
前记
这篇年度总结其实酝酿了许久,却因诸多原因拖至腊月底,此时赶在春节前发出来,也不失为"农历版"年度总结了。所谓年度总结,一般是"温故而知新",我不太想落入堆叠数字指标的"秀肌肉式"窠臼,而是想分享一下2024年我们(蚂蚁图计算团队)在「Graph+AI」开源技术方向的实践过程和思考,和大家聊一聊这个技术方向带给了我们什么,面向2025年还有哪些有意思的事情可以继续探索。
屋外寒风瑟瑟,时而夹杂着几滴冬雨拍打至窗前,伴着书桌上咖啡的徐徐热气,我们开启年初的回忆......
1. 时代变革
2022年底ChatGPT发布,开启了大模型时代的技术热。首当其冲的自然是模型训练,诸多厂商纷纷加入「技术信仰派」的行列,直到后来众所周知的「百模大战」。另一方面是基于大模型的智能化应用建设,造就了更广大的「市场信仰派」群体,「提示工程」、「模型微调」、「RAG」、「智能体」等技术热点名词更是层出不穷。
在市场信仰派中,应用软件属于较早探索大模型应用场景的领域,因为这种结合最简单、最直接,并且有效。利用大模型的自然语言理解优势,改善产品的交互UI、自动化业务流程、构建答疑助手等等。早期使用者借助微调模型将自然语言翻译为产品自身的API调用或者DSL,当上下文不足时,再引入「向量数据库」增强生成效果等等。然后向量数据库趁着大模型的风"狠狠"地火了一把......
同时我们也看到很多基础软件,在大模型刚刚兴起时并未选择"盲目"跟进。个人认为,一方面基础软件的产品生态更下沉一些,稳定性需求强于易用性,不像应用软件亟需通过大模型技术自我变革改善用户体验。另一方面基础软件开发者更坚信长期主义,倾向于深耕专业技术逐步升级产品能力。「曲则全,枉则直」,这种坚持在过往产品迭代中发挥了巨大能量,但现在回头再看,在大模型时代下,可能需要做出适度的改变。
2. 图计算开源
作为基础软件中的一员,图计算产品在这方面其实也是"后知后觉"的,虽然在2023年中我们曾做过一些思考尝试,但未形成明确的战略共识。直到2023年底,因为开源,我们做出了一些不一样的改变。这里既有主动的一面,也有被动的一面。主动方面是开源非常适合作为「技术试验田」,应用场景可以用更低的成本验证,同时我们相信这次大模型带来的技术变革非同以往。被动方面是大模型技术太热了,但开发者的注意力是有限的,单纯从社区活跃度的需求出发,也应该选择加入。所谓「反者道之动」,我们不能只看到大模型技术对图计算技术热度的冲击,而应该借助大模型技术的力量,让图计算技术的真正价值发挥出来。
