高并发内存池项目开发记录 - 02

目录
今天要实现什么
昨天把Common.h的基础数据结构写完了,今天要开始实现内存池的第一层:ThreadCache。
一开始我还不太理解为什么需要三层架构,后来想明白了:ThreadCache就是给每个线程分配自己的"小仓库",这样大部分时候线程从自己仓库拿东西,不用跟别人抢,自然就快了。
上午:理解ThreadCache设计
为什么需要ThreadCache
花了差不多1小时搞清楚这个问题。其实就是解决多线程竞争的问题:
传统malloc的问题:
线程A、B、C都调用malloc
↓
全局堆(有锁)
↓
所有线程排队等待性能瓶颈就在这个全局锁上。多个线程同时申请内存时,必须排队,这在高并发场景下会很慢。
ThreadCache的解决方案:
线程A → ThreadCache A(无锁)
线程B → ThreadCache B(无锁)
线程C → ThreadCache C(无锁)
↓
CentralCache(需要时才访问)每个线程有自己的ThreadCache,大部分时候不需要加锁,只有缓存不够时才去CentralCache申请。
TLS机制是什么
TLS(Thread Local Storage)这个概念一开始我不太懂。后来查了资料才明白,就是让每个线程有自己独立的变量副本。
普通全局变量的问题:
cpp
ThreadCache* globalCache = nullptr; // 所有线程共享一个
// 线程A和B都调用GetCache()会返回同一个ThreadCache
// 这样就失去了"线程专属"的意义TLS的解决方案:
cpp
thread_local ThreadCache* tlsCache = nullptr; // 每个线程独立
// 线程A第一次调用:tlsCache为nullptr,创建ThreadCache A
// 线程B第一次调用:tlsCache也是nullptr(但这是B的副本),创建ThreadCache B
// 两个线程的tlsCache是独立的!这个设计很巧妙,用C++11的thread_local关键字就能实现。
TLS机制工作原理图
线程B 线程A 是 否 是 否 调用GetTLSThreadCache pTLSThreadCache B = nullptr? 创建 ThreadCache B 返回 ThreadCache B指针 调用GetTLSThreadCache pTLSThreadCache A = nullptr? 创建 ThreadCache A 返回 ThreadCache A指针
关键点: 每个线程的pTLSThreadCache变量是独立的,互不干扰。
下午:开始写代码
ThreadCache类框架
先写了个基本框架:
cpp
class ThreadCache {
public:
void* Allocate(size_t size); // 申请内存
void Deallocate(void* ptr, size_t size); // 释放内存
private:
FreeList _freeLists[NFREELIST]; // 208个FreeList
};设计思路:
- 用户申请13字节 → 对齐到16字节 → 计算index=1 → 从
_freeLists[1]分配 - 如果
_freeLists[1]为空 → 向CentralCache批量申请
TLS机制实现
这里有个小坑,一开始我用了Windows特有的__declspec(thread):
cpp
__declspec(thread) ThreadCache* pTLSThreadCache = nullptr;后来想到这个只有MSVC支持,如果要跨平台应该用C++11标准的thread_local:
cpp
static thread_local ThreadCache* pTLSThreadCache = nullptr;然后写了个获取函数:
cpp
static ThreadCache* GetTLSThreadCache() {
