银行的数据智能平台和Cloudera CDP 7.3(CMP 7.3)的技术对接
面向银行场景的、保姆级详细技术对接方案 ,涵盖从环境准备、安全合规、数据集成、模型开发到运维监控的全流程,适用于将银行自建的数据智能平台 (Data Intelligence Platform)与 Cloud Data AI CMP 7.3 Private Cloud Base/Plus 进行深度集成。
📌 适用对象:银行科技部、数据中台团队、大数据平台工程师
🎯 目标:实现"数据智能平台"调用 CMP 的存储、计算、AI 能力,同时满足金融行业安全、审计、高可用要求
一、整体架构图(逻辑视图)
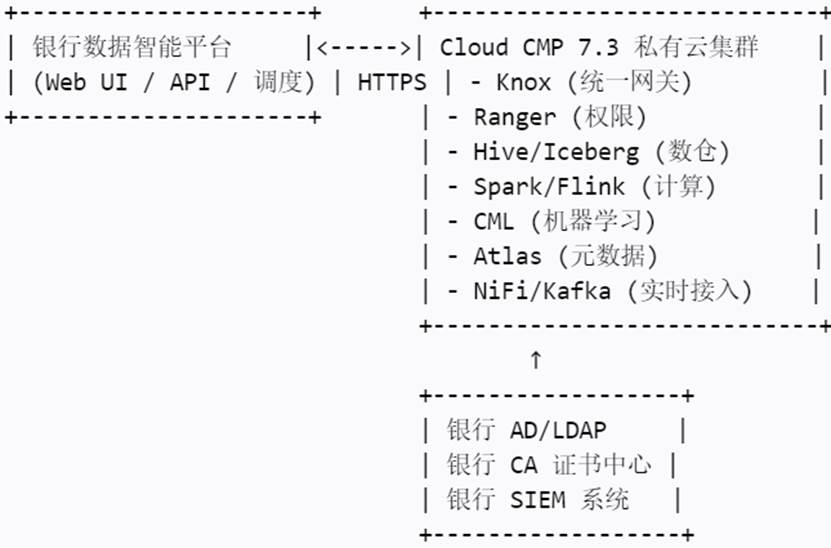
二、前置条件确认
| 项目 | 要求 |
|---|---|
| CMP 版本 | CMP Private Cloud Base 或 Plus 7.3.x(非 Public Cloud) |
| 部署模式 | On-premises(物理机/VM),支持 Kerberos + TLS |
| 网络 | 与数据智能平台同内网,防火墙开放指定端口 |
| 身份源 | 银行已部署 Active Directory 或 LDAP |
| 证书 | 银行内部 CA 可签发 TLS 证书(用于 Knox、HiveServer2 等) |
三、分步对接操作指南(保姆级)
▶ 步骤 1 :CMP 集群基础配置
1.1 启用安全认证(Kerberos + LDAP )
在 Cloud Data AI Manager 中操作
- Administration → Settings → Security
-
Authentication: Enable Kerberos
-
KDC Type: MIT KDC 或 Microsoft AD
- 配置 LDAP 同步:
-
External Authentication → LDAP
-
Server URL: ldaps://ad.bank.local:636
-
Bind DN: svc_CMP@bank.local
-
User Search Base: OU=Users,DC=bank,DC=local
-
Group Search Base: OU=Groups,DC=bank,DC=local
- 测试用户登录 Hue / CML
1.2 配置 Knox 作为统一入口(关键!)
- 启用 Knox 服务
- 配置 Topology(如 CMP-gateway.xml):
Xml
编辑
<topology>
<gateway>
<provider>
<role>authentication</role>
<name>ShiroProvider</name>
<enabled>true</enabled>
<param><name>sessionTimeout</name><value>30</value></param>
</provider>
<provider>
<role>identity-assertion</role>
<name>Default</name>
<enabled>true</enabled>
</provider>
</gateway>
<service>
<role>HIVE</role>
<url>http://hive-server2:10001/cliservice\</url>
</service>
<service>
<role>SPARKLIVY</role>
<url>http://livy-server:8998</url>
</service>
<service>
<role>CML</role>
<url>https://cml-master:443</url>
</service>
</topology>
- 所有外部访问必须通过:https://knox-host:8443/gateway/CMP-gateway/...