想明白了仅仅是第一步,关键是怎么做呢?一般遇到这种事,最简单的办法是参考同类产品「依葫芦画瓢」,但是这个方法有个风险,就是可能别人也做错了,我们会跟着错。实际更悲催的是,我们并没有可以画瓢的葫芦,因为大模型技术太新了,更没有多少人在Graph+AI这个方向上给出明确的思路。在这种情况下,我们借鉴开源社区的建设思路 ------ 寻找我们的「生态上下游」结合点。
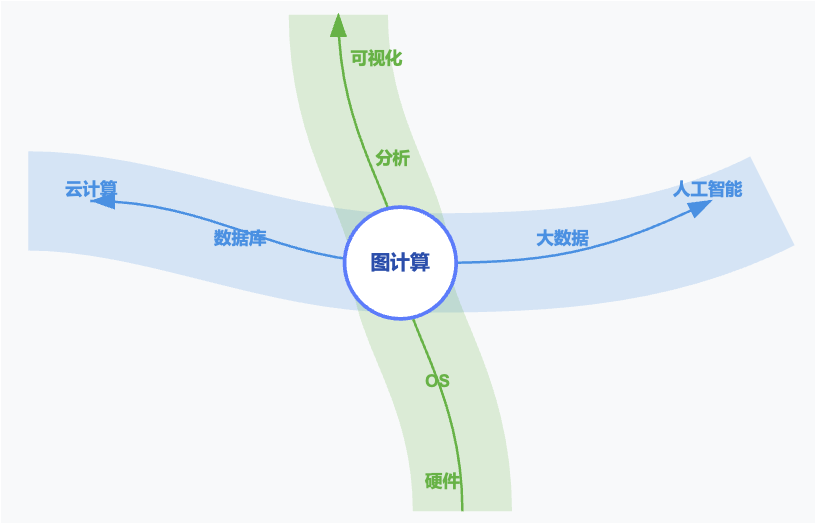
这张「十字路口图」是借助Claude绘制的一个简单的图计算技术生态上下游关系。从纵向关系看,图分析与图可视化与用户距离更近,也更容易借助AI技术提升用图的效率与体验。从横向关系看,图计算技术本身就有数据库(图数据库)与大数据(图计算引擎)双重属性,参考「Data+AI」的技术结合思路也不失为一种高效的选择。当然,也不能忽略Graph自身与AI技术直接结合的思路,这个很有意思,最能体现图自身的特色,后边我会展开来讲。
3. Graph + AI
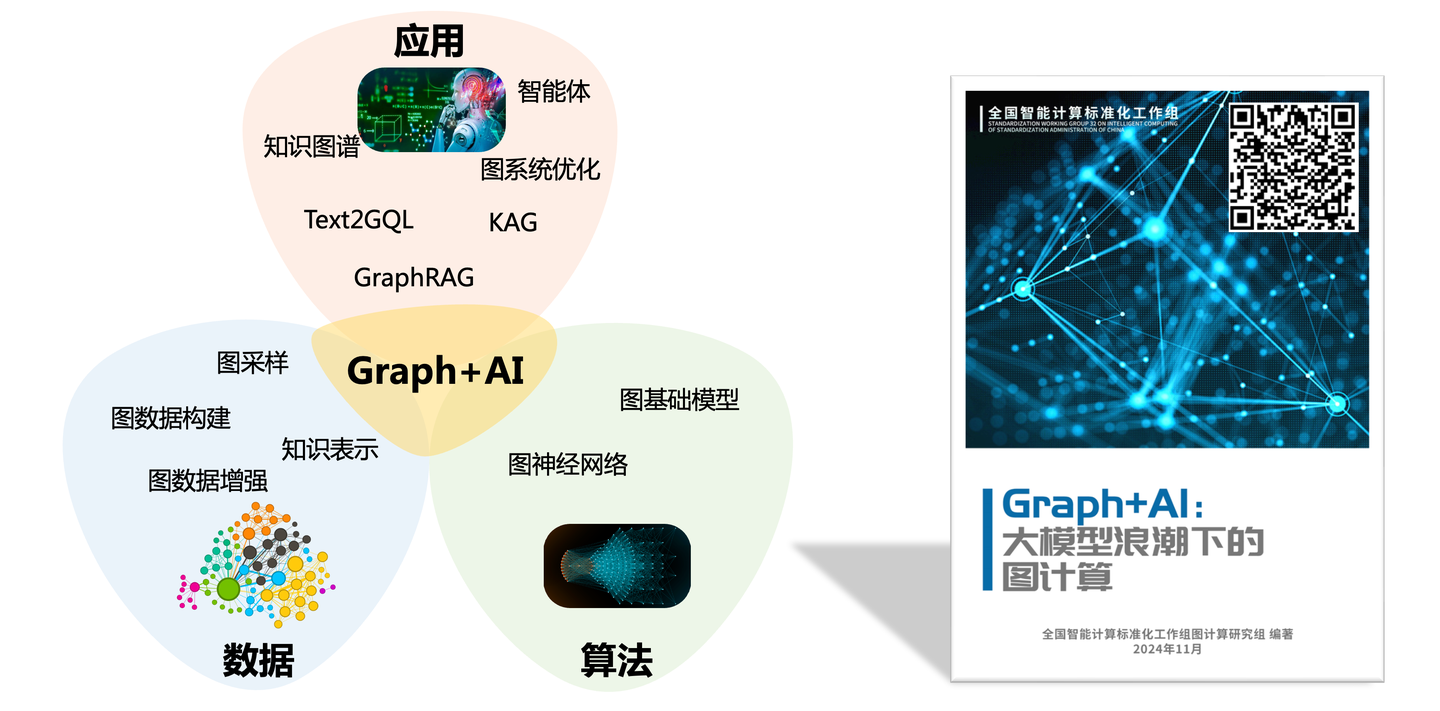
在2024年探索Graph+AI技术的过程中,我们还联合之江实验室以及各大高校和企业撰写并发布了《Graph+AI:大模型浪潮下的图计算》白皮书,从数据、算法、应用三个方面全方位论述「Graph+AI」技术结合点。涵盖了图数据构建、图神经网络、图基础模型、知识图谱、GraphRAG等热门技术,深度解读了AI时代的图计算技术应用场景和产业价值。接下来,我会结合图计算的生态上下游,重点阐述应用层面图计算的开源探索与思考。
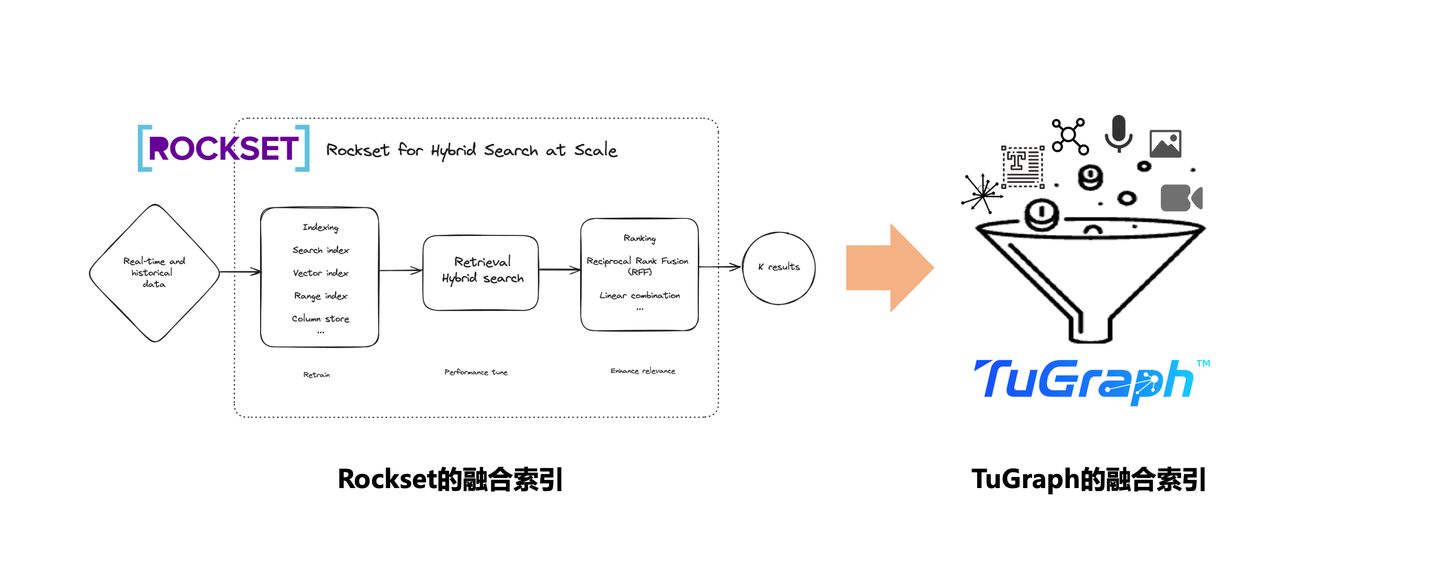
3.1 Converged Index
融合索引是提升大模型「用数能力」的关键技术,自2024年中Rockset被OpenAI收购后,融合索引技术开始逐步深入到数据库和数仓系统中,甚至形成了"在数据仓库上面扩展向量检索和语义检索并不困难,但是 反之不行"这样的结论。Rockset的存在打通了「大数据」与「大模型」之间的"桥梁",后续我们也看到了大量的主流数据库和数据仓库开始提供了向量索引的支持。当然TuGraph也不例外,我们在原来图、表索引的基础上,扩展了全文、向量索引的能力,并在未来随着多模态技术的发展,逐步支持图片、音频、视频等多模态索引能力,持续增强图数据分析能力。
3.2 OSGraph
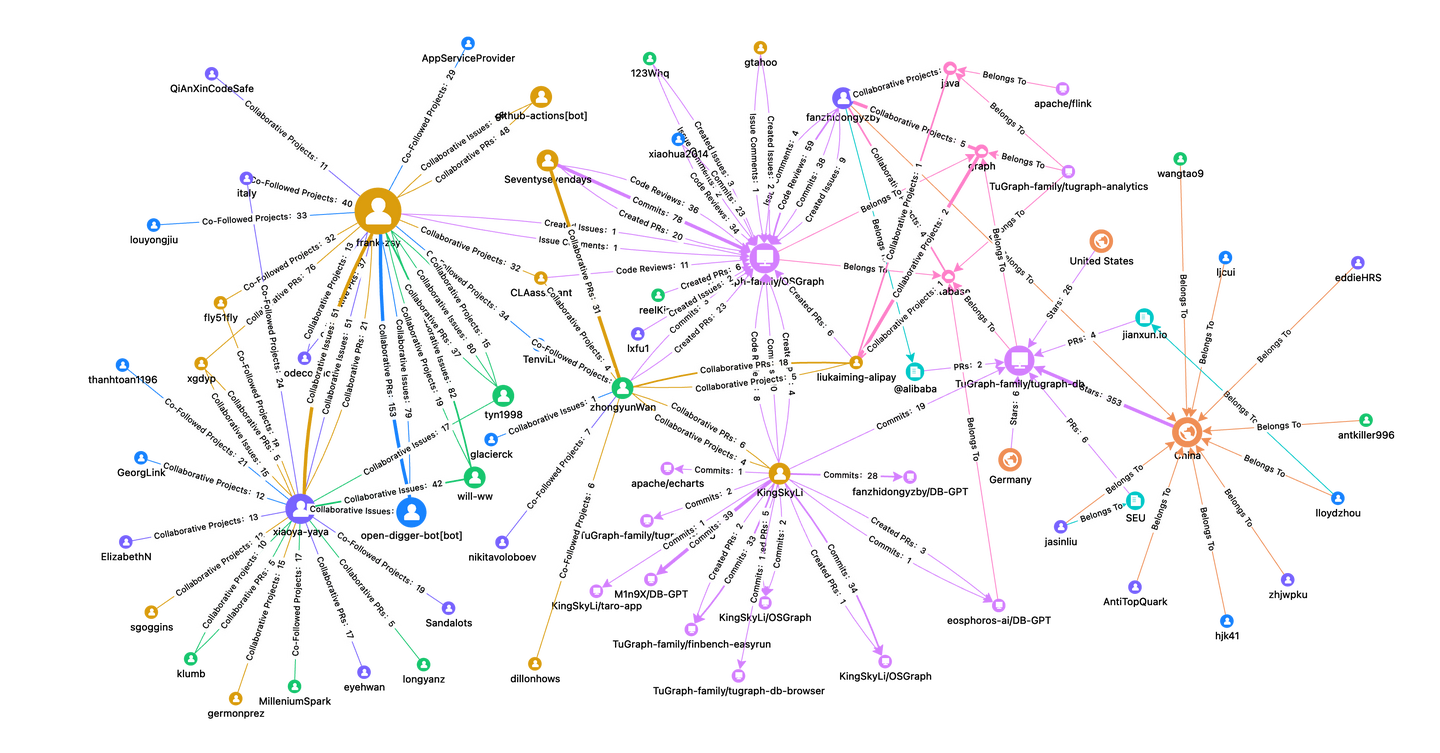
