Vitepress+EdgeOne Pages快速迁移旧网站内容
目录
- [Vitepress+EdgeOne Pages快速迁移旧网站内容](#Vitepress+EdgeOne Pages快速迁移旧网站内容)
- 下载旧网站文章、图片
- 网站文章转Markdown
- Vitepress项目快速开始
- [EdgeOne Pages零帧起手](#EdgeOne Pages零帧起手)
- 参考材料
去年在阿里云码上公益平台报名了一个公益项目,这周收到了公益组织负责人的邮件,请求帮助开发一个用于查询志愿者服务时长的网页,另外该组织官网的服务器即将到期,需要尽快迁移服务器上的网站数据。
第一个需求比较简单,使用飞书多维表格的查询视图很快就完成了;第二个就相对复杂了,各种debuff因素加满:
- 官网是基于老旧的CMS系统做的,没有导出文章、图片的功能
- 密码丢了,无法远程登录服务器
- 服务器几天后就到期,时间紧
通过对比AI工具给出的几种建议方案,最终决定使用Vitepress+腾讯云EdgeOne Pages快速搭建网站,迁移旧网站的文章。
本文详细记录使用Vitepress+腾讯云EdgeOne Pages迁移旧网站内容的过程。
下载旧网站文章、图片
- 登录网站CMS后台,打开浏览器开发者工具,通过DOM获取网站文章列表
- 通过fetch方法发送网络请求,提取响应网页中的文章内容(富文本,HTML),保存文章内容到本地
JavaScript
const items = [];
const rows = document.querySelectorAll('tr[height="35"]');
for (const row of rows) {
const cells = row.querySelectorAll('td');
const id = cells.item(1).textContent.trim();
const links = cells.item(2).querySelectorAll('a');
const category = links.item(0).textContent.slice(1, -1);
const title = links.item(1).textContent.trim();
const updatedAt = cells.item(3).textContent.trim();
items.push({
id,
category,
title,
updatedAt,
});
}
function stringToDOM(htmlString) {
const parser = new DOMParser();
const doc = parser.parseFromString(htmlString, "text/html");
return doc;
}
function downloadAsFile(filename, content) {
const blob = new Blob([content], { type: "text/plain;charset=utf-8" });
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = filename;
a.style.display = "none";
document.body.appendChild(a);
// 触发点击事件,模拟用户点击下载
a.click();
// 释放URL对象,避免内存泄漏
URL.revokeObjectURL(url);
document.body.removeChild(a);
}
function sleep(delayTime = 1000) {
return new Promise(resolve => setTimeout(resolve, delayTime));
}
const recordIds = ["580", "579", ...];
for (const id of recordIds) {
fetch(`${baseUrl}/article_edit.php?aid=${id}`)
.then(response => response.text())
.then(html => {
const element = stringToDOM(html);
const content = element.querySelector('textarea#body');
if (content) {
downloadAsFile(`${id}.txt`, content.value);
}
});
await sleep(1500);
}- 通过Python lxml解析HTML,抽取其中的图片标签,获取图片链接
- 根据图片链接,下载图片到本地
Python
from lxml import etree
parser = etree.HTMLParser()
def find_images(html: str) -> list[str]:
"""解析HTML,抽取img标签中图片的路径"""
tree = etree.fromstring(html, parser)
images = []
for image in tree.xpath('//img'):
image_url = image.get('src')
if image_url.startswith('/uploads'):
images.append(image_url)
return images
images = []
for file in (data_dir / 'articles').rglob('*.txt'):
with open(file, mode='r', encoding='utf8') as fp:
html = fp.read()
images.extend(find_images(html))
print('Found {} images'.format(len(images)))网站文章转Markdown
Vitepress推荐把图片放到public目录下,在Markdown中通过以/为前缀的路径进行引用,为了保证网站文章在转Markdown后图片路径是正确的,需要在转换之前更新HTML中图片标签的src属性。
- 更新图片标签的src属性
- 使用Python markdownify把网站文章转换为Markdown
Python
from lxml import etree
from markdownify import markdownify as md
parser = etree.HTMLParser()
def handle_image_tags(title, html: str) -> str:
"""解析HTML,过滤图片标签,更新图片标签的src属性"""
tree = etree.fromstring(html, parser)
for index, image in enumerate(tree.xpath('//img')):
