使用 GPT-SoVITS 克隆声音,很详细
一、前言
最近对文本转语言很感兴趣,但对直接在网站上生成的音频音色却不是很满意,经过一番寻找,发现了"GPT-SoVITS" ,对想要的声音进行克隆。
二、下载
可以到这里下载
下载后解压即可
这里将其解压到如下目录:
E:\software\gpt-sovits
三、启动
进入"安装目录\GPT-SoVITS-v2-240821\GPT-SoVITS-v2-240821"
双击"go-webui.bat"即可

会出现一个黑窗口
启动成功会打开浏览器跳转到这个页面
四、克隆声音
1、准备克隆音频
先准备好想要提起的声音,这里以克隆芭芭拉的声音为例

可以到这里下载原音频
下载后将其放到某个文件夹中,这里放到
F:\file\GptSovitsFile\sucai\芭芭拉
2、分离人声伴奏
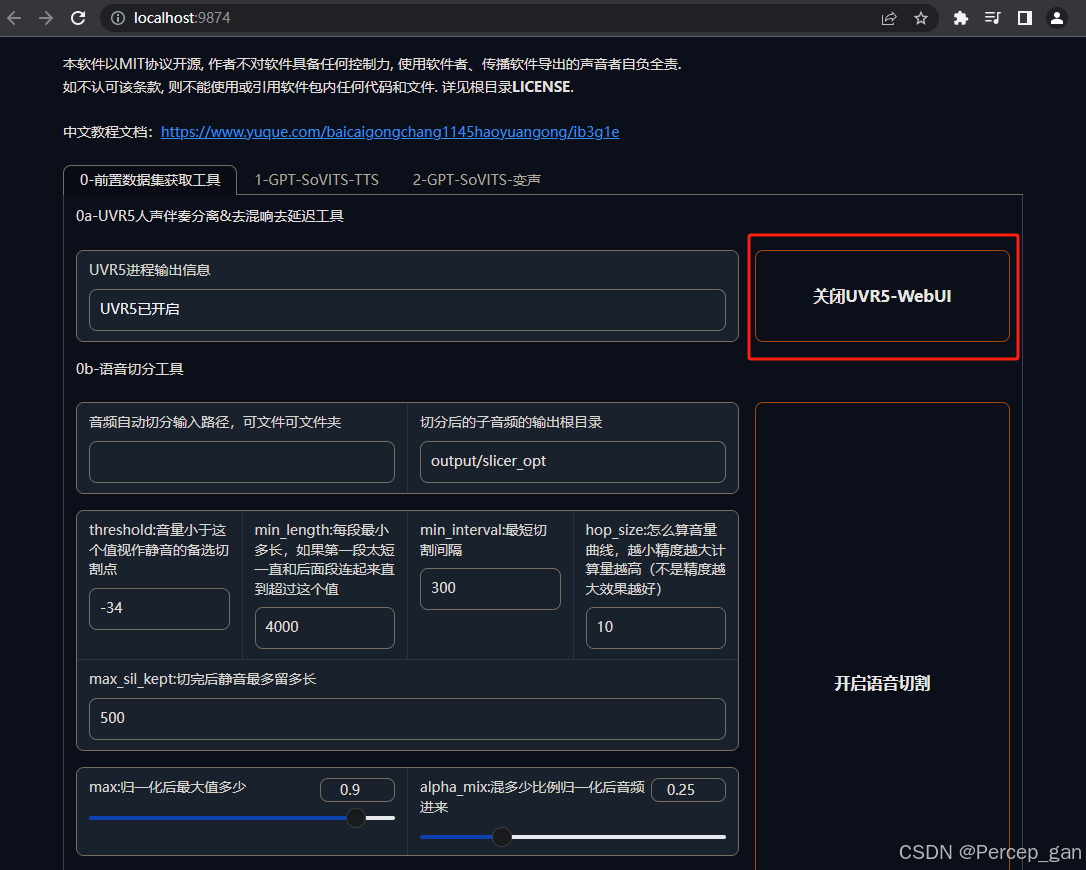
回到"GPT-SoVITS"中,点击开启"UVR5-WebUI"
稍等一会儿后会跳转到新的页面

