在本地运行 DeepSeek-R1 可让您完全控制模型的执行,而无需依赖外部服务器。在本地运行 DeepSeek-R1 有以下几个优点:
- 隐私和安全:没有数据离开您的系统。
- 不间断访问:避免速率限制、停机或服务中断。
- 性能:通过本地推理获得更快的响应,避免 API 延迟。
- 定制化:修改参数、微调提示、将模型集成到本地应用中。
- 成本效益:通过在本地运行模型来消除 API 费用。
- 离线可用性:模型下载后无需互联网连接即可工作。
使用 Ollama 在本地设置 DeepSeek-R1
Ollama 通过无缝处理模型下载、量化和执行简化了本地运行 LLM。
步骤1:安装Ollama
首先,从官方网站下载并安装Ollama 。
下载完成后,像安装其他应用程序一样安装 Ollama 应用程序。
第 2 步:下载并运行 DeepSeek-R1
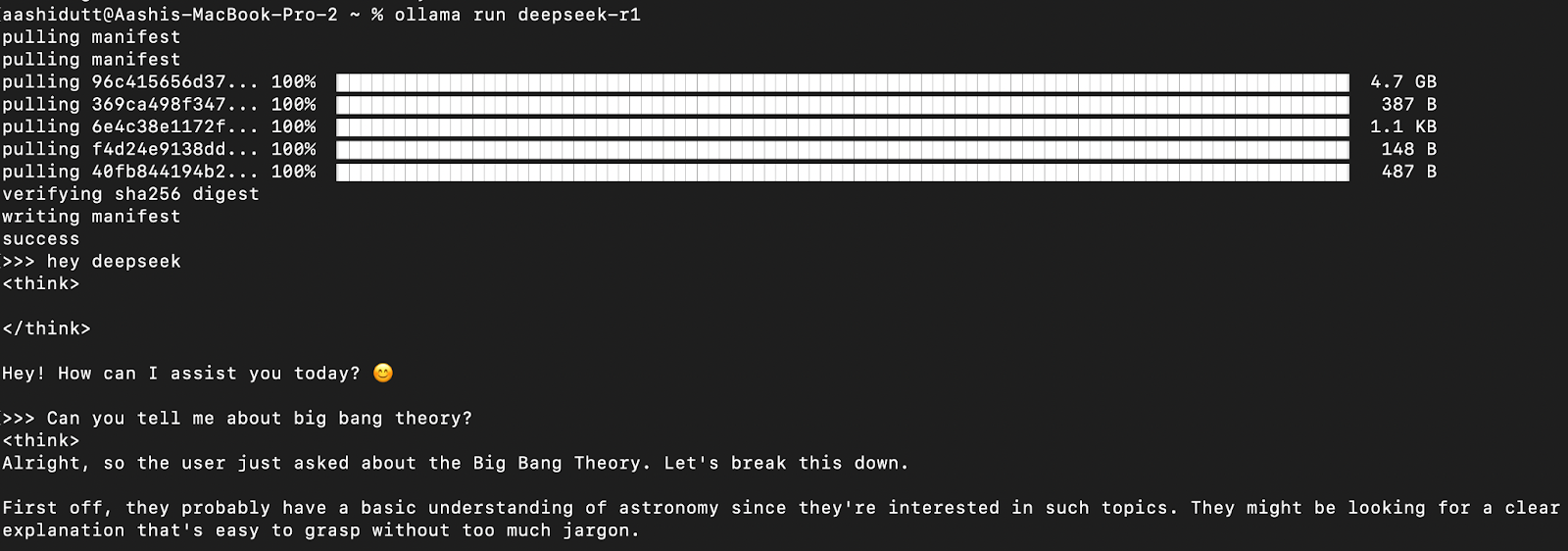
让我们测试设置并下载我们的模型。启动终端并输入以下命令。
arduino
ollama run deepseek-r1Ollama 提供一系列 DeepSeek R1 模型,从 1.5B 参数到完整的 671B 参数模型。671B 模型是原始的 DeepSeek-R1,而较小的模型是基于 Qwen 和 Llama 架构的精简版本。如果您的硬件无法支持 671B 模型,您可以使用以下命令轻松运行较小的版本,并将X以下内容替换为您想要的参数大小(1.5b、7b、8b、14b、32b、70b、671b):
arduino
ollama run deepseek-r1:Xb有了这种灵活性,即使您没有超级计算机,也可以使用 DeepSeek-R1 的功能。
步骤 3:在后台运行 DeepSeek-R1
要持续运行 DeepSeek-R1 并通过 API 为其提供服务,请启动 Ollama 服务器:
ollama serve这将使该模型可以与其他应用程序集成。
本地使用 DeepSeek-R1
步骤 1:通过 CLI 运行推理
模型下载完成后,您可以直接在终端中与DeepSeek-R1进行交互。
步骤 2:通过 API 访问 DeepSeek-R1
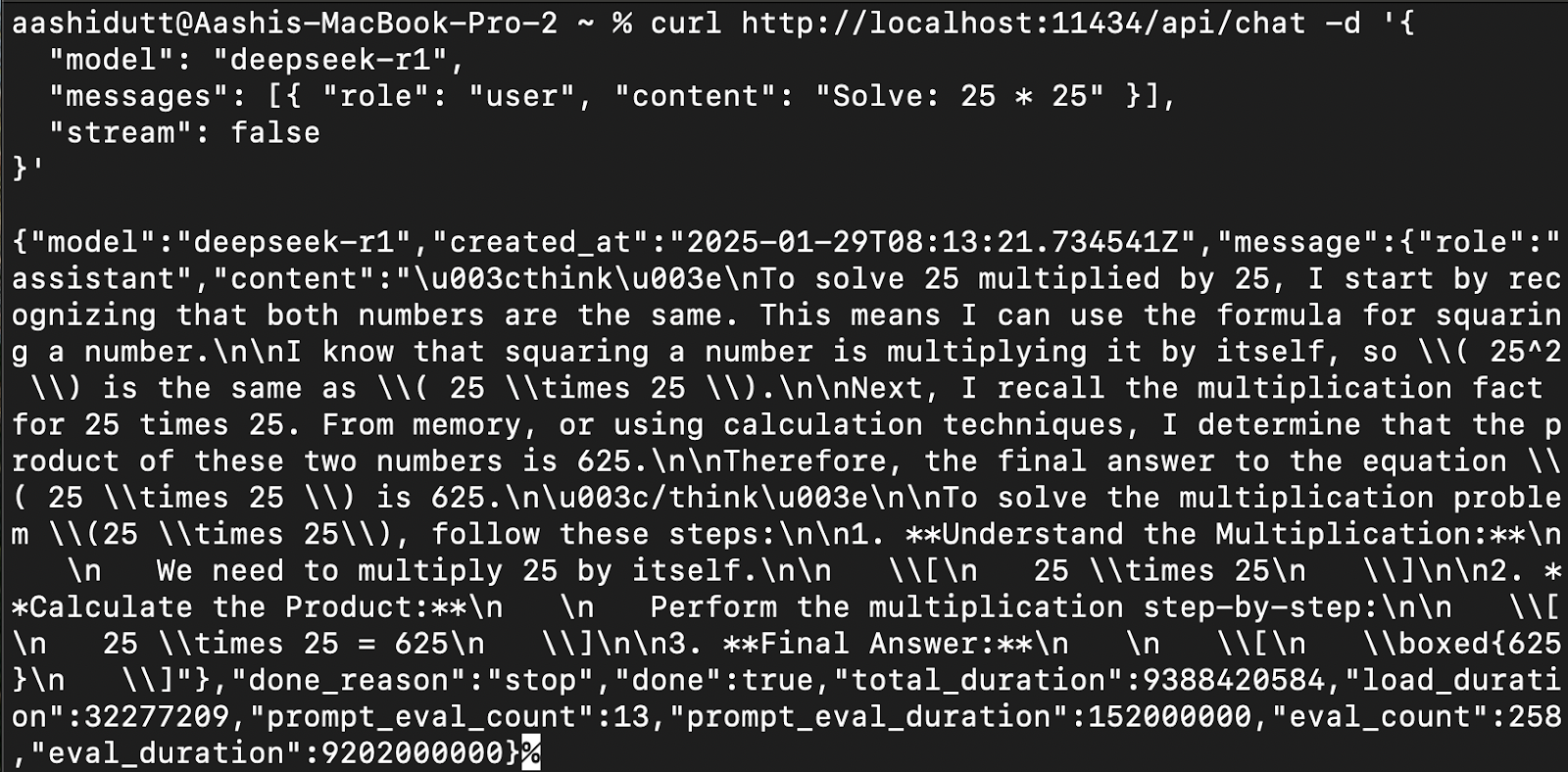
要将 DeepSeek-R1 集成到应用程序中,请使用 Ollama API curl:
