本文介绍kafka单机环境的搭建及可视化环境配置,虽然没有java代码,但是麻雀虽小五脏俱全,让大家在整体感官上对kafka有个认识。在文章的最后,我介绍了几个重要的配置参数,供大家参考。
0、环境
- kafka:2.8.0
1、启动zookeeper
kafka本身自带了一个zookeeper,我们直接用这个就行,当然你也可以用你现成的zookeeper。下面是启动zookeeper的命令:
bash
bin/zookeeper-server-start.sh config/zookeeper.properties注意:zookeeper的端口默认是2181,如果你要修改,修改zookeeper.properties文件。
2、kafka配置及启动
2.1、配置
打开config/server.properties文件,找到listeners配置,修改成你想要改成的端口。
bash
listeners=PLAINTEXT://localhost:9092注意,如果你的zookeeper不是默认,同样在server.properties文件里,找到zookeeper.connect参数,改成你实际的地址和端口。
2.2、启动
下面咱们启动kafka:
bash
bin/kafka-server-start.sh config/server.properties能够看到kafka输出了大段的日志,在最后有提示kafka启动成功的提示。
3、测试
3.1、创建一个topic
bash
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic testk --
partitions 2 --replication-factor 1创建了topic名称是testk,它有2个partition,有一个副本。注意这里的副本包含topic本身,也就是说,此时没有副本。
下面查看一个topic的详细信息:
bash
bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic testk
3.2、创建producer、consumer
先创建一个producer(基础概念我就不多说了):
bash
bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic testk重新打开一个终端窗口,我们用来创建consumer:
bash
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic testk现在有两个窗口,我们可以在producer中输入消息,能够在consumer窗口看到收到的消息。注意:--from-beginning:指的是从头开始消费。
