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -
安装docker
sudo yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
-
启动docker
sudo systemctl start docker
-
设置开机自启动
sudo systemctl enable docker
-
docker镜像配置
创建目录
sudo mkdir -p /etc/docker
写入配置文件
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [ "https://docker-0.unsee.tech", "https://docker-cf.registry.cyou", "https://docker.1panel.live" ]}
EOF
重启docker服务
sudo systemctl daemon-reload && sudo systemctl restart docker
5.2 启动所需要的组件
-
创建工作目录
mkdir fluss-quickstart-flink & cd fluss-quickstart-flink
-
创建一个名为docker-compose.yml的文件
services:
coordinator-server:
image: fluss/fluss:0.5.0
command: coordinatorServer
depends_on:
- zookeeper
environment:
- |
FLUSS_PROPERTIES=
zookeeper.address: zookeeper:2181
coordinator.host: coordinator-server
remote.data.dir: /tmp/fluss/remote-data
lakehouse.storage: paimon
paimon.catalog.metastore: filesystem
paimon.catalog.warehouse: /tmp/paimon
tablet-server:
image: fluss/fluss:0.5.0
command: tabletServer
depends_on:
- coordinator-server
environment:
- |
FLUSS_PROPERTIES=
zookeeper.address: zookeeper:2181
tablet-server.host: tablet-server
data.dir: /tmp/fluss/data
remote.data.dir: /tmp/fluss/remote-data
kv.snapshot.interval: 0s
lakehouse.storage: paimon
paimon.catalog.metastore: filesystem
paimon.catalog.warehouse: /tmp/paimon
zookeeper:
restart: always
image: zookeeper:3.8.4jobmanager:
image: fluss/quickstart-flink:1.20-0.5
ports:
- "8083:8081"
command: jobmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
volumes:
- shared-tmpfs:/tmp/paimon
taskmanager:
image: fluss/quickstart-flink:1.20-0.5
depends_on:
- jobmanager
command: taskmanager
environment:
- |
FLINK_PROPERTIES=
jobmanager.rpc.address: jobmanager
taskmanager.numberOfTaskSlots: 10
taskmanager.memory.process.size: 2048m
taskmanager.memory.framework.off-heap.size: 256m
volumes:
- shared-tmpfs:/tmp/paimonvolumes:
shared-tmpfs:
driver: local
driver_opts:
type: "tmpfs"
device: "tmpfs"
Docker Compose 环境由以下容器组成:
- Fluss集群:一个Fluss CoordinatorServer,一个Fluss TabletServer 和一个ZooKeeper服务器
- Flink集群:一个Flink JobManager 和一个Flink TaskManager 容器,用于执行查询。
注意: fluss/quickstart-flink 镜像是基于 flink:1.20.0-java17,并包含 fluss-connector-flink、paimon-flink 和 flink-connector-faker
-
要启动所有容器,请运行:
docker compose up -d
该命令会自动以分离模式启动Docker Compose配置中定义的所有容器
docker ps检查所有容器是否正常运行

您也可以访问 http://localhost:8083/,查看 Flink 是否正常运行
如果你想使用自己的Flink环境运行,请记得下载fluss-connector-flink、flink-connector-faker、paimon-flink连接器的jar文件,并将它们放入FLINK_HOME/lib/
所有涉及docker compose的以下命令应在包含docker-compose.yml文件的创建工作目录中执行
5.3 进入SQL客户端
首先,使用以下命令进入 Flink SQL CLI 容器:
docker compose exec jobmanager ./sql-client注意: 为了简化本指南,已预先创建了三个临时表,使用faker连接器生成数据。 您可以通过运行以下命令查看它们的模式:
show create table source_customer
5.4 创建Fluss表格
5.4.1 创建fluss catalog
CREATE CATALOG my_fluss WITH (
'type' = 'fluss',
'bootstrap.servers' = 'coordinator-server:9123'
);
USE CATALOG my_fluss;5.4.2 创建表
运行以下 SQL 来创建 Fluss 表:
CREATE TABLE fluss_order (
`order_key` BIGINT,
`cust_key` INT NOT NULL,
`total_price` DECIMAL(15, 2),
`order_date` DATE,
`order_priority` STRING,
`clerk` STRING,
`ptime` AS PROCTIME(),
PRIMARY KEY (`order_key`) NOT ENFORCED
);
CREATE TABLE fluss_customer (
`cust_key` INT NOT NULL,
`name` STRING,
`phone` STRING,
`nation_key` INT NOT NULL,
`acctbal` DECIMAL(15, 2),
`mktsegment` STRING,
PRIMARY KEY (`cust_key`) NOT ENFORCED
);
CREATE TABLE `fluss_nation` (
`nation_key` INT NOT NULL,
`name` STRING,
PRIMARY KEY (`nation_key`) NOT ENFORCED
);
CREATE TABLE enriched_orders (
`order_key` BIGINT,
`cust_key` INT NOT NULL,
`total_price` DECIMAL(15, 2),
