【Python】 打造高效文件分类工具
该代码基于 Python 的 tkinter 库实现了 "文件分类工具 - 优化版" 图形化桌面应用。用户能通过界面选择文件夹和要分类的文件类型,支持全选或自定义部分文件扩展名进行分类。采用多线程技术执行文件整理任务,避免界面卡顿且可中途停止。利用 os.scandir 高效遍历文件并批量分组处理,对大文件(超 500MB)增加延迟处理并记录日志。通过消息队列记录整理过程,包含跳过文件、移动文件及错误信息等,支持将日志保存为文本文件。整理完成后显示总文件数、成功移动数、失败次数和跳过文件数等统计信息,还可直接打开整理后的文件夹查看结果。
一、代码整体结构
我们的文件分类工具基于 Python 的 Tkinter 库构建,Tkinter 是 Python 的标准 GUI(Graphical User Interface,图形用户界面)库,它提供了丰富的组件来创建交互式应用程序。整个代码围绕一个名为FileOrganizerApp的类展开,这个类负责管理界面元素、用户交互以及文件整理的核心逻辑。
二、关键代码解析
(一)初始化部分
javascript
class FileOrganizerApp:
def __init__(self, root):
self.root = root
self.root.title("文件分类工具-优化版")
self.root.geometry("800x600")
# 初始化统计变量
self.total_files = 0
self.moved_count = 0
self.error_count = 0
self.current_progress = 0
# 初始化文件类型选择相关变量
self.all_files_var = tk.BooleanVar()
self.checkbox_vars = {}
self.checkboxes = {}
self.preset_extensions = [
"txt", "doc", "docx", "pdf", "jpg",
"png", "gif", "mp3", "mp4", "xls",
"xlsx", "zip", "rar", "ppt", "pptx"
]
# 创建消息队列
self.log_queue = queue.Queue()
self.create_widgets()
self.running = False
self.stop_event = threading.Event()在__init__ 方法中,我们首先设置了应用程序窗口的标题和初始大小。接着,初始化了一系列统计变量,用于记录整理过程中的文件总数、成功移动的文件数、出错的文件数以及当前的进度。
为了让用户能够选择要分类的文件类型,我们定义了all_files_var布尔变量用于全选功能,checkbox_vars字典来存储每个文件扩展名对应的复选框状态,checkboxes字典用于存储复选框组件,preset_extensions列表则列出了我们预设支持分类的文件扩展名。
消息队列log_queue用于在不同线程间传递日志信息,确保界面的流畅更新。最后,调用create_widgets方法创建界面元素,并初始化一些控制变量。
(二)界面创建部分
javascript
def create_widgets(self):
# 文件夹选择部分
frame_top = ttk.Frame(self.root, padding=10)
frame_top.pack(fill=tk.X)
self.btn_select = ttk.Button(frame_top, text="选择文件夹", command=self.select_directory)
self.btn_select.pack(side=tk.LEFT, padx=5)
self.path_var = tk.StringVar()
self.entry_path = ttk.Entry(frame_top, textvariable=self.path_var, width=60)
self.entry_path.pack(side=tk.LEFT, padx=5, fill=tk.X, expand=True)
# 文件类型选择部分
type_frame = ttk.LabelFrame(self.root, text="选择要分类的文件类型", padding=10)
type_frame.pack(fill=tk.BOTH, expand=True, pady=5)
# 全选复选框
ttk.Checkbutton(
type_frame,
text="全部分类",
variable=self.all_files_var,
command=self.toggle_checkboxes
).grid(row=0, column=0, sticky=tk.W, padx=5)