图可视化技术可以说是图计算领域最经典的应用技术了,由于图数据结构的天然复杂性,借助图可视化组件(如AntV G6)可以大幅降低图数据的理解成本。再漂亮的可视化工具,本质目的还是为了「数据洞察」服务的。从2024年初,我们尝试基于GitHub的真实数据,构建「开源图谱洞察」工具OSGraph,用于分析开源社区的项目和开发者的活动和关系。
示例中,我们通过OSGraph项目自身的「项目贡献图谱」开始,找到项目的关键开发者KingSkyLi、zhongyunWan等,并能发现X-lab实验室的will-ww、frank-zsy、xiaoya-yaya等。同时也可以关联到graph、database等技术领域,以及TuGraph社区等。
当前OSGraph已正式发布2.0版本,完成了从「图可视化」到「图数据洞察」的升级,下一步我们的目标是「图智能洞察」。借助于大模型能力,构建开源图谱上的数据增强、智能分析能力,实现更灵活和自由的开源数据探索。
3.3 Text2GQL
关于Text2GQL技术,相信很多人已经耳熟能详,也是数据库结合大模型技术的最早场景,为数据库上的自然语言交互形态提供了基础能力。而在图数据库领域,存在一个非常基础的挑战:图查询语言缺少广泛普及的统一标准 。ISO/GQL标准也是2024年4月份刚刚发布的,这导致了Text2GQL语料的极度匮乏,因此构建图数据库上的自然语言查询能力的首要工作是进行Text2GQL的语料合成。
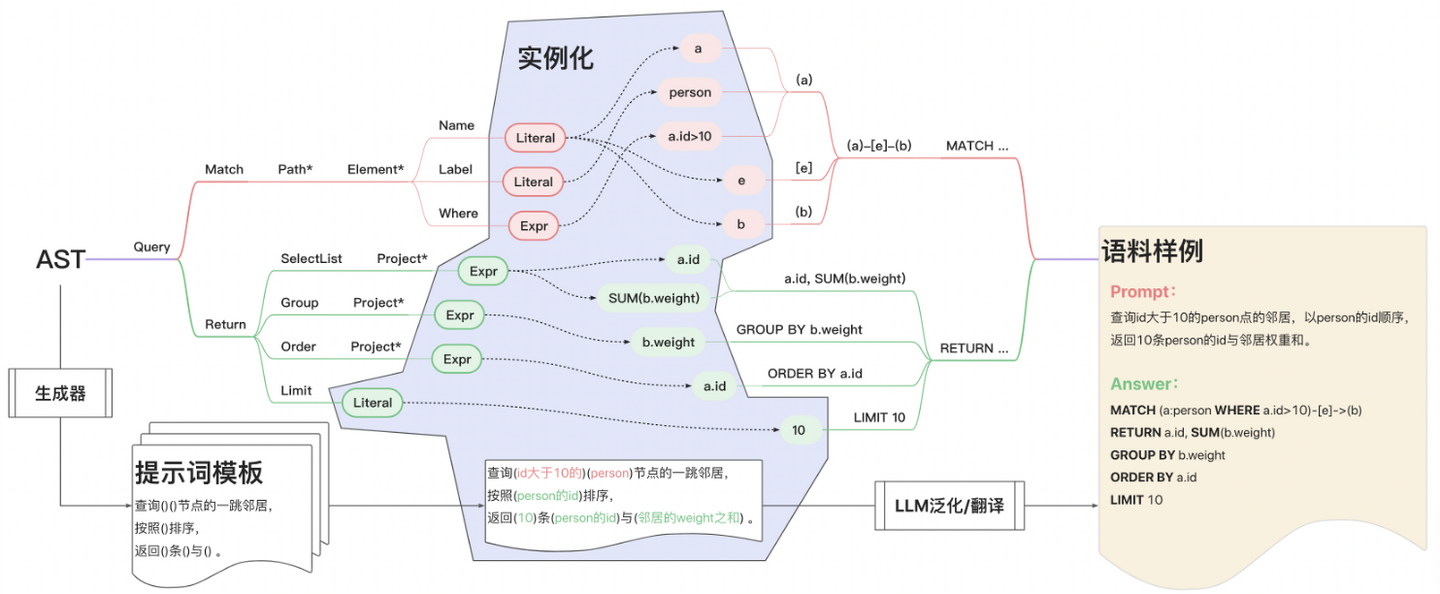
我们从2023年底就开始了Text2GQL的建设工作,构建了「语法制导的语料生成」方案,为图查询语言微调提供了必要的语料合成基建,最终通过OSPP项目联合社区开发者完善了此方案,并将源码开放到Awesome-Text2GQL项目。同时,Text2GQL的合成语料和微调模型也开放到DB-GPT-Hub项目中,预测准确率达到92%以上。
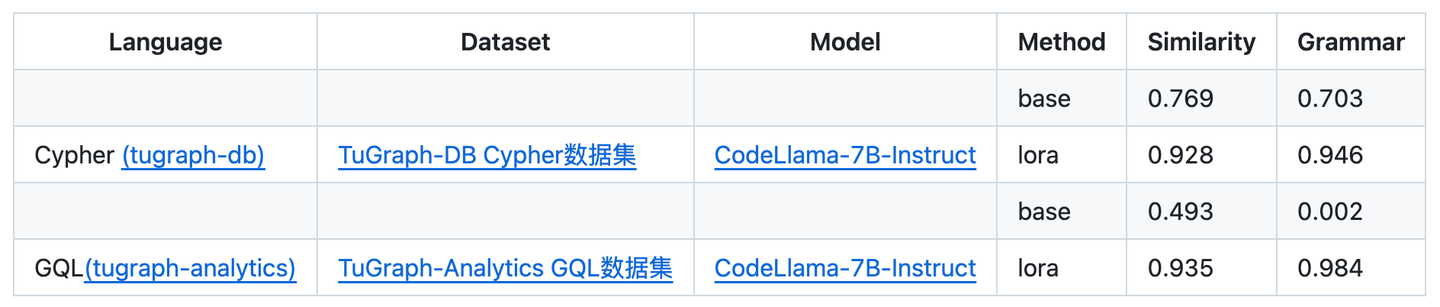
借助Text2GQL微调模型能力,增了强图查询的自然语言理解能力,这为GraphRAG的查询理解链路建设提供了重要的基础。
3.4 GraphRAG
2024年4月底,微软发表了GraphRAG论文,引爆了GraphRAG技术热。我们也在5月中联合DB-GPT社区共同发布了业内第二个GraphRAG框架,并对其做了持续改进。
- 2024年05月 :发布DB-GPT GraphRAG框架,兼容向量、图、全文索引。
- 2024年08月 :图团队发布行业首篇GraphRAG综述。
- 2024年09月 :支持社区摘要和混合检索,索引成本降低50%。
