在当今快速发展的Web开发领域,Django REST Framework(DRF)以其强大的功能和灵活性成为了众多开发者的首选。然而,错误的使用方法不仅会导致项目进度延误,还可能影响性能和安全性。本文将从我个人本身遇到的相关坑来给大家避坑。

一、API性能优化
坑:响应太慢!!!!!!
python
import os
from django_filters.rest_framework import DjangoFilterBackend
from rest_framework import viewsets
from rest_framework import filters
from rest_framework import permissions, authentication
from rest_framework.decorators import action
from rest_framework_simplejwt.authentication import JWTAuthentication
from utils.rest_framework_util.pagination import CommonPagination
from utils.rest_framework_util.response import rtn_success_info, rtn_error_info
from utils.rest_framework_util.excel_util import ExcelUtil, write_excel_file
from utils.utils import get_current_time_format
from utils.oss.tx_upload import CommonUpload
from drf_yasg import openapi
__all__ = {
"CommonViewSet",
"CommonUserViewSet"
}
from drf_yasg.utils import swagger_auto_schema
from drf_yasg import openapi
class CommonViewSet(viewsets.ModelViewSet):
permission_classes = ()
authentication_classes = ()
filter_backends = [ DjangoFilterBackend, filters.SearchFilter]
search_fields = ["id"]
save_export_folder = "static/save_export/"
pagination_class = CommonPagination
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset())
len_model = len(queryset)
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
response_data = {
"total": len_model,
"list": serializer.data
}
return rtn_success_info(response_data, msg="查询数据成功")
serializer = self.get_serializer(queryset, many=True)
return rtn_success_info(serializer.data)
def retrieve(self, request, *args, **kwargs):
instance = self.get_object()
serializer = self.get_serializer(instance)
return rtn_success_info(serializer.data)
def update(self, request, *args, **kwargs):
"""
put 修改
"""
try:
partial = kwargs.pop('partial', False)
instance = self.get_object()
serializer = self.get_serializer(instance, data=request.data, partial=partial)
serializer.is_valid(raise_exception=True)
self.perform_update(serializer)
if getattr(instance, '_prefetched_objects_cache', None):
# If 'prefetch_related' has been applied to a queryset, we need to
# forcibly invalidate the prefetch cache on the instance.
instance._prefetched_objects_cache = {}
return rtn_success_info(serializer.data, msg='修改数据成功')
except Exception as e:
return rtn_error_info(msg=e)
def destroy(self, request, *args, **kwargs):
instance = self.get_object()
self.perform_destroy(instance)
return rtn_success_info(msg="数据删除成功")
def perform_destroy(self, instance):
instance.delete()
def create(self, request, *args, **kwargs):
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)
self.perform_create(serializer)
return rtn_success_info(serializer.data, msg="创建数据成功")
@action(detail=False, methods=['POST'])
def data_import(self, request, *args, **kwargs):
response_data_list = []
file = request.FILES.get("file", None)
if file is None:
return rtn_error_info("需要传入file文件")
else:
title_list, data_list = ExcelUtil(file).read_data()
serializer_class = self.get_serializer_class()
model = serializer_class.Meta.model
try:
if model is not None:
model.objects.create()
for create_data in data_list:
response_data = {}
for index_, title in enumerate(title_list):
response_data[title] = create_data[index_]
if response_data.get('id', None) is not None:
response_data.pop("id")