# 创建扩展名复选框
for idx, ext in enumerate(self.preset_extensions):
self.checkbox_vars[ext] = tk.BooleanVar()
cb = ttk.Checkbutton(
type_frame,
text=ext.upper(),
variable=self.checkbox_vars[ext]
)
cb.grid(row=idx // 5 + 1, column=idx % 5, sticky=tk.W, padx=5)
self.checkboxes[ext] = cb
# 控制按钮部分
frame_controls = ttk.Frame(self.root, padding=10)
frame_controls.pack(fill=tk.X)
self.btn_start = ttk.Button(frame_controls, text="开始整理", command=self.start_organize)
self.btn_start.pack(side=tk.LEFT, padx=5)
self.btn_stop = ttk.Button(frame_controls, text="停止", command=self.stop_organize, state=tk.DISABLED)
self.btn_stop.pack(side=tk.LEFT, padx=5)
# 保存日志按钮
self.btn_save_log = ttk.Button(frame_controls, text="保存日志", command=self.save_log, state=tk.DISABLED)
self.btn_save_log.pack(side=tk.LEFT, padx=5)
# 查看文件按钮,初始状态为禁用
self.btn_view_files = ttk.Button(frame_controls, text="查看文件", command=self.open_folder, state=tk.DISABLED)
self.btn_view_files.pack(side=tk.LEFT, padx=5)
# 日志显示部分
frame_log = ttk.Frame(self.root, padding=10)
frame_log.pack(fill=tk.BOTH, expand=True)
self.log_area = scrolledtext.ScrolledText(frame_log, wrap=tk.WORD)
self.log_area.pack(fill=tk.BOTH, expand=True)
# 进度条
self.progress = ttk.Progressbar(self.root, orient=tk.HORIZONTAL, mode='determinate')
self.progress.pack(fill=tk.X, padx=10, pady=5)create_widgets方法负责构建应用程序的整个界面。它分为几个主要部分:
- 文件夹选择部分:包含一个按钮btn_select用于打开文件选择对话框,以及一个输入框entry_path用于显示用户选择的文件夹路径。
- 文件类型选择部分:通过一个标签框架type_frame包含一个全选复选框和多个文件扩展名复选框。全选复选框的command参数绑定到toggle_checkboxes方法,用于切换所有扩展名复选框的状态。
- 控制按钮部分:包括开始整理按钮btn_start、停止按钮btn_stop(初始状态为禁用)、保存日志按钮btn_save_log(初始状态为禁用)和查看文件按钮btn_view_files(初始状态为禁用)。这些按钮分别绑定到对应的功能方法。
- 日志显示部分:使用scrolledtext.ScrolledText组件创建一个可滚动的文本区域log_area,用于显示文件整理过程中的日志信息。
- 进度条部分:通过ttk.Progressbar创建一个水平进度条progress,用于直观展示文件整理的进度。
(三)核心功能部分
javascript
def start_organize(self):
if not self.path_var.get():
messagebox.showwarning("警告", "请先选择要整理的文件夹")
return
if self.running:
return
self.running = True
self.stop_event.clear()
self.btn_start['state'] = tk.DISABLED
self.btn_stop['state'] = tk.NORMAL