- 2024年12月 :支持文档结构图谱,索引成本降至40%,性能提升20%。
- 2025年01月 :支持向量驱动检索以及文本驱动检索,集成Text2GQL能力。
随着GraphRAG链路的持续改进,我们逐渐体会到Jerry Liu在LlamaIndex技术报告中提出的:「RAG的尽头是Agent」这个观点了。因此对于GraphRAG,下一阶段演进方向将会是GraphAgent,即「图智能体」。同时GraphRAG将作为智能体关键技术组件,以「知识库」或「记忆系统」的形式而继续存在。
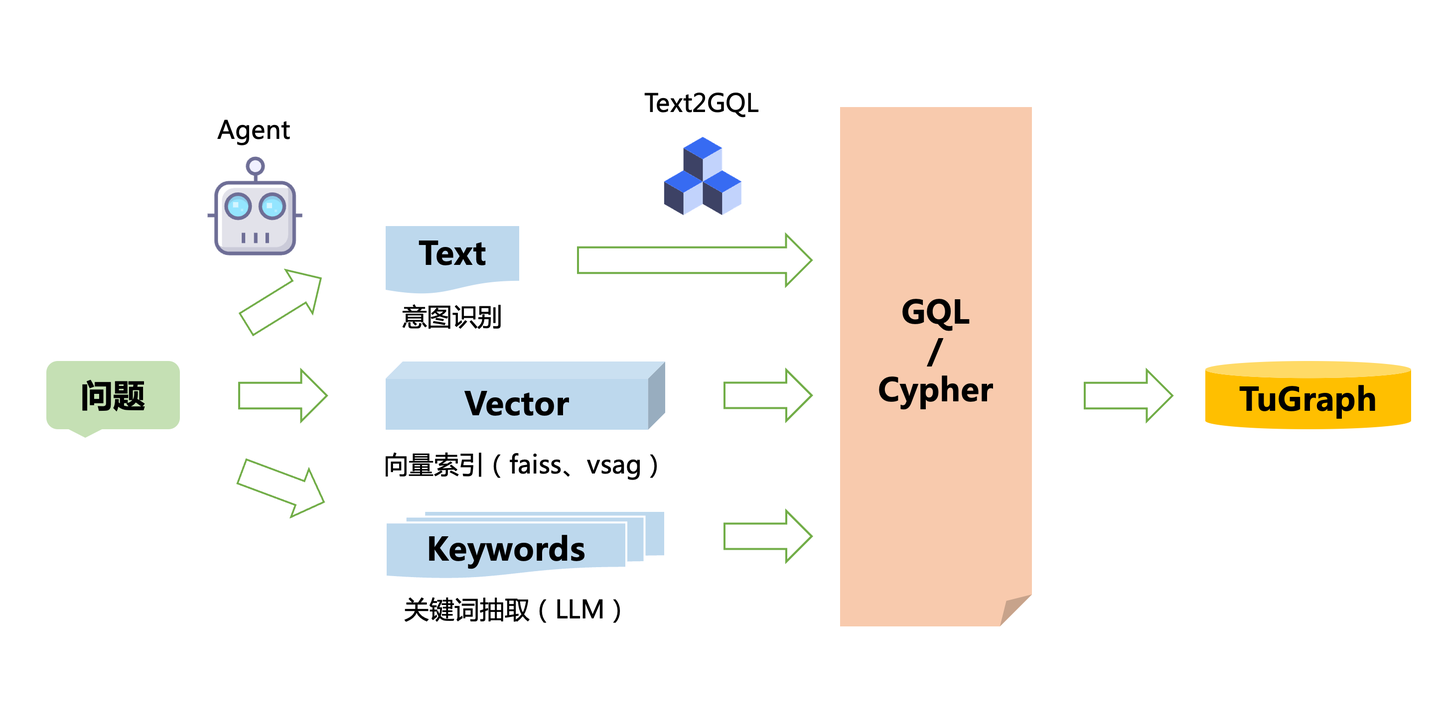
3.5 Chat2Graph
还记得2024年初我写了一篇关于LangChain的工程化解读文章,描绘了LangChain是如何从LLM开始逐步构建自身Agent的技术路径的。经过这两年大模型应用技术的发展,我们对这个过程的认知也越来越清晰:「既然大模型的幻觉不可避免,那么引入诸多改进技术的最终结果一定是智能体」。
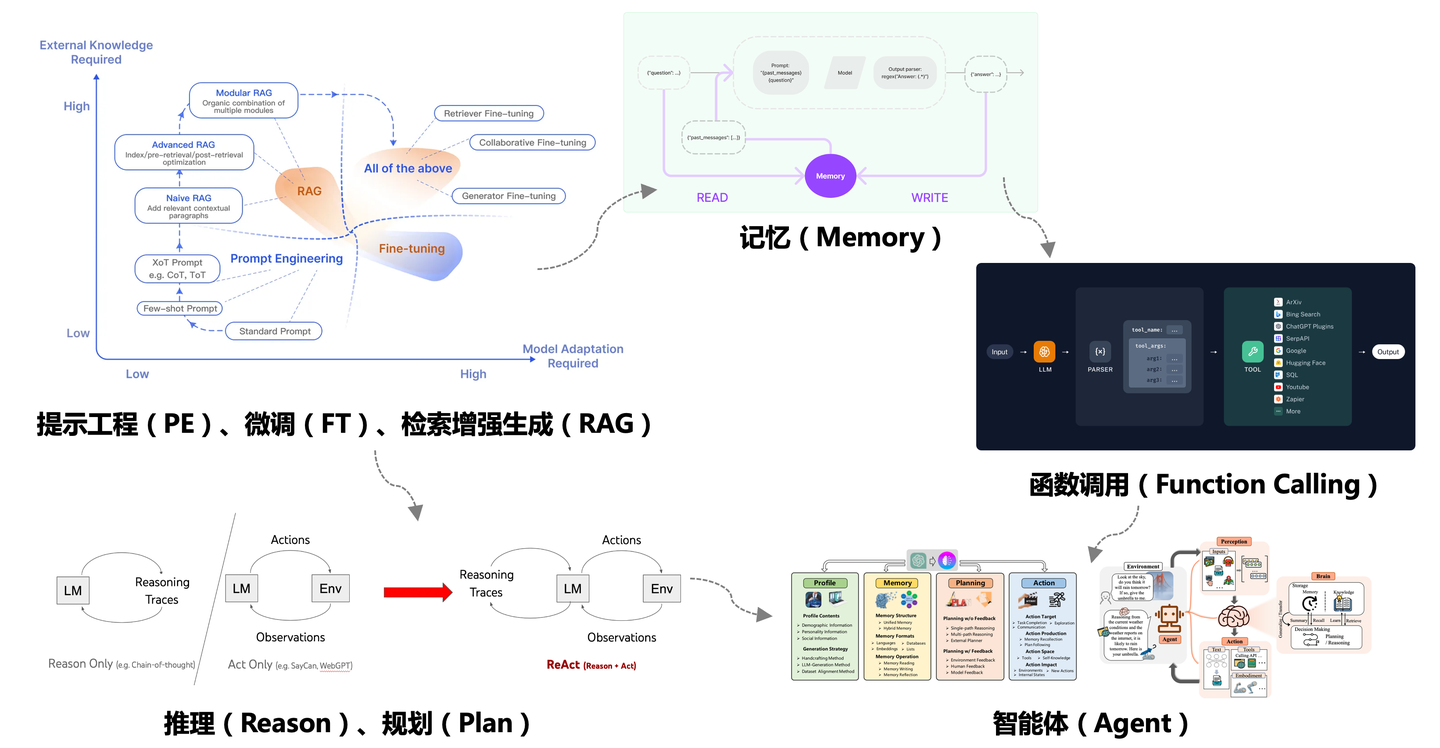
关于大模型应用技术,业内有句不成文的说法:「23年卷SFT,24年卷RAG,25年卷智能体」。这与我们这两年在「Graph+AI」的实践技术路线也是相当吻合,2025年,我们也即将开源图数据库的多智能体系统Chat2Graph「An Agentic System on Graph Database」,借助智能体实现真正的「与图对话」。
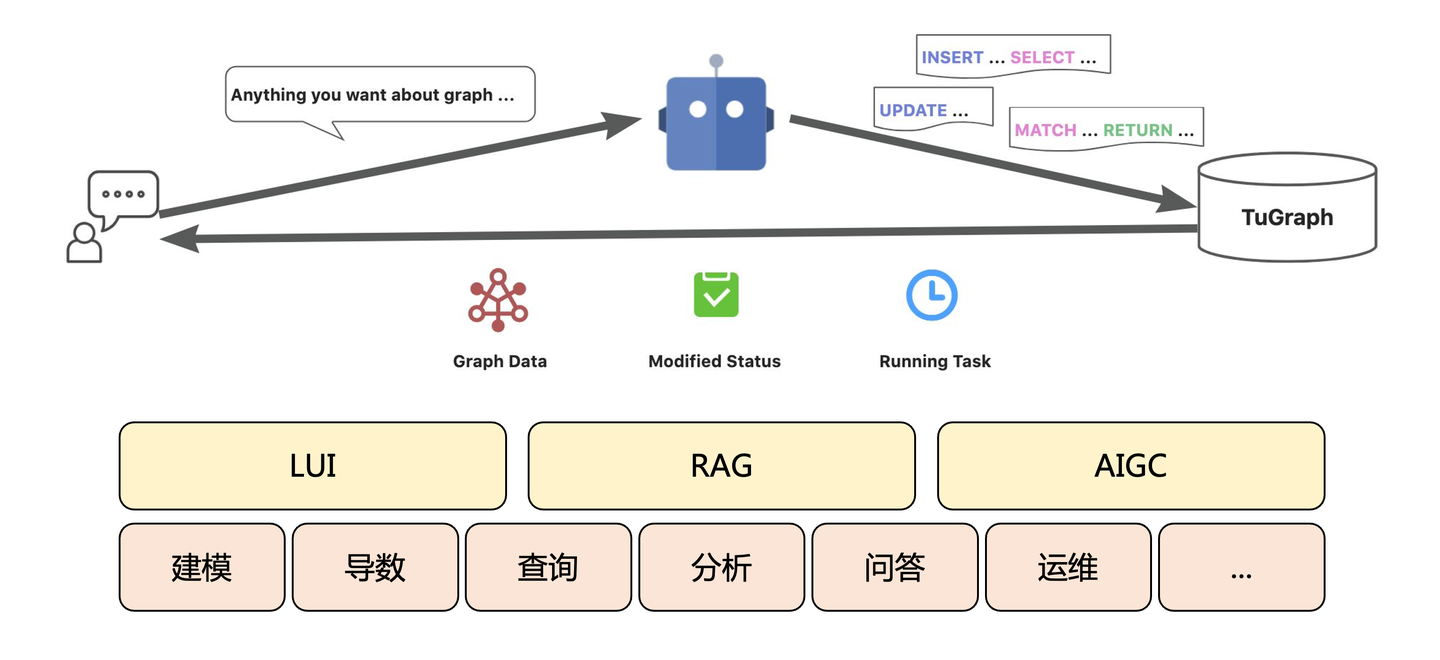
3.6 Graph Native
综上所述,不管是在图分析、图可视化方向的纵向探索,还是模型微调、RAG、智能体等方向的横向探索,借助开源社区「生态上下游」的理念,我们在2024年取得了诸多技术建设成果。但这也为我们自身设置了新的枷锁:不知不觉中我们成了技术的"搬运工",一直在用「迁移学习」的方式将相关技术"复刻"到图计算领域。比如,融合索引复刻了Rockset、OSGraph复刻了OSSInsight,Text2GQL复刻Text2SQL、GraphRAG复刻VectorRAG。
因此,我们需要从「图原生」的角度出发,思考图真正的价值是什么,从「借鉴生态」到「赋能生态」,这是我理解的「回到社区」。Chat2Graph虽然也参考了部分常见的Agent的技术,但在这个系统中,我们更想体现的是Graph在Agent生态中独有的价值,我们想把这块独特性一并做到Chat2Graph中。
