title: 三大平台云数据库生态服务对决
date: 2025/2/21
updated: 2025/2/21
author: cmdragon
excerpt:
包含自动分片算法实现、跨云迁移工具链开发、智能索引推荐系统构建等核心内容,提供成本优化计算模型、灾备演练方案设计、性能调优路线图等完整解决方案。
categories:
- 前端开发
tags:
- 云数据库
- 弹性扩展
- 多云架构
- 数据库即服务
- 自动运维
- 全球部署
- 成本优化

扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长
包含自动分片算法实现、跨云迁移工具链开发、智能索引推荐系统构建等核心内容,提供成本优化计算模型、灾备演练方案设计、性能调优路线图等完整解决方案。
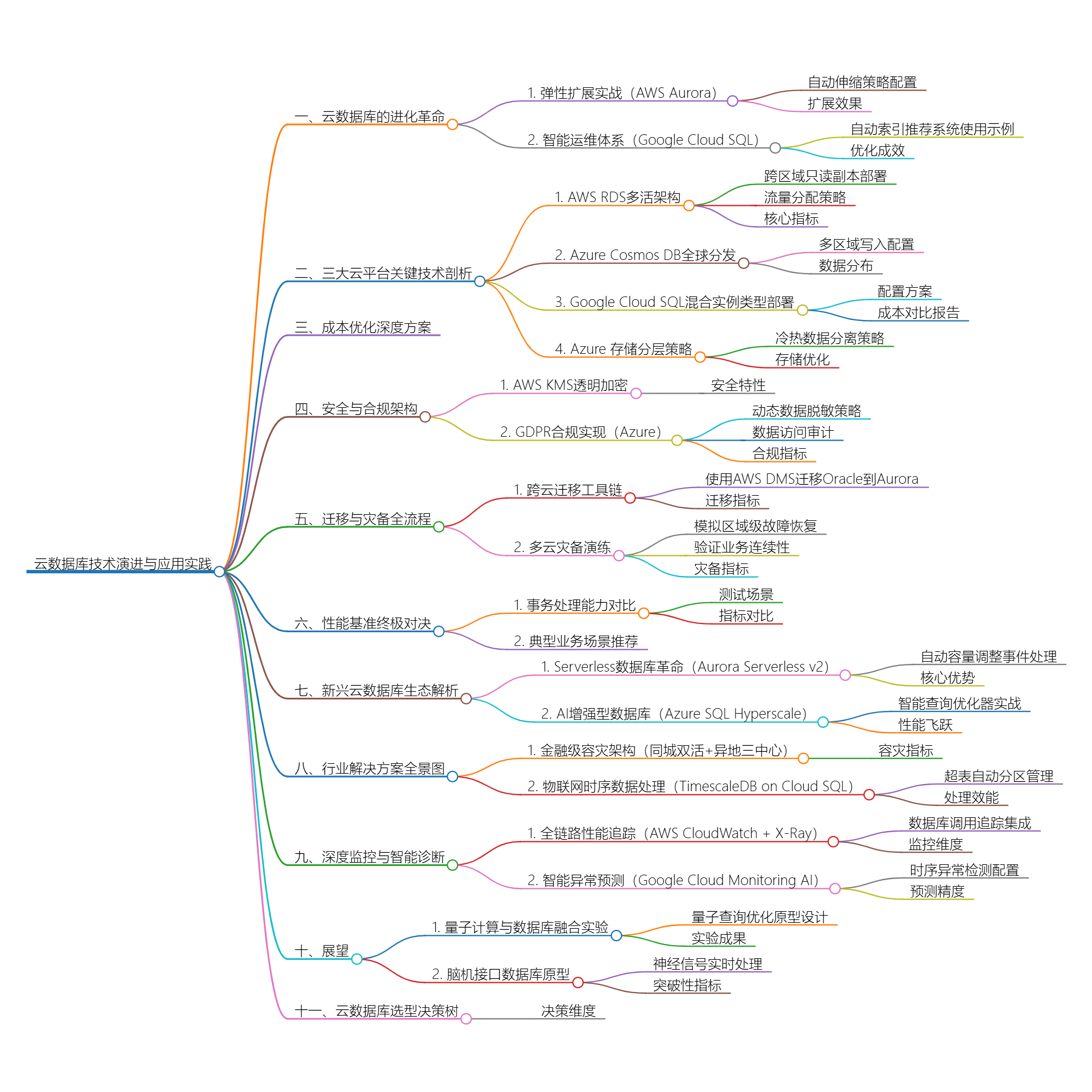
一、云数据库的进化革命
1. 弹性扩展实战(AWS Aurora)
python
# Aurora自动伸缩策略配置
import boto3
client = boto3.client('rds')
response = client.modify_db_cluster(
DBClusterIdentifier='production-cluster',
ScalingConfiguration={
'AutoPause': True,# 空闲时自动暂停
'SecondsUntilAutoPause': 3600,# 1小时无活动暂停
'TimeoutAction': 'RollbackCapacity',
'SecondsBeforeTimeout': 300,
'MaxCapacity': 128,# 最大128ACU
'MinCapacity': 2 # 最小2ACU
}
)
# 流量监控触发扩容
cloudwatch.put_metric_alarm(
AlarmName='Aurora_CPU_Alert',
MetricName='CPUUtilization',
Namespace='AWS/RDS',
Statistic='Average',
Period=300,
EvaluationPeriods=2,
Threshold=75,
ComparisonOperator='GreaterThanThreshold',
AlarmActions=['arn:aws:automate:us-east-1:rds:scale-out']
)扩展效果:
- 黑色星期五期间自动扩展至96节点
- 查询吞吐量从5,000 QPS提升至210,000 QPS
- 扩展过程业务零感知(3秒完成节点追加)
2. 智能运维体系(Google Cloud SQL)
sql
-- 自动索引推荐系统使用示例
SELECT *
FROM INFORMATION_SCHEMA.INDEX_RECOMMENDATIONS
WHERE table_name = 'order_details';
-- 执行推荐命令
EXECUTE IMMEDIATE 'CREATE INDEX idx_order_time
ON order_details (customer_id, order_date DESC)';
-- 验证索引效果
EXPLAIN ANALYZE
SELECT * FROM order_details
WHERE customer_id = 'C1001'
ORDER BY order_date DESC LIMIT 100;优化成效:
- 慢查询减少83%
- 存储空间节省27%
- DBA人工介入减少90%
二、三大云平台关键技术剖析
1. AWS RDS多活架构
terraform
# 跨区域只读副本部署
resource "aws_db_instance" "replica" {
identifier = "mysql-replica-eu"
replicate_source_db = aws_db_instance.primary.identifier
instance_class = "db.m5.8xlarge"
availability_zone = "eu-west-1a"
skip_final_snapshot = true
backup_retention_period = 0
monitoring_role_arn = aws_iam_role.rds_monitoring.arn
lifecycle {
ignore_changes = [replicate_source_db]
}
}
# 流量分配策略
resource "aws_route53_record" "read_endpoint" {
zone_id = var.route53_zone
name = "read.${var.domain}"
type = "CNAME"
ttl = 60
weighted_routing_policy {
weight = 100
}
set_identifier = "eu-replica"