self.btn_save_log['state'] = tk.DISABLED
self.btn_view_files['state'] = tk.DISABLED
self.progress['value'] = 0
self.log_area.delete(1.0, tk.END)
# 启动队列处理
self.process_log_queue()
self.update_progress()
worker = threading.Thread(target=self.organize_files, daemon=True)
worker.start()start_organize方法是启动文件整理流程的入口。首先,它检查用户是否选择了要整理的文件夹路径,如果没有则弹出警告框提示用户。然后,检查当前是否已经在运行整理任务,如果是则直接返回。
接着,设置运行状态变量running为True,清除停止事件stop_event,并根据任务状态更新界面按钮的状态,清空进度条和日志区域。
为了确保日志能够及时更新,调用process_log_queue方法启动日志队列处理,同时调用update_progress方法开始更新进度条。最后,创建一个新的线程来执行核心的文件整理逻辑organize_files,并将线程设置为守护线程,这样当主线程结束时,该线程也会自动结束。
javascript
def organize_files(self):
target_dir = self.path_var.get()
try:
# 使用更高效的scandir遍历文件
files = []
with os.scandir(target_dir) as entries:
for entry in entries:
if entry.is_file():
files.append(entry.name)
self.total_files = len(files)
processed_files = 0
# 批量分组处理文件
selected_exts = None
if not self.all_files_var.get():
selected_exts = {ext for ext, var in self.checkbox_vars.items() if var.get()}
file_groups = defaultdict(list)
skipped_count = 0
for filename in files:
if self.stop_event.is_set():
break
_, ext = os.path.splitext(filename)
ext = ext.lower().lstrip('.') if ext else 'no_extension'
if selected_exts is None or ext in selected_exts:
file_groups[ext].append(filename)
else:
skipped_count += 1
# 处理跳过的文件
self.log_queue.put(f"已跳过 {skipped_count} 个未选类型的文件")
# 批量移动文件
total_to_process = sum(len(v) for v in file_groups.values())
processed = 0
for ext, filenames in file_groups.items():
if self.stop_event.is_set():
break
dest_dir = os.path.join(target_dir, ext)
os.makedirs(dest_dir, exist_ok=True)
for filename in filenames:
if self.stop_event.is_set():
break
file_path = os.path.join(target_dir, filename)
try:
# 大文件处理(超过500MB时增加延迟)
file_size = os.path.getsize(file_path)
if file_size > 500 * 1024 * 1024:
self.log_queue.put(f"正在处理大文件: {filename} ({file_size // 1024 // 1024}MB)")
time.sleep(0.5)
shutil.move(file_path, os.path.join(dest_dir, filename))
self.moved_count += 1
# 每处理50个文件更新一次日志
if self.moved_count % 50 == 0:
self.log_queue.put(f"已移动 {self.moved_count} 个文件")