vbnet
curl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1",
"messages": [{ "role": "user", "content": "Solve: 25 * 25" }],
"stream": false
}'curl是 Linux 原生的命令行工具,但也适用于 macOS。它允许用户直接从终端发出 HTTP 请求,使其成为与 API 交互的绝佳工具。
步骤3:通过Python访问DeepSeek-R1
我们可以在任何选择的集成开发环境 (IDE) 中运行 Ollama。您可以使用以下代码安装 Ollama Python 包:
diff
!pip install ollama安装 Ollama 后,使用以下脚本与模型交互:
ini
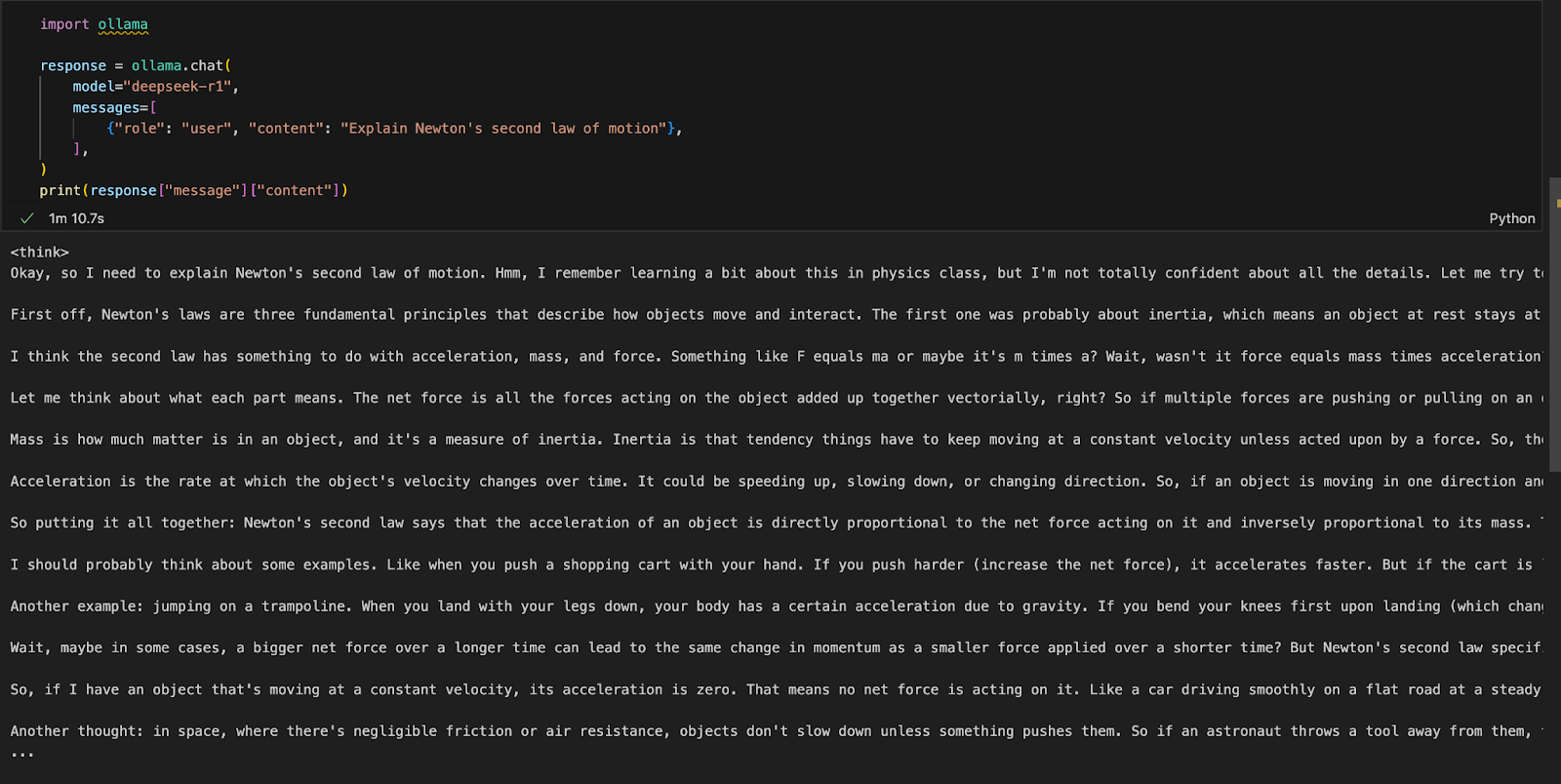
import ollama
response = ollama.chat(
model="deepseek-r1",
messages=[
{"role": "user", "content": "Explain Newton's second law of motion"},
],
)
print(response["message"]["content"])该ollama.chat()函数接收模型名称和用户提示,将其作为对话进行处理。然后脚本提取并打印模型的响应。
使用 DeepSeek-R1 为 RAG 运行本地 Gradio 应用程序
让我们使用 Gradio 构建一个简单的演示应用程序,以便使用 DeepSeek-R1 查询和分析文档。
步骤 1:先决条件
在深入实施之前,让我们确保已经安装了以下工具和库:
- Python 3.8+
- Langchain:由大型语言模型(LLM)驱动的应用程序构建框架,可轻松实现检索、推理和工具集成。
- Chromadb:专为高效相似性搜索和嵌入存储而设计的高性能矢量数据库。
- Gradio:创建一个用户友好的网络界面。
运行以下命令安装必要的依赖项:
diff
!pip install langchain chromadb gradio
!pip install -U langchain-community安装上述依赖项后,运行以下导入命令:
