在电商大促、金融交易时段或IoT实时监控场景中,企业BI系统常面临瞬时万级并发查询的冲击------运营团队需要实时追踪GMV波动,风控部门需秒级响应欺诈检测,产线监控需毫秒级反馈设备状态。传统单体架构的BI系统在此类场景下极易崩溃,轻则查询超时,重则引发数据服务雪崩。
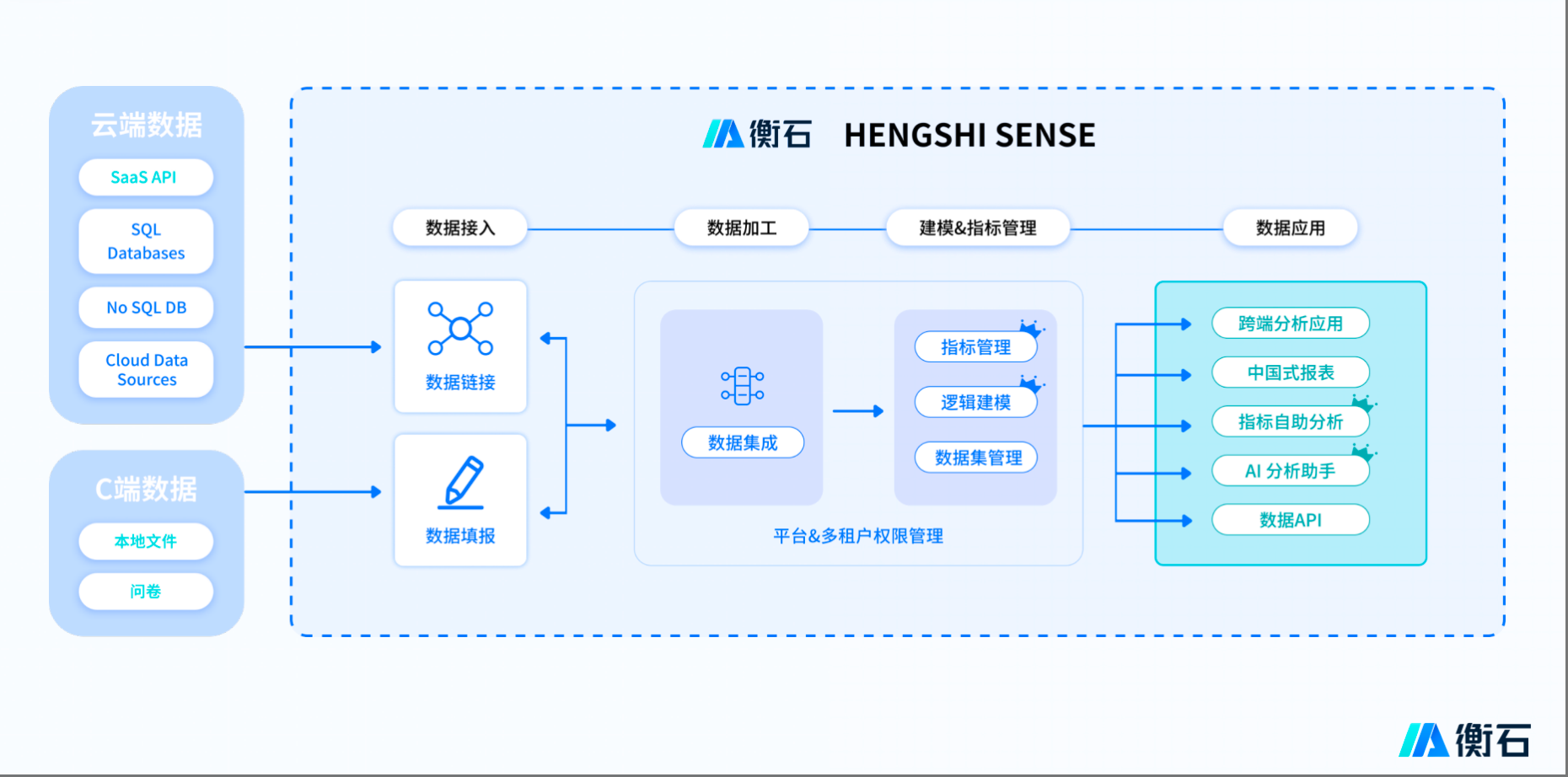
衡石科技HENGSHI SENSE通过分布式查询引擎与智能缓存分级策略,在保障亚秒级响应速度的同时,实现线性扩展能力,支撑日均亿级查询的稳定运行。其核心设计哲学是:用空间换时间,用分层换弹性,用算法换资源。本文将从技术挑战、架构设计、核心算法三方面,深度解析高并发BI系统的技术突围路径。
一、高并发BI的四大技术挑战
资源竞争与长尾延迟
复杂查询(如多表关联、窗口函数)占用大量CPU/内存,阻塞简单查询执行,导致整体响应时间波动(P99延迟可达平均值的10倍)。
热点数据过载
80%的查询集中在20%的热点数据(如当日交易、核心KPI),传统缓存策略易引发内存溢出或缓存穿透。
弹性扩展困境
突发流量下,传统垂直扩展(Scale-up)需分钟级资源调配,无法应对秒级流量脉冲。
多租户资源隔离
SaaS模式下,不同租户查询可能相互干扰,某租户的复杂查询可能耗尽集群资源。
二、架构设计:分布式引擎与缓存策略的三层解耦
衡石HENGSHI SENSE采用查询路由层-计算层-存储层的分层架构,通过动态资源调度与智能缓存实现高并发下的稳定服务。
- 查询路由层:流量整形与动态分发
查询分类器:
基于机器学习模型实时判断查询类型:

-
动态路由策略:
-
简单查询(如点查)路由至本地缓存节点;
-
聚合查询(如GROUP BY)路由至MPP计算集群;
-
复杂查询(如机器学习推理)路由至GPU加速集群。
-
2. 计算层:混合执行引擎
-
MPP引擎(Massively Parallel Processing):
-
采用向量化列式处理,单节点每秒可处理百万行数据;
-