`order_date` DATE,
`order_priority` STRING,
`clerk` STRING,
`cust_name` STRING,
`cust_phone` STRING,
`cust_acctbal` DECIMAL(15, 2),
`cust_mktsegment` STRING,
`nation_name` STRING,
PRIMARY KEY (`order_key`) NOT ENFORCED
);5.5 流式写入 Fluss
首先,运行以下 SQL 将数据从源表同步到 Fluss 表
EXECUTE STATEMENT SET
BEGIN
INSERT INTO fluss_nation SELECT * FROM `default_catalog`.`default_database`.source_nation;
INSERT INTO fluss_customer SELECT * FROM `default_catalog`.`default_database`.source_customer;
INSERT INTO fluss_order SELECT * FROM `default_catalog`.`default_database`.source_order;
END;Fluss 主键表支持高 QPS(每秒查询率)的主键点查查询。执行查找连接(lookup join)非常高效,您可以使用它来通过 fluss_customer 和 fluss_nation 主键表中的信息丰富 fluss_orders 表
INSERT INTO enriched_orders
SELECT o.order_key,
o.cust_key,
o.total_price,
o.order_date,
o.order_priority,
o.clerk,
c.name,
c.phone,
c.acctbal,
c.mktsegment,
n.name
FROM fluss_order o
LEFT JOIN fluss_customer FOR SYSTEM_TIME AS OF `o`.`ptime` AS `c`
ON o.cust_key = c.cust_key
LEFT JOIN fluss_nation FOR SYSTEM_TIME AS OF `o`.`ptime` AS `n`
ON c.nation_key = n.nation_key;5.6 在 Fluss 表上运行临时查询
现在,您可以直接在 Fluss 表上执行实时分析。例如,要计算特定客户下的订单数量,您可以执行以下 SQL 查询以获得即时的、实时的结果
-- use tableau result mode
SET 'sql-client.execution.result-mode' = 'tableau';
-- switch to batch mode
SET 'execution.runtime-mode' = 'batch';
-- use limit to query the enriched_orders table
SELECT * FROM enriched_orders LIMIT 2;结果:

如果您对特定客户感兴趣,可以通过在 cust_key 上执行查找来检索其详细信息。例如,您可以使用以下 SQL 查询来获取特定客户的详细信息:
-- lookup by primary key
SELECT * FROM fluss_customer WHERE `cust_key` = 1;
总体来说,查询结果能够非常快速地返回,因为 Fluss 为定义了主键的表启用了高效的主键查找功能
5.7 Update/Delete rows on Fluss Tables
您可以使用 UPDATE 和 DELETE 语句来更新或删除 Fluss 表中的行
5.7.1 Update
-- update by primary key
UPDATE fluss_customer SET `name` = 'fluss_updated' WHERE `cust_key` = 1;
name列的数据已经更新成了fluss_updated
5.7.2 Delete
DELETE FROM fluss_customer WHERE `cust_key` = 1;
5.8 集成pamion
5.8.1 启动 Lakehouse 分层服务
要与 Apache Paimon 集成,您需要启动 Lakehouse 分层服务。请打开一个新的终端,导航到 fluss-quickstart-flink 目录,并在此目录中执行以下命令以启动该服务:
docker compose exec coordinator-server ./bin/lakehouse.sh -D flink.rest.address=jobmanager -D flink.rest.port=8081 -D flink.execution.checkpointing.interval=30s在 Flink Web UI 中看到一个名为 fluss-paimon-tiering-service 的运行中的 Flink 作业

5.8.2 将数据流式写入 Fluss 数据湖启用的表
默认情况下,表的创建是不启用数据湖集成的,这意味着 Lakehouse 分层服务不会将表的数据分层存储到数据湖中。
要为表启用作为分层存储解决方案的Lakehouse功能,您必须使用配置选项 table.datalake.enabled = true 创建该表。请返回 SQL 客户端并执行以下 SQL 语句,以创建启用了数据湖集成的表:
CREATE TABLE datalake_enriched_orders (
`order_key` BIGINT,
`cust_key` INT NOT NULL,
`total_price` DECIMAL(15, 2),
`order_date` DATE,
`order_priority` STRING,
`clerk` STRING,
`cust_name` STRING,
`cust_phone` STRING,
`cust_acctbal` DECIMAL(15, 2),
`cust_mktsegment` STRING,
`nation_name` STRING,
PRIMARY KEY (`order_key`) NOT ENFORCED
) WITH ('table.datalake.enabled' = 'true');接下来,执行流式数据写入到启用了数据湖的表 datalake_enriched_orders 中
-- switch to streaming mode
SET 'execution.runtime-mode' = 'streaming';
-- insert tuples into datalake_enriched_orders
INSERT INTO datalake_enriched_orders
SELECT o.order_key,
o.cust_key,
o.total_price,
o.order_date,
o.order_priority,
o.clerk,
c.name,
c.phone,
c.acctbal,
c.mktsegment,
n.name
FROM fluss_order o
LEFT JOIN fluss_customer FOR SYSTEM_TIME AS OF `o`.`ptime` AS `c`
ON o.cust_key = c.cust_key
LEFT JOIN fluss_nation FOR SYSTEM_TIME AS OF `o`.`ptime` AS `n`
ON c.nation_key = n.nation_key;5.8.3 Fluss 数据湖启用表上的实时分析
datalake_enriched_orders 表的数据存储在两个地方:Fluss(用于实时数据)和 Paimon(用于历史数据)
当查询 datalake_enriched_orders 表时,Fluss 使用联合操作(union operation),将来自 Fluss 和 Paimon 的数据合并在一起,以提供完整的数据集------即结合了实时数据和历史数据的结果.