javascript
import gradio as gr
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
import ollama步骤 2:处理上传的 PDF
一旦导入了库,我们将处理上传的 PDF。
ini
def process_pdf(pdf_bytes):
if pdf_bytes is None:
return None, None, None
loader = PyMuPDFLoader(pdf_bytes)
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=100
)
chunks = text_splitter.split_documents(data)
embeddings = OllamaEmbeddings(model="deepseek-r1")
vectorstore = Chroma.from_documents(
documents=chunks, embedding=embeddings, persist_directory="./chroma_db"
)
retriever = vectorstore.as_retriever()
return text_splitter, vectorstore, retriever函数process_pdf:
- 加载并准备 PDF 内容以进行基于检索的答复。
- 检查 PDF 是否已上传。
- 使用 提取文本
PyMuPDFLoader。 - 使用 将文本分割成块
RecursiveCharacterTextSplitter。 - 使用 生成向量嵌入
OllamaEmbeddings。 - 将嵌入存储在 Chroma 向量存储器中以实现高效检索。
步骤 3:合并检索到的文档块
一旦检索到嵌入,接下来我们需要将它们拼接在一起。该combine_docs()函数将多个检索到的文档块合并为一个字符串。
python
def combine_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)由于基于检索的模型提取相关摘录而不是整个文档,因此此功能可确保提取的内容在传递给 DeepSeek-R1 之前保持可读且格式正确。