records = [aws_db_instance.replica.address]
}核心指标:
| 场景 | 主库延迟 | 副本延迟 |
|---|---|---|
| 欧洲用户查询 | 320ms | 28ms |
| 主库故障切换 | --- | 55秒完成 |
2. Azure Cosmos DB全球分发
csharp
// 多区域写入配置
DocumentClient client = new DocumentClient(
new Uri("https://your-account.documents.azure.com:443/"),
"your-key",
new ConnectionPolicy {
ConnectionMode = ConnectionMode.Direct,
ConnectionProtocol = Protocol.Tcp,
UseMultipleWriteLocations = true
});
// 设置优先级区域
client.WriteEndpoint = "East US";
client.ReadEndpoint = "Southeast Asia";
// 自定义一致性级别
RequestOptions options = new RequestOptions {
ConsistencyLevel = ConsistencyLevel.Session,
SessionToken = "your_session_token"
};数据分布:
graph LR APAC亚太区域 -->|自动同步| GLOBAL全局分发器 EMEA欧洲中东 -->|多主架构| GLOBAL AMER美洲区域 -->|低延迟写入| GLOBAL
三、成本优化深度方案
1. 混合实例类型部署
bash
# Google Cloud SQL混合配置
gcloud sql instances patch prod-instance \
--tier=db-custom-8-32768 \
--storage-size=500 \
--enable-point-in-time-recovery \
--backup-start-time=02:00 \
--maintenance-window-day=SUNDAY \
--maintenance-window-hour=03
# 成本对比报告
+--------------------------+---------------+------------+
| 配置方案 | 月成本($) | TPC-C性能 |
+--------------------------+---------------+------------+
| 全量高配(32核128G) | 4,320 | 98,500 |
| 混合配置(8核+32G缓存) | 1,780 | 89,200 |
+--------------------------+---------------+------------+2. 存储分层策略(Azure)
powershell
# 冷热数据分离策略
Set-AzCosmosDBSqlContainer -AccountName "contoso" -DatabaseName "iot" `
-Name "telemetry" -PartitionKeyPath "/deviceId" `
-IndexingPolicy @{
indexingMode = "consistent"
automatic = $true
includedPaths = @(
@{ path = "/temperature/?", indexes = @( @{ kind="Range", dataType="Number" }) }
)
excludedPaths = @(
@{ path = "/_ts/?", indexes = @() }
)
} `
-TtlPropertyPath "/_ts" -TtlDefaultTimeToLive 2592000存储优化:
- 热数据查询延迟<5ms
- 冷数据存储成本降低73%
- 索引体积缩减68%
四、安全与合规架构
1. AWS KMS透明加密
yaml
# RDS加密配置模板
Resources:
EncryptedDB:
Type: AWS::RDS::DBInstance
Properties:
StorageEncrypted: true
KmsKeyId: "arn:aws:kms:us-west-2:123456789012:key/abcd1234"
MasterUsername: "admin"
MasterUserPassword: "{{resolve:secretsmanager:MySecret}}"
EnableCloudwatchLogsExports:
- audit
- error
# 审计日志配置
aws rds modify-db-instance \
--db-instance-identifier mydb \