serializer = self.get_serializer(data=response_data)
if serializer.is_valid():
# 创建
self.perform_create(serializer)
except Exception as e:
return rtn_error_info(f"数据导入失败:{e}")
response_data_list = data_list
return rtn_success_info(data=response_data_list, msg='导入数据成功')
@action(detail=False, methods=['POST'])
def data_export(self, request, *args, **kwargs):
id_list = request.data.get('ids', None)
queryset = self.get_queryset()
row_data_list = []
is_first = False
title_list = []
title = ""
for data in queryset:
title = data.__class__.__name__
if not is_first:
data_list = []
for data_meta in data._meta.fields:
data_list.append(data_meta.name)
title_list.append(data_meta.name)
row_data_list.append(data_list) # title
is_first = True
break
for value_data in queryset.values():
data_info = []
if id_list is not None:
for id_ in id_list:
if int(value_data['id']) == int(id_):
for title in title_list:
data_info.append(value_data[title])
else:
for title in title_list:
data_info.append(value_data[title])
if len(data_info) > 0:
row_data_list.append(data_info)
excel_file_name = f"{title}_{get_current_time_format('%Y_%m_%d_%H_%M_%S')}.xlsx"
if not os.path.exists(self.save_export_folder):
os.makedirs(self.save_export_folder)
write_excel_file(row_data_list, f"{self.save_export_folder}{excel_file_name}")
if os.path.exists(f"{self.save_export_folder}{excel_file_name}"):
url = CommonUpload().cos_upload_file(f"{self.save_export_folder}{excel_file_name}")
data = {
'excel_url': url
}
return rtn_success_info(data, '导出成功')
return rtn_error_info("导出失败")
class CommonUserViewSet(CommonViewSet):
"""带用户权限的ViewSet
Args:
viewsets (_type_): _description_
Returns:
_type_: _description_
"""
permission_classes = [permissions.IsAuthenticated]
authentication_classes = [JWTAuthentication, authentication.SessionAuthentication,
authentication.BasicAuthentication]
def create(self, request, *args, **kwargs):
data = request.data
data["user"] = request.user.id
serializer = self.get_serializer(data=data)
serializer.is_valid(raise_exception=True)
self.perform_create(serializer)
return rtn_success_info(serializer.data, msg="创建数据成功")
def list(self, request, *args, **kwargs):
queryset = self.filter_queryset(self.get_queryset())
len_model = len(queryset)
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
response_data = {
"total": len_model,
"list": serializer.data
}
return rtn_success_info(response_data, msg="查询数据成功")
serializer = self.get_serializer(queryset, many=True)
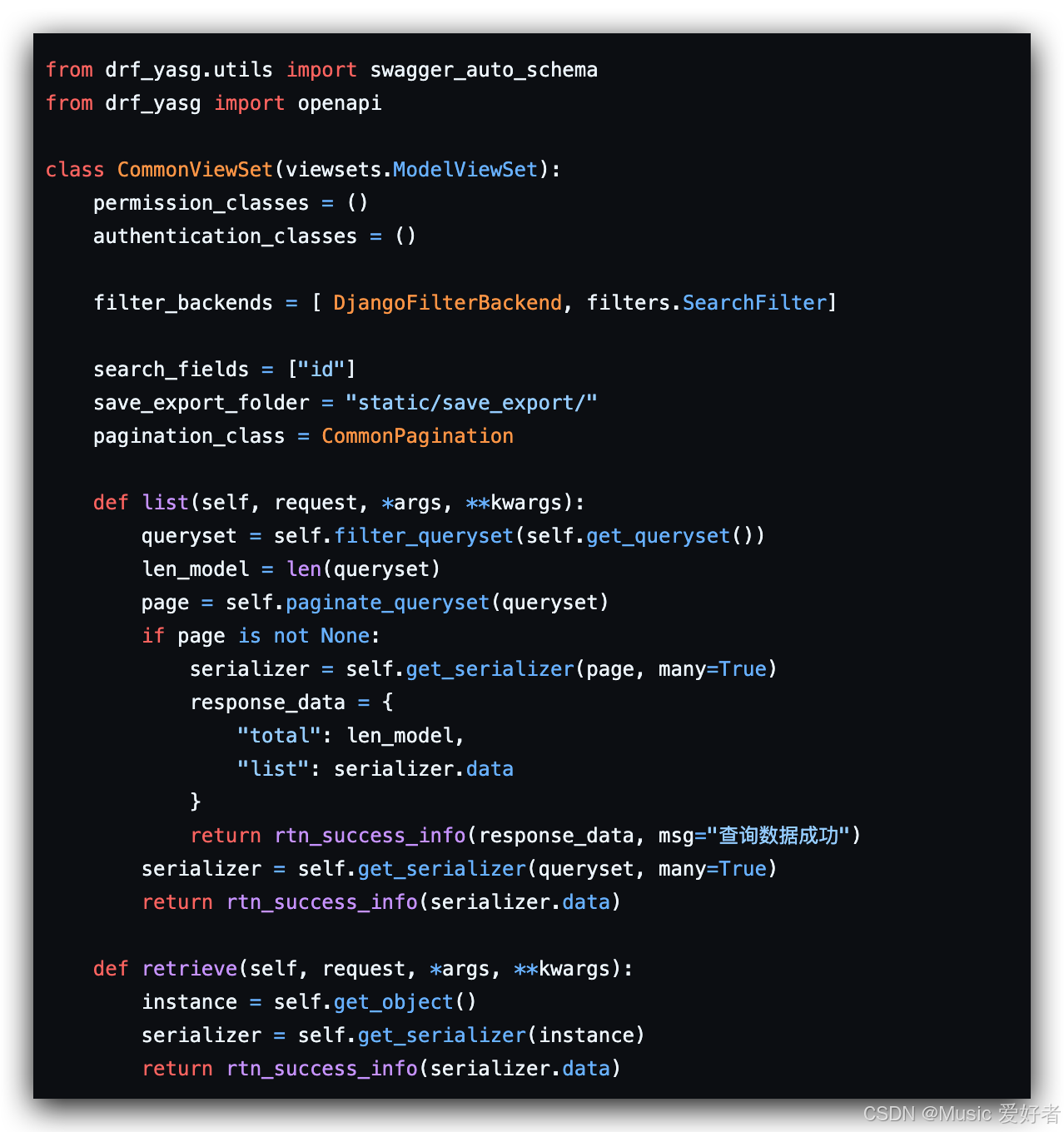
return rtn_success_info(serializer.data)以这块代码为例,大家会发现一个问题,虽然都封装了ViewSet,但是他的响应速度比之前慢很多,原因何在,问题就出现在len_model = len(queryset)上,因为当前的len(queryset)会遍历每一个model,导致性能缓慢,正确的修改方式是使用queryset.count(),会大幅度的提高性能,直接获取里面的变量。
图片
二、复杂权限管理
针对于这类的权限管理,其实DRF也给咱们弄好了,但是基于实际业务场景的复杂性,本人也提供给大家一个参考的可定制化的代码!
1.通过定制通用类的permissions
python
class CommonUserViewSet(CommonViewSet):
"""带用户权限的ViewSet
Args:
viewsets (_type_): _description_
Returns:
_type_: _description_
"""
permission_classes = [permissions.IsAuthenticated]
authentication_classes = [JWTAuthentication, authentication.SessionAuthentication,
authentication.BasicAuthentication]
``
类似这个,这个是用于基础的认证,比方说用户需要登陆才能确认的,使用这个比较方便。
2.特定用户
这类的需求,可以通过获取self.request.user来判断,其中可以通过获取用户是否为超级用户,以及username等判断,大大提高drf的灵活性!
最后,大家还遇到哪些坑,也可以分享在评论区中,大家一起排雷,祝大家春节喜乐!觉得有用的话可以分享以及关注哈!