回顾过往近十年的蚂蚁图技术建设和应用实践,我认为最有价值的地方不仅体现在业务规模和经济效益上,还有对图的理解与认知。如果一定把这种认知压缩成一个关键词,我认为应该是「连接」。连接可以直观地描述确定性和必然性,连接也可以表现为稳定性和可解释性。插入个彩蛋,图中有句话我特别喜欢:「存在不是实体的集合,而是关系的场域」,这句话是「李继刚」使用提示词引导Claude生成的,我深为共鸣。
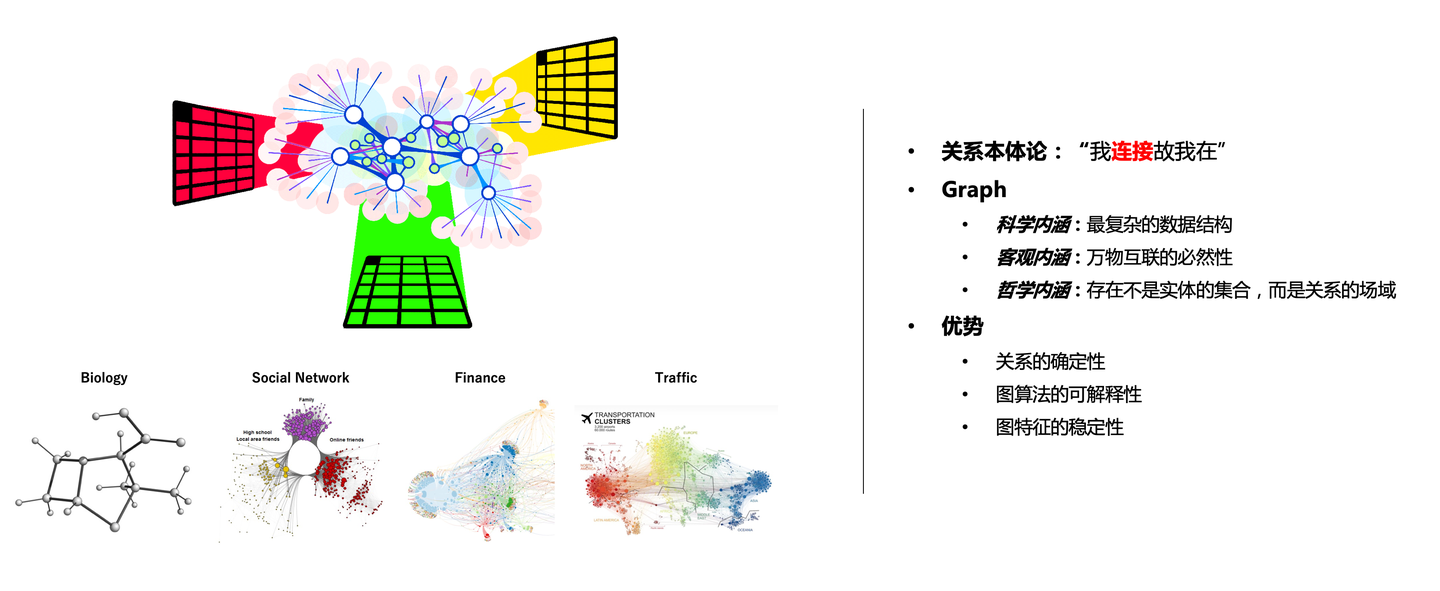
近来我经常引用人工智能的三大流派「符号主义」、「连接主义」、「行为主义」的内容,因为我觉得用这个去描述「Graph+AI」的思想来源特别的合适。
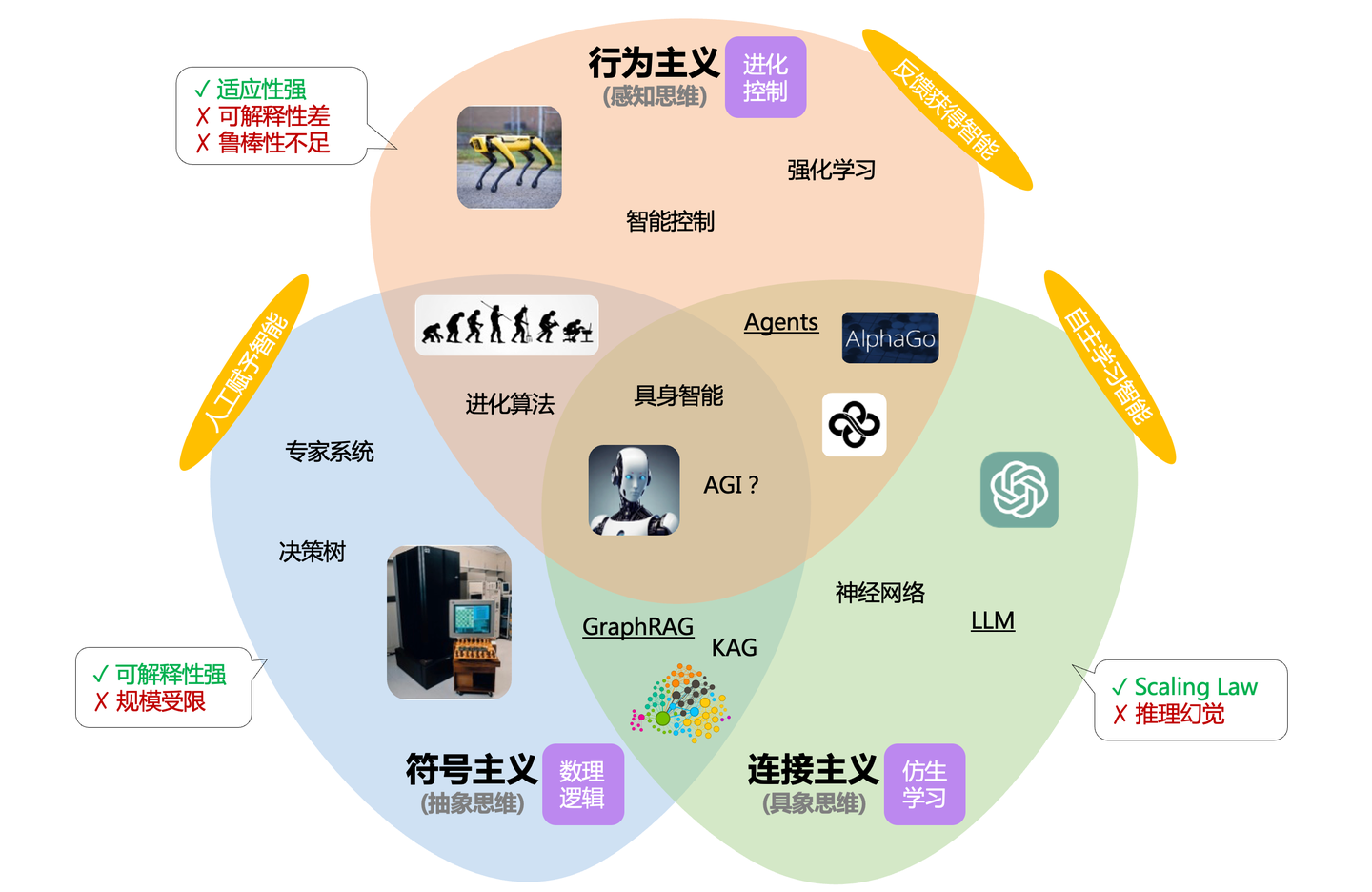
这里最想展开的是「符号主义」与「连接主义」的交叉结合部分,其中最典型的代表技术是GraphRAG和KAG。前者倾向于基于知识图谱检索增强大模型生成上下文,后者侧重于知识图谱的直接推理。虽然前边一直在描述图的「连接」本质 ------ 确定性与可解释性,好像只是「符号主义」的范畴,但事实上图技术已经深度融入到AI技术栈中,其实只看技术名词便能体会得到:「连接 主义」、「神经网络」。因此图技术的应用前景,远不止「符号主义」与「连接主义」结合的单一路径。
这里我结合从LLM到Agent的演进路径,探讨一下图技术的结合点:
- LLM:仿生大脑,神经元连接规模化后涌现智能,神经网络是最直观的计算图。
- **推理:**仿生思考,解决复杂问题,思维链(COT)、树形思考(TOT)、图形思考(GOT)。
- **记忆:**仿生海马体,感知记忆、短期记忆、长期记忆的分层记忆管理,维护记忆信息的连接。
- 工具库:仿生四肢,复杂的工具调用自动形成顺序和依赖图。
- 知识库:仿生图书馆,提供更准确的知识关联,典型代表知识图谱。
- 智能体:仿生个人,汇集大脑、思考、记忆、工具库、知识库构成完整个体,并具备外部感知交互能力。
- 多智能体:仿生社会,构建复杂任务规划图,多智能体协作构成通信图。
我们用更广义的仿生去理解大模型与智能体,会发现图技术几乎无处不在,究其原因只能归结为「事物的普遍联系性」了,或许到这里我们才开始摸到图计算在AI时代的一些「脉搏」,未来我们会在Chat2Graph这个项目中做持续的落地与验证。
4. TuGraph开源
回顾2024年,不知不觉中我们在探索「Graph+AI」技术演进过程中,逐步形成了如下的开源技术产品矩阵。从Graph Infra层已经/即将开源的图计算基础能力,结合上层的Text2GQL、GraphRAG的AI Infra层建设,逐步打造并完善图数据库多智能体系统Chat2Graph,并将其赋能到OSGraph和更多的应用层场景中去。