选择模型,一般选择"HP2_all_vocals"即可,也可以阅读上方解释,选择适合自己的模型
模型介绍:
bash
HP2_all vocals:人声伴奏分离模型,提取音频中所有人声部分和背景音部分。
HP5_only_main_vocal:提取音频中的主唱人声,排除和声和伴唱,适合处理歌曲。
model_bs_roformer_ep_317_sdr_12.9755:去掉混音中的干扰成分,增强信噪比。
onnx_dereverb_By_FoxJoy:去混响模型,减少音频中由于环境回声或混响造成的声音模糊。
VR-DeEchoAggressive:去回声模型,针对严重的回声进行处理,偏向"激进处理"。
VR-DeEchoDeReverb:结合去回声和去混响的双重功能,处理音频中的回声和混响问题。
VR-DeEchoNormal:去回声模型,适用于一般程度的回声处理,偏向"温和处理"。
接着输入存放待分离音频路径,前面已经提到将其放到
F:\file\GptSovitsFile\sucai\芭芭拉
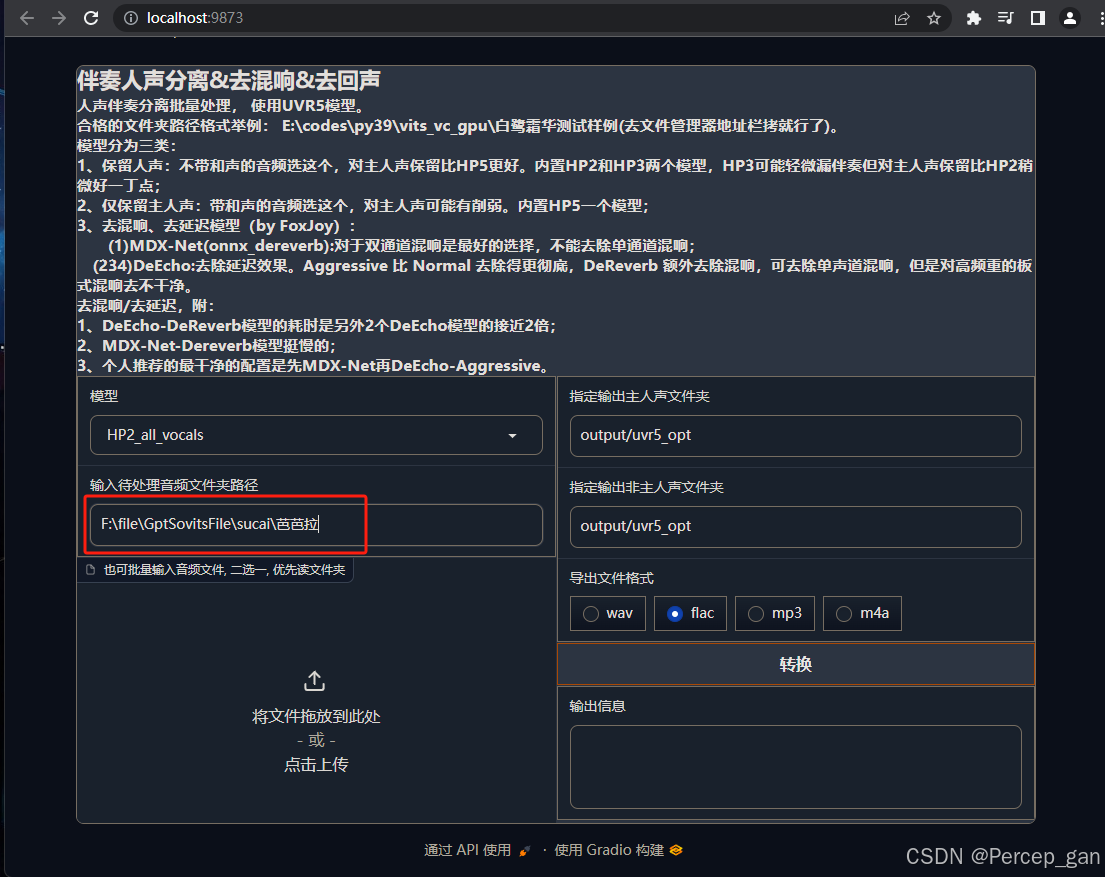