步骤 4:使用 Ollama 查询 DeepSeek-R1
现在,我们对模型的输入已经准备好了。让我们使用 Ollama 设置 DeepSeek R1。
python
import re
def ollama_llm(question, context):
formatted_prompt = f"Question: {question}\n\nContext: {context}"
response = ollama.chat(
model="deepseek-r1",
messages=[{"role": "user", "content": formatted_prompt}],
)
response_content = response["message"]["content"]
final_answer = re.sub(r"<think>.*?</think>", "", response_content, flags=re.DOTALL).strip()
return final_answer该ollama_llm()函数将用户的问题和检索到的文档上下文格式化为结构化提示。然后通过 将此格式化的输入发送到 DeepSeek-R1 ollama.chat(),后者在给定的上下文中处理问题并返回相关答案。如果您需要没有模型思维脚本的答案,请使用该strip()函数返回最终答案。
步骤 5:RAG Chain
现在我们拥有了所有必需的组件,让我们为演示构建 RAG 管道。
scss
def rag_chain(question, text_splitter, vectorstore, retriever):
retrieved_docs = retriever.invoke(question)
formatted_content = combine_docs(retrieved_docs)
return ollama_llm(question, formatted_content)上述函数首先使用 搜索向量存储retriever.invoke(question),返回最相关的文档摘录。这些摘录使用函数格式化为结构化输入combine_docs并发送到ollama_llm,确保 DeepSeek-R1 根据检索到的内容生成明智的答案。
步骤6:创建Gradio界面