image_url = image.get('src')
image_name = Path(image_url).name
if not image_url.startswith('/uploads') or image_name not in valid_images:
image.getparent().remove(image)
continue
image.set('src', '/{}'.format(image_name))
image.set('alt', '{}-{}'.format(title, index + 1))
return etree.tostring(tree, encoding='utf8', method='html').decode('utf8')
def convert_article_to_markdown(title: str, created_at: str, content: str) -> str:
"""HTML文章转Markdown"""
metadata = """---
outline: deep
title: {}
author: 江津阳光社工
date: {}
version: 1.0
---
# {}""".format(title, created_at, title)
converted = md(content, heading_style='ATX').strip()
return metadata + '\n' + converted
table = str.maketrans(r'\/:*?"<>|', '_' * 9)
filename = title.translate(table) + '.md'Vitepress项目快速开始
- 参考Vitepress快速开始初始化项目,启动起来
- 把转换后的网站文章移动docs目录下
- 安装插件VitePress Sidebar,自动生成侧边栏
- 安装插件vitepress-plugin-image-viewer,点击预览文章中的图片
- 编辑Vitepress配置文件docs/.vitepress/config.mjs,最后上传代码到Github:
JavaScript
import { defineConfig } from 'vitepress'
import { withSidebar } from 'vitepress-sidebar';
function nav() {
return [
{
text: '关于我们',
items: [
{
text: '荣誉资质',
link: '/about-us/awards-and-certifications/中心资质.md',
},
{
text: '组织架构',
link: '/about-us/organizational-structure/江津阳光社工中心组织架构.md',
},
]
},
// ...
]
}
// https://vitepress.dev/reference/site-config
const vitePressOptions = {
title: "江津阳光社会工作服务中心",
description: "让儿童都能健康快乐成长,让社区更加和谐幸福。",
lang: "zh-CN",
locales: {
"/": {
label: "简体中文",
lang: "zh-CN",
},
},
lastUpdated: true,
themeConfig: {
nav: nav(),
search: {
provider: "local",
options: {
placeholder: "搜索文章",
translations: {
button: { buttonText: "搜索文章" },
modal: {
searchBox: {
resetButtonTitle: "清除查询条件",
resetButtonAriaLabel: "清除查询条件",
cancelButtonText: "取消",
cancelButtonAriaLabel: "取消",
},
startScreen: {
recentSearchesTitle: "搜索历史",
noRecentSearchesText: "没有搜索历史",
saveRecentSearchButtonTitle: "保存至搜索历史",
removeRecentSearchButtonTitle: "从搜索历史中移除",
favoriteSearchesTitle: "收藏",
removeFavoriteSearchButtonTitle: "从收藏中移除",
},
errorScreen: {
titleText: "无法获取结果",
helpText: "你可能需要检查你的网络连接",
},
footer: {
selectText: "选择",
navigateText: "切换",
closeText: "关闭",
searchByText: "搜索提供者",
},
noResultsScreen: {
noResultsText: "无法找到相关结果",
suggestedQueryText: "你可以尝试查询",
reportMissingResultsText: "你认为该查询应该有结果?",
reportMissingResultsLinkText: "点击反馈",
},
},
},
},
},
footer: {
copyright: `版权所有 © 2019-${new Date().getFullYear()} 重庆市江津阳光社会工作服务中心`
},
docFooter: {
prev: '上一页',
next: '下一页'
},
outline: {
label: '页面导航'
},
lastUpdated: {
text: '最后更新于',
formatOptions: {
dateStyle: 'short',
timeStyle: 'medium'
}
},
langMenuLabel: '多语言',
returnToTopLabel: '回到顶部',
sidebarMenuLabel: '菜单',
darkModeSwitchLabel: '主题',
lightModeSwitchTitle: '切换到浅色模式',
darkModeSwitchTitle: '切换到深色模式',
skipToContentLabel: '跳转到内容',
}
};
const vitePressSidebarOptions = [
{
documentRootPath: 'docs',
scanStartPath: 'about-us',
basePath: '/about-us/',
resolvePath: '/about-us/',
collapsed: true,
capitalizeFirst: true,
useTitleFromFrontmatter: true,
useFolderTitleFromIndexFile: true,
},
// ...