通过数据分片(Sharding) 与**流水线并行(Pipeline Parallelism)**提升吞吐量。
-
-
流式结果返回:
- 对超过1秒的长查询,先返回部分结果(如进度条、初步统计值),避免用户等待焦虑。
3. 存储层:分级缓存与冷热分离
-
四层缓存体系:
层级 介质 容量 命中率 典型场景 L0 内存 10GB 60% 当日高频指标(如实时GMV) L1 SSD 1TB 30% 近7天数据聚合结果 L2 分布式KV 10TB 9% 历史月份摘要 L3 对象存储 PB级 1% 原始数据备份 -
冷热数据自动迁移 :
基于LRU-K算法识别热点数据,夜间定时将冷数据降级至低成本存储。
三、关键技术突破:让高并发不再依赖堆硬件
1. 自适应并发控制(ACC)算法
-
动态限流 :
根据集群负载实时调整并发度,避免资源过载:

-
优先级抢占 :
为VIP租户(如付费客户)预留资源配额,确保SLA承诺。
2. 缓存一致性协议(CCP)
-
写穿透与读合并:
-
数据更新时同步失效相关缓存(如订单表变更时,清空"当日销售额"缓存);
-
合并相似查询(如"北京销售额"与"北京+海淀销售额")减少重复计算。
-
-
两阶段提交(2PC)轻量化改造 :
通过预写日志(WAL) 与异步提交,将跨库事务耗时降低80%。
3. 分布式事务优化
衡石的架构实践指向高并发BI的未来方向------将资源调度权交给AI:
-
强化学习驱动的动态扩缩容:
- 根据历史流量模式预测资源需求,提前扩容避免突发流量冲击。
-
异构计算统一编排:
- 自动分配CPU、GPU、FPGA等异构资源,最大化硬件利用率。
-
边缘-云协同计算:
- 在工厂边缘节点部署轻量引擎,处理实时数据,仅同步聚合结果至云端。
结语:高并发不是终点,而是新起点
当企业不再因技术限制而妥协分析深度与实时性时,数据才能真正赋能业务创新。衡石HENGSHI SENSE通过分布式架构 与缓存分级策略,证明了高并发场景下依然可以兼顾速度与智能------这不仅是技术的胜利,更是数据驱动决策范式的进化。