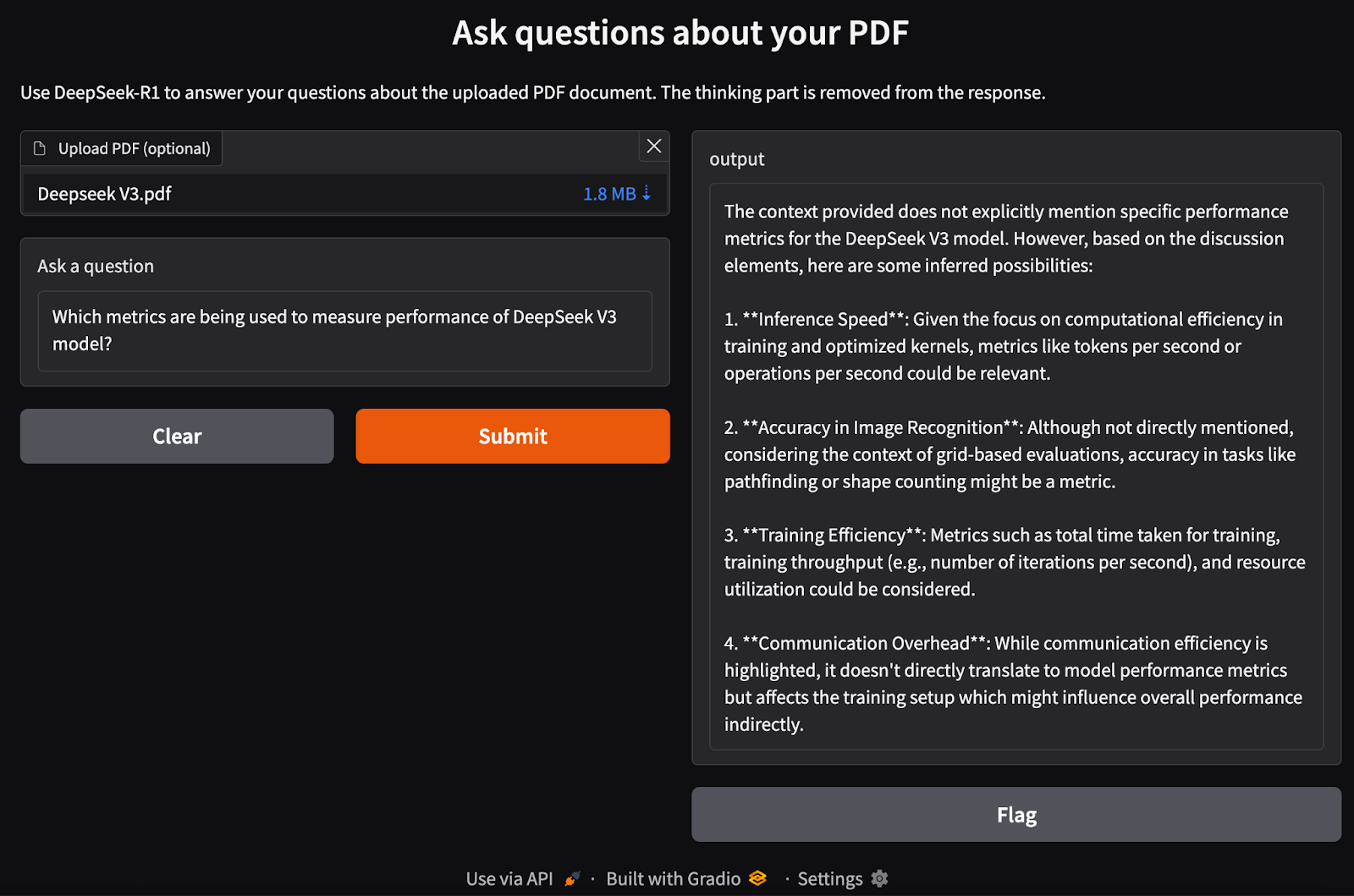
我们已经建立了 RAG 管道。现在,我们可以在本地构建 Gradio 接口以及 DeepSeek-R1 模型来处理 PDF 输入并提出与之相关的问题。
ini
def ask_question(pdf_bytes, question):
text_splitter, vectorstore, retriever = process_pdf(pdf_bytes)
if text_splitter is None:
return None
result = rag_chain(question, text_splitter, vectorstore, retriever)
return {result}
interface = gr.Interface(
fn=ask_question,
inputs=[
gr.File(label="Upload PDF (optional)"),
gr.Textbox(label="Ask a question"),
],
outputs="text",
title="Ask questions about your PDF",
description="Use DeepSeek-R1 to answer your questions about the uploaded PDF document.",
)
interface.launch()我们执行以下步骤:
- 检查 PDF 是否已上传。
- 使用函数处理 PDF
process_pdf以提取文本并生成文档嵌入。 - 将用户的查询和文档嵌入传递给
rag_chain()函数以检索相关信息并生成上下文准确的响应。 - 设置基于 Gradio 的 Web 界面,允许用户上传 PDF 并询问有关其内容的问题。
- 使用函数定义布局
gr.Interface(),接受 PDF 文件和文本查询作为输入。 - 启动应用程序
interface.launch()以通过 Web 浏览器实现无缝、交互式的基于文档的问答。
结论
使用 Ollama 在本地运行 DeepSeek-R1 可实现更快、更私密且更具成本效益的模型推理。借助简单的安装过程、CLI 交互、API 支持和 Python 集成,您可以将 DeepSeek-R1 用于各种 AI 应用程序,从一般查询到复杂的基于检索的任务。