指定输出主人声文件夹和指定输出非主人声文件夹保持默认即可
分类之后会保存在"安装目录\GPT-SoVITS-v2-240821\GPT-SoVITS-v2-240821\output\uvr5_opt"
再选择导出文件格式,这里选择 wav
最后点击转换
看到成功的信息表示转换完成
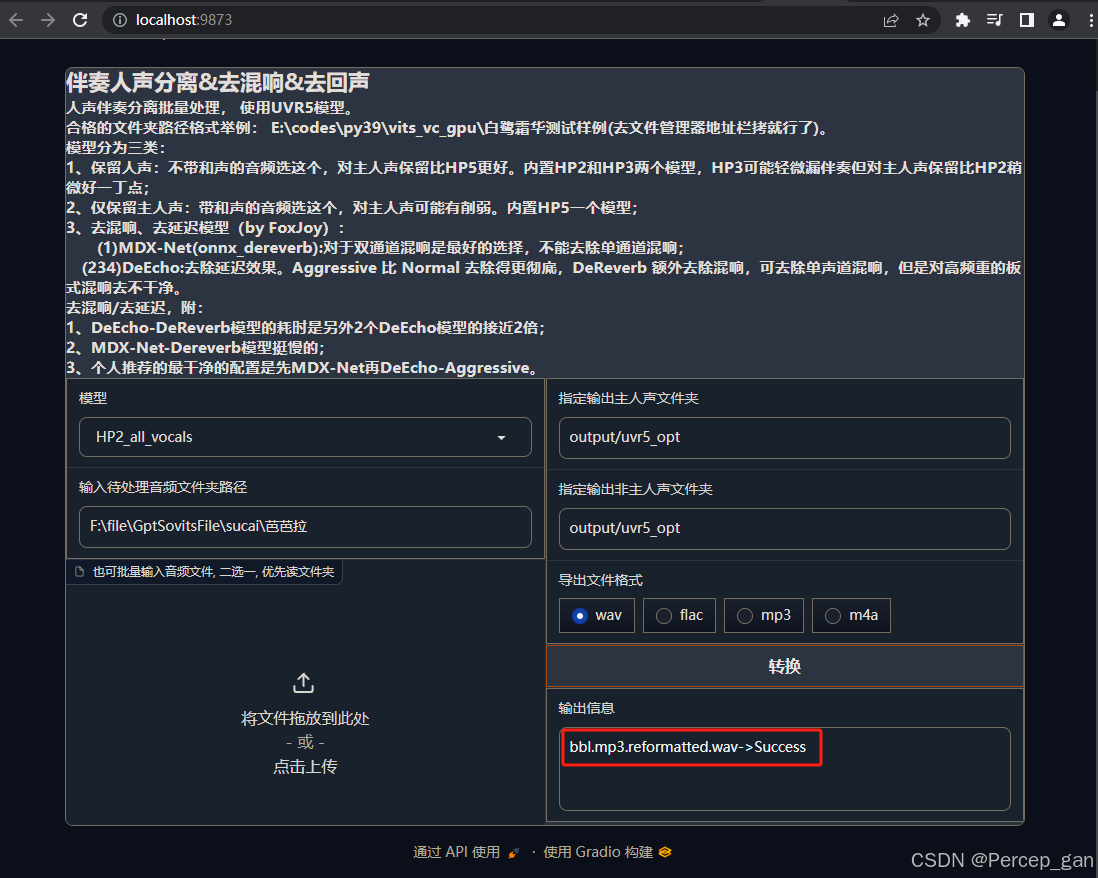
再查看输出目录 uvr5_opt
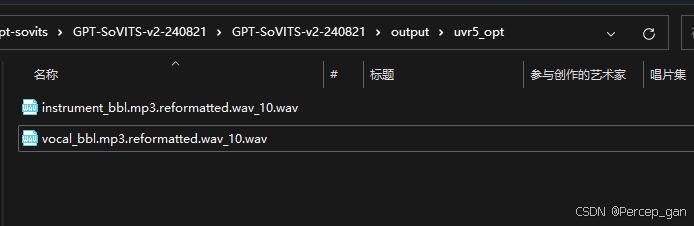
两条音频都试听一下,找出人声音频,因为要克隆声音,伴奏音频没用,这里将其删除了
这时就可以回到主界面,关闭"UVR5-WebUI"
3、音频分割
这里主要针对长音频,如果音频本来就不长,就不需要分割了
回到这界面,已知上面分离的音频保存在"安装目录\GPT-SoVITS-v2-240821\GPT-SoVITS-v2-240821\output\uvr5_opt"路径
这里路径为:
E:\software\gpt-sovits\GPT-SoVITS-v2-240821\GPT-SoVITS-v2-240821\output\uvr5_opt
