首先我们的 kafka 的消息本身是存储在日志段中的, 对应的源码是下面这段代码:
scala
class LogSegment private[log] (val log: FileRecords,
val lazyOffsetIndex: LazyIndex[OffsetIndex],
val lazyTimeIndex: LazyIndex[TimeIndex],
val txnIndex: TransactionIndex,
val baseOffset: Long,
val indexIntervalBytes: Int,
val rollJitterMs: Long,
val time: Time) extends Logging { ... }一个日志段包含消息日志文件、位移索引文件、时间戳索引文件、已中止事务索引文件等。这里的 FileRecords 就是实际保存 Kafka 消息的对象。
索引文件通常是以.index 为结尾的:
.offsetIndex我们可以根据位移索引文件定位到记录在那个log 文件,.timeindex:是时间索引文件,是用来帮助Kafka通过时间戳来查找对应记录的位移信息。
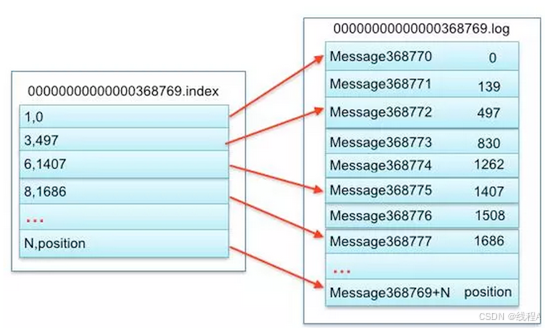
- baseOffset 表示基础偏移量, 对应着文件名称, 注意这个开始位移在一开始就是固定的。
- indexIntervalBytes 值其实就是 Broker 端参数 log.index.interval.bytes 值,它控制了日志段对象新增索引项的频率。默认情况下一般需要达到4kb 才会创建新的索引项
- rollJitterMs 是日志段对象新增倒计时的"扰动值"。因为目前 Broker 端日志段新增倒计时是全局设置,这就是说,在未来的某个时刻可能同时创建多个日志段对象,这将极大地增加物理磁盘 I/O 压力。有了 rollJitterMs 值的干扰,每个新增日志段在创建时会彼此岔开一小段时间,这样可以缓解物理磁盘的 I/O 负载瓶颈。
这个扰动值含义是当前避免同时多个线程同时向磁盘中写入对应的数据
关于这个LogSegment 是存在与之相关的方法的, 主要有三个方法, 分别是对应的 append 方法, read 方法, 以及对应的 recover 方法。
首先我们看一下对应的append 函数
scala
def append(largestOffset: Long,
largestTimestamp: Long,
shallowOffsetOfMaxTimestamp: Long,
records: MemoryRecords): Unit;- 这个函数首先会判断当前日志段时候为空, 如果为null, 我们就需要写入对应的最大时间戳
- 确保对应的最大位移值是正确的, 如果不正确的话是不给写入的
- 执行真正的写入操作
- 更新最大时间戳, 最大的位移值
- 更新写入的字节数量
和日志段相关的第二个相关的操作是 read 函数, 这个函数接受了四个参数, 分别是:
- 要读取的第一条消息的位移
- 能读取消息的最大位移数量
- 能读取的最大文件位置
- 是否允许消息体过大的时候至少返回对应的消息
和日志段相关的第三个操作是 recover 函数,在消息系统中, 日志被分成了多个日志段, 每个日志段包含一定数量的消息,这些日志消息被保存在磁盘上面,
recover 方法的作用是确保在 Broker 启动时,能够正确地从磁盘加载日志段数据,并将其恢复到一个一致的状态,以便后续的读写操作能够正常进行。