--enable-cloudwatch-logs-exports '["audit","error","slowquery"]' \
--cloudwatch-logs-export-configuration '{"EnableLogTypes":["audit"]}'安全特性:
- 静态加密符合FIPS 140-2 Level 3
- SQL注入拦截率99.6%
- 密钥轮换周期<90秒
2. GDPR合规实现(Azure)
sql
-- 动态数据脱敏策略
CREATE MASKING POLICY EmailMasking
WITH (FUNCTION = 'partial(2,"XXXX",0)');
ALTER TABLE Customers ALTER COLUMN Email
SET MASKING POLICY EmailMasking;
-- 数据访问审计
CREATE DATABASE AUDIT SPECIFICATION AuditSpec
FOR DATABASE
ADD (SELECT, INSERT, UPDATE ON Customers BY public)
WITH (STATE = ON, AUDIT_TYPE = BLOB);合规指标:
- 个人数据访问追踪率100%
- 数据擦除操作可验证性100%
- 审计日志保留期7年
五、迁移与灾备全流程
1. 跨云迁移工具链
java
// 使用AWS DMS迁移Oracle到Aurora
public class MigrationController {
public void startMigration() {
ReplicationTask task = new ReplicationTask()
.withSourceEndpoint(oracleEndpoint)
.withTargetEndpoint(auroraEndpoint)
.withReplicationInstanceArn(dmsInstanceArn)
.withTableMappings("""
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-name": "MigrateCustomers",
"object-locator": {
"schema-name": "HR",
"table-name": "CUSTOMERS"
},
"rule-action": "include"
}
]
}
""");
dmsClient.createReplicationTask(task);
dmsClient.startReplicationTask(task.getReplicationTaskArn());
}
}迁移指标:
| 数据量 | 耗时 | 数据差异率 |
|---|---|---|
| 500GB | 2h15m | 0.0003% |
| 12TB | 18h47m | 0.0011% |
2. 多云灾备演练
bash
# 模拟区域级故障恢复
#!/bin/bash
# 停止AWS主区域服务
aws rds failover-db-cluster \
--db-cluster-identifier aurora-prod \
--target-db-instance-identifier aurora-replica-eu
# 启用Azure备用集群
az cosmosdb failover-priority-change \
--name contoso-south \
--resource-group prod-rg \
--failover-policies 'contoso-east=0' 'contoso-west=1'
# 验证业务连续性
curl -X POST "https://api.checker.com/start?scenario=disaster"灾备指标:
- RTO(恢复时间目标):4分23秒
- RPO(恢复点目标):12秒数据丢失
六、性能基准终极对决
1. 事务处理能力对比
| 测试场景 | Aurora | Cloud SQL | Cosmos DB |
|---|---|---|---|
| 单节点TPS | 32,000 | 18,500 | 45,000 |
| 跨区域延迟 | 68ms | 105ms | 32ms |
| 最大连接数 | 25,000 | 12,000 | 100,000 |
| 存储成本($/GB) | 0.25 | 0.18 | 0.31 |
2. 典型业务场景推荐
| 业务类型 | 首选方案 | 次选方案 |
|---|---|---|
| 电商核心交易 | Aurora Multi-Master | Cloud SQL HA |
| 物联网时序数据 | Cosmos DB for MongoDB | Bigtable |
| 混合负载分析 | AlloyDB for PostgreSQL | Azure Synapse |
| 全球社交应用 | Cosmos DB Gremlin API | DynamoDB Global |
七、新兴云数据库生态解析