4、监控工具kafka manager
上面我在本地安装并配置了一个kafka实例,并利用kafka提供的命令行工具,分别创建了一个producer和consumer。但是不直观,这里我们配置一个kafka可视化工具, 利用工具能更直观。
我们这里使用的工具是kafka manager,现在改名字了,叫CMAK。下载地址: https://github.com/yahoo/CMAK。
4.1、启动
解压后,进入conf文件夹,打开application.conf文件。这里我们要配置zookeeper的地址,如下图:
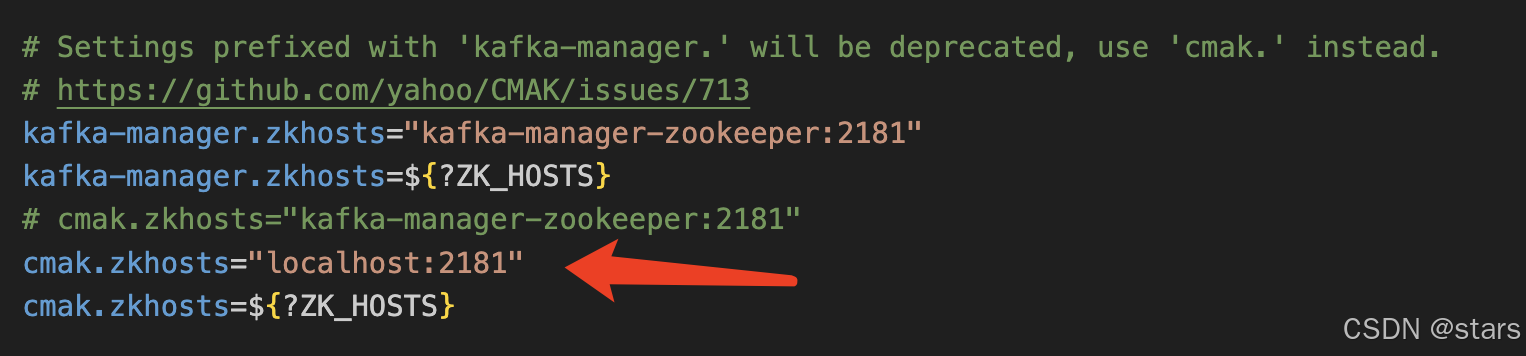
好了,可以启动了。CMAK home目录下执行:
bash
bin/cmak -Dhttp.port=9001-Dhttp.port指定了访问端口,你也可以用默认,默认端口是9000。好了,咱们访问一下。
4.2、利用CMAK配置集群
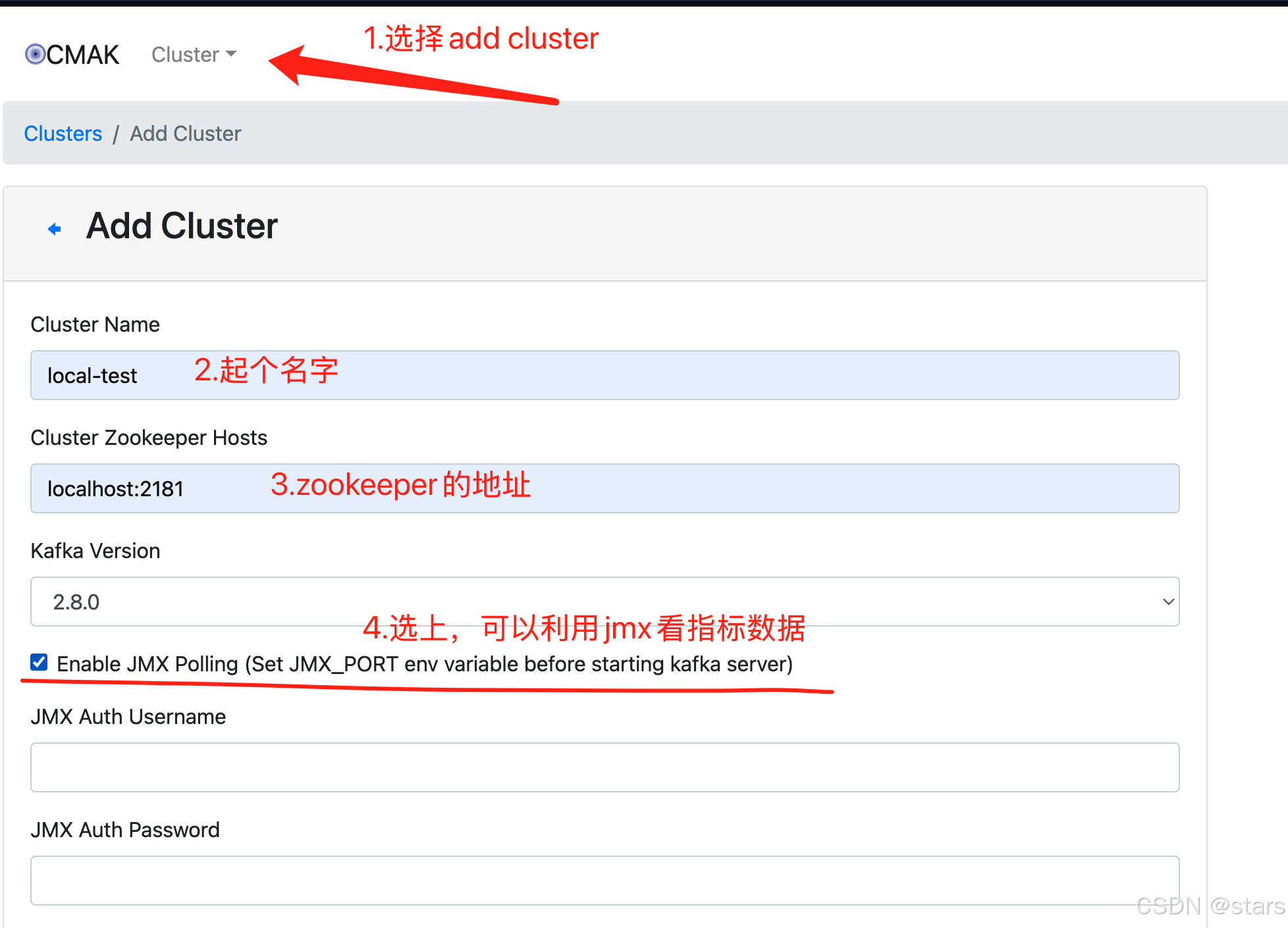
上图我标记的很清楚了,不多解释了,最后保存即可。这里要注意下,选了JMX Polling,我们要修改一下kafka的启动命令,指定JMX的监听端口。
bash
JMX_PORT=9999 bin/kafka-server-start.sh config/server.properties等kafka启动完成后,咱们再看一下配置后的效果:

相对比较简单,我就不多说了。最后我说几个重要的配置参数。
5、几个重要的kafka配置参数
- log.dirs:broker要使用的文件目录路径,可以多个,逗号分割。
- zookeeper.connect:指定了zookeeper的地址和端口,如:localhost:2181,可以多个,逗号分割。
- listeners:客户端连接kafka时,使用的协议、主机名和端口。如:PLAINTEXT://localhost:9092,其中PLAINTEXT表示明文传输。用户也可以用ssl加密的方式。
- log.retention.{hour|minutes|ms}:一条消息保存多长时间。当数据库用就将这个值调大。
- log.retention.bytes:消息保存的总磁盘容量。默认值-1,表示没有上限。
- message.max.bytes: 最大消息的大小。默认值1000012,不到1M,实际的生产环境超过1M的消息太多了,建议调大点。
好了,今天就到这里了。内容不少,希望大家能理解。
//~~