如果您只想查询存储在 Paimon 中的数据------这样可以提供高性能访问而无需承担联合数据的开销------您可以使用带有 \(lake 后缀的 datalake_enriched_orders\)lake 表。这种方法也启用了所有 Flink Paimon table source 的优化和特性,包括系统表,如datalake_enriched_orders\(lake\)snapshots
要直接从 Paimon 查询快照,请使用以下 SQL 语句:
-- switch to batch mode
SET 'execution.runtime-mode' = 'batch';
-- query snapshots in paimon
SELECT snapshot_id, total_record_count FROM datalake_enriched_orders$lake$snapshots;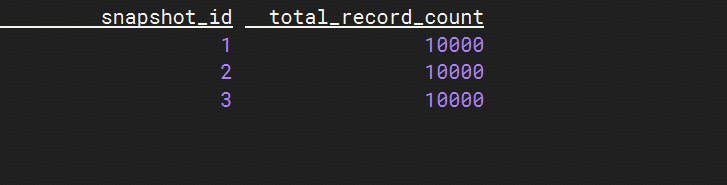
确保在查询快照之前等待检查点(~30秒)完成,否则结果将是空的
要对 Paimon 中的数据进行分析,请运行以下 SQL 语句:
-- to sum prices of all orders in paimon
SELECT sum(total_price) as sum_price FROM datalake_enriched_orders$lake;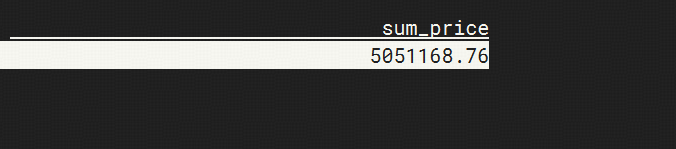
为了实现亚秒级的数据新鲜度,您可以直接查询表,这将无缝统一来自 Fluss 和 Paimon 的数据
-- to sum prices of all orders in fluss and paimon
SELECT sum(total_price) as sum_price FROM datalake_enriched_orders;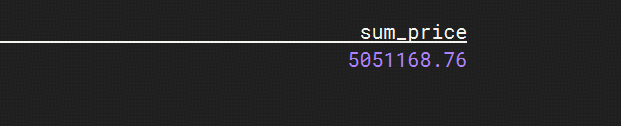
您可以多次执行实时分析查询,并且每次的结果可能会有所不同,因为新的数据会持续实时地写入 Fluss。随着新数据的流入,查询结果将反映出最新的状态
最终,您可以使用以下命令来查看存储在 Paimon 中的文件
docker compose exec taskmanager tree /tmp/paimon/fluss.db
[root@bigdata-bussiness-prod fluss-quickstart-flink]# docker compose exec taskmanager tree /tmp/paimon/fluss.db
/tmp/paimon/fluss.db
└── datalake_enriched_orders
├── bucket-0
│ ├── changelog-c283a7b6-eb51-41cd-9950-5898a509baf1-0.orc
│ └── data-c283a7b6-eb51-41cd-9950-5898a509baf1-1.orc
├── manifest
│ ├── manifest-7c574c54-03f6-4b93-81e6-ef19d798868d-0
│ ├── manifest-7c574c54-03f6-4b93-81e6-ef19d798868d-1
│ ├── manifest-list-f14c24ba-8c1b-4cd7-8186-0a195a1509f9-0
│ ├── manifest-list-f14c24ba-8c1b-4cd7-8186-0a195a1509f9-1
│ ├── manifest-list-f14c24ba-8c1b-4cd7-8186-0a195a1509f9-2
│ ├── manifest-list-f14c24ba-8c1b-4cd7-8186-0a195a1509f9-3
│ ├── manifest-list-f14c24ba-8c1b-4cd7-8186-0a195a1509f9-4
│ ├── manifest-list-f14c24ba-8c1b-4cd7-8186-0a195a1509f9-5
│ └── manifest-list-f14c24ba-8c1b-4cd7-8186-0a195a1509f9-6
├── schema
│ └── schema-0
└── snapshot
├── EARLIEST
├── LATEST
├── snapshot-1
├── snapshot-2
└── snapshot-3Paimon 存储的文件遵循标准格式,这使得它们可以与其它查询引擎(如 StarRocks)无缝集成和查询
5.9 clean up
停止所有的容器
docker compose down -v