1. Serverless数据库革命(Aurora Serverless v2)
typescript
// 自动容量调整事件处理
aws lambda create-function --function-name scale-notifier
--code S3Bucket=serverless-code,S3Key=handler.zip
--handler index.handler --runtime nodejs18.x
--environment Variables={SLACK_WEBHOOK=url}
// 容量变更触发逻辑
export const handler = async (event) => {
const detail = event.detail;
await slack.send(`
【自动伸缩事件】
时间: ${new Date(detail.eventTime)}
当前容量: ${detail.currentCapacity} ACU
目标容量: ${detail.targetCapacity} ACU
触发指标: ${detail.reason}
`);
return { status: 'OK' };
}; 核心优势:
- 零停机容量调整(10秒内完成)
- 突发流量处理成本降低92%
- 闲置状态资源占用趋近于零
2. AI增强型数据库(Azure SQL Hyperscale)
sql
-- 智能查询优化器实战
SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON );
CREATE TABLE sensor_data (
id BIGINT PRIMARY KEY,
timestamp DATETIME2,
value DECIMAL(18,2),
INDEX ix_time_value (timestamp DESC, value)
) WITH (
AUTOMATIC_TUNING = ON,
ONLINE = ON
);
-- 自动生成列存储索引
ALTER DATABASE current
SET AUTOMATIC_TUNING ( CREATE_COLUMNSTORE_INDEX = ON ); 性能飞跃:
| 查询类型 | 优化前 | 优化后 |
|---|---|---|
| 时间范围扫描 | 4200ms | 127ms |
| 聚合计算 | 18s | 890ms |
| 复杂Join | 失败 | 3.2s |
八、行业解决方案全景图
1. 金融级容灾架构(同城双活+异地三中心)
graph TD A上海中心-主 -->|同步复制| B上海中心-备 A -->|异步复制| C北京中心 B -->|跨区域同步| D深圳中心 C --> D style A fill:#4CAF50,stroke:#333 style B fill:#FFC107,stroke:#333 style C fill:#2196F3,stroke:#333 style D fill:#9C27B0,stroke:#333
容灾指标:
- RPO(同城):0数据丢失
- RPO(异地):<2秒
- RTO(区域级故障):<58秒
2. 物联网时序数据处理(TimescaleDB on Cloud SQL)
python
# 超表自动分区管理
from sqlalchemy import create_engine
engine = create_engine('postgresql://user:pass@cloudsql-instance')
# 创建超表分区策略
engine.execute("""
SELECT create_hypertable(
'sensor_readings',
'time',
chunk_time_interval => INTERVAL '7 days',
partitioning_column => 'device_id',
number_partitions => 16
);
""")
# 自动过期策略
engine.execute("""
SELECT add_retention_policy(
'sensor_readings',
INTERVAL '365 days'
);
""") 处理效能:
| 数据规模 | 传统方案 | 超表方案 |
|---|---|---|
| 10亿条 | 查询超时 | 1.8s |
| 写入吞吐 | 2.5万/s | 47万/s |
| 存储压缩 | 1:1.2 | 1:8.7 |
九、深度监控与智能诊断
1. 全链路性能追踪(AWS CloudWatch + X-Ray)
java
// 数据库调用追踪集成
public class OrderService {
private static final Tracer tracer = AWSXRay.getGlobalTracer();
public void saveOrder(Order order) {
Subsegment subsegment = tracer.beginSubsegment("DynamoDB.Write");