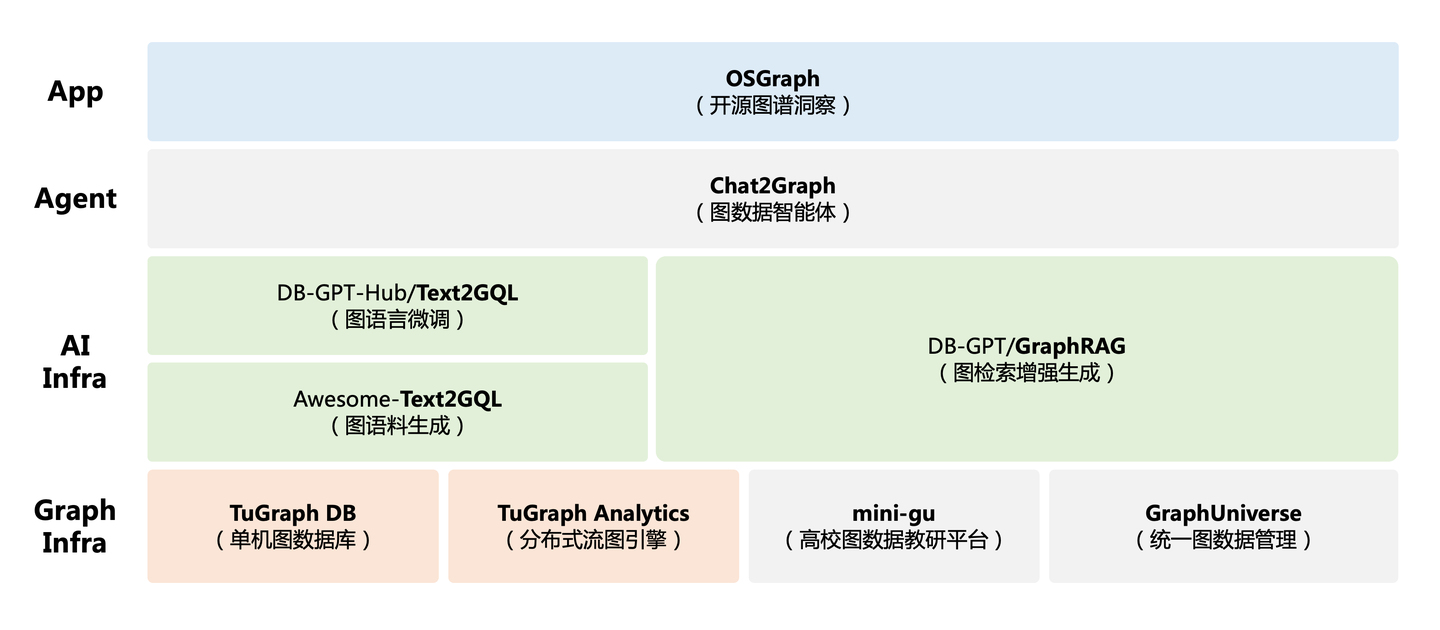
作为图计算布道师,需要同时touch到技术、内容和社区三个维度。关于开源,我们一直奉行的准则是:「技术是核心,通过技术迭代产出优质内容,既而影响社区」。对社区来说:「通过优质内容发现有用的技术,既而赋能自身的应用场景」。这是个双向反馈的过程,我们会持续在保持「开发者关系」(DelRel)、「公共关系」(PR)和表达关系三个维度上持续深耕。比较可喜的是,经过2024年「Graph+AI」路径上的持续探索,TuGraph在开源社区综合指标(OpenRank)上,逐步领先于同类产品,这进一步坚定了我们对这个技术方向的投入和信心。
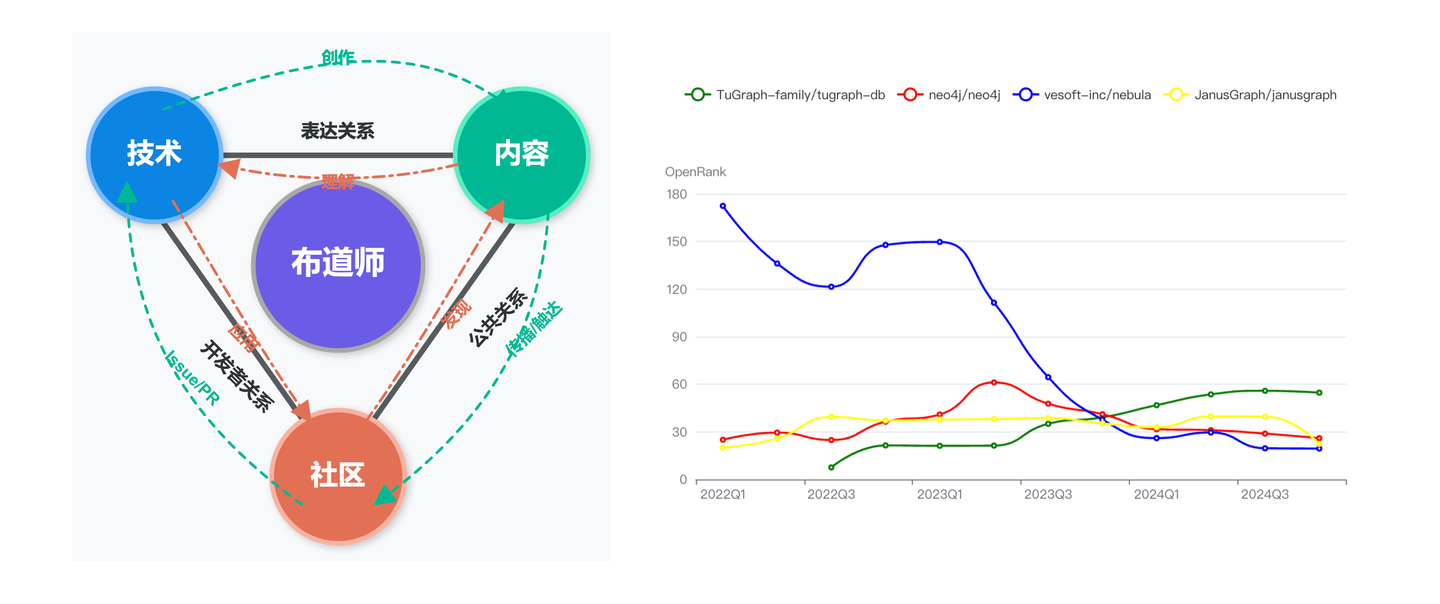
也正式归功于在「生态上下游」这个大方向的探索与实践,TuGraph有幸拉动了DB-GPT、AntV、X-lab、OpenSPG、OceanBase、VSAG、Libro等社区的联合共建,并获得到2024年度OpenStar最佳SIG组奖项。在此,对蚂蚁开源委员会、蚂蚁开源办公室的认可,表示特别的感谢。

后记
其实想聊的还有很多,局限于篇幅,我只能把最想和大家分享的感受列举如上。实际上「Graph+AI」的开源技术领域远不止如此,受制于我个人的工程知识背景,并未对大模型训练过程与图技术的结合做更多展开。最后,还有几个特别的点想稍微提及一下,因为我觉得2024年少了这些会有点不太完整。
首当其冲的,是「提示工程」(Prompt Engineering)。相信不人对这个技术领域多少有一些偏见,甚至不乏有人觉得这压根不是什么技术领域,更有人将提示工程师比作「巫师」,提示词是他们发出的「咒语」。在这里我想表达的是,提示工程虽然看起来不像写代码那么「科学」,但并不代表它不具备「逻辑」,大模型时代我们可能需要更「哲学」的思维,这点在优秀的提示工程师身上几乎是必备的素养。关于这些,大家可以参考我访谈「李继刚」的交流稿,看完可能会有不一样的感受。
另外,随着大模型能力的持续增强,提示词的重要性将会越来越高。如果你正在开发智能体,试想一下你在针对应用场景不断优化智能体的过程中,有多少时间是在修改提示词?或许会有人质疑说,那这样我们还做智能体做什么,直接攻坚提示工程不就完了,甚至不少提示工程师也是这么认为的。但这里,我就抛出一个问题,暂时不给出我的答案,大家可以带回去细想,可能会有别样的收获。
