在 "十四五" 规划全面推进国产化替代的背景下,**某大型电网企业联合镜舟科技与腾讯云,基于全球领先的开源分析型数据库 StarRocks 及腾讯 TBDS 大数据平台,构建电力行业国产化湖仓一体架构。**该项目实现 PB 级电力数据的统一管理,为能源行业核心系统国产化升级提供了可复制的技术范本。
数字电力正面临日益复杂的数据挑战
随着数字化转型深入推进,该电网企业作为服务超 2.5 亿用户的特大型能源企业,面临着日益复杂的数据管理挑战:
- **数据链路复杂,时效性低:**数据供给路径冗长,导致延迟高,无法满足实时性要求。
- **资源瓶颈:**计算集群资源紧张,CPU 和 IO 高负载,限制了性能扩展。
- **高并发挑战:**先有的业务大量使用宽表设计,查询并发压力剧增,现有架构难以支撑。
- **融合计算能力不足:**数据分散,跨集群融合计算能力缺失,限制了个性化需求支持。
- **数据治理难度大:**全域的数据资产建设,没有统一的主题划分,数据分散。
解决方案:基于 StarRocks+TBDS 构建统一数据平台
作为 StarRocks 核心商业化公司,镜舟科技联合腾讯云为该电网企业设计了一套分层渐进式的技术升级方案。
该方案核心在于优化数据链路,通过缩短供给路径并引入实时分析引擎,有效提升数据时效性。同时,通过扩展集群规模提升资源利用率,解决计算资源瓶颈问题。
针对高并发查询压力,镜舟团队对查询引擎进行深度优化,增强缓存机制和负载均衡能力。此外,通过构建统一数据平台,实现跨集群数据整合和计算,满足多样化的分析需求,并为数据治理奠定坚实基础。
在该电网企业实际业务场景下的 POC 测试中,StarRocks 展现了显著的性能优势:现网系统查询耗时:1513 秒,StarRocks 查询耗时:0.176 秒,实现近 8600 倍的查询加速。
1. 基于 StarRocks+TBDS 的湖仓技术架构
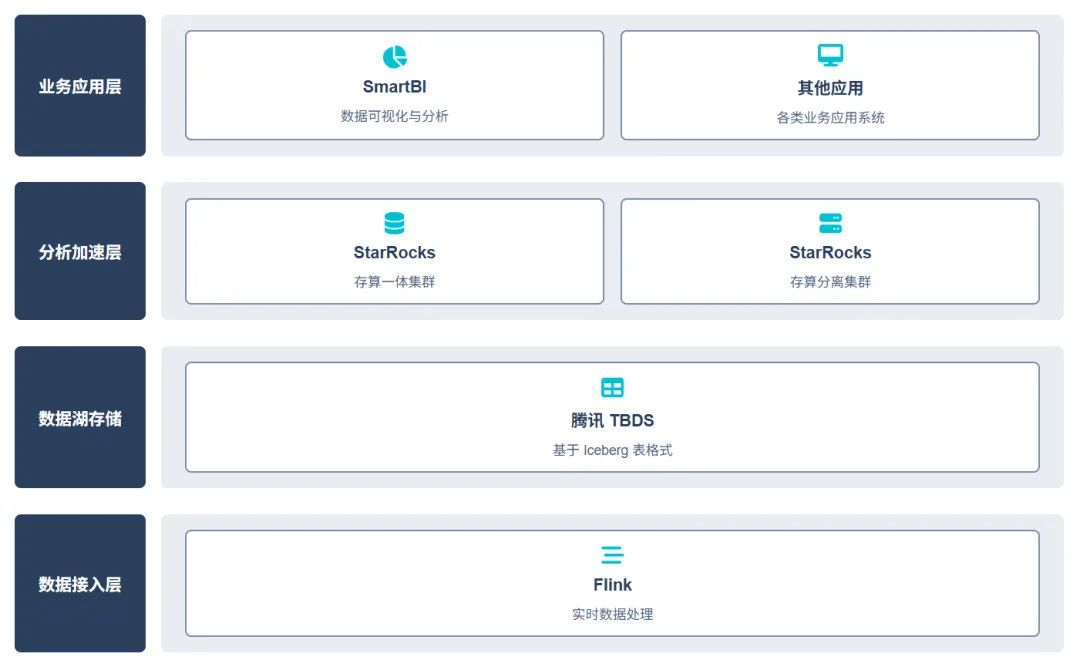
该电网企业的湖仓架构包含四个关键层次,包含从数据采集到业务应用的全链路:
- 数据接入层:Flink 实时数据处理
- 数据湖存储:腾讯 TBDS(Iceberg 表格式)
- 分析加速层:StarRocks 多集群(存算一体 + 存算分离)
- 业务应用层:SmartBI 等可视化工具
2. 关键技术提升整体性能
方案实施过程中,团队重点解决了三大技术难题,确保系统平稳过渡的同时提升整体性能:
1. 国产化适配验证:
完成包括海光芯片和麒麟 V10 操作系统在内的全栈国产化适配验证,保障系统在国产化基础设施上的稳定运行。
2. 业务平滑迁移:
通过支持 Greenplum 语法兼容,成功保障了存量业务的平滑迁移,并利用多集群架构实现了网级与省侧业务高效协同。
3. 湖仓数据统一协同:
基于腾讯 TBDS 数据湖构建统一元数据目录,同时借助 Flink 实现实时数据入湖,StarRocks 提供强大的分析加速能力,形成完整的数据流转与处理闭环。
StarRocks 数据底座:电力业务腾飞的新引擎
此次升级帮助该电网企业进一步构建统一的基础数据底座,为各业务平台提供数据存储、处理、治理、建模和计算分析等全数据生命周期能力服务,支撑网省各级单位数据应用需求。
- 业务连续性保障:StarRocks 兼容 Greenplum 近 10 万条 SQL 语法。支持渐进式改造,存算分离与存算一体混合部署模式灵活可选。
- 架构扩展性提升:多集群架构实现分散 MPP 集群的统一纳管,弹性扩缩容能力适配业务增长需求。
- 技术自主可控:全国产化技术栈(海光芯片 + 麒麟系统),并与腾讯 TBDS 实现数据湖管理标准统一。
未来,镜舟科技将持续完善 StarRocks 与腾讯 TBDS 的深度协同,为关键行业提供安全可靠的数据基座。
镜舟科技:企业级数据分析基座构建者
作为 StarRocks 开源项目的主要贡献者及商业化领军企业,镜舟科技基于 "开源 + 商业化" 双引擎模式,通过企业级产品镜舟数据库(Mirrorship)为企业级用户打造专业的 Lakehouse 解决方案:
- 技术领先性:镜舟数据库支持 PB 级实时分析的分布式数据库,同时镜舟科技技术团队深度参与 StarRocks 开源社区建设,并基于此给企业级用户提供更多技术保障。
- 行业实践经验积累:镜舟科技已成功支撑金融、智能制造等领域的数据分析平台建设,企业级客户已覆盖超百家头部企业。