if (pTLSThreadCache == nullptr) {
pTLSThreadCache = new ThreadCache; // 懒加载
}
return pTLSThreadCache;
}理解关键点:
- 每个线程第一次调用时创建自己的ThreadCache
- 后续调用直接返回,不需要重复创建
- 不同线程的
pTLSThreadCache指向不同的对象
批量申请策略
Allocate函数的实现比较直接:
cpp
void* Allocate(size_t size) {
//1. 计算索引
size_t index = SizeClass::Index(size);
//2. 检查FreeList是否有缓存
if (!_freeLists[index].Empty()) {
return _freeLists[index].Pop(); // 直接从缓存取
}
//3. 缓存为空,批量申请
return FetchFromCentralCache(index, SizeClass::RoundUp(size));
}ThreadCache内存申请流程
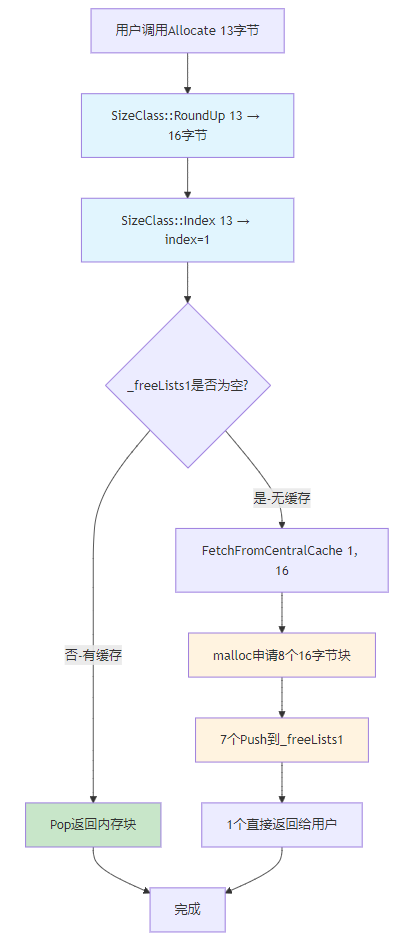
FetchFromCentralCache的临时实现:
因为CentralCache还没写,所以先用malloc模拟。但这里有个细节我一开始理解错了:
cpp
void* FetchFromCentralCache(size_t index, size_t size) {
// ❌ 错误理解:申请一个大块,自己切分
// void* bigBlock = malloc(8 * size);
// ✅ 正确做法:申请8个独立的size大小的块
for (int i = 0; i < 7; ++i) {
void* obj = malloc(size); // 每次申请size字节
_freeLists[index].Push(obj); // 缓存7个
}
return malloc(size); // 第8个直接返回
}为什么是8个? 这是个经验值,一次申请太少会频繁调用(性能差),申请太多会浪费内存。后面会实现慢增长算法动态调整。
ListTooLong智能检查
Deallocate实现后遇到一个问题:如果某个线程疯狂申请然后全部释放,FreeList会积累大量内存。
举个例子:
线程A申请1000个32字节对象
线程A全部释放回ThreadCache
→ _freeLists[1]现在有1000个对象
→ 但线程A可能以后都不用了
→ 这些内存就浪费了所以需要一个检查机制:
cpp
void Deallocate(void* ptr, size_t size) {
size_t index = SizeClass::Index(size);
_freeLists[index].Push(ptr);
// 🎯 检查是否缓存太多了
if (ListTooLong(index)) {
// TODO: 归还给CentralCache
}
}ListTooLong的设计思路:
一开始我想设个固定值,比如超过100个就归还。但后来想到,8字节的对象和64KB的对象不能用同一个标准:
- 8字节 × 100 = 800字节(没啥影响)
- 64KB × 100 = 6.4MB(太浪费了!)
所以要分段设置阈值:
cpp
bool ListTooLong(size_t index) {
size_t maxCount = 0;
if (index <= 15) { // 8-128字节(小对象)
maxCount = 512; // 多缓存点没关系
}
else if (index <= 71) { // 129-1024字节(中等对象)
maxCount = 256; // 适中
}
else { // 更大的对象
maxCount = 64; // 严格控制
}
return _freeLists[index].Size() > maxCount;
}这些数字是怎么来的?