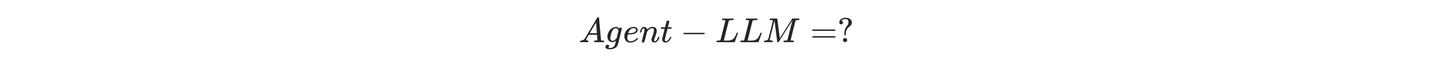
最后,不得不提及刚发布的DeepSeek-R1了,结合着前阵子吃瓜的gpt-4o-mini可能是8B模型,大家有没有发现我们所熟知的大模型正在朝着小模型、低成本的方向加速迭代。这也就意味着,那些过去只有在带GPU的服务器上才能运行的模型,将来必然会出现在每个人的手持设备上,而且推理质量和性能甚至比当下最好的大模型都要好。那么,人手一个「最懂你的AI助理智能体」将不再是问题,TA可能比你自己还要了解你,帮你购物、订餐、开会、写作,相当于24小时的私人秘书。再结合多智能体系统协作的思路,当你的微信群、钉钉群里,大部分时间是智能体之间在沟通,而你只需要和智能体保持必要的信息对齐即可,这将会给个人和社会带来多大的改变?不敢细想!!!
言至于此,不觉已是深夜,就此打住!
祝大家新春快乐,蛇年大吉!!!
参考
- Graph+AI白皮书:https://mp.weixin.qq.com/s/fxwMJ83NFNt2hmNBuUgzog
- 融合索引:https://rockset.com/blog/converged-indexing-the-secret-sauce-behind-rocksets-fast-queries
- 泼天富贵,OpenAI收购数据仓库公司,为什么?:https://mp.weixin.qq.com/s/ZKLFOQjjftHGWXDfgaq4Pw
- TuGraph融合索引:https://github.com/TuGraph-family/tugraph-db/blob/v5.x/docs/development_guide.md
- AntV G6:https://github.com/antvis/G6
- OSGraph:https://osgraph.com
- OSGraph项目:https://github.com/TuGraph-family/OSGraph
- X-lab社区:https://github.com/X-lab2017
- TuGraph社区:https://github.com/TuGraph-family
- OSGraph 2.0:https://github.com/TuGraph-family/OSGraph/releases/tag/v2.0.0
- ISO/GQL:https://www.gqlstandards.org
- 语法制导的语料生成:https://mp.weixin.qq.com/s/rZdj8TEoHZg_f4C-V4lq2A