except Exception as e:
self.error_count += 1
self.log_queue.put(f"错误: {filename} ({str(e)})")
processed += 1
self.current_progress = (processed / total_to_process) * 100
self.root.after(10, self.organize_complete)
except Exception as e:
self.log_queue.put(f"系统错误: {str(e)}")
self.root.after(10, self.organize_complete)organize_files方法是文件分类的核心逻辑所在。它首先获取用户选择的目标文件夹路径target_dir。然后,使用os.scandir函数更高效地遍历目标文件夹中的所有文件,将文件列表存储在files变量中,并记录文件总数total_files。
接下来,根据用户在界面上选择的文件类型进行分组处理。如果用户选择了全部分类(all_files_var为True),则selected_exts为None,表示处理所有文件;否则,通过列表推导式获取用户勾选的文件扩展名集合selected_exts。
使用defaultdict创建file_groups字典,将文件按扩展名分组。在遍历文件过程中,如果文件类型不在用户选择的范围内,则跳过该文件并记录跳过的文件数。
在批量移动文件阶段,首先计算需要处理的文件总数total_to_process。对于每个文件组,创建对应的目标文件夹(如果不存在),然后逐个移动文件。在移动文件时,增加了对大文件(超过 500MB)的处理逻辑,当遇到大文件时,在日志中记录并增加 0.5 秒的延迟,以避免在处理大文件时导致系统卡顿。同时,每成功移动 50 个文件,在日志中记录已移动的文件数。如果移动过程中出现错误,记录错误信息并增加错误计数。
在整个过程中,根据已处理文件数和总文件数实时更新当前进度current_progress。最后,通过root.after方法在 10 毫秒后调用organize_complete方法,用于处理整理完成后的后续操作。
(四)其他辅助功能部分
javascript
def stop_organize(self):
self.stop_event.set()
self.log_queue.put("正在停止整理进程...")stop_organize方法用于停止文件整理任务。它通过设置stop_event事件,通知正在执行文件整理的线程停止操作,并在日志队列中添加停止进程的提示信息。
javascript
def process_log_queue(self):
try:
while True:
msg = self.log_queue.get_nowait()
self.log_area.insert(tk.END, msg + "\n")
self.log_area.see(tk.END)
except queue.Empty:
pass
self.root.after(100, self.process_log_queue)process_log_queue方法负责从日志队列log_queue中获取日志信息,并将其显示在日志区域log_area中。它通过一个循环不断尝试从队列中获取消息,使用get_nowait方法避免阻塞。如果队列为空,捕获queue.Empty异常并跳过。每次获取并显示消息后,通过root.after方法设置 100 毫秒后再次调用自身,以实现实时更新日志。
javascript
def update_progress(self):
self.progress['value'] = self.current_progress
self.root.after(100, self.update_progress)update_progress方法用于更新进度条的显示。它将当前进度current_progress的值设置到进度条progress上,并通过root.after方法设置 100 毫秒后再次调用自身,以实现进度条的实时更新。
javascript
def organize_complete(self):
self.running = False
self.btn_start['state'] = tk.NORMAL
self.btn_stop['state'] = tk.DISABLED
self.btn_save_log['state'] = tk.NORMAL
# 整理完成后启用查看文件按钮
self.btn_view_files['state'] = tk.NORMAL
self.current_progress = 100
stats_message = (
f"\n整理完成:\n"