老实说,现在就是拍脑袋定的一个初始值。真正要优化得等性能测试后根据数据调整。所以代码里加了TODO注释提醒后面优化。
遇到的问题
问题1:理解内存分配的大小
用户申请13字节,到底发生了什么?这个问题困扰了我一会儿。
完整流程:
用户:tc->Allocate(13)
↓
Step1: SizeClass::RoundUp(13) = 16字节(8字节对齐)
Step2: SizeClass::Index(13) = 1(映射到FreeList[1])
Step3: FetchFromCentralCache(1, 16)
↓
申请8个16字节的内存块
↓
7个Push到_freeLists[1]
1个返回给用户用户实际得到16字节,但只用13字节,多出的3字节就是内部碎片。这是空间换时间的代价。
问题2:FreeList中的内存管理
在实现Deallocate时,需要注意ListTooLong的检查时机。如果检查过于频繁,会影响性能;检查不及时,又会浪费内存。
目前的方案是每次Deallocate都检查一次,虽然简单,但感觉可能不是最优解。后面可能需要考虑:
- 定时检查?
- 达到某个阈值后才检查?
这些细节等后面优化时再考虑。
问题3:项目文件管理
Git提交时差点把不必要文件文档也提交上去了。这些文档是我自己学习用的,不应该出现在GitHub上。
后来用git reset回退了提交,只提交了核心代码。
测试验证
写了个简单的测试验证基本功能:
cpp
int main() {
cout << "Testing ThreadCache..." << endl;
// 测试TLS机制
ThreadCache* tc1 = GetTLSThreadCache();
ThreadCache* tc2 = GetTLSThreadCache();
cout << "TLS test: " << (tc1 == tc2) << " (should be 1)" << endl;
// 测试批量申请
void* ptr1 = tc1->Allocate(32); // 触发FetchFromCentralCache
void* ptr2 = tc1->Allocate(32); // 从缓存获取
void* ptr3 = tc1->Allocate(32); // 从缓存获取
cout << "Batch allocation test:" << endl;
cout << "ptr1: " << ptr1 << endl;
cout << "ptr2: " << ptr2 << endl;
cout << "ptr3: " << ptr3 << endl;
// 验证指针有效性
if (ptr1 && ptr2 && ptr3) {
cout << "Cache validation: All pointers valid" << endl;
}
// 测试释放
tc1->Deallocate(ptr1, 32);
tc1->Deallocate(ptr2, 32);
tc1->Deallocate(ptr3, 32);
cout << "All tests passed!" << endl;
return 0;
}运行结果:

TLS机制工作正常,批量申请也没问题(申请的空间地址基本连续)。虽然现在用的是malloc模拟,但至少验证了整体逻辑是对的。
今天的收获
1. 理解了TLS机制
thread_local关键字真的很强大,它让每个线程拥有独立的变量副本,而且用法很简单。这在多线程编程中是个很重要的技术。
2. 学会了迭代开发思维
一开始我想一次性把所有功能都实现完美,但后来发现这样反而容易卡住。
更好的方式是:
- 先用临时方案(malloc模拟CentralCache)
- 跑通基本流程
- 后面再逐步完善
这种"先能跑,再优化"的思路在工程中很实用。
3. 理解了内存管理的权衡
ListTooLong的阈值设计让我意识到,系统设计很少有"完美"的方案,都是在各种约束下做权衡:
- 缓存多了 → 浪费内存
- 缓存少了 → 频繁申请,性能差
只能根据实际场景调整参数,没有一劳永逸的答案。
4. Git工作流的实践
虽然只是个人项目,但也尽量模拟真实的开发流程:
- 规范的提交信息
- 合理的文件管理(学习文档不上传GitHub)
- 出错后用
git reset回退
这些细节以后工作中肯定用得上。
完整代码
ThreadCache.h
cpp
#pragma once
#include "Common.h"
class ThreadCache
{
public:
// 申请和释放内存对象
void* Allocate(size_t size)
{
//1.计算索引
size_t index = SizeClass::Index(size);
//2.检查对应的Freelist是否为空
if(!_freeLists[index].Empty())
{
//3.有内存直接返回
return _freeLists[index].Pop();
}
//没内存了,向CentralCache批量申请
return FetchFromCentralCache(index, SizeClass::RoundUp(size));
};
void Deallocate(void* ptr, size_t size)
{
//1.计算索引,和Allocate一样
size_t index = SizeClass::Index(size);
//2.将对象push到对应的Freelist中
_freeLists[index].Push(ptr);
//3.检查是否需要批量归还给CentralCache
if (ListTooLong(index)) {
// TODO: 实现批量归还给CentralCache的逻辑