将文件夹路径放到切分输入路径
点击开启语言切割
看到输出信息显示"切割结束"表示切割完成
4、语音降噪
主要是处理有杂音的音频,如果音频干净可不降噪,直接点击"开启语言降噪即可"
看到降噪输出信息提示降噪完成即可
完成后可在"output"下生成"denoise_opt"文件夹
里面就是降噪的音频
原来的音频就干净,降噪后对比原音频只是小声了点
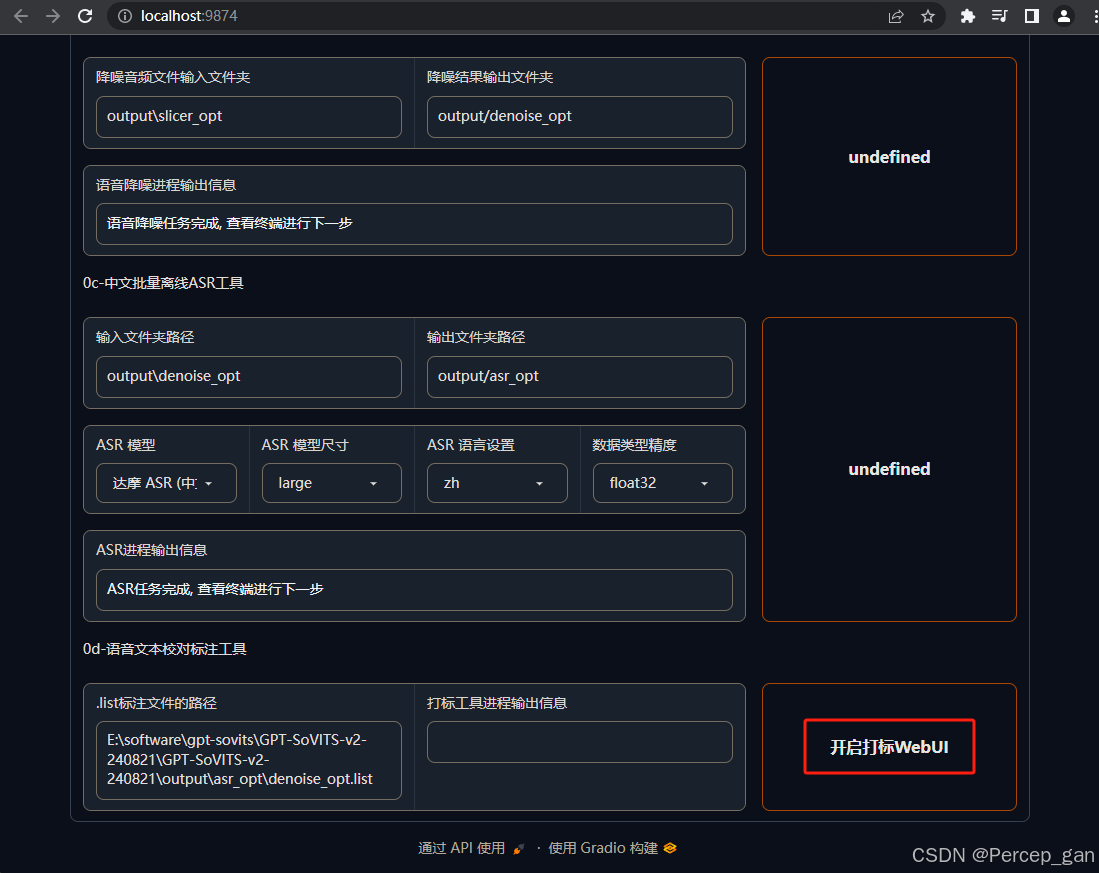
5、ASR工具
这一步主要是生成带时间戳的文本,如果需要的是中文,默认即可。
点击"开启离线批量ASR"
看到输出提示完成即可
生成文件在"asr_opt"文件夹
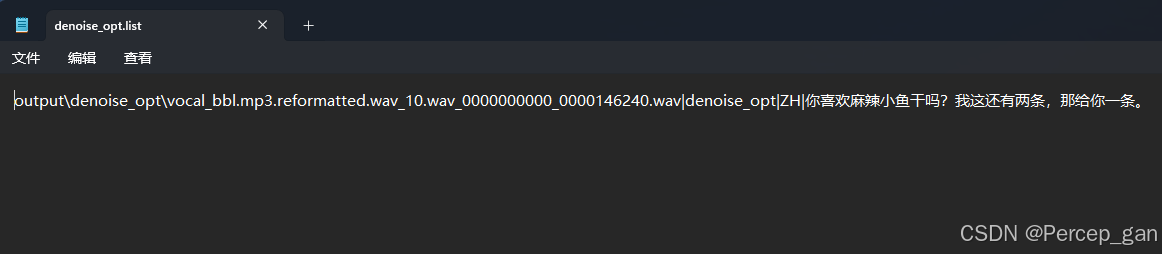
文件内容如下
6、语音文本校对标注工具
这一步主要是校对文本 ASR 工具生成的文本是否正确,对错误的文本进行修改。
保持默认,点击"开启打标WebUI"即可
会跳转到一个新的页面
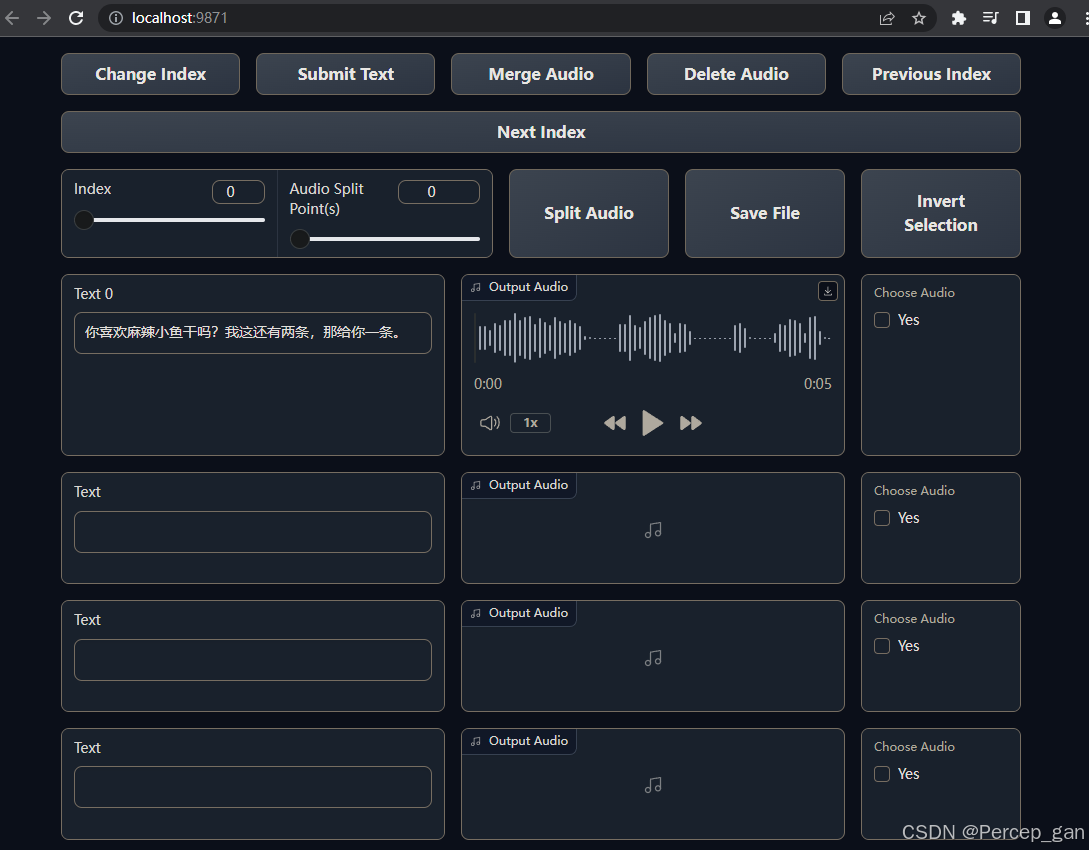