- Text2GQL开源之夏项目:https://mp.weixin.qq.com/s/PCV4Qi9w9K-tRf1vMWHpEQ
- Awesome-Text2GQL:https://github.com/TuGraph-family/Awesome-Text2GQL
- 微软GraphRAG论文:https://arxiv.org/abs/2404.16130
- DB-GPT项目:https://github.com/eosphoros-ai/DB-GPT
- DB-GPT GraphRAG:https://mp.weixin.qq.com/s/WILvYFiKugroy9Q_FmGriA
- GraphRAG综述:https://mp.weixin.qq.com/s/Dx8pYhmbrhtRMXNez_GOmw
- 社区摘要增强:https://mp.weixin.qq.com/s/LfhAY91JejRm_A6sY6akNA
- 文档结构图谱:https://mp.weixin.qq.com/s/EQ3QnWWt1v9_S79MdRaJlw
- 向量驱动检索:https://github.com/eosphoros-ai/DB-GPT/pull/2200
- 文本驱动检索:https://github.com/eosphoros-ai/DB-GPT/pull/2227
- LlamaIndex技术报告:https://mp.weixin.qq.com/s/wuyMN7CLAT9HGYlmjLWUtA
- LangChain的工程化解读:https://mp.weixin.qq.com/s/9HtxRuyzavovC9NytzCDIg
- KAG项目:https://github.com/OpenSPG/KAG
- OpenSPG社区:https://github.com/OpenSPG
- OceanBase社区:https://github.com/OceanBase
- VSAG社区:https://github.com/antgroup/vsag
- Libro社区:https://github.com/difizen/libro
- 李继刚访谈:https://zhuanlan.zhihu.com/p/7494277954
- DeepSeek-R1:https://github.com/deepseek-ai/DeepSeek-R1
- gpt-4o-mini可能是8B:https://mp.weixin.qq.com/s/bT_w-T9ElmPUXbYA1f7kCg