✅ 优势:隐藏内部组件 IP,统一 TLS 加密,集中认证。
▶ 步骤 2 :数据接入对接(银行 → CMP )
场景:每日 T+1 客户交易数据入湖
方案 A :使用 Apache NiFi (推荐)
- 在 CMP 上启用 NiFi 服务
- 创建 Flow:
- Input:SFTP / JDBC / REST(连接银行 Oracle/DB2)
- Process:Validate CSV → Convert to Parquet → Encrypt PII
- Output:PutHDFS → 写入 /data/ods/txn_daily/yyyyMMdd/
- 配置 NiFi 使用 Kerberos 认证访问 HDFS
- 触发方式:
- 定时调度(NiFi Schedule)
- 或由银行调度平台调用 NiFi REST API 启动 Flow
方案 B :批量导入(Sqoop + Oozie )
Sqoop Job 示例(通过 Knox Livy 提交)
sqoop import \
--connect jdbc:oracle:thin:@//db.bank.local:1521/ORCL \
--username bank_user \
--password-file /user/CMP/.passwd \
--table TXN_HISTORY \
--target-dir /data/ods/txn_raw \
--as-parquetfile \
--incremental append \
--check-column TXN_DATE
💡 所有密码使用 Hadoop Credential Provider 加密存储。
▶ 步骤 3 :计算与模型对接(智能平台 ↔ CMP )
3.1 智能平台提交 Spark 作业
- 方式:通过 Livy API (经 Knox )
Python
Python 示例(数据智能平台后端调用)
import requests
livy_url = "https://knox.bank.local:8443/gateway/CMP-gateway/livy/v1/batches"
headers = {
"Content-Type": "application/json",
"Authorization": "Basic base64(user:pass)" # 或 Token
}
payload = {
"file": "hdfs:///apps/risk_score.py",
"className": "com.bank.RiskScoring",
"args": "--date", "20251231",
"conf": {
"spark.executor.memory": "4g",
"spark.sql.catalogImplementation": "hive"
}
}
resp = requests.post(livy_url, json=payload, headers=headers, verify='/etc/ssl/certs/bank-ca.pem')
3.2 在 CML 中部署模型 API (供智能平台调用)
- 登录 CML → Create Project → Python 3.9
- 编写模型服务:
Python
model.py
from cml.models import model
import joblib
model_file = joblib.load("fraud_model.pkl")
@model
def predict(transaction_amount, user_age, ...):
features = transaction_amount, user_age, ...
return {"risk_score": float(model_file.predict_proba(features)01)}
- Deploy as API → 获取 Endpoint URL:
Text:
https://cml.bank.local/api/altus-ds-1/models/call-model
- 数据智能平台调用(带 API Key):
Bash
curl -X POST https://cml.bank.local/... \
-H "Authorization: Bearer <API_KEY>" \
-d '{"transaction_amount": 5000, "user_age": 35}'
🔐 API Key 由 CML 管理,可绑定到特定 AD 用户/组。
▶ 步骤 4 :元数据与治理对接
4.1 启用 Atlas 并同步到银行治理平台
- 在 CMP 中启用 Atlas 服务
- 验证自动捕获:
- Hive 表创建 → Atlas 显示实体
- Spark 作业读写 → 生成血缘 Lineage
- 推送元数据到银行治理平台 (如 DataHub、自研系统):
- 方式 1:Atlas Hook + Kafka → 银行消费
- 方式 2:定时调用 Atlas REST API 导出 JSON
Bash
curl -u admin:admin http://atlas-host:21000/api/atlas/v2/search/basic?typeName=hive_table
4.2 敏感数据打标与脱敏
- 在 Ranger 中创建策略:
- Resource: hive; default; customer_info; id_card
- Policy Type: Masking
- Masking Option: Show first 3 chars, rest as ****
- 银行用户查询时自动脱敏,无需改 SQL。
▶ 步骤 5 :安全与合规加固
| 要求 | 配置项 |
|---|---|
| 传输加密 | 所有服务启用 TLS 1.2+,证书由银行 CA 签发 |
| 存储加密 | HDFS 启用 Transparent Data Encryption (TDE),密钥由银行 KMS 管理 |
| 审计日志 | Ranger Audit → Solr;CM Logs → Fluentd → 银行 ELK |
| 最小权限 | 禁用默认账户;服务账户仅授权必要权限 |
| 漏洞扫描 | 定期使用 Nessus 扫描 CMP 组件 |
📜 符合《金融行业网络安全等级保护实施指引》三级要求。
▶ 步骤 6 :监控与告警对接
- 指标采集 :
- 部署 Prometheus Node Exporter + CM Exporter
- 抓取指标:yarn_queue_memory_used, hdfs_capacity_remaining
- 告警规则 (Grafana):
- HDFS 使用率 > 85% → 企业微信告警
- Kafka Lag > 10000 → 邮件通知
- 对接银行运维平台 :
- 通过 Webhook 发送告警到银行 Zabbix/Open-Falcon
四、常见问题与避坑指南
| 问题 | 解决方案 |
|---|---|
| Knox 返回 401 | 检查 ShiroProvider 配置,确认 LDAP 用户存在 |
| Spark 作业无法读 Hive 表 | 确保 hive-site.xml 在 Spark Conf 中,且用户有 Ranger 权限 |
| CML 模型部署失败 | 检查 Docker 镜像拉取权限,CML 需访问内部 Harbor |
| Atlas 血缘不完整 | 确保 Spark 作业使用 spark.sql.queryExecutionListeners=org.apache.atlas.spark.AtlasSparkListener |
| 性能慢 | 调整 YARN 队列资源,Hive LLAP 开启 |
五、交付物清单(项目验收)
- CMP 集群安全加固报告
- 数据接入流程文档(含 NiFi Flow 图)
- 模型 API 调用示例代码(Python/Java)
- Ranger 权限策略截图
- Atlas 血缘截图(从源表到模型)
- 监控看板 URL(Grafana)
- 应急回滚方案(如 CMP 故障切换)
六、参考链接