因为音频比较短,这里只有一段文本如果音频较长,这里是有多段文本的
检查文本框中的文本是否正确,不正确则进行修改,为了防止出错,建议修改一段点一下"Submit Text"
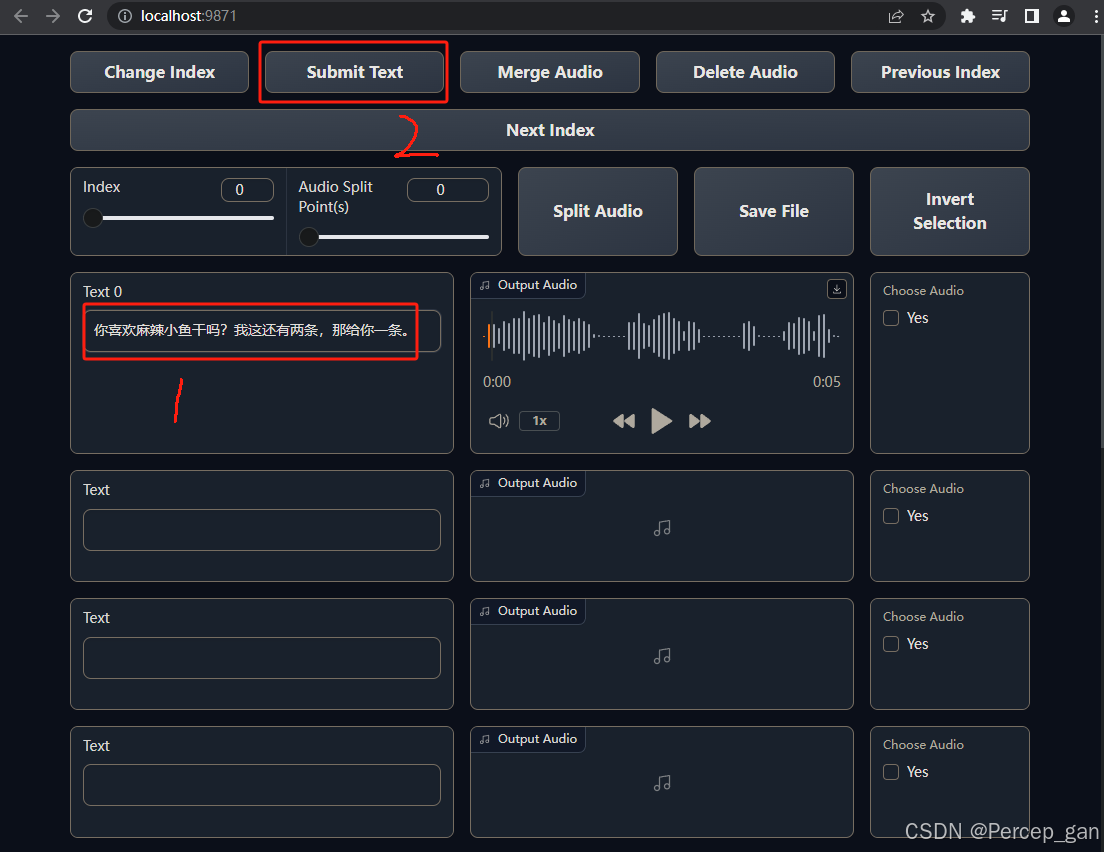
这里原文本为:
你喜欢麻辣小鱼干吗?我这还有两条,那给你一条。
将其改为:
你喜欢麻辣小鱼干吗?我这还有两条,呐~给你一条。
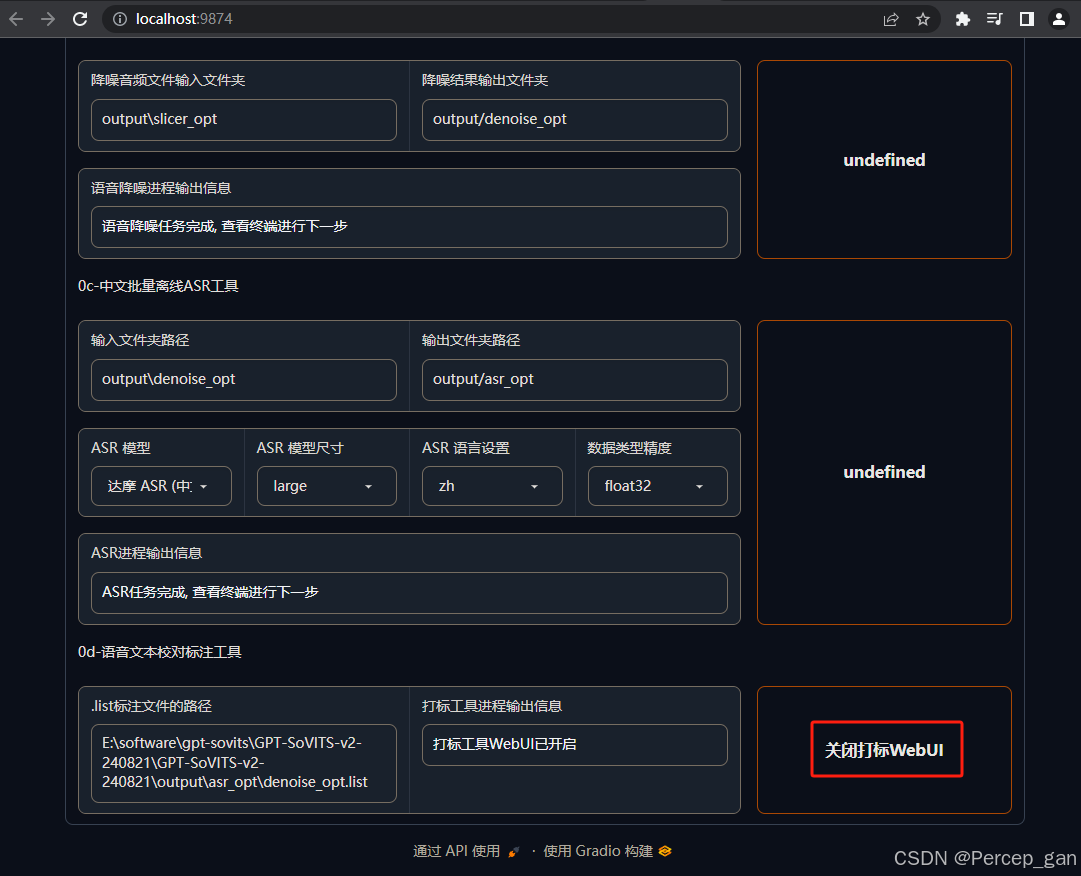
确认无误之后回到主界面,点击"关闭打标WebUI"
7、训练模型
承接上面,将主界面拉到最顶部,选择"1-GPT-SoVITS-TTS"
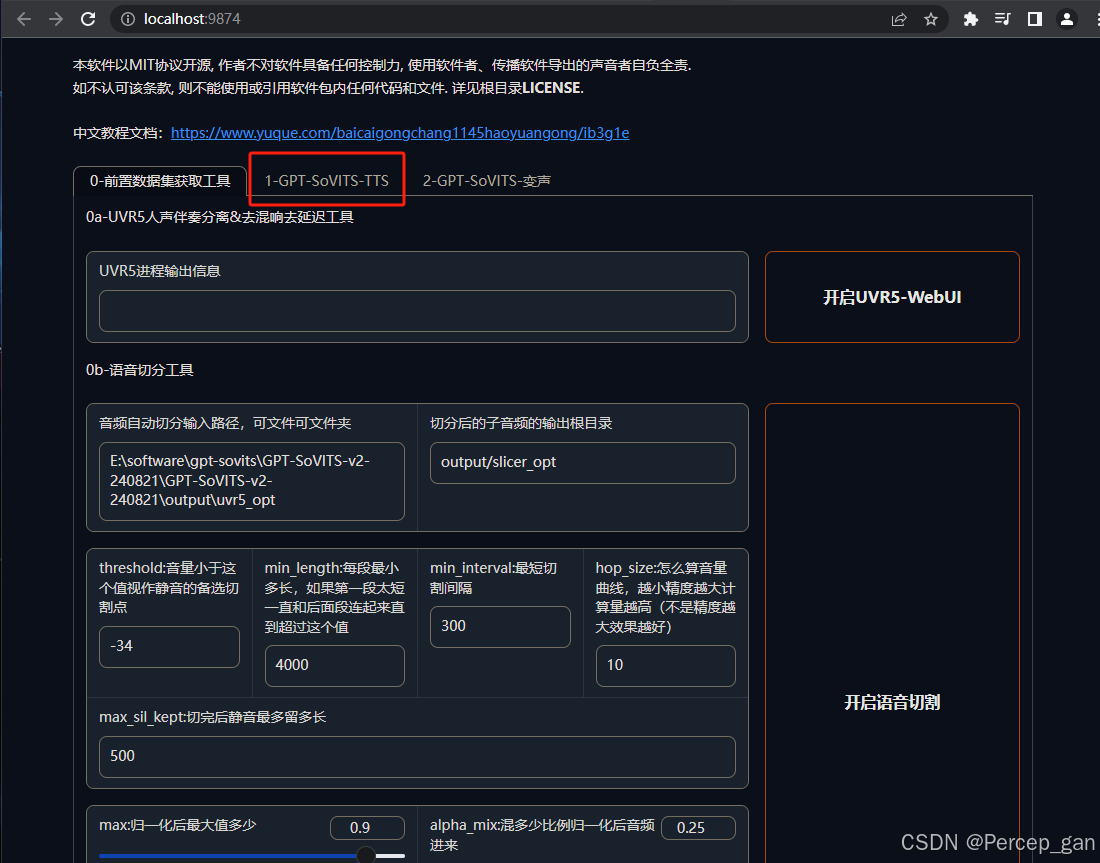
为你的模型取一个名字,这里取名"bbl"
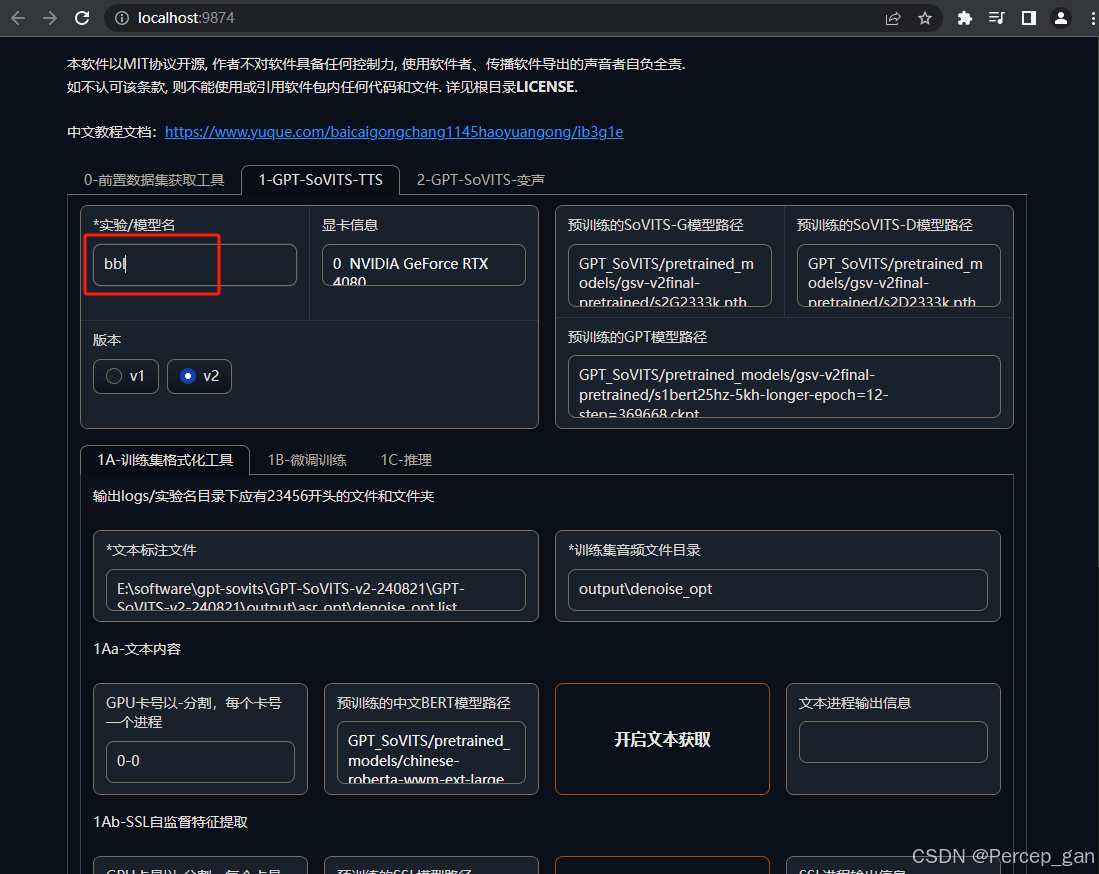
其他不用修改,拉到最下面,点击"开启一键三连"
看到结束的提示即可
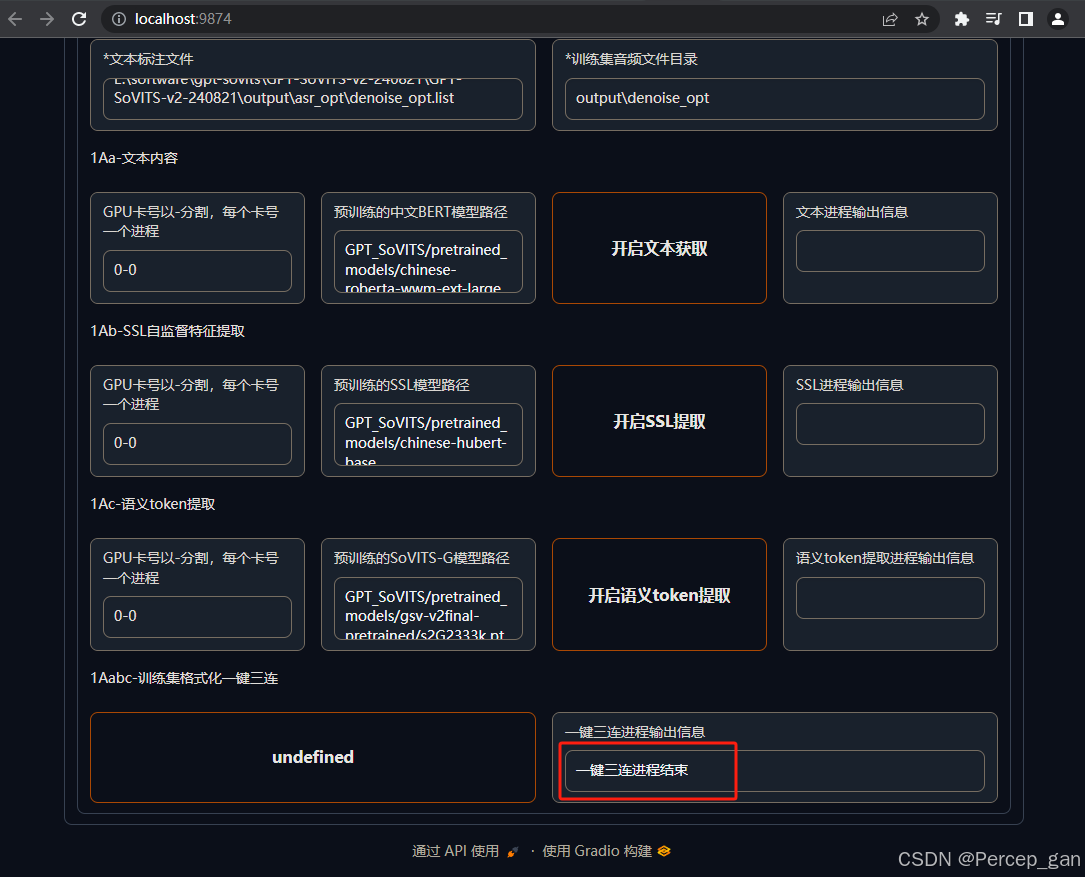