];
export default defineConfig(withSidebar(vitePressOptions, vitePressSidebarOptions));注意:由于VitePress Sidebar插件默认按目录名生成侧边栏,需要在目录下添加index.md文件,指定名称才能让侧边栏显示为中文。
Markdown
---
title: 荣誉资质
---EdgeOne Pages零帧起手
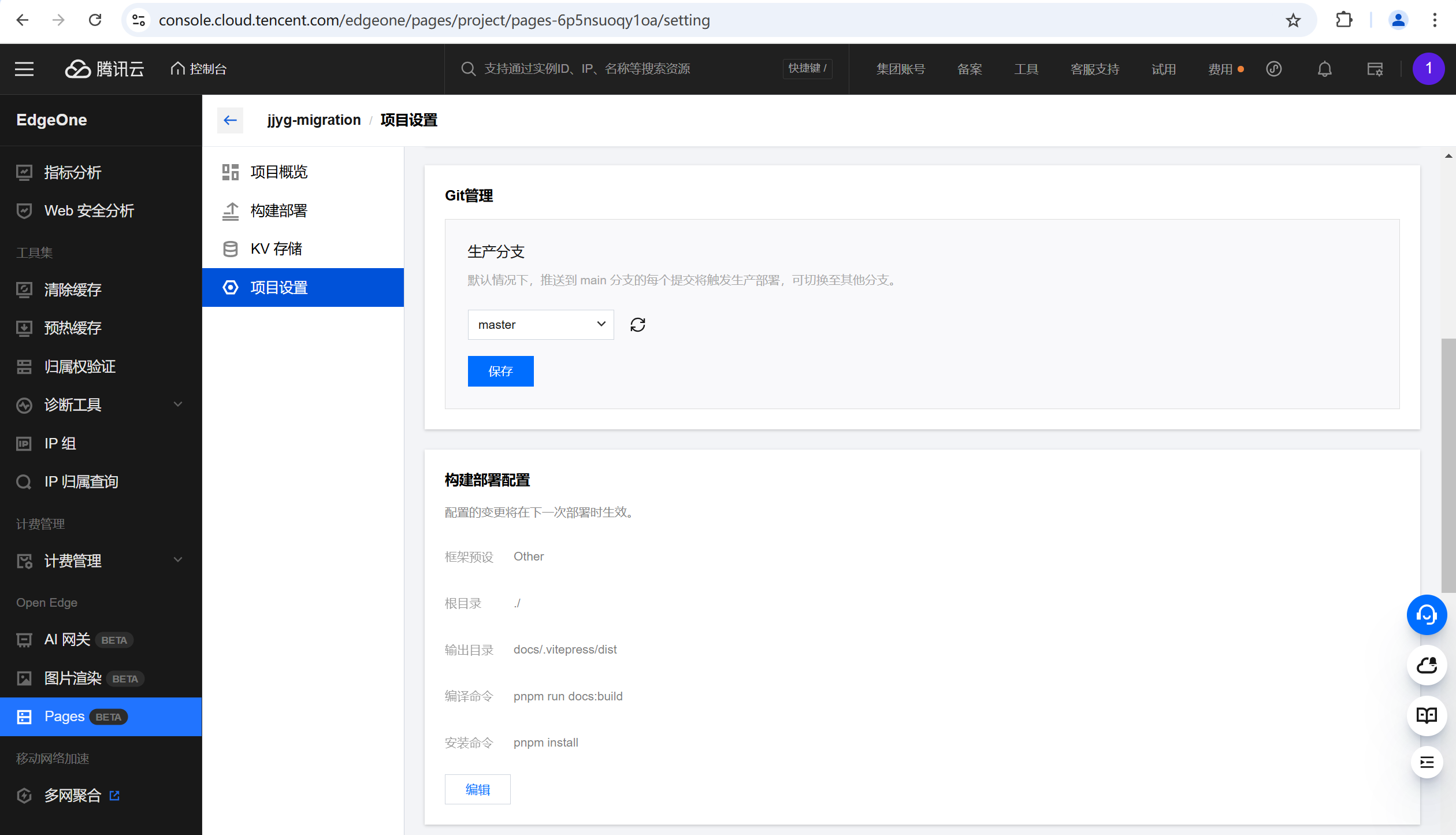
EdgeOne Pages是基于Tencent EdgeOne基础设施打造的前端开发和部署平台,专为现代Web开发设计,帮助开发者快速构建、部署静态站点和无服务器应用。通过集成边缘函数能力,实现高效的内容交付和动态功能扩展,支持全球用户的快速访问。
- 连接Github仓库
- 填写构建参数:
- 输出目录:docs/.vitepress/dist
- 编译命令:
pnpm run docs:build - 安装命令:
pnpm install
- 点击开始部署,部署完成后就可以通过临时(3小时)的域名访问网页了,添加自定义域名后,即可通过自己的域名访问网站。