// ReleaseToCentralCache(index);
}
};
private:
// TODO: 性能调优时根据实测数据调整这些阈值
static const size_t SMALL_OBJ_MAX_COUNT = 512; // 小对象最大缓存数
static const size_t MEDIUM_OBJ_MAX_COUNT = 256; // 中等对象最大缓存数
static const size_t LARGE_OBJ_MAX_COUNT = 64; // 大对象最大缓存数
// 检查FreeList是否过长,需要批量归还
bool ListTooLong(size_t index)
{
size_t maxCount = 0;
if (index <= 15) { // 8-128字节,小对象
maxCount = SMALL_OBJ_MAX_COUNT;
}
else if (index <= 71) { // 129-1024字节,中等对象
maxCount = MEDIUM_OBJ_MAX_COUNT;
}
else { // 更大的对象
maxCount = LARGE_OBJ_MAX_COUNT;
}
return _freeLists[index].Size() > maxCount;
}
// 向CentralCache批量申请内存对象
void* FetchFromCentralCache(size_t index, size_t size)
{
// TODO: 实现慢增长算法,当前固定申请8个
// TODO: 调用真正的CentralCache,当前用malloc模拟
// 前7个直接Push到FreeList缓存起来
for (int i = 0; i < 7; ++i) {
void* obj = malloc(size);
_freeLists[index].Push(obj);
}
// 第8个直接返回给用户使用
void* returnObj = malloc(size);
return returnObj;
}
FreeList _freeLists[NFREELIST]; // 自由链表数组
};
// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象
static thread_local ThreadCache* pTLSThreadCache = nullptr;
// 获取当前线程的ThreadCache对象
static ThreadCache* GetTLSThreadCache() {
if (pTLSThreadCache == nullptr) {
pTLSThreadCache = new ThreadCache;
}
return pTLSThreadCache;
}test_threadcache.cpp
cpp
#include "../src/ThreadCache.h"
int main() {
cout << "Testing ThreadCache..." << endl;
// 测试TLS机制
ThreadCache* tc1 = GetTLSThreadCache();
ThreadCache* tc2 = GetTLSThreadCache();
cout << "TLS test: " << (tc1 == tc2) << " (should be 1)" << endl;
// 测试批量申请机制
void* ptr1 = tc1->Allocate(32); // 第一次申请,会触发FetchFromCentralCache
void* ptr2 = tc1->Allocate(32); // 第二次申请,应该从缓存中取
void* ptr3 = tc1->Allocate(32); // 第三次申请,应该从缓存中取
cout << "Batch allocation test:" << endl;
cout << "ptr1: " << ptr1 << endl;
cout << "ptr2: " << ptr2 << endl;
cout << "ptr3: " << ptr3 << endl;
// 验证缓存是否成功的关键指标
if (ptr1 && ptr2 && ptr3) {
cout << "Cache validation: All pointers valid" << endl;
cout << "Expected: ptr2 and ptr3 from cache (fast)" << endl;
} else {
cout << "Cache validation: FAILED - Null pointers detected!" << endl;
}
// 测试释放
tc1->Deallocate(ptr1, 32);
tc1->Deallocate(ptr2, 32);
tc1->Deallocate(ptr3, 32);
cout << "All tests passed!" << endl;
return 0;
}下一步开发
接下来要开始CentralCache的设计和实现。这个会比ThreadCache复杂,因为涉及到:
- 多线程同步 - 需要加锁保护
- Span管理 - 要用到Day1实现的Span结构
- 与PageCache的交互 - 内存不够时向PageCache申请
目前对CentralCache的理解还比较模糊,需要慢慢搞清楚。不过至少ThreadCache这一层已经基本完成了,有了第一层的基础,后面应该会更容易理解。
ThreadCache实现的核心思路是:用空间换时间,批量换无锁。这个思想在后面的CentralCache和PageCache设计中应该也会用到。
开发时长:约4小时