这一步是把你的声音样本转换成项目训练模型支持的特定格式,会在日志文件夹"logs"下生成以前面模型命名的文件夹(bbl)
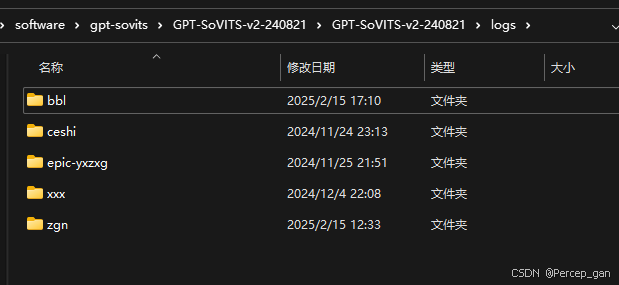
里面文件如下
8、微调训练
承接上面的主界面,网上拉到命名模型那一部分,点击"1B-微调训练"
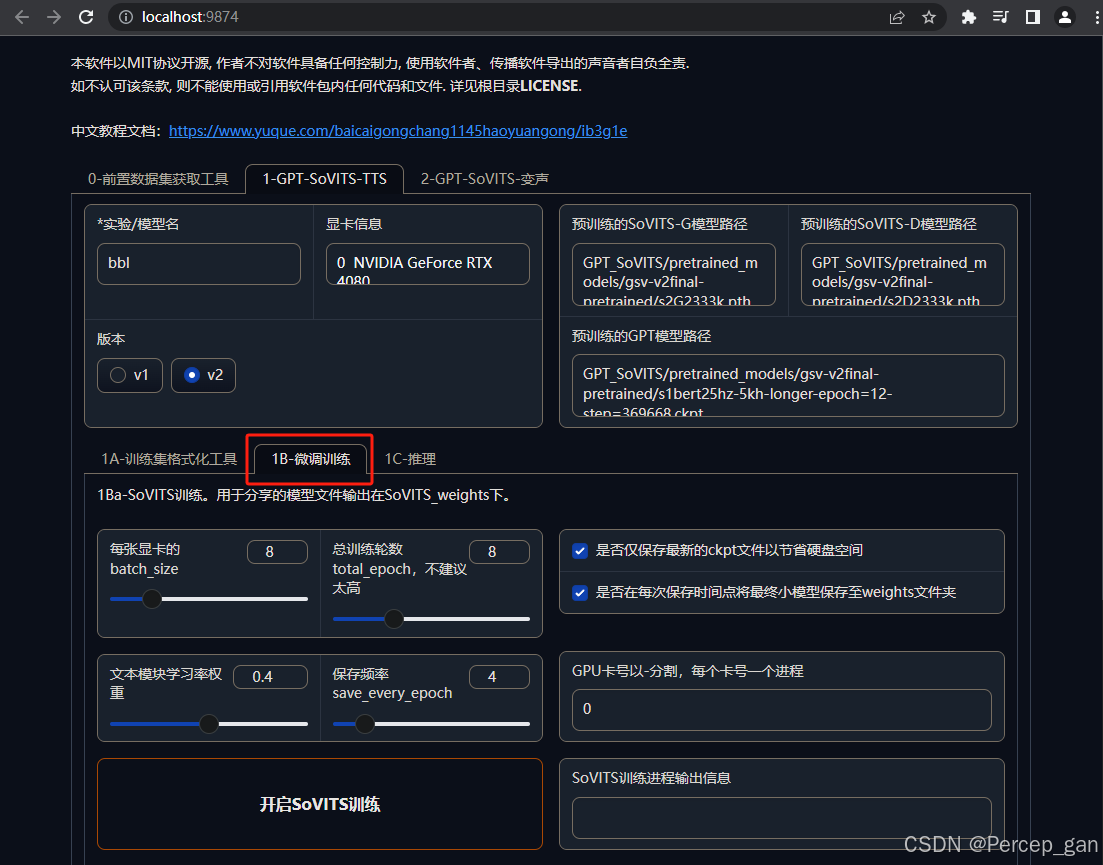
参数默认即可,先"开启SoVITS"
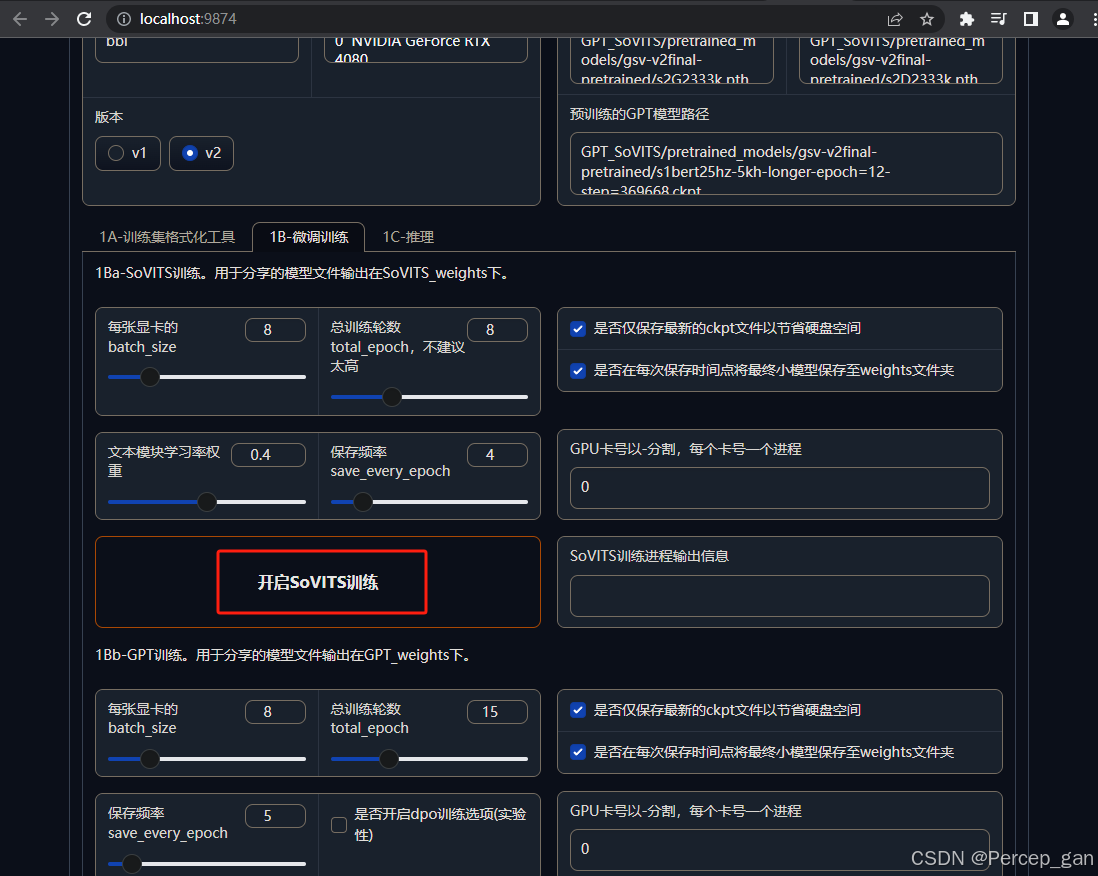
等待训练完成
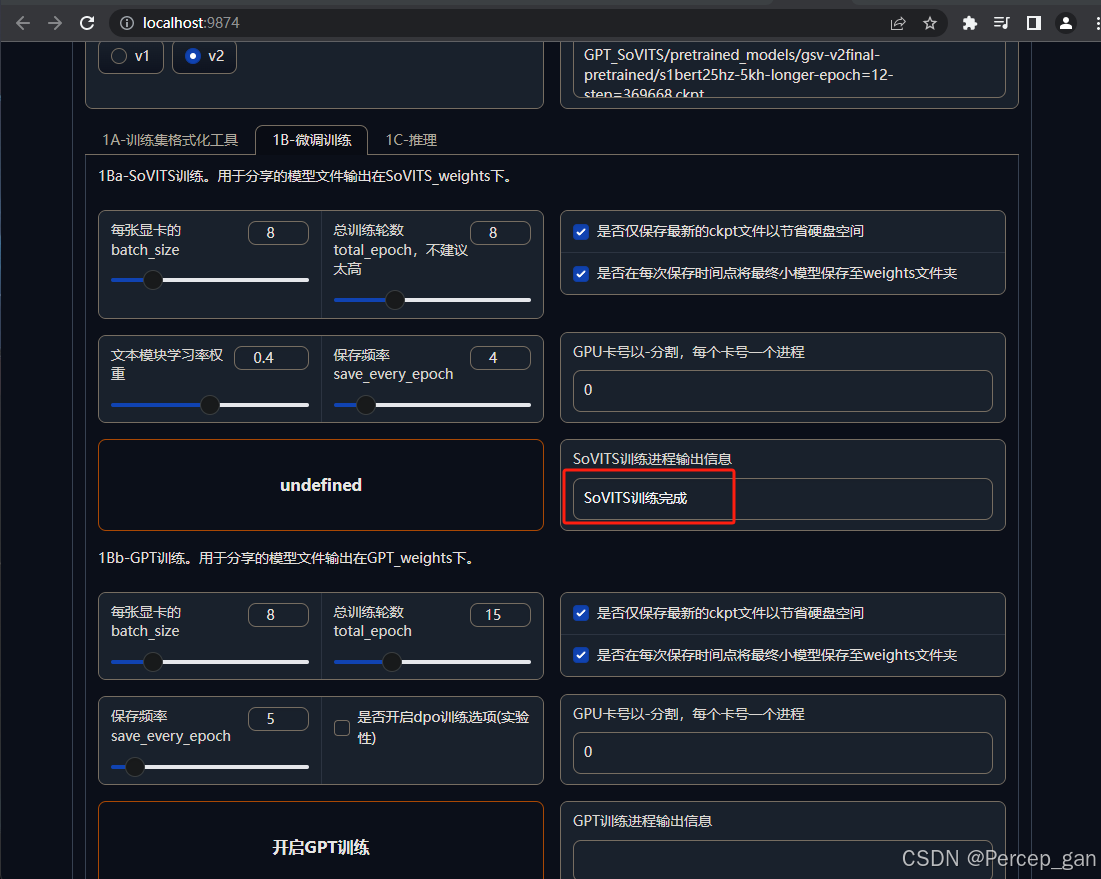
因为本次使用的是"v2"版本的"GPT-SoVITS",生成的模型保存在"安装目录\GPT-SoVITS-v2-240821\GPT-SoVITS-v2-240821\SoVITS_weights_v2"
模型如下
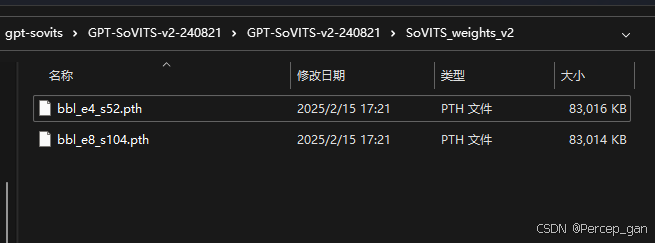
为什么是两个模型?(总训练轮数)/(保存频率)
接着点击"开启GPT训练"