f"总文件数: {self.total_files}\n"
f"成功移动: {self.moved_count}\n"
f"失败次数: {self.error_count}\n"
f"跳过文件: {self.total_files - self.moved_count - self.error_count}"
)
self.log_queue.put(stats_message)
messagebox.showinfo("整理统计", stats_message)organize_complete方法在文件整理完成后被调用。它首先将运行状态变量running设置为False,并恢复界面按钮的初始状态,启用开始按钮、禁用停止按钮、启用保存日志按钮和查看文件按钮。同时,将进度条设置为 100%。
然后,生成整理统计信息字符串stats_message,包含总文件数、成功移动的文件数、失败次数和跳过的文件数。将统计信息添加到日志队列中,并通过messagebox.showinfo弹出对话框显示整理统计结果。
javascript
def save_log(self):
log_text = self.log_area.get(1.0, tk.END)
file_path = filedialog.asksaveasfilename(defaultextension=".txt", filetypes=[("Text files", "*.txt")])
if file_path:
try:
with open(file_path, 'w', encoding='utf-8') as f:
f.write(log_text)
messagebox.showinfo("保存成功", "日志已成功保存。")
except Exception as e:
messagebox.showerror("保存失败", f"保存日志时出现错误:{str(e)}")save_log方法用于将日志区域中的内容保存为文本文件。它首先获取日志区域的所有文本内容log_text,然后通过filedialog.asksaveasfilename打开文件保存对话框,让用户选择保存路径和文件名。如果用户选择了保存路径,尝试将日志内容写入文件。如果保存成功,弹出提示框告知用户;如果保存过程中出现错误,捕获异常并弹出错误提示框。
javascript
def open_folder(self):
folder = self.path_var.get()
if folder:
try:
if os.name == 'nt': # Windows 系统
os.startfile(folder)
elif os.name == 'posix': # Linux 或 macOS 系统
webbrowser.open(folder)
except Exception as e:
messagebox.showerror("错误", f"打开文件夹时出错: {str(e)}")open_folder方法用于在文件整理完成后,打开用户选择的目标文件夹。它
首先获取用户在界面上选择的文件夹路径folder。如果路径存在,根据当前操作系统类型进行不同的操作:对于 Windows 系统,使用os.startfile函数打开文件夹;对于 Linux 或 macOS 系统,使用webbrowser.open函数打开文件夹。如果在打开过程中出现异常,捕获异常并通过messagebox.showerror弹出错误提示框,告知用户打开文件夹时出现的错误信息。
三、运行与使用
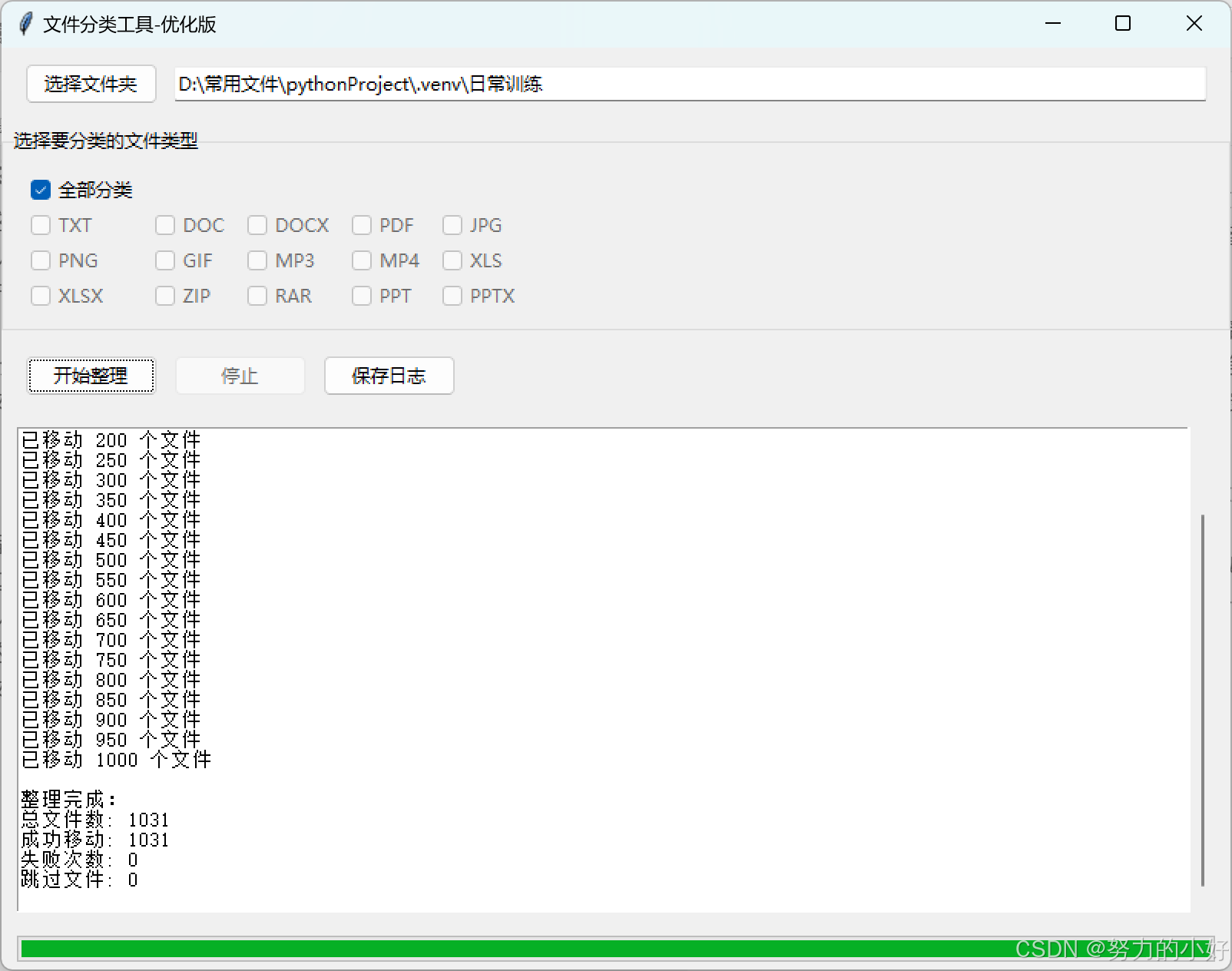
当你运行这段代码时,会弹出一个图形化界面的文件分类工具窗口。在窗口中,你可以通过点击 "选择文件夹" 按钮选择需要整理文件的文件夹路径,该路径会显示在输入框中。
在 "选择要分类的文件类型" 区域,你可以选择 "全部分类",也可以单独勾选需要分类的文件扩展名类型,如 "TXT""JPG""PDF" 等。完成选择后,点击 "开始整理" 按钮,工具将开始扫描文件夹内的文件,并按照你选择的类型进行分类整理。
在整理过程中,进度条会实时显示整理进度,日志区域会记录整理过程中的详细信息,包括每个文件的处理情况、错误信息等。如果在整理过程中你想停止操作,可以点击 "停止" 按钮。整理完成后,你可以点击 "保存日志" 按钮将整理过程中的日志信息保存为文本文件,也可以点击 "查看文件" 按钮直接打开整理后的文件夹查看分类结果。
四、示图
五、作者有话说
代码功能已经过严格测试,确认无误。然而,值得注意的是,测试集的大小仅为3个G,相对而言规模较小,因此无法百分之百保证在所有情况下均无任何问题。鉴于此,强烈建议在使用之前做好数据备份,以防万一出现数据丢失的情况。如果您在使用过程中发现任何bug或问题,欢迎随时留言反馈,作者将及时响应并进行相应的修改。