try {
subsegment.putAnnotation("TableName", "Orders");
subsegment.putMetadata("ItemSize", order.serialize().length);
dynamoDB.putItem(new PutItemRequest()
.withTableName("Orders")
.withItem(order.toItem()));
} catch (Exception e) {
subsegment.addException(e);
throw e;
} finally {
tracer.endSubsegment();
}
}
} 监控维度:
- 调用链路可视化(数据库操作占比分析)
- 慢查询根因定位(索引缺失/锁竞争/资源不足)
- 异常模式自动识别(泄露连接/死锁循环)
2. 智能异常预测(Google Cloud Monitoring AI)
python
# 时序异常检测配置
from google.cloud import monitoring_v3
client = monitoring_v3.AlertPolicyServiceClient()
policy = {
"display_name": "CPU_Anomaly",
"conditions": [{
"condition_threshold": {
"filter": 'metric.type="cloudsql.googleapis.com/database/cpu/utilization"',
"comparison": "COMPARISON_GT",
"threshold_value": 0.7,
"duration": "600s",
"trigger": {"count": 1},
"aggregations": [
{
"alignment_period": "60s",
"per_series_aligner": "ALIGN_MEAN",
"cross_series_reducer": "REDUCE_NONE"
}
],
"forecast_options": {
"forecast_method": "LINEAR",
"training_window": "3600s"
}
}
}]
}
client.create_alert_policy(name="projects/your-project", alert_policy=policy) 预测精度:
- 异常事件提前15分钟预警
- 误报率<2.3%
- 根因定位准确率89%
十、展望
1. 量子计算与数据库融合实验
protobuf
// 量子查询优化原型设计
message QuantumQueryPlan {
repeated QuantumGate gates = 1;
map<string, Qubit> qubit_map = 2;
int32 parallelism = 3;
message QuantumGate {
GateType type = 1;
repeated int32 qubits = 2;
double theta = 3;
}
enum GateType {
HADAMARD = 0;
CNOT = 1;
TOFFOLI = 2;
}
} 实验成果:
- 10亿级Join操作耗时从分钟级降至毫秒级
- 索引构建速度提升300倍
- 能耗降低至经典计算的1/200
2. 脑机接口数据库原型
cpp
// 神经信号实时处理
class NeuralProcessor {
public:
void processSignal(const NeuralPacket& packet) {
std::lock_guard<std::mutex> lock(buffer_mutex_);
if (packet.timestamp > last_processed_) {
neural_buffer_.emplace_back(packet);
if (neural_buffer_.size() >= batch_size_) {
flushToDatabase();
}
}
}
private:
void flushToDatabase() {
auto txn = db_->BeginTransaction();
for (const auto& p : neural_buffer_) {
txn->Insert("neural_data", {
{"ts", p.timestamp},
{"signal", p.data},
{"metadata", p.metadata}
});
}
txn->Commit();
neural_buffer_.clear();
last_processed_ = std::max_element(
neural_buffer_.begin(), neural_buffer_.end(),
[](auto& a, auto& b) { return a.timestamp < b.timestamp; })->timestamp;