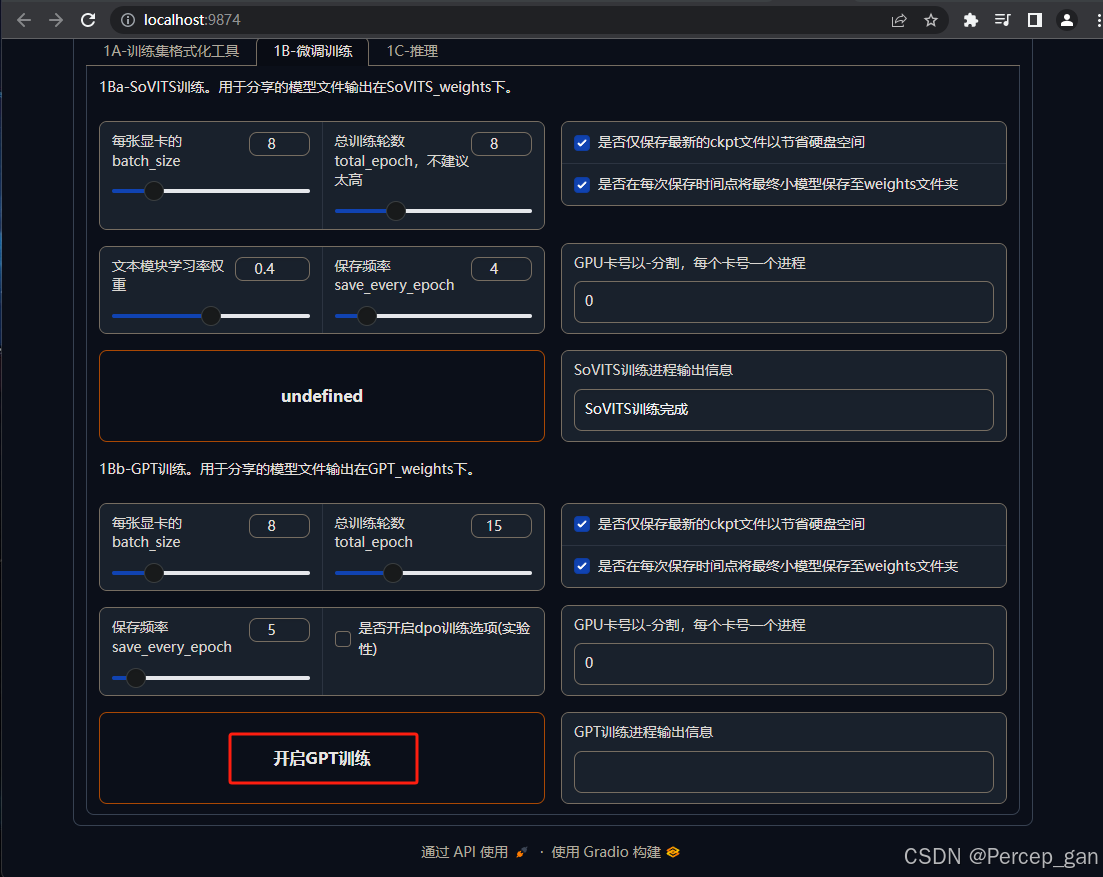
等待训练完成
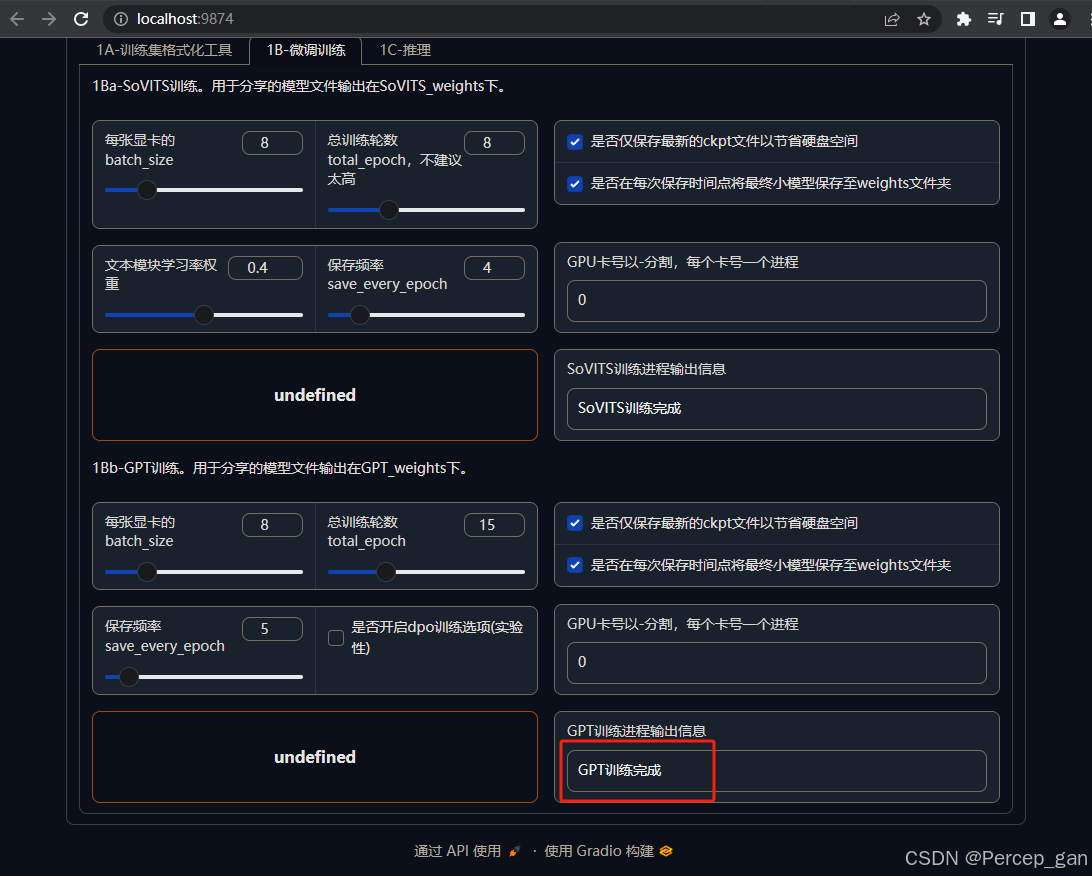
因为本次使用的是"v2"版本的"GPT-SoVITS",生成的模型保存在"安装目录\GPT-SoVITS-v2-240821\GPT-SoVITS-v2-240821\GPT_weights_v2"
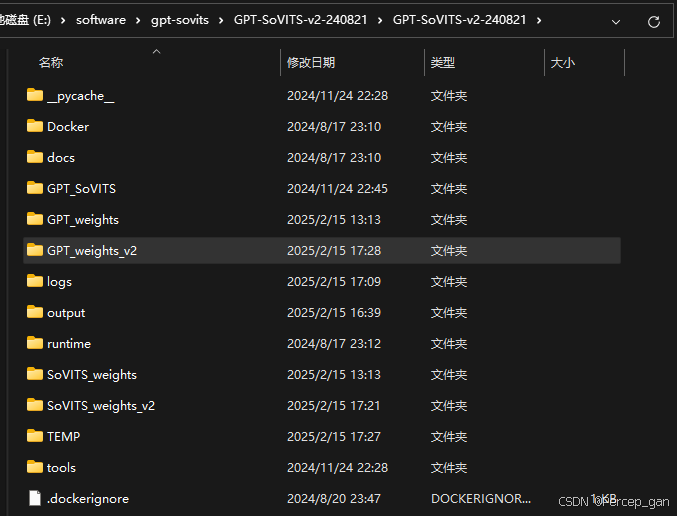
模型如下
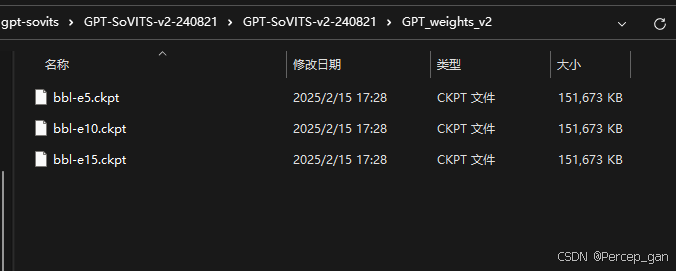
同样,三个模型是因为(总训练轮数)/(保存频率)
9、推理
承接上面的主页面,将其往上拉到命名模型下方,点击"1C-推理"
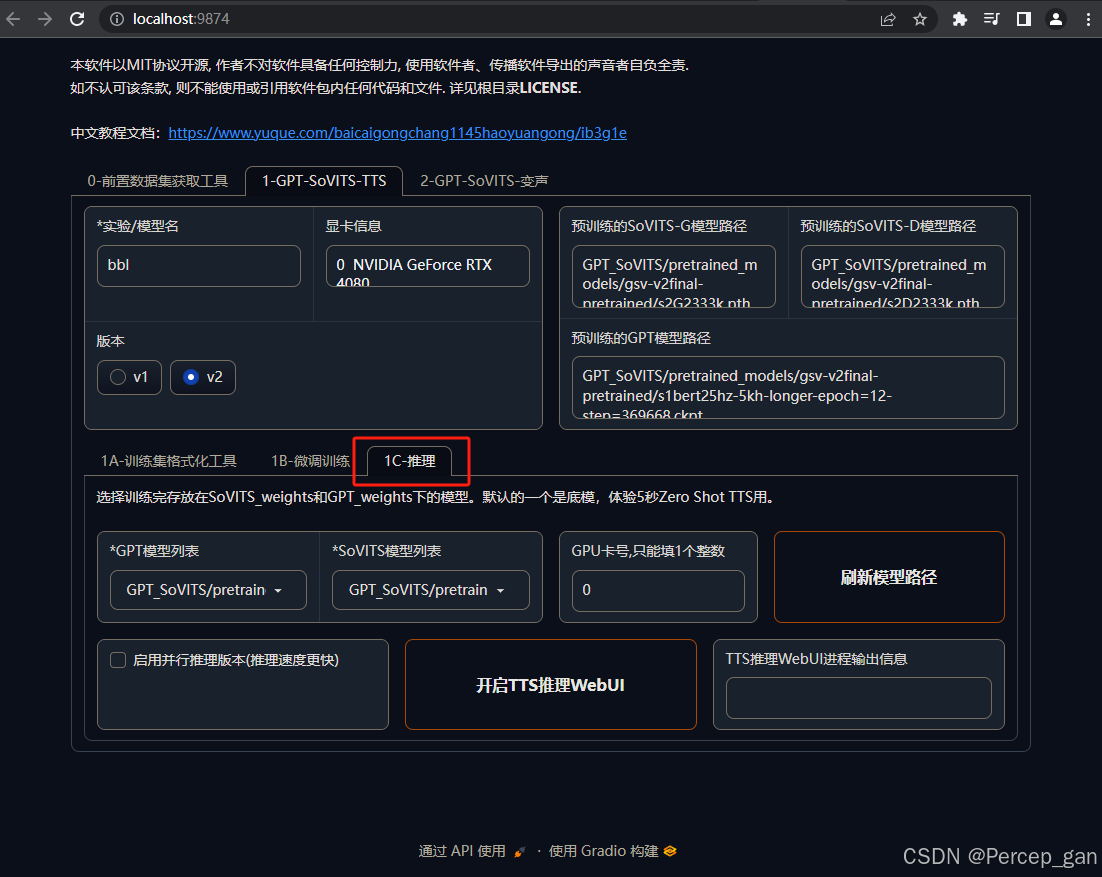
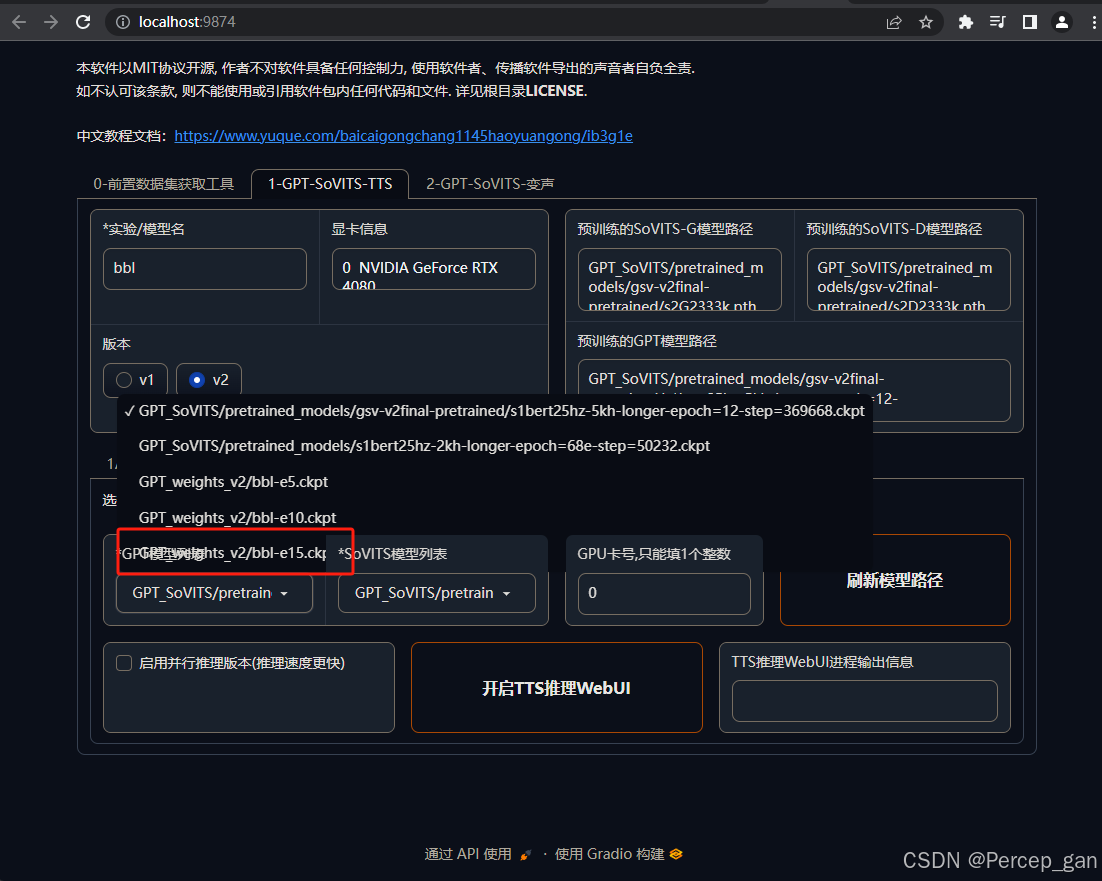
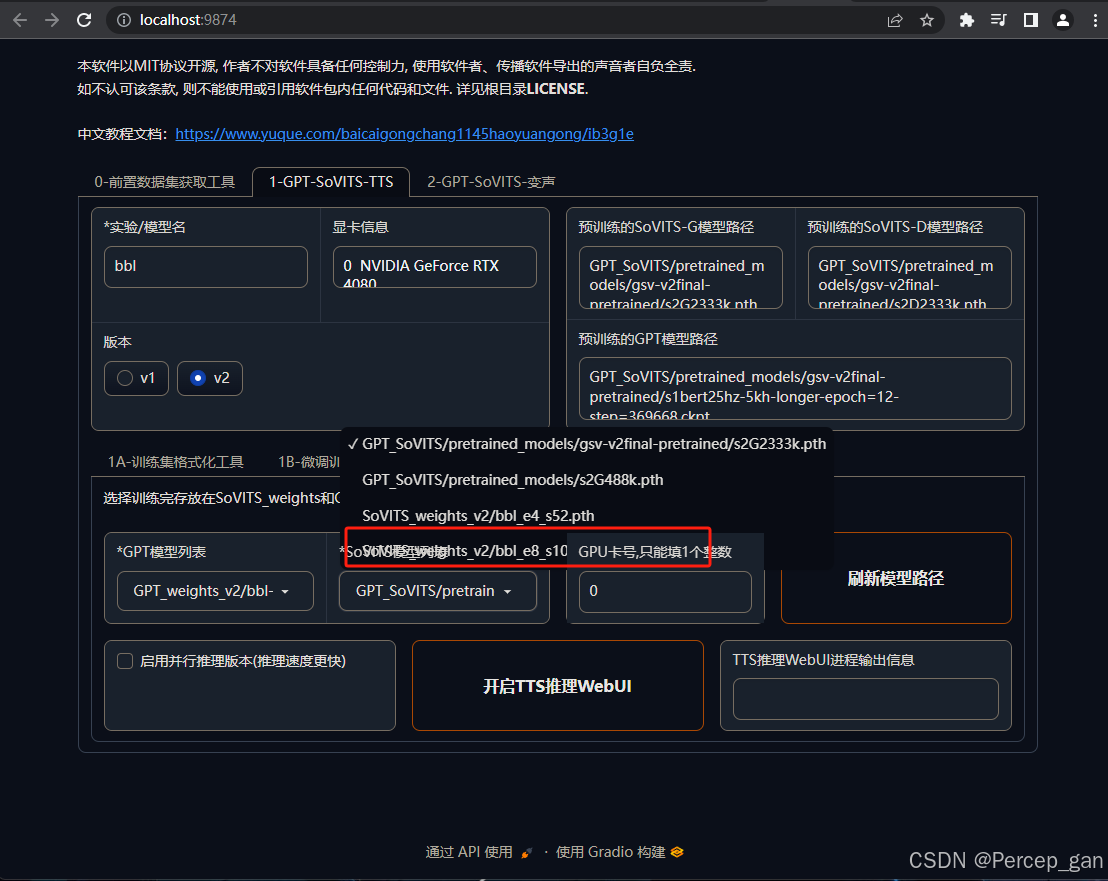
选择GPT、SoVITS模型,如果没有看到就点击一下"刷新模型路径"
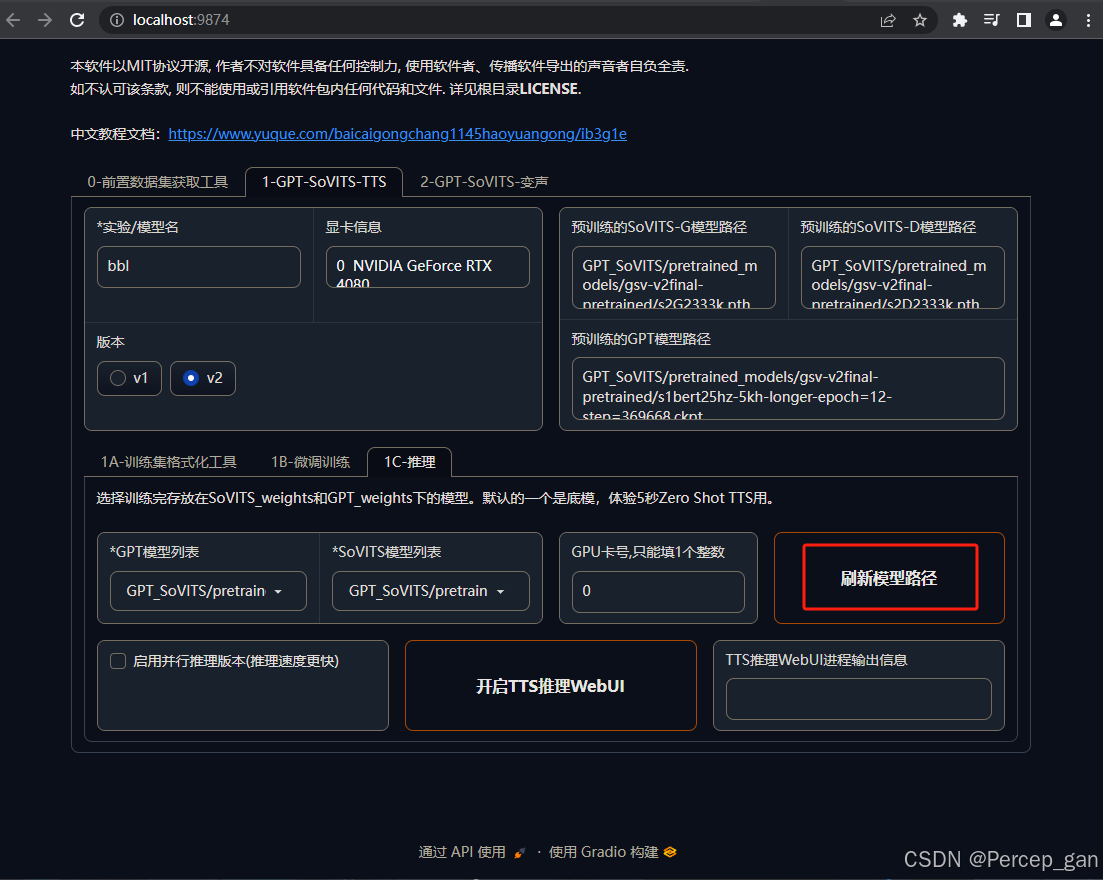
选择参数最大的模型,效果最好
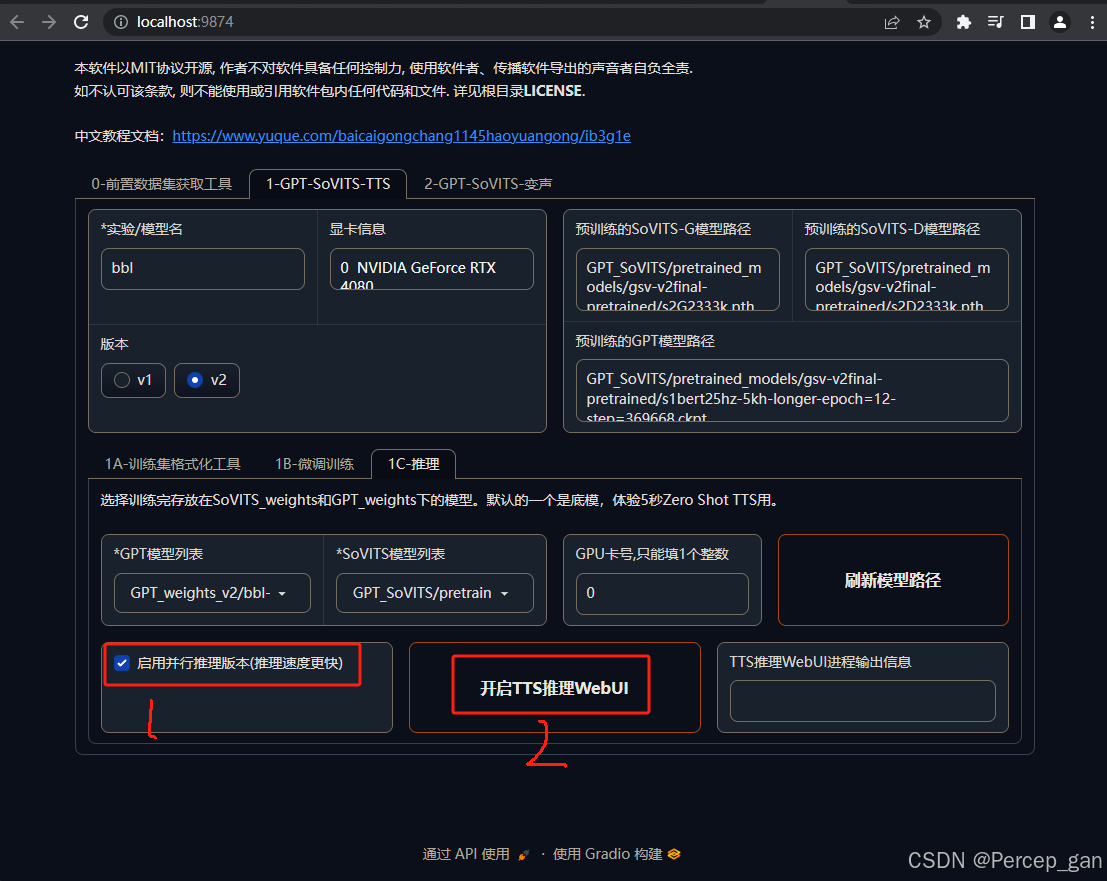
勾选"启用并推理版本",再点击"开启TTS推理WebUI"
会跳转到一个新页面
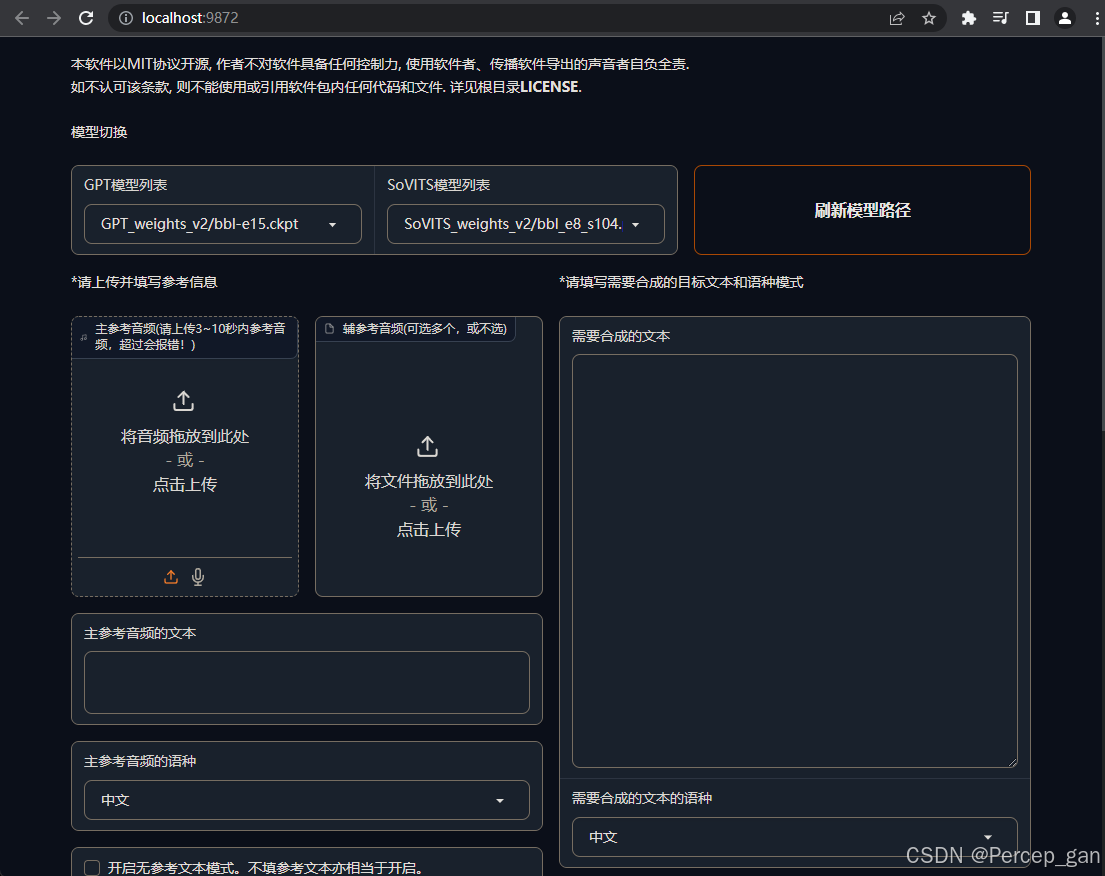
这是模型区,如果在主界面忘记选,可以在这里选,一般选择参数最大的,效果最好
这是推理区,可以将前面处理好的音频拖入,比如前面降噪后的音频
再加上音频台词,就是对应音频的台词
你喜欢麻辣小鱼干吗?我这还有两条,呐~给你一条。
最后在右边添加需要生成音频的文本,这里是:
从来生死都看淡

推理设置保持默认即可,点击"合成语音"就会生成对应音频
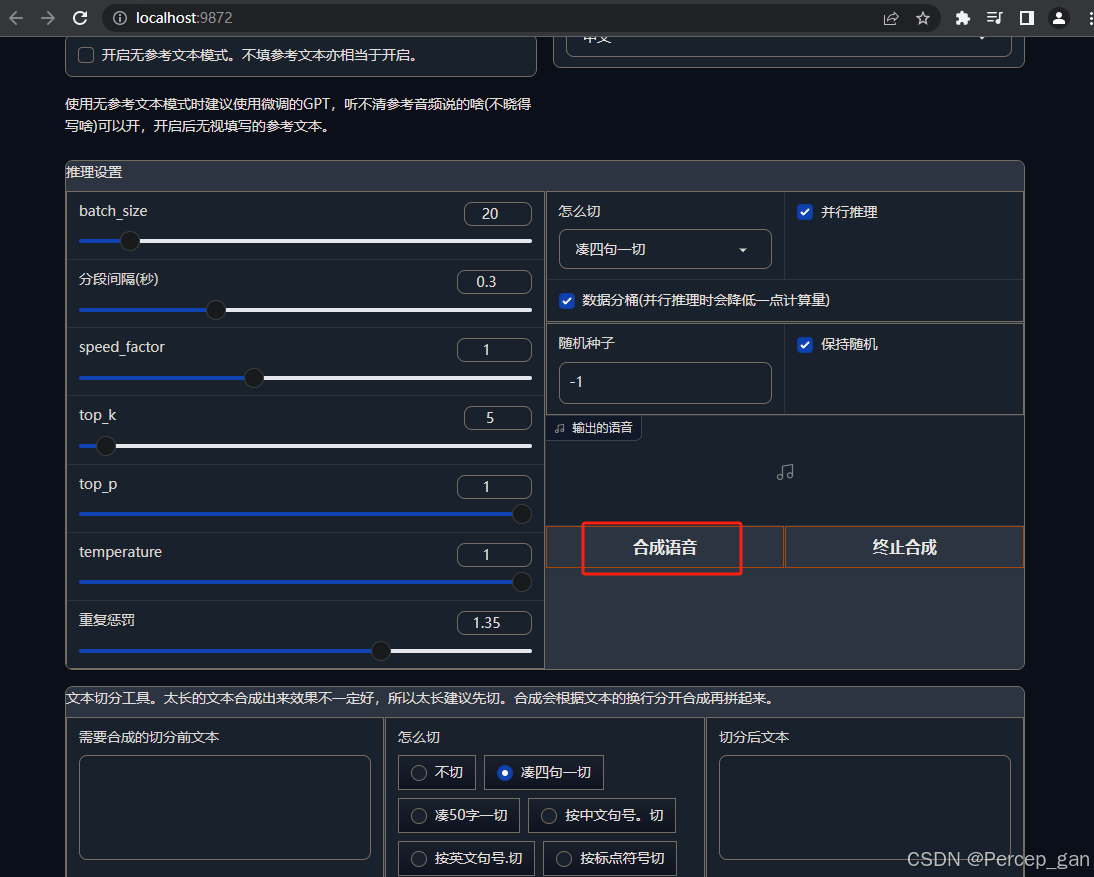
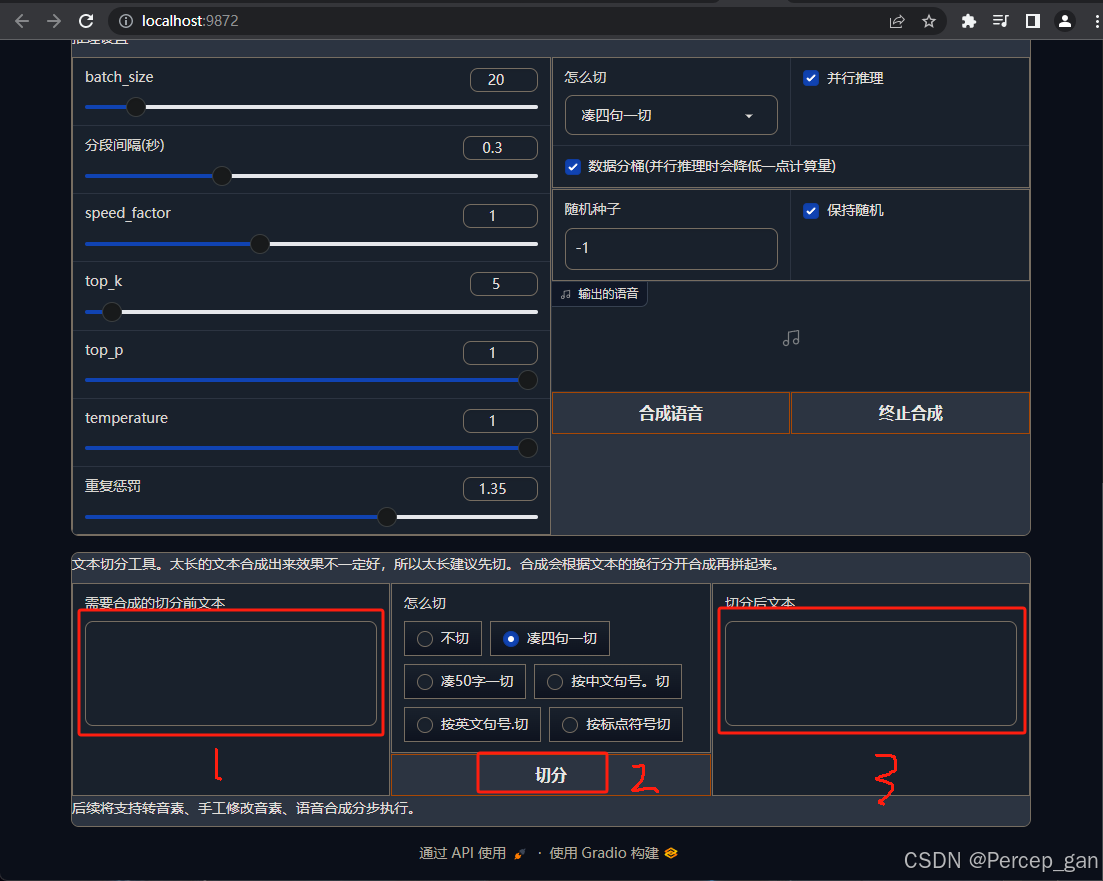
最后是文本切分区,如果文本很长,可以先放到左边,点击切分,切分方式保持默认,再将右边切分好的文本放到文本生成音频区域