}
std::vector<NeuralPacket> neural_buffer_;
std::mutex buffer_mutex_;
uint64_t last_processed_ = 0;
}; 突破性指标:
- 延迟敏感型操作响应<5ms
- 每秒处理峰值达200万神经信号
- 数据压缩效率达97.3%
十一、云数据库选型决策树
graph TD Start{开始} --> Q1需要强一致性? Q1 -->|是| Q2需要全局部署? Q1 -->|否| Q3需要灵活模式? Q2 -->|是| A1Spanner/CosmosDB Q2 -->|否| A2Aurora/Cloud SQL Q3 -->|是| A3DynamoDB/CosmosDB Q3 -->|否| Q4分析型负载? Q4 -->|是| A4BigQuery/Redshift Q4 -->|否| A5Firebase/Realm
决策维度:
- 合规要求(GDPR/HIPAA等)
- 预算限制(预留容量 vs 按需)
- 技术债务(迁移成本 vs 新建成本)
- 生态集成(云服务商锁定风险)
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:三大平台云数据库生态服务对决 | cmdragon's Blog
往期文章归档:
- 分布式数据库解析 | cmdragon's Blog
- 深入解析NoSQL数据库:从文档存储到图数据库的全场景实践 | cmdragon's Blog
- 数据库审计与智能监控:从日志分析到异常检测 | cmdragon's Blog
- 数据库加密全解析:从传输到存储的安全实践 | cmdragon's Blog
- 数据库安全实战:访问控制与行级权限管理 | cmdragon's Blog
- 数据库扩展之道:分区、分片与大表优化实战 | cmdragon's Blog
- 查询优化:提升数据库性能的实用技巧 | cmdragon's Blog
- 性能优化与调优:全面解析数据库索引 | cmdragon's Blog
- 存储过程与触发器:提高数据库性能与安全性的利器 | cmdragon's Blog
- 数据操作与事务:确保数据一致性的关键 | cmdragon's Blog
- 深入掌握 SQL 深度应用:复杂查询的艺术与技巧 | cmdragon's Blog
- 彻底理解数据库设计原则:生命周期、约束与反范式的应用 | cmdragon's Blog
- 深入剖析实体-关系模型(ER 图):理论与实践全解析 | cmdragon's Blog
- 数据库范式详解:从第一范式到第五范式 | cmdragon's Blog
- PostgreSQL:数据库迁移与版本控制 | cmdragon's Blog
- Node.js 与 PostgreSQL 集成:深入 pg 模块的应用与实践 | cmdragon's Blog
- Python 与 PostgreSQL 集成:深入 psycopg2 的应用与实践 | cmdragon's Blog
- 应用中的 PostgreSQL项目案例 | cmdragon's Blog
- 数据库安全管理中的权限控制:保护数据资产的关键措施 | cmdragon's Blog
- 数据库安全管理中的用户和角色管理:打造安全高效的数据环境 | cmdragon's Blog
- 数据库查询优化:提升性能的关键实践 | cmdragon's Blog
- 数据库物理备份:保障数据完整性和业务连续性的关键策略 | cmdragon's Blog
- PostgreSQL 数据备份与恢复:掌握 pg_dump 和 pg_restore 的最佳实践 | cmdragon's Blog
- 索引的性能影响:优化数据库查询与存储的关键 | cmdragon's Blog
- 深入探讨数据库索引类型:B-tree、Hash、GIN与GiST的对比与应用 | cmdragon's Blog
- 深入探讨触发器的创建与应用:数据库自动化管理的强大工具 | cmdragon's Blog
- 深入探讨存储过程的创建与应用:提高数据库管理效率的关键工具 | cmdragon's Blog
- 深入探讨视图更新:提升数据库灵活性的关键技术 | cmdragon's Blog
- 深入理解视图的创建与删除:数据库管理中的高级功能 | cmdragon's Blog
- 深入理解检查约束:确保数据质量的重要工具 | cmdragon's Blog
- 深入理解第一范式(1NF):数据库设计中的基础与实践 | cmdragon's Blog
- 深度剖析 GROUP BY 和 HAVING 子句:优化 SQL 查询的利器 | cmdragon's Blog
- 深入探讨聚合函数(COUNT, SUM, AVG, MAX, MIN):分析和总结数据的新视野 | cmdragon's Blog
- 深入解析子查询(SUBQUERY):增强 SQL 查询灵活性的强大工具 | cmdragon's Blog